@liuhui0803
2016-09-04T11:50:36.000000Z
字数 7943
阅读 3835
实现反垃圾邮件系统过程中的猫鼠游戏
Tarantool 架构 设计
摘要:
本文将谈谈为Mail.Ru集团的邮件服务实现反垃圾邮件系统的过程,并将介绍在该项目中使用Tarantool数据库的经验:Tarantool的作用,我们面临的局限和集成方面的问题,过程中可能遇到的陷阱,以及最终的解决方法。
正文:

本文将谈谈为Mail.Ru集团的邮件服务实现反垃圾邮件系统的过程,并将介绍在该项目中使用Tarantool数据库的经验:Tarantool的作用,我们面临的局限和集成方面的问题,过程中可能遇到的陷阱,以及最终的解决方法。
首先简单讲讲前因后果。我们大概在十年前开始为邮件服务提供反垃圾邮件功能。第一个解决方案使用了带有RBL(实时黑洞清单 — 一种与垃圾邮件发送者有关的实时IP地址清单)的Kaspersky Anti-Spam,虽然可降低垃圾邮件数量,但由于系统本身的惯性,无法足够快速(例如实时)地抑制垃圾邮件的发送。此外速度方面的要求也未能满足:用户本应在最低延迟情况下收到正常邮件信息,但当时所用的集成解决方案在识别垃圾邮件发送者方面速度不够快。当垃圾邮件发送者发现垃圾信息未能成功发送后,会用非常快的速度更改自己的行为模式和垃圾内容特征。我们无法接受这样的系统惯性,决定自行开发垃圾邮件筛选器。
我们的第二个系统是MRASD — Mail.Ru Anti-Spam Daemon。实际上这是一种非常简单的解决方案。客户邮件信息会通过一台Exim邮件服务器到达提供主筛选器的RBL,随后到达MRASD并在这里进行主要的处理工作。这个反垃圾邮件守护进程会将信息拆分成块:邮件头和正文。随后使用基本算法让每块信息实现标准化,例如让大小写实现统一(全部大写或全部小写),将外观类似的字符统一为某种格式(例如用一个字符代表俄文和英文的“O”)等。实现标准化后,该守护进程从中提取出所谓的“实体”,即邮件签名。我们的垃圾邮件筛选器会分析邮件信息中的不同部分,发现可疑内容会将其阻止。例如,可以为“万艾可”这个词定义一个签名,所有包含该词的邮件会被阻止。实体也可以是一个链接、一张图片、一个附件等。垃圾邮件检查过程中还要计算已核查邮件信息的指纹。指纹内容通过多个复杂的哈希函数计算而来,是对邮件特征做出的具备唯一性的汇总。根据计算而来的哈希值和收集到的哈希统计信息,反垃圾邮件系统会将邮件标记为垃圾邮件或放行。当哈希值或某个实体出现的频率达到某一阈值后,服务器会开始阻止所有匹配的邮件信息。为此我们通过统计(计数器)记录某个实体的出现次数和收件人的举报频率,据此为实体设置SPAM/HAM标签(在与垃圾邮件有关的领域,“Ham”是“Spam”的反义词,是指经核查不包含任何垃圾内容的邮件)。
MRASD的核心部件使用C++实现,但其中大部分业务逻辑通过解释型语言Lua实现。正如上文所述,垃圾邮件发送者通常非常敏捷,会快速更改自己的行为。我们希望能对垃圾邮件发送者的每次改动快速做出响应,因此使用解释型语言实现业务逻辑(通过使用Lua,无须每次重新编译整个系统并对其进行更新)。另外还需要满足有关速度的要求:Lua编写的代码在性能测试中表现很出色,很容易与C++代码集成。
