@liuhui0803
2018-03-27T01:04:16.000000Z
字数 6427
阅读 3864
数据工程师新手指南——中篇
数据科学 软件开发 创业公司 编程
摘要:
本文探讨了星型架构和数据建模,并介绍了事实表和维度表的差异,以及使用Datestamp作为分区键的优势,尤其是在回填过程中的优势。此外还探讨了Airflow作业的基本结构,并归纳了Airflow中可用的不同类型操作。最后,本文列举了一些与ETL有关的最佳实践。
正文:
本文最初发布于Robert Chang的博客,经原作者授权由InfoQ中文站翻译并分享。阅读英文原文:A Beginner’s Guide to Data Engineering — Part II。
上文回顾
在数据工程师新手指南——上篇中,我介绍过企业的数据分析能力重点在于不同技术层的构建。从原始数据的收集到数据仓库的搭建,再到机器学习技术的应用,我们会发现,数据工程师在所有这些领域中都扮演了极为重要的角色。
对任何数据工程师来说,数据仓库的设计、构建和维护都是最重要的技能之一。上一篇文章中已经定义了数据仓库的概念以及三个通用的操作环节:提取、转换和加载,即ETL。
对于尚不熟悉ETL流程的人,我还介绍了几个流行的开源框架,这些框架都是由诸如LinkedIn、Pinterest、Spotify等公司开发的,此外还重点介绍了Airbnb自己的开源工具Airflow。最后,我还提出了一个结论,数据科学家通过基于SQL的ETL范式可以更有效地掌握数据工程。
本文摘要
上篇的讨论层次较高。在本篇中,我将通过更深入的技术讨论来介绍如何构建足够好的数据管道,并介绍一些有关ETL的最佳实践。下文的内容主要会用到Python、Airflow和SQL。
首先,我将介绍数据建模这个概念,设是一种设计过程,需要通过妥善定义的表Schema和数据关系来反映业务指标和维度。我们还将介绍数据分区,这种操作可以让我们更高效地查询和回填数据。通过阅读本文,大家将理解数据仓库以及管道设计的基本概念。
随后还将详细介绍Airflow作业的概念。大家将了解如何使用传感器(Sensor)、运算符(Operator)以及传输器(Transfer)实施提取、转换和加载过程。本文还将介绍ETL最佳实践,并列举来自Airbnb、Stitch Fix、Zymergen等公司的现实案例作为例子。
