@liuhui0803
2017-06-26T01:57:27.000000Z
字数 8278
阅读 3797
Yelp是如何无损压缩图片的
前端 图片优化 JPEG
摘要:
Yelp承载了上亿张用户上传的照片,这些图片耗费了应用和网站用户的大量带宽,而图片本身的存储和传输也需要付出不菲成本。为了向用户提供更出色的体验,Yelp一直在努力优化这些照片,目前已经在不牺牲质量的前提下将照片的体积平均减少了30%。借此可以减少用户下载照片所需的时间和带宽,同时存储图片的成本也大幅降低。
正文:
Yelp承载了上亿张用户上传的照片,这些照片从美食到发型,再到我们最新发布的#yelfies功能,涵盖了不同类型的内容。用户通过手机应用或网站下载这些图片需要占用大量带宽,而图片本身的存储和传输也需要Yelp付出不菲的成本。为了改善用户体验,我们一直在努力优化,目前已经将照片的体积平均减少了30%。借此可以减少用户下载照片所需的时间和带宽,同时存储图片的成本也大幅降低。哦,这一切都是在不牺牲照片质量的前提下实现的!
背景信息
Yelp存储着用户过去12年以来上传的所有照片。我们使用了无损格式(PNG、GIF)以及PNG和JPEG等格式,图片存储使用了Python和Pillow等技术。最初照片上传是通过下面这样的代码实现的:
# do a typical thumbnail, preserving aspect rationew_photo = photo.copy()new_photo.thumbnail((width, height),resample=PIL.Image.ANTIALIAS,)thumbfile = cStringIO.StringIO()save_args = {'format': format}if format == 'JPEG':save_args['quality'] = 85new_photo.save(thumbfile, **save_args)
上述代码托管于GitHub:rawstarting_point.py
我们从这些代码着手研究如何优化文件大小,以便在不牺牲质量的前提下缩减图片体积。
优化
首先需要决定这个优化工作是要由我们进行,还是由CDN服务商像变魔术一样代为搞定。考虑到自己很重视内容质量,我们决定自行评估不同选项,并在优化后的文件大小和图片质量之间进行权衡。我们研究了现有的照片文件体积缩减技术,详细了解不同技术使用各种参数后,能对文件大小和照片质量产生的影响。这一研究工作完成后,我们决定主要从三方面着手进行。下文将介绍我们的收获,以及每种优化技术所能实现的效果。
- 对于Pillow技术的改动
- Optimize标记
- 交错式JPEG
- 对于应用程序中照片逻辑的改动
- 大型PNG检测
- 动态JPEG质量
- 对于JPEG编码器的改动
- Mozjpeg(栅格量化、自定义量化矩阵)
对于Pillow技术的改动
Optimize标记
这是最容易的改动:以CPU时间为代价,修改Pillow中有关文件大小缩减的设置选项(optimize=True)即可。这种方式完全不会影响图片质量。
对于JPEG,该标记可以让编码器扫描每张图片时额外多扫描一次,借此确定最优化的霍夫曼编码方式(Huffman coding)。每次首轮扫描并不直接写入文件,而是会计算每个值的出现机率,通过这些必要信息确定最理想的编码方式。PNG格式自身使用了zlib,此时Optimize标记实际上会让编码器使用gzip -9代替gzip -6。
做出这一改动很容易,但后来发现这并不是万能药,只能实现几个百分点的“瘦身”。
交错式JPEG
在将图片保存为JPEG格式时,可以选择多种不同的保存类型:
- 从上至下按顺序加载的基准JPEG(Baseline JPEG)。
- 从模糊状态逐渐变清晰的交错式JPEG(Progressive JPEG)。我们可以直接在Pillow中启用交错式选项(
progressive=True),随后性能有了较大改观(毕竟相对对于图片没有完整显示,不锐利的图片远不那么容易察觉)。
另外交错式文件的打包方式也能略微减小文件体积。具体原因请参阅这篇维基百科文章,JPEG格式使用了一种8x8“Z字”模式排列的像素实现熵编码。当解包这些像素块的值并按顺序排列时,通常首先会获得一个非零数字,随后会获得一系列“零”,整张图片中每个8x8像素块都需要反复交替完成这样的模式。但在交错式编码方式中,像素块的解包顺序变了。每个块中较大值的数字会位于文件前方(借此实现交错式图片最开始所显示的“粗略图”),随着越来越多值更小的数字,以及更多“零”逐渐丰富细节,最终显示出清晰的原图。这种对图片数据重新排序的方式不会改变图片本身,但会增加每一行中“零”的个数(不过也可以更轻松地进行压缩)。
我们通过用户上传的甜甜圈照片来对比一下这两种方式(点击可查看大图):

模拟的基准JPEG渲染方式。

