@liuhui0803
2016-10-19T08:12:07.000000Z
字数 3640
阅读 3619
降低领英私有云的MTTD和MTTR
ESPRESSO Kafka 性能 LPS Voldemort
摘要:
领英内部使用了一个名为Nuage的云平台管理门户。Nuage本身也是一种分布式系统,包含分布在多个数据中心内的数个前端和后端。与其他任何分布式系统类似,这个系统的调试不仅困难而且需要耗费大量时间。领英通过日志汇总、请求标记,以及用户体验异常报表等方式改善该系统的MTTD和MTTR,本文将介绍他们的具体做法。
正文:
我们将领英内部的云管理门户称之为Nuage(法语中的“云”)。领英的开发者可以借此快速在领英的数据中心内新建数据存储,例如Kafka话题、Voldemort存储,以及Espresso数据库等。该产品包含一个供领英的开发者使用的HTTP前段,以及一个与Kafka等底层系统通信的rest.li后端服务。
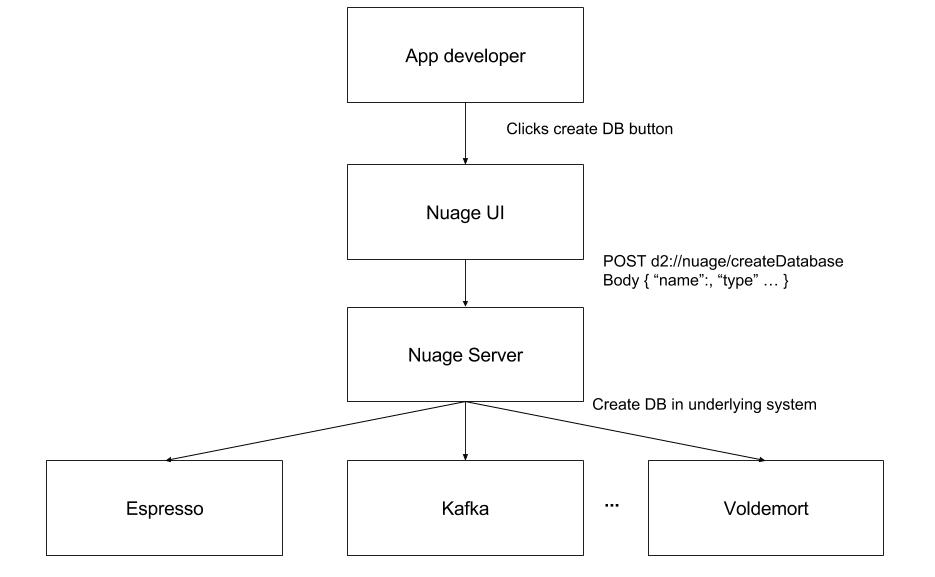
与领英的底层存储和流系统类似,Nuage本身也是一种分布式系统,包含分布在多个数据中心内的数个前端和后端。与其他任何分布式系统类似,这个系统的调试不仅困难而且需要耗费大量时间。对于某些事件,可能需要找到每个服务涉及到的所有相关计算机,从这些计算机中读取特定时段内的日志,然后进行汇总和分析。具体到Nuage则需要找到相关数据中心,确定该数据中心内有关的前端和后端计算机,然后提取特定时段内的日志。
为了简化Nuage系统的调试并降低平均恢复时间(MTTR),我们执行了日志汇总、请求标记,以及用户体验异常报表等工作。下文将介绍日志汇总的相关设置,但首先想谈谈请求标记和用户体验异常报表,因为这些是进行日志汇总的前提条件。
请求标记和异常报表
如上文所属,Nuage包含运行在不同宿主机上的前端和后端服务。为了简化调试工作,我们希望能轻松地将前端和后端事件信息关联在一起。为此我们会在前端生成一个随机的请求ID,将其作为HTTP标头传递给Nuage后端。前端会在日志中记录发送至后端的请求(包括请求ID)以及所获得的响应。在收到传入的请求后,后端会检查HTTP标头中的请求ID,并将该请求ID添加至所关联的每一条日志信息中。后一个操作是通过log4j的映射诊断上下文环境(Mapped Diagnostic Context,MDC)实现的。MDC实际上是一种“每线程”的映射,可以在日志输出格式化程序(Formatter)中引用。这样我们就可以将请求ID包含在与该请求有关的每一条日志项中,借此可解决一系列问题:
- 当有多个线程同时写入日志时,可以更简单地判断每条日志项与哪个请求有关。
- 使用Grep命令在日志中查找请求ID可找到所有相关日志项。
- 可以更方便地分析请求ID并将其插入Elasticsearch中一个独立的列,具体做法请参阅下一节。
Webserver.java – 为请求对应的线程加入请求ID。
