@liuhui0803
2016-10-07T23:42:10.000000Z
字数 4652
阅读 3447
无服务器架构 2/3
无服务器 DevOps 架构 云计算
摘要:
无服务器是软件架构世界中的热门话题。在这一领域我们已经看到很多书籍、开源框架、大量不同类型的供应商和产品,甚至专门的会议活动。但无服务器到底是什么,为什么值得(或不值得)考虑该技术?希望本文能为你提供一些启发。这是系列文章的第二篇,主要将介绍无服务器架构所能提供的收益。
正文:
- 降低运维成本
- BaaS – 降低开发成本
- FaaS – 伸缩成本
- 范例 – 偶发请求
- 范例 – 不均匀的流量
- 优化是节约某些成本的根本
- 简化运维管理
- FaaS伸缩能力提供的收益不仅限于成本
- 降低程序包和部署的复杂度
- 上市时间/实验
- “更绿色的”计算?
收益
上文主要定义并解释了无服务器架构的含义。下文将探讨用这种方式设计和部署的应用程序所能获得的收益和存在的不足。
需要注意的是,其中一些技术还很新。截止撰写本文时,最领先的FaaS实现AWS Lambda诞生也还没超过2年。因此再过两年后,目前我们所获得的一些收益看上去可能也像是炒作,而目前的一些不足之处届时可能也已经妥善解决了。
由于这些结论尚未经过大范围的实践证实,你在决定使用无服务器技术前一定要慎重考虑。希望本文列出的利弊清单可以帮你顺利做出决策。
首先准备展望一下美好生活,说说无服务器技术能带来的优势。
降低运维成本
从本质上来看,无服务器技术实际上是一种外包解决方案。该技术可以让你雇佣别人代替你管理服务器、数据库,甚至应用程序逻辑。由于使用的都是可以同时被他人共用的预定义服务,这里也存在着很大的规模经济效益,当一个供应商可以同时运行数千个类似的数据库时,每个用户支付的费用自然更低。
对你来说,成本的降低共体现在两方面:基础结构成本和人员(运维/开发)成本。虽然部分成本收益可能只来源于与其他用户分享基础结构(硬件、网络),但人们这样做的预期在于大部分情况下相比自行开发和托管的系统,用在外包无服务器系统上的时间会少很多(因此可以降低运维成本)。
然而这种收益和基础结构即服务(IaaS)或平台即服务(PaaS)所提供的收益并无太大区别。但我们可以通过两种主要方式对这些收益进行扩展,分别是无服务器BaaS和无服务器FaaS。
BaaS – 降低开发成本
IaaS和PaaS基于这样的一种前提:服务器和操作系统的管理工作可成为一种商品化的服务。然而无服务器后端即服务可以让整个应用程序组件成为商品化的服务。
身份验证就是个很好的例子。很多应用程序需要开发自己的认证功能,其中通常会包含诸如注册、登录、密码管理、与其他认证服务供应商的集成等功能。总的来说大部分应用程序的此类逻辑都是类似的,因此诞生了类似Auth0这样的服务,可以让我们将已经创建好的认证功能集成在自己的应用程序中,无须自行开发。