模拟的交错式JPEG渲染方式。
对应用程序照片逻辑的改动
大型PNG检测
在保存用户生成的内容时,Yelp主要使用两种图片格式:JPEG和PNG。JPEG是一种适合照片的格式,但不能很好地用于高对比度的设计类内容(例如徽标)。PNG是完全无损的,很适合用来保存各种设计图,但如果用来存储细微失真无法察觉的普通照片,会产生巨大的文件。如果用户上传了PNG格式的照片图,识别此类图片并将其转换为JPEG格式,便可以节约宝贵的存储空间。Yelp上最常见的PNG格式照片主要是移动设备截取的屏幕截图,以及通过应用为照片增加特效或边框后的产物。
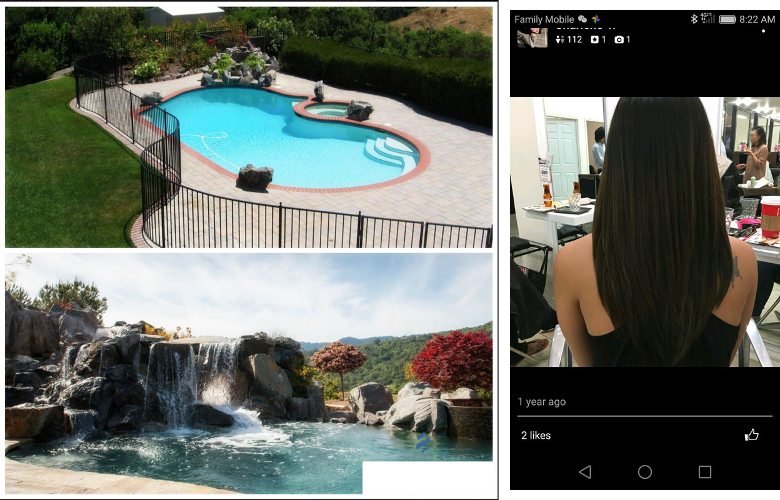
(左侧)包含徽标和边框,典型的复合型PNG图片。(右侧)以屏幕截图方式上传的典型的PNG图片。
我们希望减少这种不必要的PNG图片数量,但更重要的是,同时不能太过火,以至于更改了徽标、设计图等内容的格式或降低了它们的质量。如何判断图片是否是照片?通过像素吗?
通过使用2,500张样本图片做实验,我们发现根据文件大小与独特的像素特征可以很好地判断图片类型。我们用最大分辨率为候选图片生成缩略图,然后看输出的PNG文件大小是否会超过300KiB。如果会,随后将检查图片内容,以确定其中是否包含超过2^16种颜色(Yelp会将上传的RGBA图片转换为RGB模式,如果不转换,那么这方面也要进行检查)。
在实验数据集中,这种通过手工调优的阈值来定义“大小”的方式帮助我们将文件体积缩小了88%(等同于转换所有图片格式后预期实现的节约),同时没有因为任何误判导致不该转换的图形内容被转换成JPEG。
动态JPEG质量
对于JPEG文件来说,首先想到,也最著名文件瘦身方式是一个名为quality的选项,很多应用程序保存JPEG格式的图片时,支持为该选项设置代表不同质量的数值。
然而质量是一种很抽象的概念。实际上,一张JPEG图片的每个颜色通道都可以分别设置不同质量。0 - 100的质量数值可映射至每个颜色通道不同的量化表,决定了最终会损失掉的数据量(通常损失的是高频数据)。在数字信号领域,量化这个词实际上代表着必然会导致信息丢失的JPEG编码过程。
降低文件体积最简单的办法是降低图片质量,引入更多噪音。然而就算相同质量级别,也不意味着每张图片都会损失同样数量的信息。
我们可以针对每张图片的优化情况动态地选择质量设置,在质量和文件大小之间找到一个最佳平衡点。为此我们使用了两种方法:
- 自下至上:这种算法可以在8x8像素块的层面上处理图片,据此生成适当的量化表。该算法会同时计算理论上质量的损失程度,以及损失的这些数据能否放大或抵消在人眼看来更容易或更不易察觉的损失。
- 自上至下:这种算法可将优化后的整张图片与优化前的原始版本进行对比,借此判断将会丢失多少信息。通过使用不同质量设置以迭代的方式生成多个候选图片,我们可以选择一个在所选的任何评估算法看来损失最小的版本。
我们评估了一种“自下至上”的算法,但感觉在质量方面无法满足我们的高要求(不过看起来该算法对于中等质量要求的图片还是很适合的,这种情况下为了获得更小的体积,编码器可以丢弃更多数据)。九十年代早期,当时的计算能力还不怎么充足,围绕这一领域有很多学术性的研究论文,当时学界走了另一种捷径,例如不对不同像素块之间的影响进行评估。
因此我们采取了第二种方法:使用二等分算法生成不同质量级别的候选图片,并使用pyssim计算其结构相似性(SSIM),借此对每个候选图片的质量下降程度进行评估,直到最终确定一个可配置,但可提供一致质量标准的值。这样就可以选择性地降低图片的平均文件大小(以及平均质量),同时确保质量的降低不会被人眼所察觉。
下图中列出了2500张样本图片通过3种不同质量方法得出的SSIM值。
- 蓝线代表当前方法产生的原始图片,其设置为
quality = 85。 - 红线代表降低文件大小的备选方法,其设置为
quality = 80。 - 最后,橙线代表我们最终选择的动态质量设置,
SSIM 80-85,我们会选择满足或超过SSIM比值范围的图片,具体为质量介于80至85(含)之间的图片,而这个比值是一个预先计算出来的静态值,借此可确保只针对质量介于该范围之间的图片进行转换,这样便可以在不降低质量最低图片的质量同时降低文件平均大小。
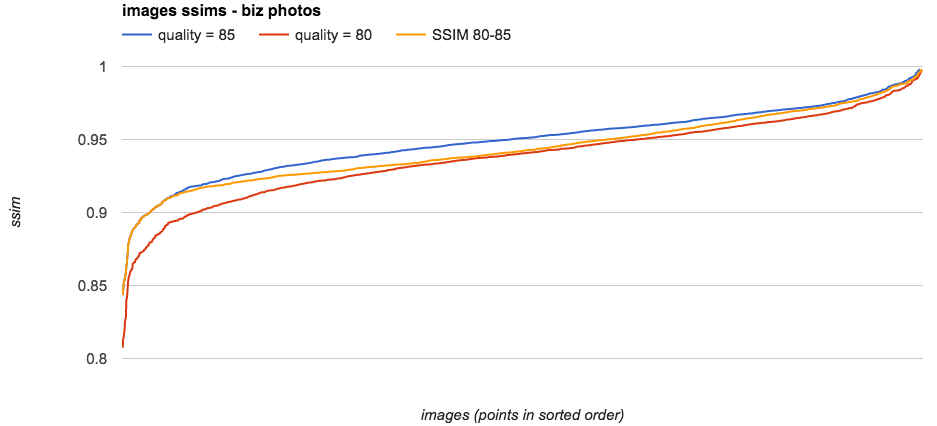
对2500张图片使用3种不同策略后得到的SSIM。
SSIM?
有不少图片质量算法会试图模拟人类的视觉系统。我们评估了其中的很多算法,认为SSIM虽然比较老,但最适合这种迭代式优化,因为它具备下列这些特征:
- 对JPEG量化误差敏感
- 算法足够快速、简单
- 可以通过PIL原生图像对象的方式计算,无需将图片转换为PNG并传递至CLI应用程序(参见第二条)
动态质量代码范例:
