@liuhui0803
2016-12-08T07:27:12.000000Z
字数 3519
阅读 2443
NetflixOSS:Hollow正式发布
未分类
摘要:
Hollow是一种Java库,为中小规模的内存中数据集提供了一套全面的工具,适合从单一生成方到多个消耗方等不同场景下的数据只读访问。
正文:
“如果你能非常有效地缓存一切,那么通常你就可以改变游戏规则。”
软件工程师通常会面临一些有关不属于“大数据”的数据集的传播方式问题,例如:
- 电商网站的产品元数据
- 搜索引擎的文档元数据
- 互联网电视网络中有关电影和电视节目的元数据
面对这些问题,我们通常会选择两种解决方法:
- 将此类数据集中存储(例如使用RDBMS、NoSQL数据存储,或使用缓存集群)并供客户远程访问
- 将此类数据序列化(例如创建JSON、XML等形式),分发给客户并由客户保存本地副本
上述每种方式的缩放会造成不同的挑战。数据的集中化存储也许可以应对数据集总量的飞速增长,但:
- 数据的交互会存在延迟和带宽限制
- 远程数据存储永远不像本地数据副本那么可靠
另外将数据序列化并在RAM中保存数据完整本地副本的做法,虽然可以在降低延迟和提高访问频率方面起到数量级程度的提升,但随着数据集总量的增长,这种方式在缩放性方面会面临更加难以解决的挑战:
- 数据集的堆占用空间(Heap footprint)飞速增加
- 数据集的获取需要下载更多数据
- 数据集的更新可能需要耗费大量CPU资源或对GC行为产生较大影响
工程师通常会选择混合方法:将频繁访问的数据缓存在本地,并远程访问“长尾”数据。这种方法也会产生挑战:
- 数据结构的Bookkeeping会导致缓存的堆占用空间大幅增加
- 对象保留的时间太久,以至于增加了对GC行为的消极影响
Netflix意识到这种混合方式只能提供“伪”收益。为了确定本地缓存的大小,通常需要在远程访问大量记录产生的延迟,以及将更多数据保存在本地对堆产生的需求之间进行慎重的权衡。然而如果能能非常有效地缓存一切,那么通常就可以改变游戏规则,同时可以在将整个数据集保存到内存中的前提下,实现比只保存部分数据时更低的堆占用和CPU消耗。Netflix最新的OSS项目Hollow应运而生。

Hollow是一种Java库,为中小规模的内存中数据集提供了一套全面的工具,适合从单一生成方到多个消耗方等不同场景下的数据只读访问。
“Hollow***会根据数据集调整自己的规模* …以往如此灵活的数据集是不适合用于Hollow的。”
性能
Hollow主要侧重于上文提到的问题:在内存中保留一份完整的,可供使用的只读数据集。借此可规避从不完整的缓存中更新和逐出(Evicting)数据所产生的后果。
出于性能特点方面的考虑,Hollow会按照数据集的尺寸调整自己的规模,使其更适合充当内存中解决方案。以往如此灵活的数据集是不适合用于Hollow的,例如Hollow可以完全适应以JSON或XML格式呈现,尺寸超过100GB的数据集。
敏捷性