BaaS数据库也是类似的情况,例如Firebase的数据库服务。一些移动应用程序团队发现让自己的客户端直接与服务器端的数据库进行通信,往往会采用这样的做法。BaaS数据库避免了大部分数据库管理负担,此外这类服务通常还提供了可满足无服务器应用所需模式的,用于为不同类型用户提供所需认证方法的机制。
取决于你的知识背景,这些方式可能会让你感到坐立不安(别着急,具体原因会在下文不足之处一节详细介绍),但不可否认的是,很多打造出成功产品的成功公司所依赖的绝不仅仅是自己服务器端运行的代码。Joe Emison 在最近举行的无服务器大会上针对这个话题给出了几个例子。
FaaS – 伸缩成本
正如上文所述,无服务器FaaS的好处之一在于“横向伸缩是完全自动化高弹性的,且将由服务供应商负责管理”。这种做法可以提供诸多收益,但从最基本的基础结构层面来说,最大的收益在于你只用为自己需要的计算能力付费,而在AWS Lambda这样的服务中甚至可以将计费粒度细化至100毫秒。取决于流量规模和类型,这一特性可能会为你提供巨大的经济效益。
范例 – 偶发请求
假设你运行的某个服务器应用程序只需要每分钟处理1个请求,每个请求的处理需要花费50毫秒,而一小时的时间内CPU平均使用率为0.1%。从某种观点来看,这样的使用模式无疑是极为低效的,但如果有其他1000个应用程序和你共享CPU,大家都可以用这一台服务器顺利完成自己的任务。
无服务器FaaS就是为了解决这种低效问题,并能帮你降低成本。在这个场景中你每分钟只需要为100毫秒的计算时间付费,只占时间总量的0.15%。
这种方式还能提供下列连锁收益:
- 对于未来出现的,对负载要求非常低的微服务,可支持将整个组件拆分为不同的逻辑/领域,哪怕这种细化程度的运维成本原本根本不支持这样做。
- 这样的成本收益还能促进民主化。很多公司或团队很可能想要尝试一些新技术,如果通过FaaS满足自己的计算需求,“试水”产生的运维成本将显得微乎其微。实际上如果你的所有工作负载相对较小(但也并非完全微不足道),甚至可能不需要为计算能力支付任何费用,因为某些FaaS供应商提供的“免费层”服务就足够了。
范例 – 不均匀的流量
再看看另一个例子。假设你的流量特征呈现明显的“峰谷”,也许基准流量仅为每秒20个请求,但每五分钟会遇到一次每秒200个请求(常规数量的10倍)并持续10秒钟的情况。出于范例的目的,我们假设基准性能就已经让服务器满载运行,但你不希望在峰值时期延长响应时间。如何解决这个问题?
在传统环境中,为了应对峰值需求可能需要将硬件总容量提升10倍,但这样的容量只在4%的总运行时间内可以得到充分利用。自动伸缩功能在这里可能并不是一种好的做法,因为新的服务器实例需要一定时间“热身”才能正常运转,但当新实例启动完成后,峰值时期已经结束了。