import cStringIOimport PIL.Imagefrom ssim import compute_ssimdef get_ssim_at_quality(photo, quality):"""Return the ssim for this JPEG image saved at the specified quality"""ssim_photo = cStringIO.StringIO()# optimize is omitted here as it doesn't affect# quality but requires additional memory and cpuphoto.save(ssim_photo, format="JPEG", quality=quality, progressive=True)ssim_photo.seek(0)ssim_score = compute_ssim(photo, PIL.Image.open(ssim_photo))return ssim_scoredef _ssim_iteration_count(lo, hi):"""Return the depth of the binary search tree for this range"""if lo >= hi:return 0else:return int(log(hi - lo, 2)) + 1def jpeg_dynamic_quality(original_photo):"""Return an integer representing the quality that this JPEG image should besaved at to attain the quality threshold specified for this photo class.Args:original_photo - a prepared PIL JPEG image (only JPEG is supported)"""ssim_goal = 0.95hi = 85lo = 80# working on a smaller size image doesn't give worse results but is faster# changing this value requires updating the calculated thresholdsphoto = original_photo.resize((400, 400))if not _should_use_dynamic_quality():default_ssim = get_ssim_at_quality(photo, hi)return hi, default_ssim# 95 is the highest useful value for JPEG. Higher values cause different behavior# Used to establish the image's intrinsic ssim without encoder artifactsnormalized_ssim = get_ssim_at_quality(photo, 95)selected_quality = selected_ssim = None# loop bisection. ssim function increases monotonically so this will convergefor i in xrange(_ssim_iteration_count(lo, hi)):curr_quality = (lo + hi) // 2curr_ssim = get_ssim_at_quality(photo, curr_quality)ssim_ratio = curr_ssim / normalized_ssimif ssim_ratio >= ssim_goal:# continue to check whether a lower quality level also exceeds the goalselected_quality = curr_qualityselected_ssim = curr_ssimhi = curr_qualityelse:lo = curr_qualityif selected_quality:return selected_quality, selected_ssimelse:default_ssim = get_ssim_at_quality(photo, hi)return hi, default_ssim
上述代码托管于GitHub:dynamic_quality.py。
对于这种技术还有其他几篇博客文章介绍,这里有一篇Colt Mcanlis撰写的文章,在我们发布本文的同时,Etsy也发布了一篇文章!大家都在努力塑造更快的互联网,鼓掌!
