@liuhui0803
2016-10-25T08:14:46.000000Z
字数 4097
阅读 3331
优步借Euclid完善其工程营销理念
API Hadoop Hive MySQL Spark
摘要:
针对广告投入获得快速、细化、可靠的ROI是优步构建内部营销平台Euclid的主要原因。为了跟上不断扩张的规模和数据复杂性的增长,今年上半年,优步使用Euclid取代了通过手工方式处理ROI数据的原有系统。
正文:
针对广告投入获得快速、细化、可靠的ROI是优步构建内部营销平台Euclid的主要原因。为了跟上不断扩张的规模和数据复杂性的增长,今年上半年,优步使用Euclid取代了通过手工方式处理ROI数据的原有系统。
与其他拆箱即用的解决方案不同,基于Hadoop和Spark的Euclid生态系统使得我们可以借助一种不依赖具体渠道,名为MaRS的API插件架构,以及可将异构数据流存入一套能轻松查询的单一架构的自定义ETL流程,帮助优步面对规模的扩张做好准备。Euclid基础之上的可视化层使得营销人员可以拉取ROI指标进而对广告预算进行优化。Euclid的模式识别能力使得营销工作变得更加智能。借助这些能力,营销人员可以检测舞弊,自动分配广告预算(按照渠道/国家/城市/产品),自动管理广告花销,管理营销活动,以非常细化的程度为目标受众建立资料,实时执行广告竞标。
Euclid解决的问题
长久以来我们在营销工作中遇到的问题造就了今天的Euclid平台:
自动管理广告花销
为了摆脱手工收集和处理任务的繁重负担,我们需要一种不仅能快速可靠分析数据,而且能针对全球数百个外部广告投放网络产生的不同细化程度的具体事件,例如展示、点击、安装等显示广告花销的系统。
应对数据复杂度问题
优步的数据来自所用的每个广告投放网络中包含的上百个不同渠道,其中包含上万个营销活动、数百万个关键字,以及大量广告创意。以及以此为基础构建的多种货币单位和不同类型的优步产品。除了规模,还需要考虑不同的数据种类,不同类型的广告(社交、展示、搜索、招聘信息等)产生了复杂的数据结构和映射关系。在这种规模和容量的前提下交付复杂的数据,SLA就显得至关重要。我们需要确保能按照承诺的间隔,每小时或每天提供相应的数据。
获得更精准的ROI
过去,我们的团队只能获得滞后的渠道级ROI数据。Euclid不仅需要消除时滞,而且需要能提供更细化的ROI,例如针对具体广告、创意,或关键字级别的ROI。为此我们需要将内外部数据源结合在一起,对其进行预测式分析进而发现未来趋势和多点归因(Multi-touch attribution)。