通过阅读本文,大家将会更好地理解Airflow的多样性,以及配置即代码这一概念。并且你会发现,实际上Airflow已经内建了大部分本文涉及到的最佳实践。
数据建模
当用户使用诸如Medium这样的产品时,他的头像、已保存的文章以及文章阅读数量等信息都会被系统记录起来。为了向用户提供准确、及时的服务,必须针对在线事务处理(OLTP)这样的需求对产品数据库进行优化。
但如果要开发一个在线分析处理系统(OLAP),具体目标就截然不同了。设计师需要专注于见解的生成,这也意味着分析推论必须能轻松转换为查询,并要能高效地计算出统计学结果。这种“分析为先”的方法通常需要涉及一种名为数据建模的设计过程。
数据建模、规范化和星型架构
这些设计需要进行决策,例如我们通常需要决定哪些表需要进行规范化(Normalized)。一般来说,规范化之后的表,其Schema更简单,包含的数据更加标准化,冗余更低。然而小型表的数量激增同时也意味着如果需要追踪数据之间的关系,我们将需要进行更多工作,同时查询模式也变得更复杂(更多JOIN操作),同时需要维护的ETL管道也更多。
但从另一方面来看,查询去规范化(Denormalized)的表(即Wide表)通常会更简单,因为所有指标和维护都已经预先联结(Join)在一起了。然而因为这种表的尺寸更大,Wide表的数据处理往往更慢,对上游的依赖性更高。这也会使得ETL管道的维护变得更困难,因为相关工作并非模块化的。
为了进行权衡,人们提出了很多设计模式,其中最常用的模式之一,同时也是Airbnb唯一使用的模式,名为星型架构(Star schema)。使用这样的名称,主要是因为表会按照星型的架构进行组织,并能通过类似星型的模式进行可视化。这种设计更重视规范化表的构建,尤其是事实表和维度表。需要时,也可以从这些小型的规范化表构建出去规范化的表。这样的设计方式可以在ETL的可维护性以及分析的易用性之间实现更好的平衡。
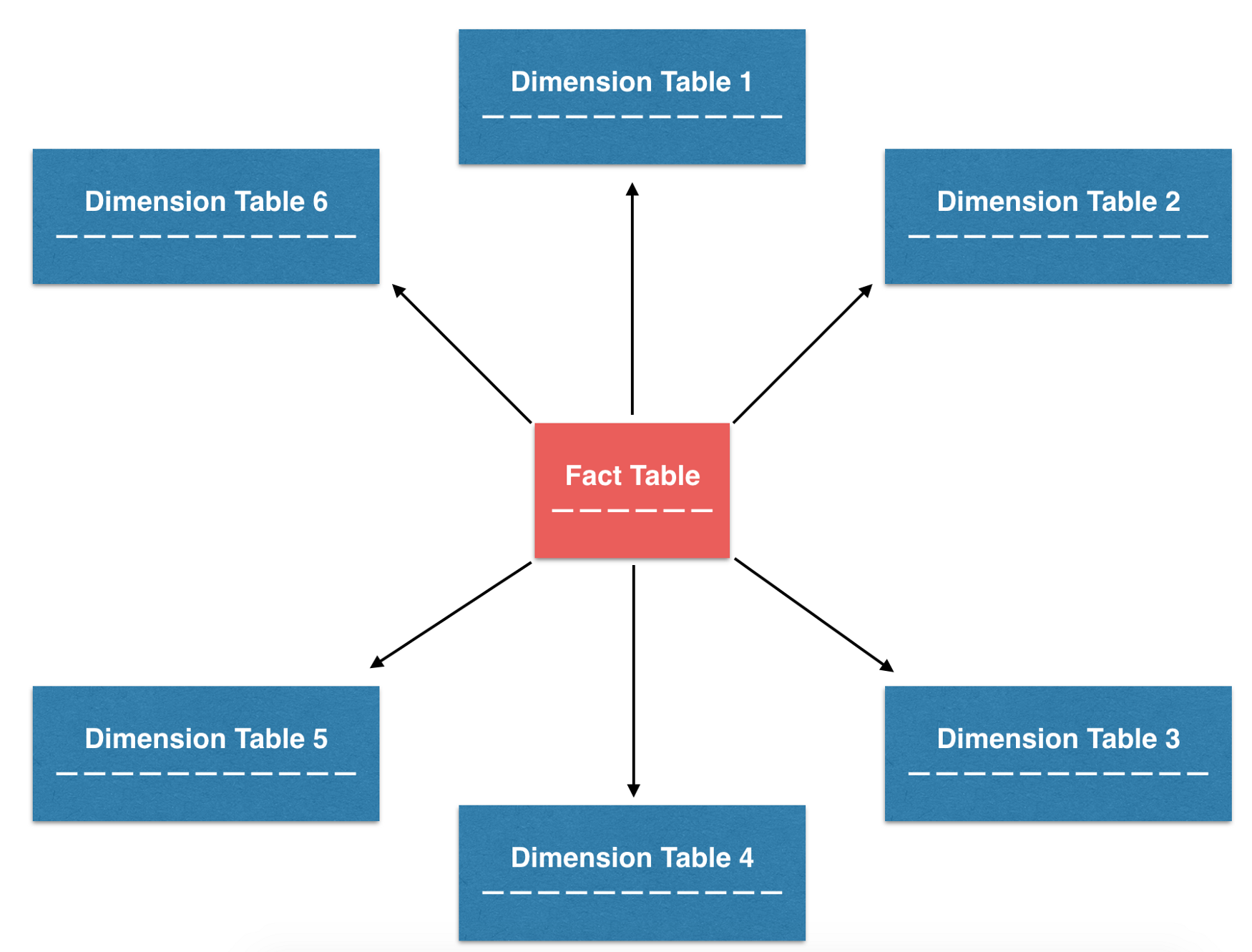
星型架构将表按照星型的方式组织,事实表为核心,维度表环绕四周