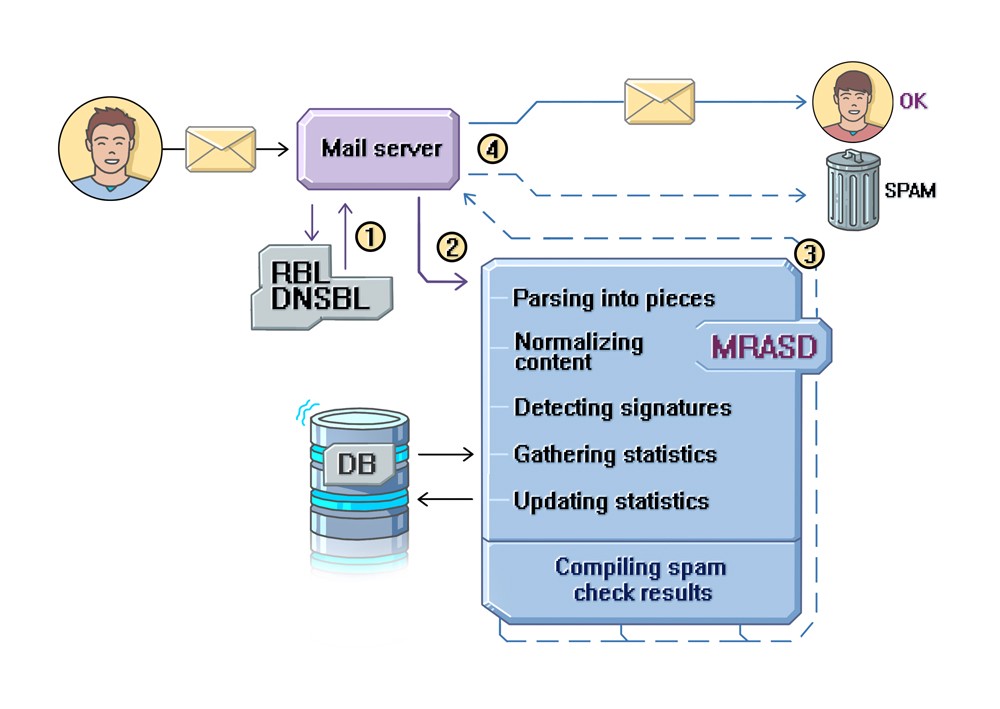
上述架构展示了简化后的反垃圾邮件筛选器工作流:邮件信息从发件人到达邮件服务器;如果该邮件成功通过了主筛选器(1)的筛查,随后将到达MRASD (2)。MRASD将检查结果发送至邮件服务器(3),根据这些结果将邮件放入收件人的“垃圾邮件”文件夹或收件箱。
MRASD帮助我们将未能成功筛选的垃圾邮件数量减少了十倍。随着后续完善,我们也在继续对整个系统进行改进:添加新的子系统和组件,引入新工具。整个系统还在继续成长并变得更复杂,而同时反垃圾邮件任务也变得更为多样化。但这些变化并不会对整个技术堆栈造成太大影响,下文将详细介绍具体原因。
技术堆栈的演化
在邮件服务刚诞生的时代,邮件流和消息内容远不像今天那么丰富,但当时可选的工具和可用的计算能力也极为贫瘠。正如上文“原始”的MRASD模型中提到的,当时甚至需要存储所有类型的统计数据。这些数据中很大一部分都是“热”数据(即常用数据),这就对数据存储系统提出了一定要求。我们选择用MySQL作为“冷”数据的存储系统,但依然没能决定如何处理“热”的统计数据。当时分析了所有可行解决方案(虽然“热”,但并非任务关键型数据所需的性能和功能),最终选择了Memcached,当时这个解决方案已经足够稳定。但在“热”数据和关键数据的存储方面依然存在问题。与其他缓存解决方案类似,Memcached有自己的局限,例如缺乏复制机制,以及缓存下线(并清空)后缓慢冗长的恢复期。进一步研究后我们的目光投向Kyoto Cabinet,一种非关系型键值数据库系统。
时光飞逝,邮件工作负载持续增加,反垃圾邮件的负载也与日俱增。随后还出现了一些新服务,使得我们必须存储更多数据(Hadoop、Hypertable)。直到今天,峰值处理负载已高达每分钟55万封邮件(如果用每天的平均数来计算,大约等于每分钟处理35万封邮件),而每天要分析的日志文件也超过了10TB。想想过去的情况吧:如果不考虑增加的工作负载,我们对数据处理(加载、存储)的要求基本保持不变。某天我们开始意识到Kyoto无法满足我们对数据量的需求。更重要的是,我们希望存储系统能为“热”数据和关键数据提供更广泛的功能。也就是说,需要寻找更适合的方案,必须足够灵活并易于使用,同时必须提供极高的性能和故障转移能力。
那段时间里,一个名为Tarantool的NoSQL数据库在我们公司内部逐渐开始流行,Tarantool是公司内部开发的,可以完全满足我们的“需求”。另外我最近也核查了我们的服务,感觉自己像考古学家一样惊喜地发现了某个最早期版本的Tarantool — Tarantool/Silverbox。评测发现该产品的性能完全可以满足我们对数据量的需求(这一时期的准确工作负载指标暂不清楚),同时内存用量也让我们觉得满意,于是打算试试Tarantool。另一个重要因素在于,该产品的开发团队就在我们隔壁,直接使用JIRA就可以快速提出功能请求。我们决定与其他先行者一样在自己的项目中使用Tarantool,同时也觉得其他先行者的正面体验为我们提供了足够的激励。