EUCLID的架构
Euclid系统包含三个主要部件:MaRS(营销报表服务)、邮件服务,以及一个ETL数据流程。
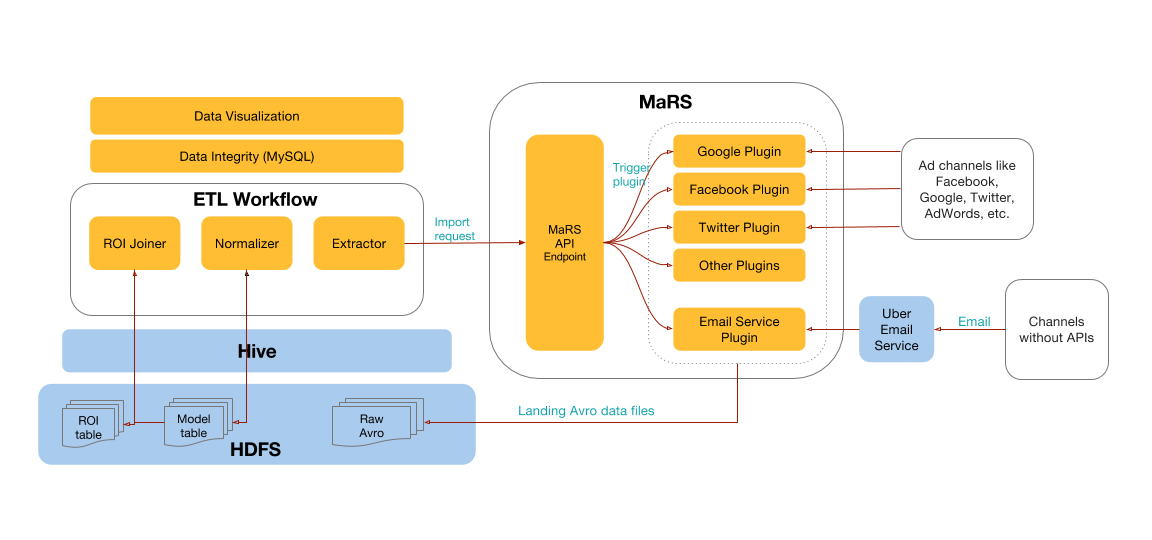
MaRS(营销报表服务)
我们通过基于插件的报表摄取微服务MaRS实现了快速缩放,几个月内就涵盖了80个渠道。在使用Euclid前,营销经理每周需要为全球数百个渠道的广告花销手工创建高度概括的周报表。这些数据不够细化,有可能包含人为错误,营销团队无法针对花销目标快速反应,也无法对广告花销进行精准的优化。
MaRS通过使用标准化的API接口,借助插件导入营销活动数据的方式解决了这一问题。插件可将广告投放网络逻辑与ETL数据流程的其他环节相互隔离,这种隔离使得我们能独立于Hadoop ETL流程开发并测试特定广告投放网络所用的逻辑。我们用的ETL数据流程叫做MaRS API,它可以将广告网络的ID作为参数传递,并直接获得不同的广告花销数据,而无须了解任何广告投放网络的具体逻辑。
这样的设计为我们提供了一大优势,可将插件的开发工作外包给外部供应商,供应商可以为多种广告投放网络开发插件。我们正是通过这种方式对Euclid可导入的API渠道数量实现了大规模的扩展。目前Euclid支持超过30种插件,其中包括Facebook、Twitter以及AdWords。
插件的实现极为简单。外部的插件开发者只需要继承三个基本类,定义Avro架构,并应用一个规格化规则:
- Auth类:处理网络API的身份验证。
- Extractor类:通过广告投放网络API提取数据。
- Transform类:将API数据转换为Avro格式。
- Avro架构:存储原始的广告投放网络数据架构。
- 规格化(Normalization)规则:通过应用映射规则将原始Avro架构中的数据转换为统一的模型化表格。
工程师可独立实现各种插件,无需担心服务环境或数据基础架构的底层产生变化。Hadoop Hive Pipeline基于配置的设计与基于API插件的MaRS架构相配合,使得我们可以在不改动代码的情况下为新渠道快速添加插件。
Euclid邮件服务
对于缺乏API的渠道,Euclid提供了一种基于邮件附件的摄取框架。通过使用该系统,广告渠道可以使用预先确定的格式直接发送CSV附件。包含在MaRS架构中的邮件服务使得广告投放网络可以将每日花销数据以邮件附件形式推送至预定义的收集点。随后Euclid可以自动验证这些数据,并将其载入ETL流程。通过这种方式,Euclid每天可以从数十个小渠道中加载数据。