事实表和维度表
为了理解如何通过事实表和维度表构建去规范化的表,首先需要深入讨论它们的角色:
- 事实(Fact)表通常包含事务的时点数据,表中的每一行都可能非常简单,通常仅代表事务的一个单位。由于简单,它们通常可作为真值(Truth)表的来源,进而派生出业务指标。例如在Airbnb,我们会用各种事实表追踪诸如预订、保留、更改、取消等事件对应的事务。
- 维度(Dimension)表通常包含与特定实体有关,并且缓慢发生变化的特性,以及有些情况下可组织成为层次结构的特性。这些特性通常也叫做“维度”,可以与事实表联结,但前提是事实表具备所需的外键。在Airbnb,我们构建了多种维度表,例如用户、列表以及市场,借此对数据进行切片。
下面这个简单的例子展示了事实表和维度表(均为规范化的表)如何联结在一起并用于解答基本的查询问题,例如每个市场过去一周产生了多少预订操作。大家也可以设想一下,如果将额外的指标m_a, m_b, m_c和维度dim_x, dim_y, dim_z投射到最终的SELECT子句,就可以从这些规范化的表很轻松地生成一张去规范化的表了。

fct_and_dim_tables_in_action.sql
规范化的表可用来回答即席查询问题或构建去规范化的表
数据分区以及历史数据的回填
当今时代,数据存储和计算的成本越来越低,很多企业现在已经可以将自己的所有历史数据轻松存储在数据仓库内,而不再清理老的数据。这就使得我们可以重新处理历史数据,并用处理结果响应新的业务需求和变化。
按照Datastamp进行数据分区
由于可用数据的总量稳步激增,运行查询和执行分析的效率会越来越低。除了遵循一些有关SQL的最佳实践,例如“频繁地提前筛选”、“仅投射必须的字段”等,数据分区也是改善查询性能最有效的方法之一。
数据分区这一做法的基本思路很简单:我们不需要将所有数据存储在一个块内,而是可以将其拆分为独立的自包含块。来自同一个块的数据可以分配相同的分区键,这意味着数据的任何子集都可以非常快速地查询。这种技术可以大幅改善查询性能。