“Tarantool时代”就此开始。我们积极主动并持续不断地将 Tarantool引入反垃圾邮件架构中。目前我们使用基于Tarantool高负载服务的队列存储各类统计信息:用户声誉、发件人IP声誉、用户可信度(“Karma”统计信息)等。目前我们正在将升级后的数据存储系统与实体统计处理程序进行集成。你可能会纳闷,为什么要为反垃圾邮件项目使用一个统一的数据库解决方案,并且不考虑迁移至其他存储方案。事实并非如此。我们也考虑并分析了其他系统,但在目前的项目中,Tarantool对各种任务的处理效果都很不错,并且可以满足对负载的要求。引入新的(未知,以前没用过的)系统会有相应风险,需要付出更多时间和资源。与此同时,我们(以及我们的很多其他项目)对Tarantool已经非常熟悉。我们的开发者和系统管理员已经对Tarantool的使用和配置极为了解,知道如何更充分地使用这个产品。另一个优势在于,Tarantool的开发团队还在不断改进自己的产品,能为我们提供更好的支持(这些家伙就在隔壁,多棒啊 :))。当继续使用Tarantool实现另一个解决方案时,可以直接得到所有必要的帮助和支持(下文会进一步提到这一点)。
下文将概括介绍我们的反垃圾邮件项目中与本文话题有关,并且用到了Tarantool的几个系统。
系统中Tarantool使用情况概述
Karma
Karma是一种代表用户可信程度的数字值。该值最初被用作常规的“胡萝卜加大棒”用户系统的基准,该系统无须复杂的依赖系统。Karma是根据从其他用户声誉系统所获得数据聚合而来的值。Karma系统的想法很简单:每个用户都有自己的Karma值,值越高代表越可信,值越低代表检查垃圾邮件时需要对其邮件信息进行的检查越严格。举例来说,如果发件人发送的邮件信息包含可疑内容但发件人Karma值很高,此类邮件将进入收件人的收件箱,如果Karma值比较低情况恐怕就悲剧了。这套系统总让我想起学校里老师在期末考时拿出的点名簿。从不缺勤的学生只需要回答几个问题就可以放假,缺勤较多的学生恐怕要回答很多问题才能得到高分。
Tarantool通过一台服务器存储与Karma有关的数据工作。下图展示了这样的一个实例每分钟处理的请求数量。
RepIP/RepUser
RepIP和RepUser(声誉IP和声誉用户)是一种高负载服务,主要负责处理与使用特定IP的发件人(用户)活动和操作有关的统计信息,以及与用户在一段时间内使用邮件服务的频率有关的统计信息。通过这个系统我们可以了解用户发送过多少邮件,其中多少封被别人读过,多少封被别人标记为垃圾邮件。这套系统的优势之一在于可以提供完整的时间线,而非仅仅提供用户活动的快照。
为什么说这一特性对行为分析很重要?假设你没有通知任何人就直接搬家到外国,你的所有朋友都留在本国。多年后你终于开通了网络。哇!打开最常用的社交网站,看到了朋友的照片,嗯,他的变化还真大… 通过照片你能得到多少信息?恐怕不会太多。那么再假设你看到的是一段展示了朋友整个变化过程的视频,结婚了什么的…类似于一个简短的传记短片。我敢说第二种情况下你会对朋友的生活有更准确的了解。