ETL数据流程工作流
Euclid的ETL数据流程基于Hive,可以使用工作流管理工具对摄取的数据进行提取、规格化,以及连接:
- Extracto:请求MaRS从广告投放网络API摄取数据。
- Normalizer:将广告投放网络提供的原始花销数据规格化为统一的Hive表,表名为fact_marketing_spend_ad。
- ROI joiner:将花销数据与转换后的其他数据,例如用户级的注册以及首次行程等数据结合在一起,获得细化的ROI指标。
通过使用MaRS处理广告投放网络的逻辑,不依赖具体渠道的ETL流程使得我们的工程师可以运用大规模的优步营销数据,同时可将运作和维护流程的成本降至最低。由于每个渠道的营销活动数据和报表架构存在差异,因此这些数据其实很难直接用于查询和分析。但Euclid中基于配置的规格化步骤可以将各种Avro架构中的异构数据转换为一种模型表并存储在Parquet中,随后数据的跨维度和跨切片汇总、对比、分析工作可以变得更容易。
虽然如此,但每天的数据摄取依然是个麻烦的过程,因为我们需要处理不同类型的数据架构并满足不同的SLA。例如,如果版本被弃用,凭据或上游渠道数据格式有变化,或如果上游数据出错,API也将被破坏。为了避免此类问题,Euclid中的自定义MySQL监视和警报功能承担了各种类型的数据健康度检查。该技术的自动化回填策略(Backfill policy)、失败日志,以及待命警报功能可以检测出导致数据完整性问题的原因。借此Euclid流程每天可以顺利地将数以百亿计的记录摄取至Hadoop中。
使用Euclid优化优步营销ROI的前后效果对比
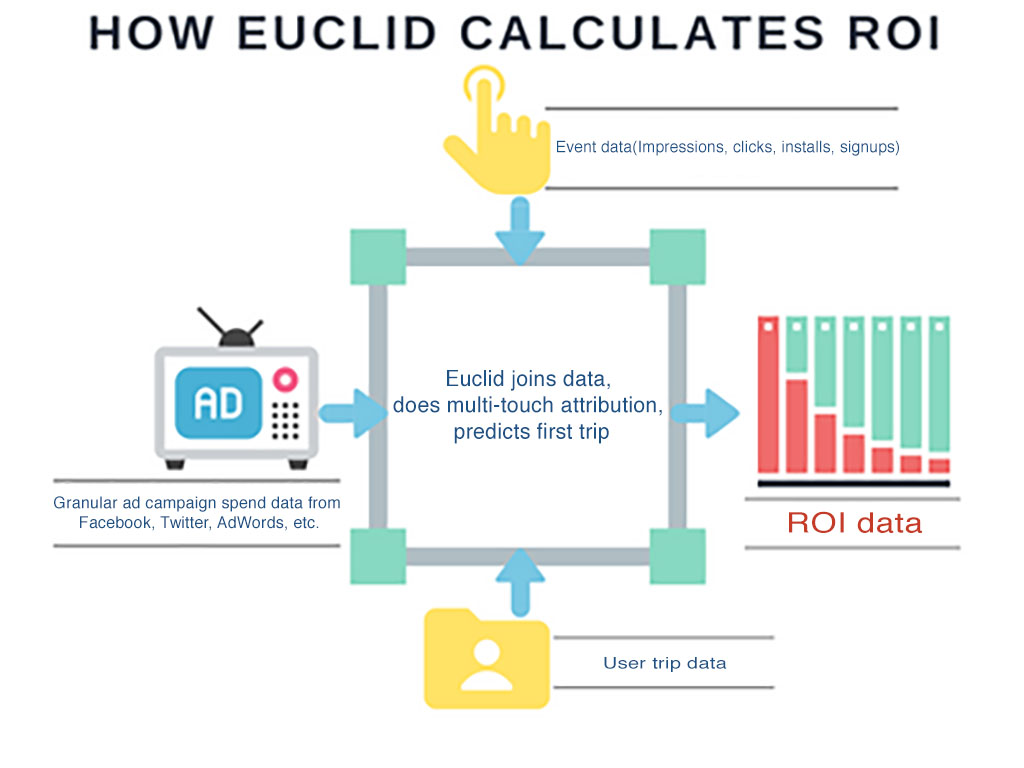
细化的ROI广告指标
除了基本的用户获取指标,用户通过优步展开第一段行程的成本对我们来说也是一个重要的广告绩效ROI指标。以前团队在度量广告的ROI时存在时滞。现在通过使用Euclid,营销人员可以更快速可靠地获得细化的ROI广告数据。在Euclid分层式的营销活动花销数据集帮助下,营销人员可以进一步深入向下挖掘,直至社交渠道所展示广告的创意水平、搜索渠道的关键字水平、招聘渠道的求职公告水平等。
下面是营销人员针对同一个营销活动测试过的三个展示型广告创意,你觉得哪个广告的效果更好?
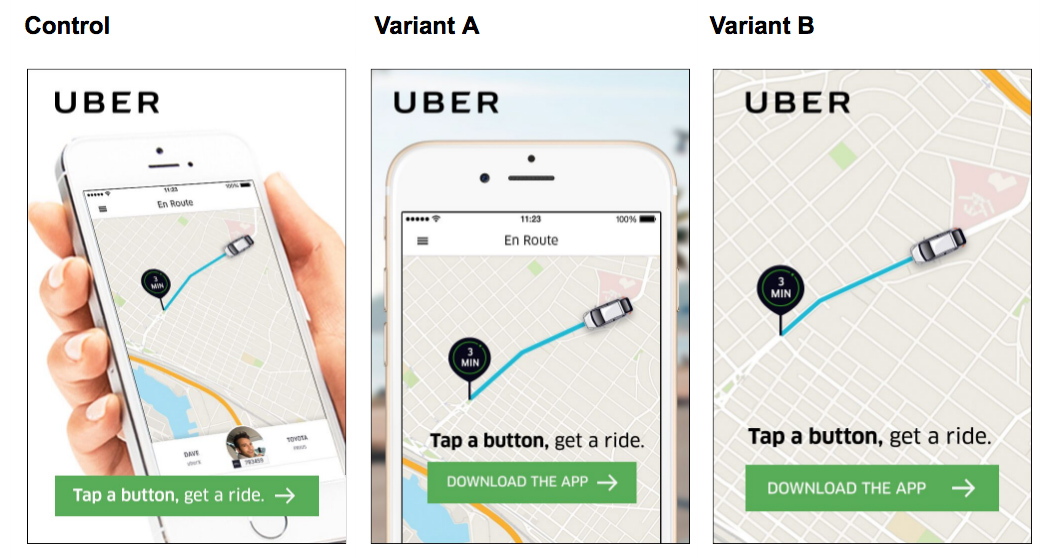