尤其是有个分区键是最常用的:datestamp(可简称为ds),而用它的原因有很多。首先,在诸如S3等数据存储系统中,原始数据通常会按照Datestamp进行整理,并存储在包含时间标签的目录中。此外,批处理ETL作业通常以每天作为工作单位,这也意味着每天运行时都会创建新的日期分区。最后,很多分析型问题需要统计特定时间范围内事件的出现次数,因此按照Datestamp查询是一种常见模式。也正是因此,Datestamp成了最流行的数据分区方式!

partition_by_ds.sql
按照ds分区的表
历史数据的回填
使用Datestamp作为分区键的另一个重要优势在于,可以简化数据回填工作。在构建了ETL管道后,管道会向前,而非向后计算指标和维度。通常我们可能想要重新访问历史趋势和变化情况,此时可能需要重新计算过去的指标和维度,这一过程叫做数据回填。
回填操作很常见,以至于Hive内置了动态分区功能,该功能可以同时针对很多分区执行相同的SQL操作,并执行多次插入。为了证明动态分区的实用性,可以设想一个任务,我们需要回填每个市场的预订数量并展示到仪表盘中,数据范围从earliest_ds到latest_ds。此时也许可以这样做:
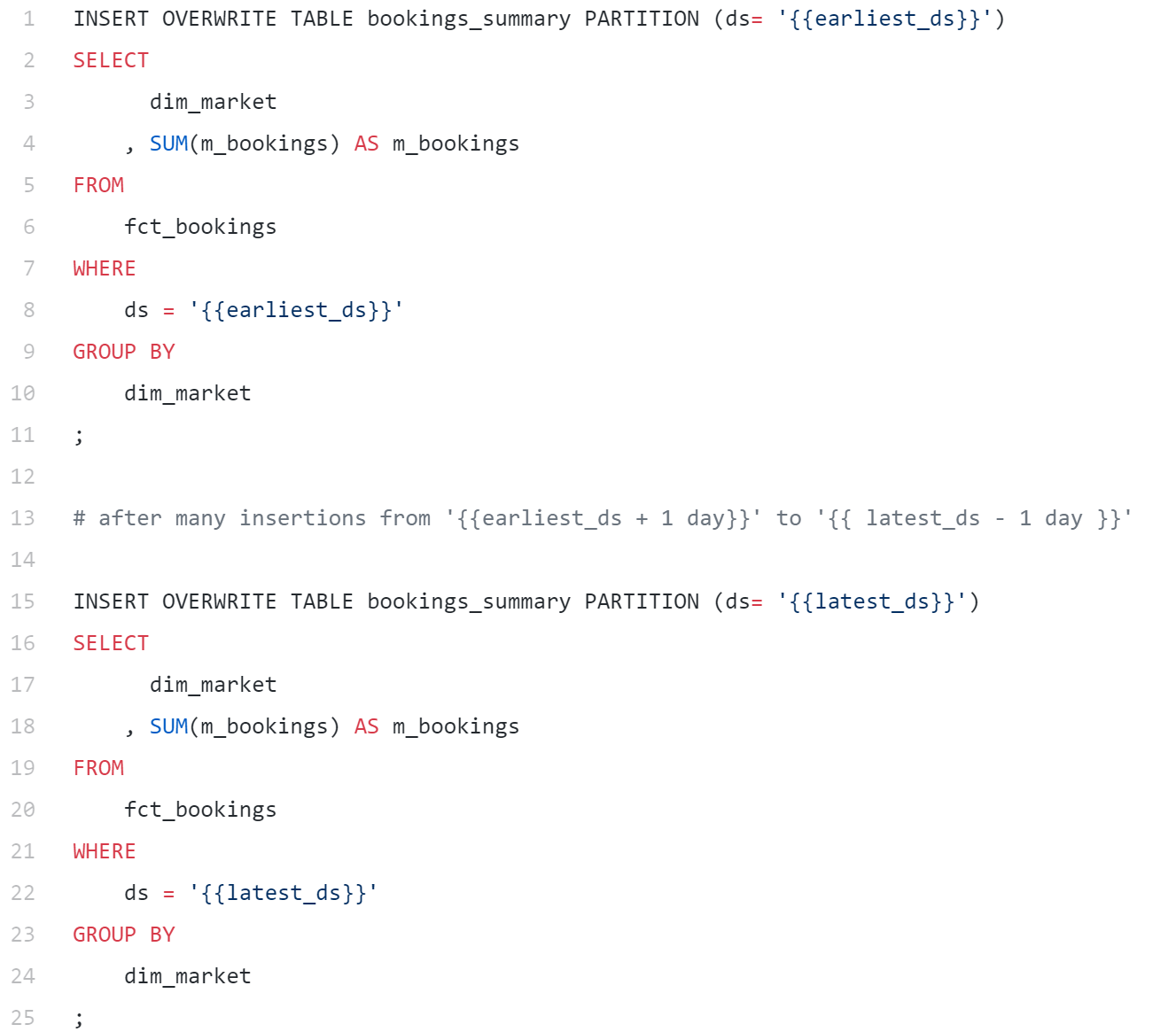
上述操作非常冗繁,因为我们针对不同分区将同一个查询运行了多次。如果时间跨度非常大,那么这个操作将会十分低效。然而如果使用动态分区,就可以大幅简化,只需要一个查询:
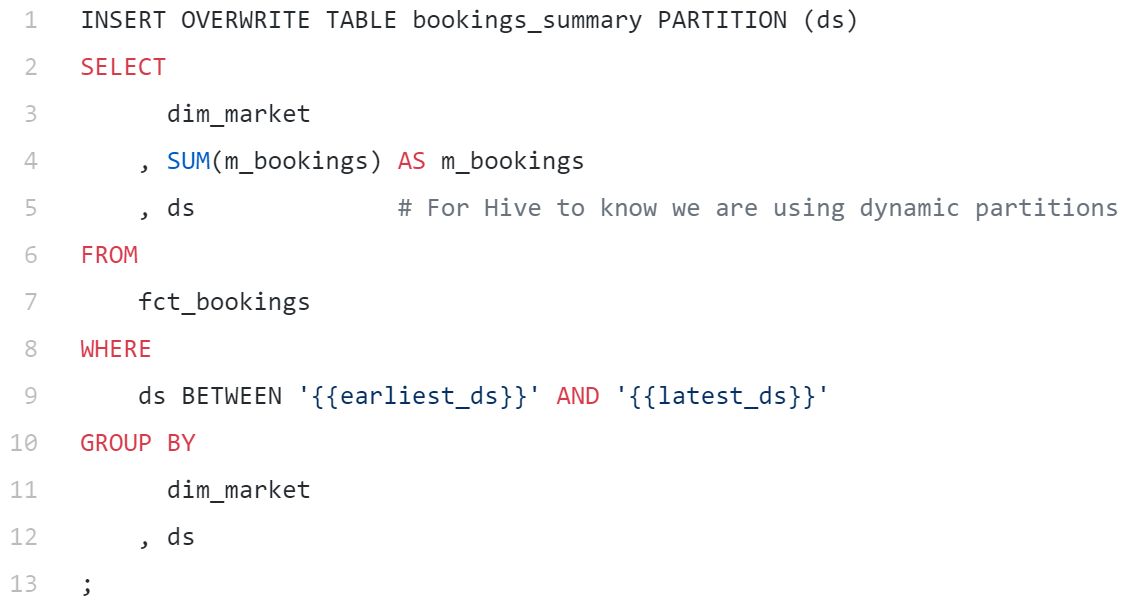
请注意SELECT和GROUP BY子句中额外的ds,WHERE子句中扩展的范围,以及如何将语法从PARTITION (ds= '{{ds}}')改为PARTITION (ds)。动态分区的美妙之处在于我们可以将所需的全部相同工作包裹到GROUP BY ds中,并将结果一次性插入相关的ds分区。这种查询方式非常强大,Airbnb的很多数据管道都在使用。下文我还将介绍如何使用Jinja控制流编写包含回填逻辑的Airflow作业。
Airflow管道剖析
在了解了有关事实表、维度表、日期分区等概念,以及这些概念对数据回填的意义后,可以归纳一下相关概念并试着实际创建一个Airflow ETL作业了。
定义有向无环图(DAG)
