@liuhui0803
2016-06-29T05:32:26.000000Z
字数 4092
阅读 3052
Facebook视频直播如何面对80w+并发观众
Facebook 体系结构 设计 FacebookLive
了解如何构建全球规模分布式服务的公司,其数量甚至比拥有核武器的国家数量还要少。Facebook就是这样的一家公司,该公司最新发布的视频直播服务Facebook Live正是这样一种全球规模的服务之一。
Facebook的CEO Mark Zuckerberg认为:
我们做了一个重大决定,打算将视频方面的工作重心转向在线直播视频领域,因为相比过去五到十年来大家将视频上传网上,视频直播是一种新兴的形式...我们开始步入视频领域全新的黄金时代。过去五年来,人们每天在Facebook观看和分享的内容大部分都是视频,这一点丝毫不会让人感到惊讶。
如果从事广告行业,还有什么能比通过永无止境,随时扩展,自由创建的方式为观众提供广告内容更能让人激动的?Google为以指数形式扩张的互联网提供广告业务也正是利用了这样的经济意义。
Facebook视频直播服务有一个绝佳的范例,在一段45分钟的视频里,两个人用橡皮筋勒爆了一只西瓜。峰值时期这个视频吸引了超过800,000人同时观看,并获得超过300,000条评论。面对超过15亿人组成的社交网络,很容易实现这种规模的病毒式传播。
相比而言,2015年超级碗的观众总数1.14亿人,在线直播观众数均值为236万。2015年E3展会期间Twitch的观众数峰值为840,000人。9月16日美国共和党辩论的在线直播并发观众数峰值为921,000人。
Facebook的技术水平确实高高在上。另外需要注意,大家观看那段西瓜视频的同时,还有很多用户在通过Facebook观看大量其他在线视频。
Wired一篇文章引用了Facebook首席产品官Chris Cox的话,据他称,Facebook:
有超过一百位员工正在从事与视频直播有关的工作。(该项目最初大约有12人,现在已经有超过150名工程师)
必须能在不崩溃的情况下为数百万个并发直播*提供支撑。
必须能为同一个直播视频的数百万并发观众提供支撑,同时必须为全球不同供应商的不同设备提供无缝的视频直播。
Cox认为“最后发现这是对基础结构提出的一个巨大挑战。”
如果能深入了解这个基础结构挑战是如何解决的岂不是很有趣?那就继续读下去吧!
Facebook网络流量团队主要负责开发用于驱动Facebook CDN和全球负载平衡系统的缓存软件,来自该团队的Federico Larumbe最近做了一场很棒的演讲:Facebook Live的缩放,他在其中分享了一些视频直播服务的细节。
我对这些内容的注解如下。这真是让人印象深刻。
故事的起源
Facebook Live是一项新功能,可供用户实时分享视频内容(注意,这只是Facebook众多功能之一)。
2015年4月发布的Live服务最初只能由社会名流通过Mentions应用使用,借此与粉丝展开互动。
随后经历了长达一年的产品完善和协议迭代。
最初使用HLS(HTTP Live Streaming)协议,iPhone可支持该协议,并且这个协议可以充分支持现有的CDN体系结构。
同时他们还开始研究RTMP(Real-Time Messaging Protocol)这种基于TCP的协议。通过这种协议可以将视频流和音频流从手机发送到Live Stream服务器。
优势:RTMP在广播方和观众之间的端到端延迟更低,在用户需要相互交互的互动广播方面这一点很重要。更低的延迟和不到几秒钟的时延让体验大为不同。
劣势:需要具备一整套全新的体系结构,因为该协议并非基于HTTP的。为了实现规模化,还需要开发一套新的RTMP代理。
此外他们还考虑过MPEG-DASH(Dynamic Adaptive Streaming over HTTP)。
优势:相比HLS其存储空间利用率可提高15%。
优势:支持自适应视频码率,可根据网络吞吐量动态调节编码质量。
该服务于2015年12月在十多个国家上线。
直播视频有大不同,会产生新问题
上文提到的西瓜视频造成了这样的一种流量模式:
首次增幅非常陡峭,每秒请求数在几分钟内就超过了100次,并且在视频播放完毕之前还在持续增加。
随后流量大幅降低。
换句话说,流量呈现出“尖峰”模式。
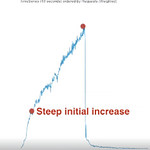
直播视频与普通视频的不同之处在于:会造成“尖峰”模式的流量。
相比普通视频,直播视频更容易产生3倍以上的访问量。
直播视频通常会出现在用户“消息源”的最顶端,因此被访问的概率更高。
每个公众页面的所有粉丝会收到通知消息,这群人很可能也会观看这些视频。
“尖峰”流量会导致缓存系统和负载平衡系统遇到问题。
缓存的问题
可能有很多人希望同时观看直播视频,这就是经典的惊群(Thundering Herd)问题。
尖峰流量的模式会给缓存系统造成极大压力。
视频内容会拆分为多个一秒时长的片段,遇到尖峰流量时,提供这些片段的服务器可能会过载。
全球负载平衡的问题
Facebook具备遍布全球的入网点(PoP),Facebook的流量遍布全球。
防止尖峰流量造成PoP过载,这是一个很大的挑战。
体系结构概览
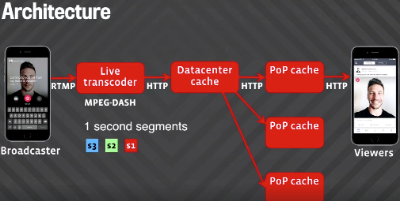
直播视频是这样通过一位广播者播放给数百万观众欣赏的:
广播者通过手机启动视频直播。
手机将一条RTMP视频流发送给Live Stream服务器。
Live Stream服务器对视频解码,并转码成不同码率。
每个码率的版本可持续生成一秒时长的一系列MPEG-DASH片段文件。
片段存储在数据中心缓存内。
缓存的片段从数据中心发送至遍布全球的入网点缓存内(PoP缓存)。
播放端的观众收到一条Live Story。
观众设备上的播放器开始以每秒一个的速度从PoP缓存获取视频文件片段。
如何进行缩放?