为了解哪个广告的点击率(Click-through rate,CTR)指标更好,营销人员需要通过Euclid的可视化层向下挖掘至创意水平的绩效数据。他们可以看到由Euclid摄取的ROI细化花销数据与用户转化率指标结合在一起的结果。在本例中,变体B“放大版”的CTR远远高于控制版或“缩小版”(变体A)的CTR。
考虑到有数百个渠道投放了数千个广告,其中很多广告是由外部机构运营的,根本无法以人工的方式分别检查每个广告的状态和效果。这种情况下,优步的渠道经理可以通过Euclid更轻松地找出效果不好的广告。
预测首次行程
从优步应用被安装到产生首次行程,这个转化过程通常存在不小的时滞,如果不知道首次行程什么时候开始,我们就无法确定触发这次行程的动机到底是具体哪个营销活动催生的。昨天的广告花销可能会促使用户点击或安装,但未必能促使用户注册或产生首次行程。那么我们又该如何衡量营销的ROI?当Euclid摄取到有关展示、点击、安装的数据后,会对这些数据应用一些模式,例如合作驾驶员和乘客的注册地点和时间,他们使用的设备类型,他们参与的广告渠道等。通过将此类信息与有关转化率的历史数据映射,Euclid可以用统计学方法预测用户可能会在何时何地开始自己的首次行程。随着Euclid持续以这种方式将更多数据汇总至训练模型,预测精度也将持续提高。
解决多点归因问题
当用户在社交网络上看到一则广告,随后在网络上搜索“优步”,点击搜索结果中的广告,并在优步注册后,这一切成绩并不能完全归功于搜索结果中的广告。多点归因(Multi-touch attribution)是Euclid尝试解决的另一个挑战,为此Euclid会查看展示级别的数据,分析完整的用户转化过程,随后将每次转化的“功绩”按照相应权重分配给不同渠道。清晰的多点归因使得营销人员能够为恰当的渠道分配恰当的预算。Euclid会每天摄取展示级别的数据,随后使用自己的预测引擎进行分析并训练多点归因模型。由Hadoop和Spark驱动的Euclid还计划尽快将营销用的多点归因引擎部署至生产数据流程中。
后续目标
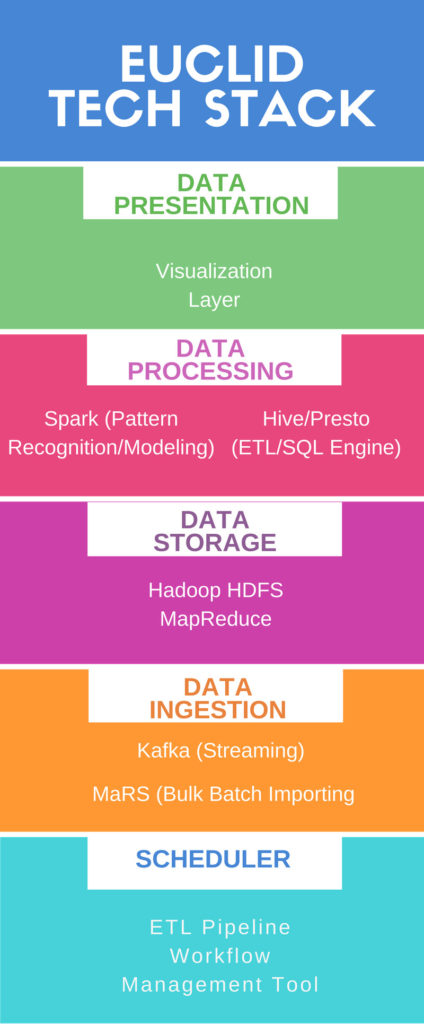
目前我们所开发的Euclid技术栈已经可以帮助营销人员理解特定渠道最适合的创意、搜索关键字,以及广告营销活动。我们计划让下一代Euclid成为更高级的营销引擎,提供数据管理平台(DMP)和需求方平台(DSP)功能。
领导Euclid架构开发的优步业务平台工程部软件工程师Hohyun Shim与Mrina Natarajan合作撰写了本文。
作者: Mrina Natarajan,阅读英文原文: Designing Euclid to make Uber engineering marketing savvy