正如早前的文章中提到的,任何ETL作业其核心都在于三个关键环节:提取、转换、加载。虽然概念上听起来简单,但现实中的ETL作业通常很复杂,会组合包含很多提取、转换和加载任务。因此通常我们会使用图(Graph)的形式将复杂的数据流可视化呈现。看起来图中的每个节点可以代表一个任务,箭头代表了任务之间的依赖关系。考虑到特定任务的数据仅需要计算一次,随后需要继续向前计算,因此这种图是有方向但是不循环的。也正是因此,Airflow作业通常会叫做“DAG”(Directed Acyclic Graph)。

来源:Airbnb的Experimentation Reporting Framework DAG截图
Airflow在界面方面最明智的设计之一是,可以让任何用户通过图视图对DAG进行可视化,并可使用代码作为具体配置。数据管道的作者必须定义不同任务之间依赖关系的结构,借此对其进行可视化。相关规格通常会写入一个名为DAG定义文件的文件中,该文件决定了Airflow作业的结构。
操作:传感器、运算符和传输器
DAG描述了如何运行一个数据管道,具体操作则描述了要在数据管道内执行的具体工作。一般来说,操作可分为三个主要类型:
- 传感器(Sensor):等待某一指定时间、外部文件,或上游数据源。
- 运算符(Operator):触发某一操作(例如运行批处理命令,执行Python函数,或执行Hive查询等)。
- 传输器(Transfer):将数据从一个位置移动到另一个位置。
你可能已经明白了,这些操作如何对应到上文提到的提取、转换和加载任务。传感器会在经过一段时间或来自上游数据源的数据可用后接通数据流。在Airbnb,考虑到我们的大部分ETL作业都涉及Hive查询,我们通常会使用NamedHivePartitionSensors来检查Hive表的最新分区是否已经可以进行下游处理。
运算符触发数据转换,对应了“转换”这个步骤。由于Airflow是开源的,因此社区贡献者可以扩展BaseOperator类,按需创建自定义运算符。在Airbnb,我们最常用的运算符是HiveOperator(用于执行Hive查询),但同时我们也会使用PythonOperator(例如运行Python脚本)和BashOperator(例如运行Bash脚本甚至更复杂的Spark作业)。这方面有着无穷无尽的可能性!