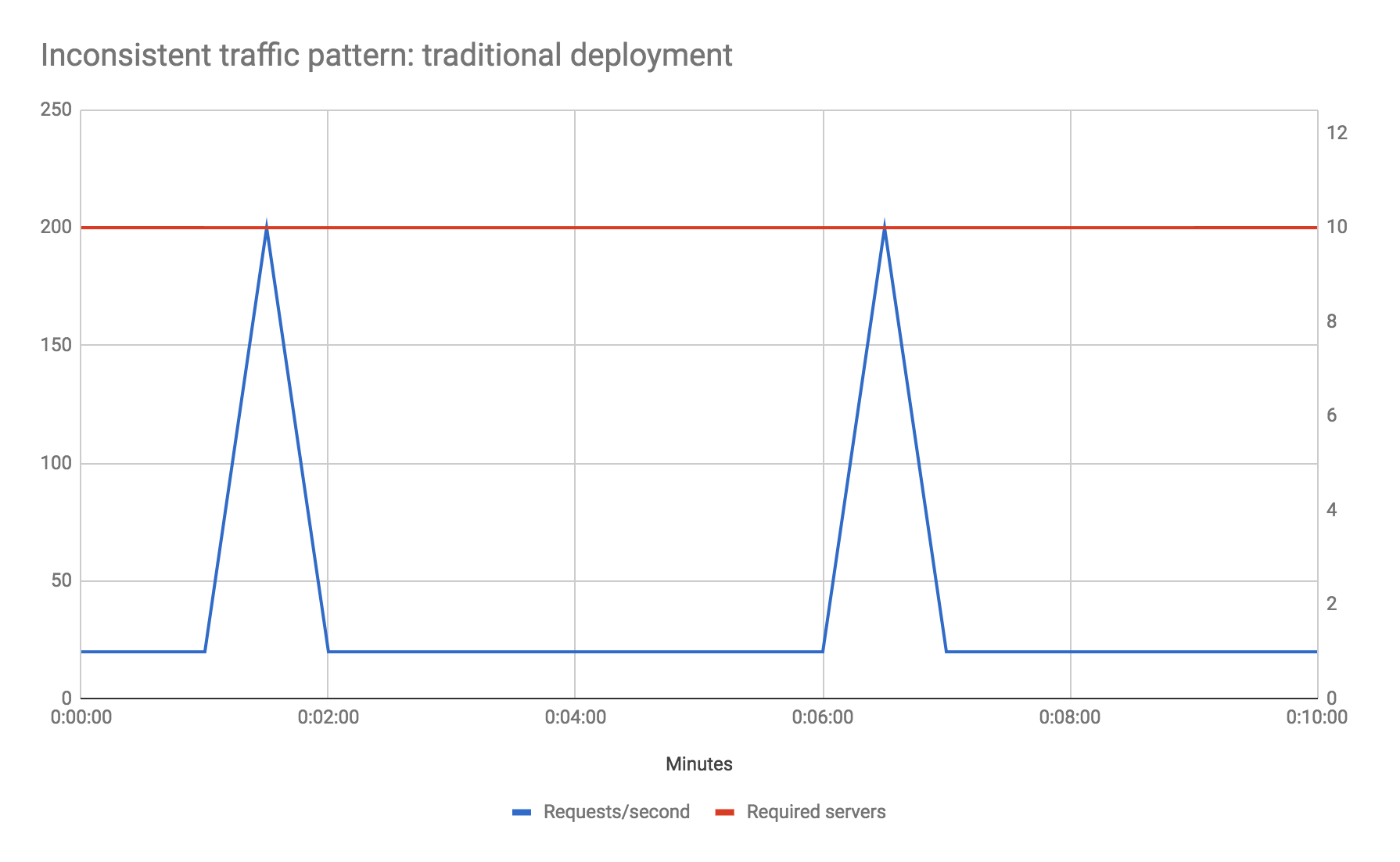
不过在无服务器FaaS环境中这一切不再是问题。甚至无须执行任何额外操作,可以直接认为流量是均匀分布的,并且只需要为峰值时期使用的额外计算资源付费。
很明显,为了凸显无服务器FaaS在节约成本方面所提供的巨大收益,这里列举的例子是很有针对性的,目的在于证明除非流量非常均匀一致,并且能充分利用整个服务器系统的全部资源,否则仅从伸缩的角度来看,使用FaaS可以帮你节约大量成本。
但上述例子中有个问题需要注意:如果你的流量是均匀的并且始终能够充分利用服务器资源,你可能无法获得这样的成本收益,此时使用FaaS反而可能会花更多钱。因此需要针对当前供应商的成本,以及传统方式下同等容量、全时间运行的服务器成本进行一定的权衡,看看自己能否接受这样的成本。
优化是节约某些成本的根本
关于FaaS的成本还有个有趣的问题:对自己的代码进行任何性能优化,不仅可以加快应用运行的速度,而且取决于所选供应商计费粒度的细化程度,还会对运维成本的降低立刻产生直接影响。举例来说,如果目前每个操作需要花费1秒钟,但将时间缩短至200毫秒,无须改动基础结构即可在计算成本方面立即节约80%。
简化运维管理
本节内容尤其需要注意:运维方面的某些问题对无服务器来说还较为麻烦,目前我们只准备谈谈该领域一些新出现的积极意义…
在无服务器BaaS端,运维管理工作比其他架构更简单的原因非常明显:支持的组件数量越少,工作量也就越低。
FaaS端的特征比较多,下文将深入介绍其中的几个。
FaaS伸缩能力提供的收益不仅限于成本
从上文的内容来看,伸缩是一种新特征,但也要注意FaaS的伸缩功能不仅可以降低计算成本,而且可以降低运维管理成本,因为伸缩工作可以自动完成。
如果伸缩过程是手工进行的,在最理想情况下,例如有专人负责给服务器阵列添加或删除实例,但如果使用FaaS可以完全忽略这一问题,让FaaS供应商代替你对自己的应用程序进行伸缩。
就算在非FaaS架构中可以使用“自动伸缩”,但这一过程依然需要设置和维护,FaaS完全无须执行这样的操作。
同理,因为伸缩是由供应商针对每个请求/事件分别进行的,你甚至再也不需要考虑自己最多可以处理多少并发请求才不至于耗尽所有内存或导致性能显著下降这样的问题,至少对于通过FaaS承载的组件无须考虑。由于负载可能激增,下游数据库和非FaaS组件也需要针对这种情况做好充分考虑。
降低程序包和部署的复杂度
虽然API网关本身比较复杂,但相比部署整个服务器,打包和部署FaaS函数的过程已大幅简化。只需要将代码编译并打包为zip/jar格式,随后上传即可。无须puppet/chef,无须启动/停止Shell脚本,无须考虑是否要在计算机上部署一个或多个容器。对于新手甚至无须打包代码,可以直接在供应商的控制台内编写代码(当然不推荐用这种方式编写生产代码!)。