对于JPEG编码器的改动
Mozjpeg
Mozjpeg是libjpeg-turbo的开源分支,虽然运行速度较慢,但可以获得体积更小的文件。这种方法很适合通过脱机批处理的方式重新生成图片。虽然相比libjpeg-turbo需要多用大约3倍-5倍的计算时间,但这种开销较高的算法可以获得更小的图片!
Mozjpeg最大的不同之处在于,可以使用可替换的量化表。正如上文所述,质量是一种抽象概念,需要对每个色彩通道应用量化表。各种迹象表明,默认的JPEG量化表实际上并不是最优的。JPEG规范中提到:
这些表仅供示范,可能并不总能适合每个具体的应用程序。
那么得知大部分编码器实现都使用了这些量化表后,你应该不会太吃惊了…… 🤔🤔🤔
我们针对Mozjpeg的基准测试使用了其他备选表,随后选择使用效果最好的常规用途备选量化表来创建图片。
Mozjpeg + Pillow
大部分Linux发行版默认装有libjpeg,因此默认情况下无法在Pillow中使用mozjpeg,不过好在只需简单地修改配置就能搞定。在构建mozjpeg时,请使用--with-jpeg8标记,并确保它可被Pillow找到并链接。如果使用了Docker,可以使用类似下面这样的Dockerfile:
FROM ubuntu:xenialRUN apt-get update \&& DEBIAN_FRONTEND=noninteractive apt-get -y --no-install-recommends install \# build toolsnasm \build-essential \autoconf \automake \libtool \pkg-config \# python toolspython \python-dev \python-pip \python-setuptools \# cleanup&& apt-get clean \&& rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*# Download and compile mozjpegADD https://github.com/mozilla/mozjpeg/archive/v3.2-pre.tar.gz /mozjpeg-src/v3.2-pre.tar.gzRUN tar -xzf /mozjpeg-src/v3.2-pre.tar.gz -C /mozjpeg-src/WORKDIR /mozjpeg-src/mozjpeg-3.2-preRUN autoreconf -fiv \&& ./configure --with-jpeg8 \&& make install prefix=/usr libdir=/usr/lib64RUN echo "/usr/lib64\n" > /etc/ld.so.conf.d/mozjpeg.confRUN ldconfig# Build PillowRUN pip install virtualenv \&& virtualenv /virtualenv_run \&& /virtualenv_run/bin/pip install --upgrade pip \&& /virtualenv_run/bin/pip install --no-binary=:all: Pillow==4.0.0