最后,我们还会通过一种特殊的运算符将数据从一个位置传输到另一个位置,这通常对应了ETL中的加载操作。在Airbnb,我们通常会使用MySqlToHiveTransfer或S3ToHiveTransfer,但这主要取决于数据基础架构以及数据仓库的所在位置。
一个简单的范例
下面是一个简单的范例,展示了如何定义DAG定义文件,获得实例化的Airflow DAG,随后使用上文提到的不同操作定义相应的DAG结构。

DAG创建完成后,可以看到下列图视图:
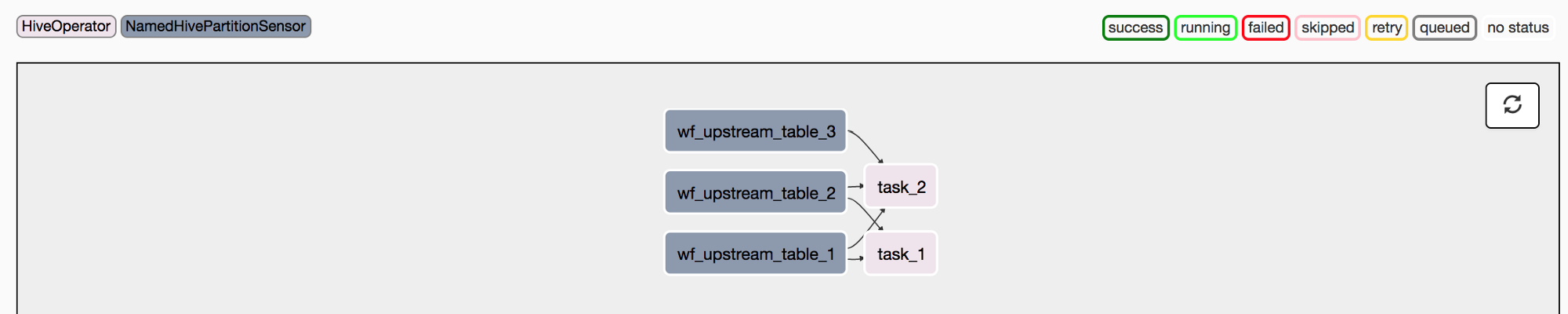
范例DAG的图视图
值得考虑的ETL最佳实践
与其他技术类似,编写好的Airflow作业也应该是简洁的,可读的,可缩放的。在我的第一份工作中,ETL对我来说仅仅是一系列不得不做的,纯粹的机械任务。当时我不觉得这有什么技术含量,也不知道有什么最佳实践。然而在Airbnb,我学到了很多最佳实践,并且开始认同ETL的价值以及其中蕴含的美。下文我将列举一些可能并不完整,但有着极高价值的ETL最佳实践。
- 数据表分区:正如上文所述,如果需要处理包含海量历史数据的大型表,数据分区将非常有用。使用Datestamp对数据分区后,即可利用动态分区功能进行并行回填。

data_partition_create_statement.sql
- 增量式数据加载:这种做法可以让ETL更加模块化并且更易于管理,尤其是在使用事实表构建维度表时。每次运行时,我们只需要将新事务附加到上一个日期分区的维度表中,而不需要扫描整个实时历史。