数据分析也是如此:拥有的信息越多,对用户行为的评估就越准确。我们可以从发件人的邮件活动中发现趋势,了解发件人的习惯。通过这样的统计,每个用户和IP地址都可以获得一个“可信分”和一个特殊标签。在邮件到达服务器前,主筛选器可以使用该标签筛选出高达70%的垃圾信息。这一比例也证明了声誉服务的重要性,因此需要为该服务提供尽可能高的性能和容错能力。所以在这里我们使用了Tarantool。

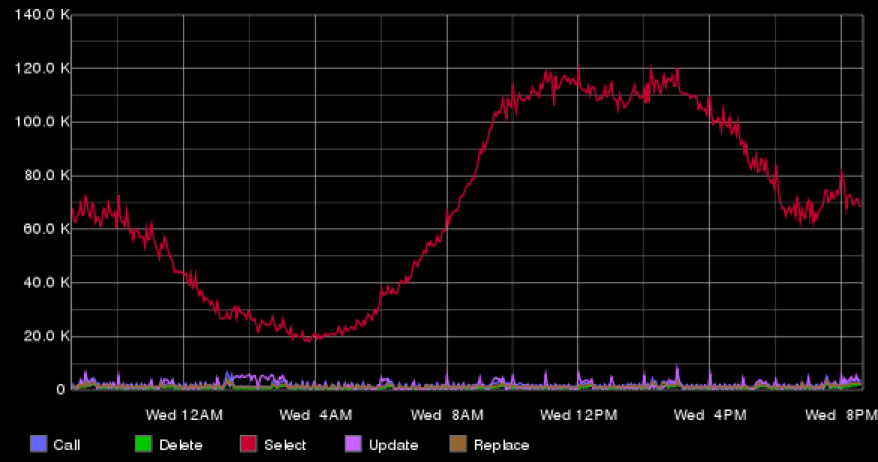
声誉统计信息存储在两台服务器上,每台服务器运行四个Tarantool实例。下图演示了每分钟处理的RepIP请求平均数。

虽然实现了声誉服务,但在Tarantool的配置方面还有几个问题。与上文讨论的系统不同,RepIP/RepUser产生的数据包更大:数据包平均大小为471,97比特(最大为16Kbyte)。从逻辑上来看,数据包由两部分组成:一个小的“基础”部分(标记,相关统计信息),以及一个较大的统计信息部分(每次操作的详细统计状态)。对整个数据包进行寻址需要耗费大量网络资源,进而导致记录的加载和存储时间延长。很多系统只需要数据包中的基础部分,但如何从Tuple中将其分离出来呢(“Tuple”是Tarantool对记录的叫法)?这时候存储过程可以大显身手了。我们在Tarantool的init.lua文件中增加了必要的函数,并从客户端调用这些函数(从1.6版Tarantool开始可以直接用C语言编写存储过程)。
Tarantool 1.5.20版之前存在的问题
不能说使用Tarantool的过程中一帆风顺没有遇到任何问题,问题还是存在的。例如,在一次定期安排的重启动后,(超过500个)Tarantool客户端由于超时无法重新连接。当失败后的下一次重连接企图被延迟更长时间后,我们试过增大超时值,但依然无效。最后发现故障原因在于Tarantool在事件循环的每个周期内对每个请求只能接受一个连接,而当时还有数百个请求在等待。此时有两种解决方法:安装一个新版Tarantool(1.5.20或以上版本),或修改Tarantool的配置(禁用io_collect_interval选项可解决该问题)。Tarantool的开发者很快修复了这个问题,因此使用Tarantool 1.6或1.7将不会再遇到。
RepEntity —实体声誉
我们目前正在集成一个用于存储实体统计信息(链接、图片、附件等)的新组件 — RepEntity。RepEntity的用途类似于上文介绍的RepIP/RepUser:可提供有关实体行为的详细信息,反垃圾邮件筛选器将通过这些信息做决策。借助RepEntity统计信息,可以根据邮件信息的内容筛选出垃圾邮件。例如,某封邮件可能包含可疑的链接(例如包含垃圾邮件内容或指向钓鱼网站),RepEntity可以帮助我们更快速发现并阻止此类内容。怎么做到的?我们可以动态地看到链接内容,检测出行为的变化,这些是“平坦”的计数器做不到的。
除了数据包格式的不同,RepEntity和RepIP系统的基本差别还有:RepEntity会在服务器上造成更高的负载(处理和存储的数据更多,请求数量也更多)。一封邮件信息很可能包含数百个实体(相对的最多可能只包含10个IP地址),对于大部分实体,必须加载并存储包含完整统计信息的数据包。另外要注意的是,数据包是由一个特殊的聚合程序存储的,该程序首先还需要等待生成足够多的统计信息。因此这些操作为数据库系统造成了更多的负载,需要更精确的设计和实施。需要强调一点,(由于项目的某些局限)我们为RepEntity使用了Tarantool 1.5,因此我还将深入介绍这个版本的问题。