import org.apache.log4j.MDC;public void onRequest(request) {String requestId = request.get(“x-req-id”);MDC.put(“requestId”, requestId);}
Log4j.xml – 将请求ID写入每条日志项。
<layout class="org.apache.log4j.PatternLayout"><param name="ConversionPattern" value="%d{yyyy/MM/dd HH:mm:ss.SSS} [req-id-%X{requestId}] ..." /></layout>
日志范例

除了这些宝贵的信息外,我们还设置了在前端或后端遇到非预期异常后向我们发送邮件通知,并在通知中包含方便进行调查所需的细节信息。选择邮件作为通知方式是因为这些异常本身没必要让我们立刻着手处理,现有的其他警报机制即可应对各种紧急问题。从下文的邮件范例中可以看到,我们可以直观地看到前端和后端的堆栈跟踪情况。邮件中还包含了触发这一异常的请求所对应的请求ID,这样就可以更容易地找到日志中的所有相关日志项。
用户遇到异常后发送给Nuage开发团队的邮件范例。
Nuage发现了非预期异常收件人:nuage-debugging请求ID:123456用户:lideveloper前端信息所发送请求:Rest.li端点:d2://nuage ...后端信息响应:创建Voldemort存储XYZ时出现异常...状态代码:500
这样的设置已被证明在降低我们的平均检测时间(MTTD)方面非常有用。我们不再依赖用户上报自己使用前端过程中遇到的问题,可以在问题发生后立刻开始进行调试。借助邮件中包含的信息,我们可以通过下文将要介绍的Elasticsearch、Logstash和Kibana(ELK)快速着手深入分析。
使用Elasticsearch、Logstash和Kibana(ELK)进行日志汇总
ELK堆栈使得我们可以将来自多个产品和宿主机的日志汇总在一起并进行集中搜索,借此可实现很多用例,例如可以回答注入“错误X的发生频率和每次发生位置是什么”或“上周以来异常率有何变化”等问题。ELK各种组件的用途如下:
- Elasticsearch:底层数据库;
- Logstash:将日志解析为结构化格式并将其放入Elasticsearch;
- Kibana:一种对Elasticsearch数据进行可视化的Web UI。
Logstash可以在应用程序服务器上运行,或读取其他来源的日志。我们在领英内部的用法通常是在运行应用程序的服务器上使用Kafka生成器(Producer)发送日志,随后由Logstash使用Kafka消耗器(Consumer)读取日志,并在解析后将其发送至Elasticsearch集群。由于日志可以在其它计算机上处理,这种做法可以降低对服务器的影响。下图展示了Nuage的ELK工作流。
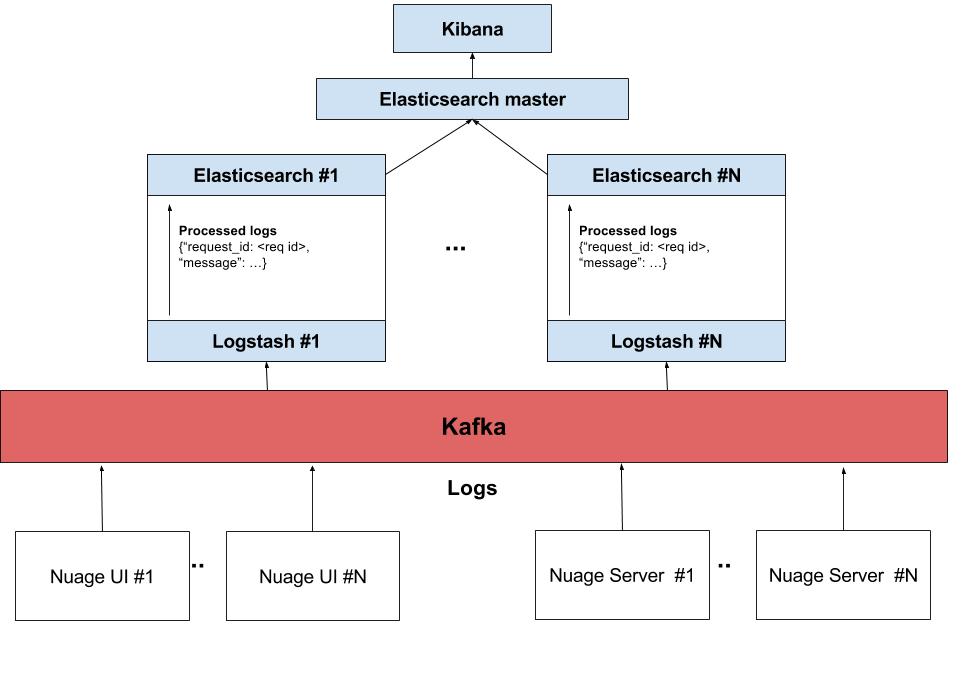
作为我们Logstash配置的一部分,我们会通过解析日志找到请求ID并将其以一个单独的字段发送至Elasticsearch的日志行中。
Logstash – 解析日志行并将请求ID放入相应字段。