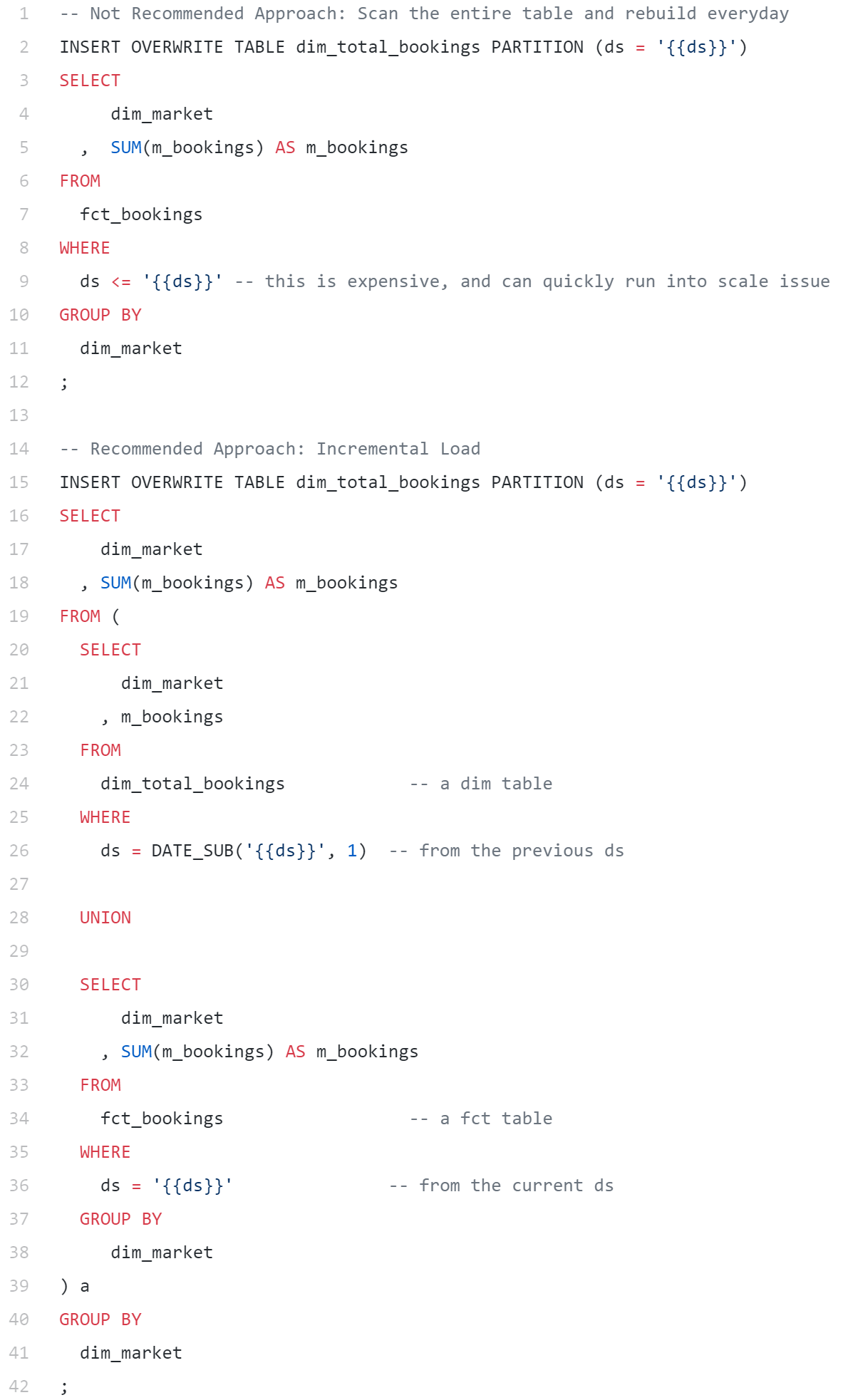
- 强制实施幂等性:很多数据科学家会通过时点快照执行历史数据分析工作。这意味着底层源表在处理过程中必须保持不变,否则我们会得出不同的答案。在构建管道时,必须确保在针对相同业务逻辑和时间段运行相同查询时,必须能返回相同的结果。这种特征有个很高大上的名字:幂等性(Idempotency)。
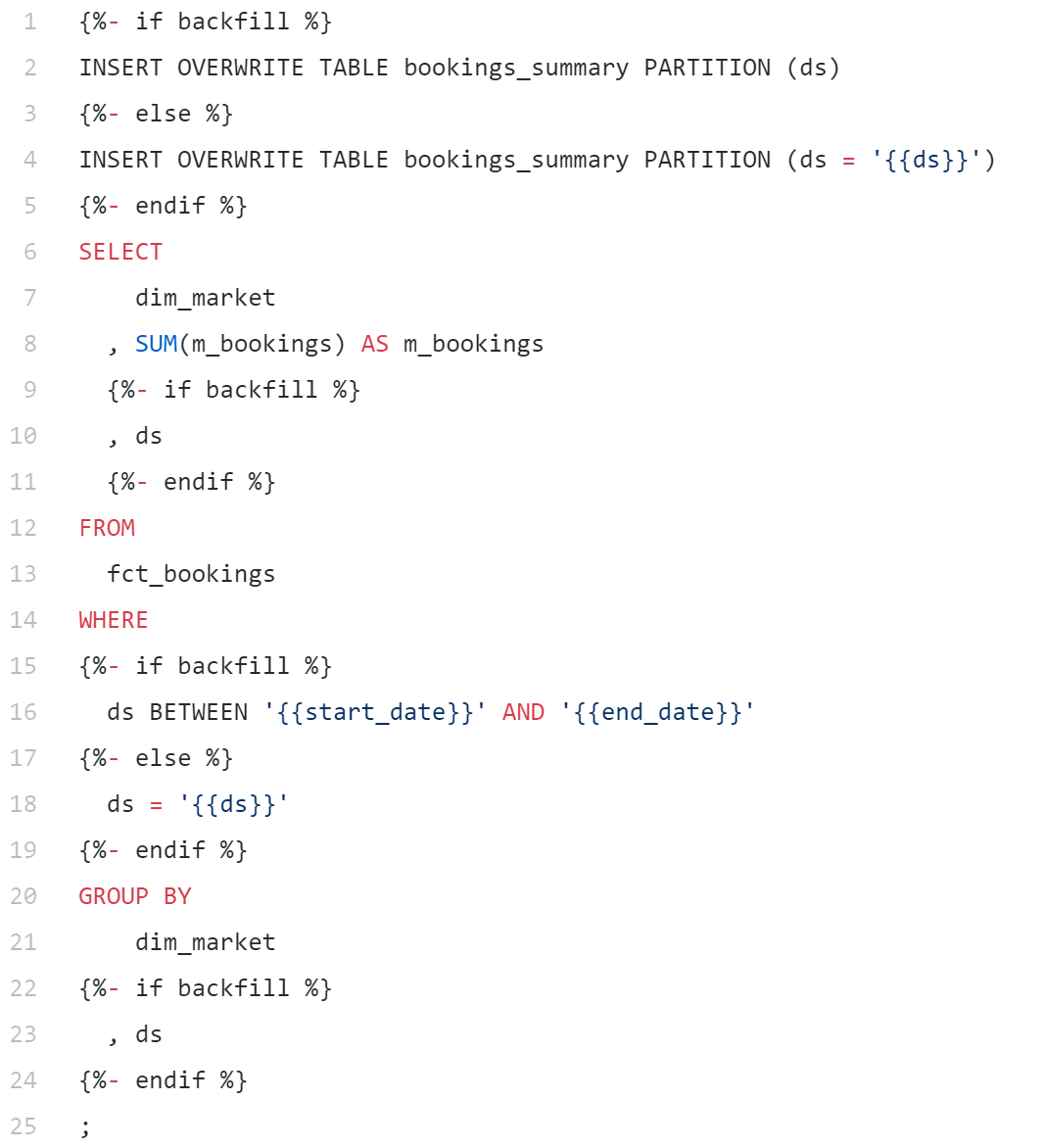
- 参数化的工作流:正如同模板的存在大幅简化了HTML页面的创建和整理,Jinja也可以与SQL配合使用简化我们的工作。如上文所述,Jinja模板的常见用途之一正是将回填逻辑纳入典型的Hive查询中。Stitch Fix有一篇很棒的文章介绍了如何在ETL中使用这种技术。
- 尽早、尽可能频繁地检查数据:在处理数据时,我们通常会将数据写入暂存(Stage)表,检查数据质量,并只将暂存表中的数据放入最终的生产用表。在Airbnb,我们将这一过程叫做“暂存-检查-放入”范式。这个三步范式中,检查操作是一个非常重要的预防机制,这个操作可以很简单,例如检查记录总数是否大于零;也可能非常复杂,例如通过异常检测系统检查是否出现预料之外的分类或异常值。

stage_check_exchange.sql
“暂存-检查-放入”操作的基本结构(即数据管道的“单元测试”)