上述代码托管于GitHub:Dockerfile。
这就行了!构建完成后即可在常规图片处理工作流程中配合Pillow使用Mozjpeg。
影响
上述这些改进对我们能产生多大影响?最开始这项研究工作时,我们从Yelp的业务照片中随机选择了2,500个样本,借此通过处理流程来评估不同方法对文件大小的影响。
- 针对Pillow设置的改动将文件大小降低了大约4.5%
- 大型PNG检测机制将文件大小降低了大约6.2%
- 动态质量降低了大约4.5%
- 改为使用Mozjpeg编码器后降低了大约13.8%
总的来说,我们的图片文件平均大小降低了约30%,而这一收效来自于我们规模最大、最常用分辨率的图片,随后用户访问网站的速度更快,而我们每天可以节约TB级别的数据流量。这些措施都已体现在CDN中:
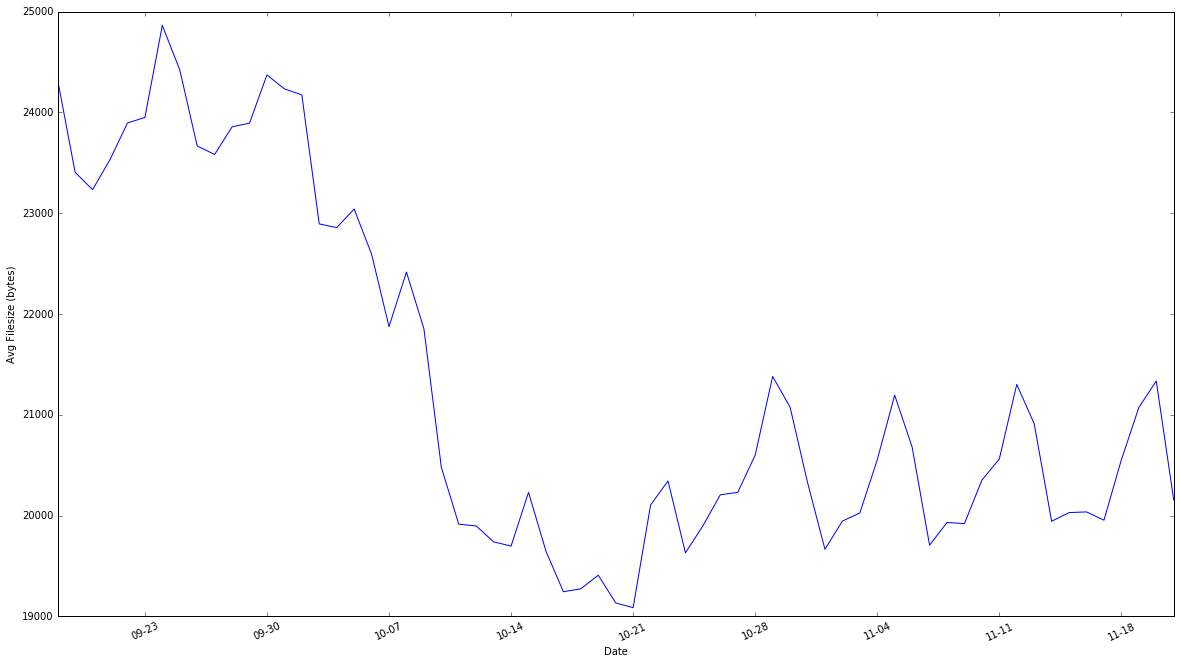
通过CDN衡量的,不同时段的平均文件(图片和非图片静态内容)大小。
我们最终未考虑过的措施
本节主要将介绍一些你可能会考虑使用的,其他用于优化图片的常见措施,但由于我们对工具的选择或出于其他方面的考虑,Yelp并未采取这些措施。
二次采样
二次采样(Subsampling)是一种决定网页图片质量和文件大小的主要因素。网上有很多对该技术的介绍,但就本文来说,我们完全可以说自己已经以4:1:1的方式进行了二次采样(如果不单独指定,这也是Pillow的默认值),因此再次使用该技术不会获得任何效果。
有损PNG压缩
考虑到我们针对PNG的处理方式,选择将部分图片继续保留PNG格式,但使用有损压缩编码器,例如pngmini,这也许是一种合理做法,但我们依然选择将这类图片转换为JPEG。这种备选方式也能提供不错的效果,按照作者的说法,相比原始PNG,可将文件大小降低72-85%。
动态内容类型
按照计划,我们以后肯定会对考虑选择WebP或JPEG2k等更现代化的内容类型。但就算这些构想中的项目顺利实现,依然会有大量长尾用户请求未经优化的JPEG/PNG图片,因此目前的相关努力还是值得的。
SVG
我们网站上很多地方使用了SVG,例如设计师按照我们的风格指南设计的静态资源。虽然这种格式,以及诸如svgo等优化工具可以帮助网页成功减负,但与我们这里所做的工作没太大关系。
有魔法的供应商
很多供应商提供了图片交付/大小调整/裁剪/转码服务,包括开源的thumbor。也许这是改善图片加载速度最简单的办法,但这种方式以及动态内容类型对我们来说还是太新了,也许以后会考虑吧。目前我们依然倾向于选择自行构建的解决方案。
扩展阅读
下面列出的两本书,内容虽然超出了本文的范围,但强烈建议阅读。
作者:Stephen Arthur,阅读英文原文:Making Photos Smaller Without Quality Loss