数据中心缓存和多个PoP缓存之间存在相乘关系,用户访问的是PoP缓存而非数据中心缓存,全球分布着大量PoP缓存。
此外每个PoP内部也存在这相乘的关系。
PoP内部分为两层:一层HTTP代理,以及一层缓存。
观众通过HTTP代理请求视频片段,随后代理会检查该片段是否位于缓存中。如果位于缓存中,可直接将片段返回给观众;如果不在缓存中,则会向数据中心发出该片段的请求。
不同的片段存储在不同缓存中,借此通过多个缓存主机实现负载平衡。
保护数据中心防范惊群问题
如果所有人在同一时间请求同一个片段会怎样?
如果片段不在缓存中,每个观众只会向数据中心发送一个请求。
请求合并(Request Coalescing)。通过为PoP缓存添加请求合并,可减少请求的数量,只有第一个请求会被发送至数据中心,在收到第一个请求的响应并将数据发送给所有观众前其他请求会被暂挂。
为避免热服务器问题(Hot Server problem)为代理增加了一个新的缓存层。
如果将需要某一片段的所有观众发往同一个缓存主机,该主机可能会过载。
代理增加了一个缓存层。只有发往代理的第一个请求可以实际创建到缓存的请求,其他所有请求可以直接通过代理获得响应。
PoP依然处于风险中 – 可通过全球负载平衡加以缓解
面对惊群问题,数据中心可以获得妥善保护,但PoP依然处于风险中。问题在于视频直播的“尖峰”实在是太大了,PoP可能会在负载到达负载平衡器前就已过载。
每个PoP的服务器和连接数有限,如何预防“尖峰”导致的PoP过载?
通过一个名为Cartographer的系统将互联网子网映射到PoP。该系统可以衡量每个子网和每个PoP之间的延迟,这就是所谓的延迟衡量。
每个PoP的负载都会被衡量,每个用户会被发送至具备足够容量,距离最近的PoP。代理包含对所接收的负载进行衡量的计数器,这些计数器可进行聚合汇总,这样就可以知道每个PoP的负载情况。
在容量的局限和最小化延迟方面还需要进行优化。
控制系统本身的衡量和回应也存在延迟。
将负载的衡量窗口从原本的1.5分钟缩短至3秒,但依然存在一个3秒的窗口。
为此需要在实际发生之前对负载进行预测。
通过实施容量估算程序,可以从每个PoP之前的负载和当前的负载推断出将来的负载情况。
如果负载正在增加,估算程序如何预测负载何时降低?
此时为插值(Interpolation)函数使用了三次样条函数(Cubic splines)。
首先执行一阶和二阶导数。速度为正值意味着负载正在增加,加速度为负意味着速度增速正在下降,最终将归零并开始降低。
三次样条函数可以比线性插值(Linear interpolation)预测出更为复杂的流量模式。
避免摆动。这个插值函数还解决了摆动的问题。
衡量和回应所存在的延迟意味着作为决策依据的数据不够新。插值可以减少错误做出更精确的预测,并能降低摆动。这样负载才能更接近目标容量。
目前预测工作是基于最新的三个区间做出的,每个区间时长30秒,几乎可以代表负载的瞬时状况。
测试
首先需要让PoP过载。
为了模拟直播流量开发一个负载测试服务,并将其分布至全球PoP中。
可以模拟生产负载10倍的环境。
可以模拟一位观众一次请求一个视频片段。
该系统帮助Facebook发现并解决了容量估算程序中存在的问题,能借此对参数进行微调,并可验证缓存层解决了惊群问题。
上传的可靠性
实时上传视频这个操作本身就充满挑战。
例如,某次上传可能只有100-300Kbps的可用带宽。
音频需要64Kbps的吞吐率。
标清规格视频需要500Kbps的吞吐率。
手机上可以使用自适应编码技术应对视频和音频吞吐率不足的问题。视频编码时的码率可以根据可用网络带宽进行调整。
为了确定上传的码率,手机会衡量RTMP连接的上传速度,并与上一个区间的结果取加权平均值。
未来的发展方向
- 不再使用请求拉取机制,而是研究一种推送机制,利用HTTP/2在视频片段被请求之前将其推送至PoP。
相关文章
Gamoloco追踪1476093个频道的直播视频统计信息。