首先我们估算了存储所有统计信息所需的内存数量。为了更好地说说明这项工作的重要性,先说几个数据吧:对于预期的工作负载,将数据包的大小增大1字节意味着数据总量将增加1GB。如你所见,我们的任务是以最紧凑的方式将数据存储在Tuple中(上文已经说过,无法将整个数据包存储在一个Tuple中,因为大部分请求只需要后去数据包中的部分数据)。为了计算需要在Tarantool中存储的数据总量,还需要考虑:
- 存储索引所需的额外空间
- 存储Tuple数据容量信息(1字节)所需的额外空间
- Tuple尺寸存在1MB的上限(1.7版请参阅:http://tarantool.org/doc/book/box/limitations.html)
不同请求(读取、插入、删除)数量的增加使得Tarantool频繁遇到超时错误。通过调查发现对于频繁的插入和删除操作,Tarantool会发起一个复杂的过程以实现树的再平衡(所有索引均为TREE类型)。Tarantool中的树索引使用了一种复杂的自平衡逻辑,只有在某些“不平衡”条件满足后才能发起。因此当一个树变得“足够不平衡”后,Tarantool会发起再平衡过程,并使得Tarantool开始变得卡顿。在日志中发现类似资源暂时不可用(错误号:11)的错误信息会每隔几秒出现一次。出现这些错误时客户端无法获得所请求的数据。Tarantool团队的同行提出了一个解决方案:试着使用不同类型的树索引,例如AVLTREE,这种索引可在每次插入/删除/更改操作后重平衡。实际上虽然再平衡操作的调用次数虽然增加,但总开销反而降低了。更新架构并重启动数据库后问题成功解决。
在过时数据的清理方面也遇到了问题。遗憾的是,Tarantool(据我所知至少1.7版还是如此)不允许为某些记录定义TTL(存活时间),甚至彻底忘了这个问题,而是将所有清理操作委派给数据库处理。不过可以自行使用Lua和box.fiber实现所需的清理逻辑。好的一面来说,这样可获得更大灵活性:可以定义复杂的清理条件,而不仅仅是简单的TTL。然而为了恰当地实现清理逻辑,还需要了解其中一些细微差异。
我实现的第一个清理纤程(Fiber)让Tarantool慢到无法忍受。实际上我们所能删除的数据量相比记录总数小很多,为减小适合删除的记录总数,使用自己需要的字段构建了一个辅助索引。随后实施了一个纤程对所有符合条件的记录(其Last-modified时间戳早于指定的时间戳)进行遍历,并检查其他清理条件(例如记录目前是否设置有“write-in-progress”标记),如果所有条件都满足,纤程会删除该记录。
在零负载环境中测试这个逻辑时,一切都能正常工作。在低负载环境下效果也不错。但在将负载增大到预期规模的一半后遇到问题了。发出的请求开始出现超时错误。我知道必须对某些地方进行调优了。随着进一步研究发现自己对纤程的工作原理理解有误。我本来认为纤程是一种独立线程,不会对客户端请求的接收和处理产生影响(上下文切换除外)。但很快发现我的纤程使用了与处理请求的线程相同的事件循环。因此在一个周期内针对大量记录进行迭代但什么都不删除,导致事件循环受阻,无法继续处理客户端请求。