- 构建有意义的警报和监视系统:由于ETL作业的执行通常需要耗费大量时间,因此有必要增加警报和监视系统,以免我们需要时刻关注DAG的处理进度。不同公司对DAG的监视采取了不同的方法,在Airbnb我们会定期使用EmailOperators发送警报邮件告知违反SLA的作业。其他团队也会使用警报标记出失衡的实验结果。另外Zymergen有一个有趣的范例,他们会使用SlackOperator通知与模型性能有关的指标,例如R-squared。
上述很多原则源自与经验丰富的数据工程师探讨的结论,我本人在构建Airflow DAG过程中获得的经验,以及Gerard Toonstra撰写的Airflow ETL最佳实践一文。如果你也感兴趣,强烈建议观看Maxime的下列这场讲话:
https://youtu.be/dgaoqOZlvEA
来源:Airflow原创者Maxime探讨有关ETL的最佳实践
中篇回顾
在这一系列文章的第二篇,我们深入探讨了星型架构和数据建模。此外还介绍了事实表和维度表的差异,以及使用Datestamp作为分区键的优势,尤其是在回填过程中的优势。此外,我们还探讨了Airflow作业的基本结构,并归纳了Airflow中可用的不同类型操作。另外还介绍了与ETL有关的最佳实践,并介绍了在将Airflow作业与Jinja以及SlackOperators配合使用可获得的灵活性和无穷无尽的可能!
在这一系列文章的最后一篇,我将介绍一些高级的数据工程模式,尤其是如何从管道的构建晋级为框架的构建。此外我还会列举几Airbnb内部使用的框架作为例子。