这个过程很简单,在一些团队中可以提供巨大的收益:整个无服务器解决方案无须进行任何系统管理。
平台即服务(PaaS)解决方案也能提供类似的部署收益,但正如上文对FaaS和PaaS对比时提到的,FaaS的伸缩优势是独一无二的。
上市时间/实验
“简化运维管理”是工程师很熟悉的收益,但这对业务意味着什么?
最显著的意义在于成本:运维所需时间更少 = 运维需要的人员更少。但目前我认为最重要的意义在于“上市时间”。随着团队和产品变得愈加精益(Lean)和敏捷,我们会希望持续尝试新事物并快速更新现有系统。虽然直接重新部署即可对稳定状态的项目进行快速迭代,但更出色的新想法到首次部署能力使得我们能用最小阻力和最低成本完成各种新实验。
FaaS*新想法到首次部署*的特性很适合某些情况,尤其是对于通过供应商生态系统内已经成熟的事件触发简单函数这种情况。举例来说,假设你的组织正在使用类似Kafka的消息系统AWS Kinesis将不同类型的实时事件广播到整个基础结构。借助AWS Lambda,可以在几分钟内为这种Kinesis流开发并部署新的生产事件监听器,一天之内就可以完成各种不同类型的实验!
对于基于Web的API,由于存在各种不同用例,不能说真能有效简化运维,但各种开源项目和小规模的实现正在朝着这一目标努力。下文将进一步介绍。
“更绿色的”计算?
过去几十年来,全球数据中心的数量和规模都有了爆发式增长,这些数据中心的能耗,以及构建众多服务器、网络交换机等设备所需的物理资源用量也水涨船高。苹果、谷歌,以及其他类似的公司都开始谈到要将自己的数据中心部署在距离可再生能源更近的地区,以降低此类设施对化石燃料的用量。
这种显著增长的部分原因在于有越来越多的服务器大部分时候都是闲置的,但依然需要开机运行。
商用和企业环境中数据中心内典型的服务器在全年时间内只用到了运算能力总量的5-15%。
-- 福布斯
这样的效率实在非常低,并会对环境产生巨大影响。
一方面这要“归功于”云基础结构,因为企业可以根据需要随时“购买”更多服务器,不再需要预先妥善规划并供应所有必要的服务器。然而有人可能会争辩说,如果大量此类服务器用完之后置之不理,不进行妥善的容量管理,服务器供应过程的简化只会让整个情况变得更糟。
无论使用自行托管、IaaS或PaaS基础结构解决方案,我们依然需要决定应用程序在未来数月甚至数年内的容量需求。这一过程通常需要谨慎,没错,容量管理与过渡供应会导致上文提到的低效率问题。但在使用无服务器方法后,我们再也不需要自行确定有关容量的决定,反而可以让无服务器技术供应商根据自己的需求实时提供足够的计算容量。随后供应商可根据自己所有客户的需求确定自己的总容量需求。
这种差异可以让整个数据中心内所有资源得到更充分的利用,相比传统的容量管理方法可大幅降低对环境的影响。
本文作者:Mike Roberts,阅读英文原文:Serverless Architectures