Hollow不仅有助于改善性能,还可大幅促进团队处理与数据有关的任务时的敏捷性。
从初始体验的角度来看,Hollow非常易用。Hollow可根据指定的数据模型自动生成自定义API,借此消耗方可以直观地与数据进行交互,并能从IDE的代码补全功能中获益。
在持续使用Hollow的过程中也能获得源源不断的优势。将数据放入Hollow后将能获得更多潜力。例如可以极为快速地将包含当前数据或过去时点的整个生产数据集分流(Shunt)到本地开发工作站,加载这些数据并精确再现具体的生产场景。
选择Hollow 的同时,用户可以在工具方面获得更多优势。Hollow包含大量已经开发完成可以实用的工具,可以帮助用户分析操作各种数据集,进而获得见解。
稳定性
你的目标到底是实现几个“九”的可靠性?三个?四个?五个?九个?作为一种本地的内存中数据存储,Hollow不容易受到环境问题的影响,例如网络中断、磁盘故障、集中化数据存储中其他用户的干扰等。如果数据生成方遇到故障或消耗方无法连接到数据存储,还可以用陈旧的数据继续维持运转,虽然数据略显陈旧,但至少有可用的数据可以维持服务不中断。
Hollow已经在Netflix内部经历了超过两年的持续运行考验。我们使用该技术存储关键数据集,而这些数据集是塑造Netflix使用体验所必不可少的,该技术运行在非常高负荷的服务器上,以接近甚至达到容量最大值的水平为客户请求提供着服务。尽管Hollow会想方设法试图榨干服务器硬件性能的“每一滴油水”,但我们也在细节方面付诸了巨大的关注,并设法对基础架构中的重要组件进行加固。
起源
作为当时对这一问题的解决方案,三年前我们公布了Zeno。Hollow取代了Zeno,但从很多方面来看,可以说Hollow传承了Zeno的“衣钵”。
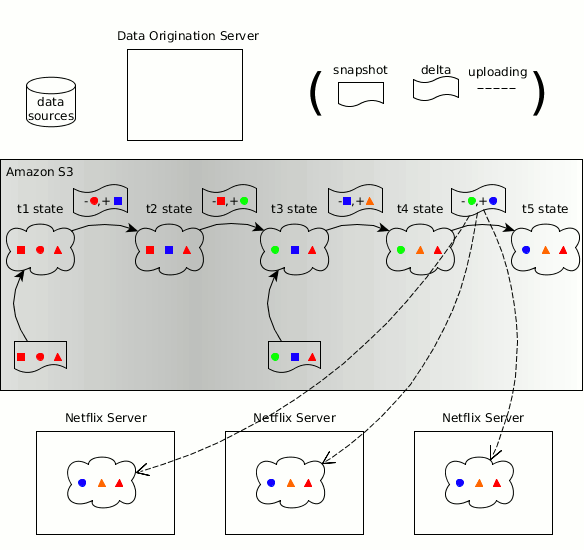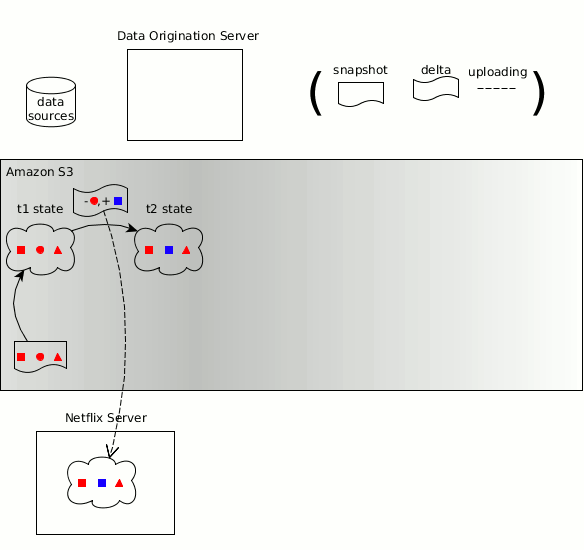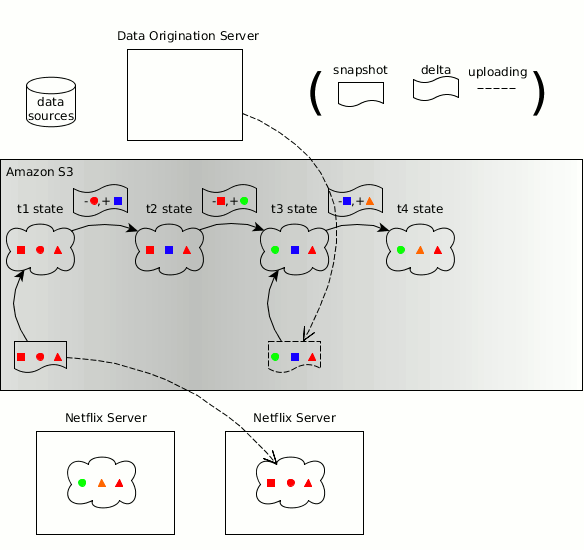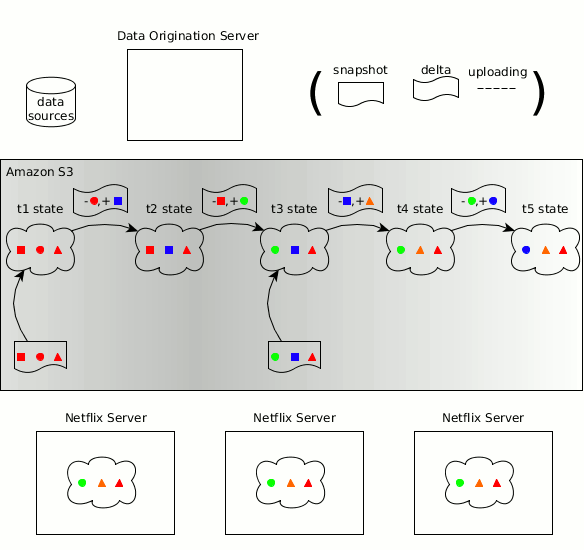
Zeno有关生成方、消耗方、数据状态、快照、增量的概念已融入Hollow
与Zeno类似,数据集具体变化的时间线可拆分为多个离散的数据状态,每个状态都是数据在特定时点的一个完整快照。Hollow可自动生成不同状态之间的增量,因此消耗方只需做最少量的工作即可保持自己所用数据为最新版本。Hollow会自动进行数据去重,借此将消耗方所用数据集的堆占用空间降至最低。
变革
Hollow沿用了Zeno的三个概念,并在此基础上进行了革新,进而对整个解决方案的方方面面进行了完善。
Hollow并未使用POJO作为“内存中”的具体呈现,而是使用了一种更紧凑的定长强类型数据编码方式。该编码方式可将数据集的堆占用空间和随时访问数据时的CPU消耗降至最低。所有编码后的记录会打包为可重用的内存块(Slab),并在JVM堆的基础之上进行池化,借此避免服务器高负载时对GC行为产生影响。