# Add the request ID to a separate field if one is present.grok {match => ["message", "\[req[\-]id[\-]%{POSINT:request_id}\]$"]}
借助这样的设置,直接在Kibana仪表盘中输入类似“request_id: ”这样简单的查询即可从前端和后端计算机获得与该请求有关的所有相关日志,这一过程中甚至不需要知道这个请求是由哪台计算机处理的。由于不再需要确定运行请求的计算机,无需通过Grep命令查找特定计算机的日志,无需确定特定请求相关的其他日志行还有哪些,我们的调试过程得以大幅简化,进而显著缩短了我们的MTTR。
Kibana – 从Elasticsearch中获得与前端和后端有关的所有相关日志行。
搜索:request_id: 123456
结果:
| 日期 | 服务 | 宿主机 | 请求ID | 消息 |
|---|---|---|---|---|
| ... | nuage-frontend | host1 | 123456 | 用户lidev正在创建Espresso数据库 |
| ... | nuage-backend | host2 | 123456 | 正在处理来自nuage-frontend的新请求 |
| ... | nuage-backend | host2 | 123456 | 用户lidev被授权创建数据库 |
| ... | nuage-backend | host2 | 123456 | 正在将数据库定义上传至Espresso host3 |
| ... | nuage-backend | host2 | 123456 | 数据库创建失败:到host3的连接超时 |
未来扩展
目前我们只将请求ID与Nuage前端请求和Nuage后端的处理和响应关联在一起。考虑到这个产品的本质,Espresso或Voldemort等底层系统经常会遇到各种异常,因此我们可以对其进行一个简单的改进,让Nuage后端对收到的请求ID进行转发并在底层系统之间进行传递。随后来自该系统的响应也可以附加至调试邮件中,并可以使用ELK,这样我们就可以在前端、后端,以及底层系统中查找与该请求ID有关的所有日志,在调试过程中针对日志信息获得更完整的视图。这就要求所有这些系统的日志必须全部发送至同一个Elasticsearch集群,或能够通过一个Tribe节点与多个Elasticsearch集群通信,这样即可在一个位置查看所有系统的日志。
结论
通过这样的ELK设置和请求标记,我们可以针对遇到的问题轻松查看所有相关日志。通过将这样的能力与包含触发用户体验异常的请求ID的邮件提醒配合使用,我们的私有云管理系统Nuage的MTTD和MTTR均有显著改善。如果你想进一步了解Nuage及其目标,建议阅读Alex Vauthey有关“隐形”基础架构的文章。
作者:Gustaf Helgesson,阅读英文原文:Reducing the MTTD and MTTR of LinkedIn’s Private Cloud