为什么上文要提到删除操作?每次删除某些记录时,都会Yield一个操作取消对事件循环的阻塞以便开始处理下一个事件。因此我决定,如果已经执行了N次操作(其中N代表按照经验推断的值,此处取N=100)但没有Yield,随后有必要强制进行Yield(例如使用wrap.sleep(0))。
另外需要注意,删除记录会触发索引更新,因此在对记录进行迭代时可能会漏掉某些需要删除的数据。这种问题也有解决方案。在一个周期内,可以选择少量元素(不超过1000个)并对其进行迭代,删除需要删除的数据,并继续对剩余的未删除元素进行监视。下一次迭代时,可以选择另一小批元素并从最后一个未删除的元素开始迭代。
我们还试着实现另一种解决方案,以便在未来进行更平滑的重新分片(Resharding),但这次尝试失败了:所实现的机制会产生巨大的开销,因此目前暂时放弃了重新分片操作。希望在新版Tarantool中可以顺利实现该功能。
关于性能有如下的建议:
可以通过禁用*.xlog文件的方式改善Tarantool的性能,但要注意,这样会让Tarantool只能充当缓存,并受到各种后续局限(缺乏复制机制,重启动后冗长的热身期)。为了解决该问题可以立刻创建一个快照,然后在需要时使用快照还原数据。
如果一台计算机上运行了多个Tarantool实例,可以将每个实例“锁定”到某一CPU核心,借此可改善性能。尽管如此,假设你有12个物理核心,一开始就使用12个实例是更好的做法,因为除了执行线程本身,每个Tarantool实例还有一个WAL线程。
我们希望Tarantool能具备这些功能:
- 分片(Sharding)。
- 基于群集的方法以及简单易用的动态群集配置,例如,如果节点故障需要增加节点,能够提供类似MongoDB(mongos)和Redis(Rredis sentinel)的做法。
- 可以针对记录的清理定义TTL(存活时间)。
结论
Tarantool是我们反垃圾邮件系统的基石,我们的很多高负载服务也基于该产品。通过预创建的连接器,用户可以轻松地将Tarantool与不同编程语言实现的组件相互集成。Tarantool拥有久远的成功历史:多年来一直在我们的反垃圾邮件项目中使用Tarantool,在运行和稳定性方面从没遇到过大问题。但为了更充分地利用该数据库系统,还需要考虑配置上的一些细节差异(这里说的是 Tarantool 1.5 版的细节)。
关于未来的计划,简单来说是这样的:
- 增加项目中使用Tarantool的服务数量。
- 迁移至 Tarantool 1.7。
- 开始使用Vinyl引擎,尤其需要应用给RepEntity,该系统中非常“热”的数据其实并不多。
作者:Dmitriy Kalugin-Balashov,阅读英文原文:The Cat-And-Mouse Story Of Implementing Anti-Spam For Mail.Ru Group’s Email Service And What Tarantool Has To Do With This