OBJECT类型记录在内存中布局方式的一种范例
Hollow数据集本身是自包含的,任何用例无需另行编写专用代码即可获得能被整个框架使用的序列化Blob。此外按照设计,Hollow充分考虑了向后兼容性,这也可以降低部署工作的频率。
“可构造强大的访问模式,而无须考虑数据模型最初的设计是否考虑过这种访问模式。”
由于Hollow将所有数据保存在内存中,因此在开发相关工具时可假设能够在无需离开JVM堆的情况下对整个数据集随时执行随机访问。Hollow自带大量预制工具,此外用户可通过库所提供的基本构建块简单直接地开发自定义工具。
Hollow技术的核心在于通过不同方式对数据创建的索引。借此即可灵活访问数据中的相关记录,并构造强大的访问模式,而无须考虑数据模型最初的设计是否考虑过这种访问模式。
收益
Hollow的配套工具非常易于设置和使用。借此用户可以从数据中获得以往闻所未闻的见解和洞察力。
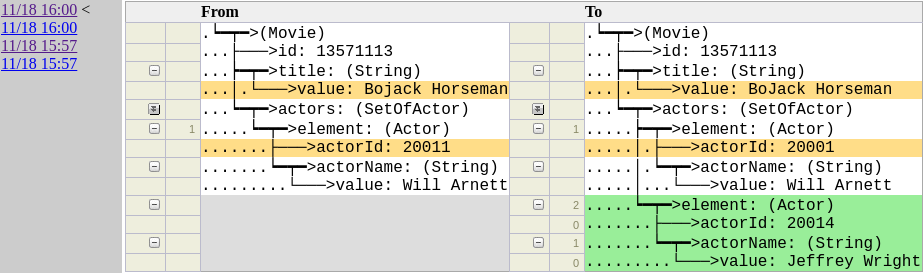
历史工具可用于检查记录在一段时间以来的变化情况
Hollow可以让运维过程变得更为强大。如果某一特定记录看起来有问题,用户只需要通过历史工具执行一个简单的查询,即可清晰了解实际发生的具体变化以及变化发生的时间。如果不幸发布了有问题的数据集进而造成灾难性后果,用户可以将数据集回滚至出错前的状态,在最短时间内解决生产环境中出现的问题。由于数据集不同状态之间的过渡非常快,这一操作可在几秒钟内应用至整个环境。
“将数据放入Hollow后将能获得更多潜力。”
Hollow让Netflix获益匪浅,虽然对元数据的需求与日俱增,但服务器启动所需的时间和堆空间占用均有了显著降低。由于Hollow可通过详细的堆空间占用分析进行更有针对性的数据建模,因此性能还有进一步提高的空间。
除了性能方面的收益,在编录(Catalog)数据的分发方面我们的生产力也有了显著提高。这要归功于Hollow所提供的相关工具,同时也要归功于我们所用的架构,而这种架构的实现也离不开Hollow。
结论
无论看哪里,在我们眼中看到的问题都能通过Hollow解决。现在Hollow已经公开发布,所有人都可从中获益。
但Hollow并非可适用于任何规模的数据集。如果数据足够大,将整个数据集完整保存在内存中的做法本就不可行。然而在恰当框架以及少量数据建模工作的帮助下,可支持的数据量也许远远超过你的想象。
Hollow的相关文档请参阅http://hollow.how,代码已发布至GitHub。我们建议用户深入阅读快速上手指南,根据指南的提示只需几分钟即可搭建并运行演示环境,不到一小时就可以搭建出全功能的生产级Hollow实现。随后即可放入自己的数据模型,从起点迈出自己的第一步。
用户在使用过程中可通过Gitter获得来自我们以及其他用户的直接帮助,或可使用“hollow”标签在Stack Overflow发帖寻求帮助。
作者:Drew Koszewnik,阅读英文原文:NetflixOSS: Announcing Hollow
