@liuhui0803
2018-04-08T01:57:38.000000Z
字数 3391
阅读 2730
借助Kubernetes不停机从Heroku迁移至AWS
AWS Heroku Kubernetes DevOps
摘要:
本文介绍了Voucherify为了应对成本和资源利用率等方面的挑战,将原本托管于Heroku的大部分平台组件不停机迁移至AWS的原因和迁移思路。
正文:
本文最初发布于Mike Sedzielewski的博客,经原作者授权由InfoQ中文站翻译并分享。阅读英文原文:Migrating from Heroku to AWS with kubernetes and without stopping production。
几个月前,我们成功地将大部分基础架构组件从Heroku迁移至AWS。现在,当一切尘埃(还是应该说“云”)落定后,我想简要介绍一下做出这一决策的主要考虑因素,以及如何在确保我们的Voucherify API不停机(哪怕一分钟都没中断)的情况下顺利完成了迁移任务。
架构概况
为了更好地理解迁移工作的原因,先来简单了解一下Voucherify是什么,原本的架构是怎样的。
Voucherify提供了可编程的构建块,可帮助用户构建优惠券、推介、商户会员制度等宣传推广活动。基本上,可将其理解为一种以API为先的平台,开发者可借此构建复杂并且个性化的宣传推广活动,例如当客户成为“高级”会员后,通过邮件向客户发送优惠券代码。企业还可以借助这个平台追踪代码的兑换情况,借此确定怎样的推广活动可以获得最佳效果。最后,该平台还提供了仪表盘,营销人员可以借此简化与推广有关的维护工作,开发者也可以借此简化整个活动的监控工作。
整个平台基本上可分为三个组件:
- 暴露相关API的核心应用程序
- 提供仪表盘页面的网站
- 对与API无关的其他作业提供支撑的微服务
在数据存储方面,我们使用了Postgres、Mongo以及Redis trio。
迁移后的架构是这样的:
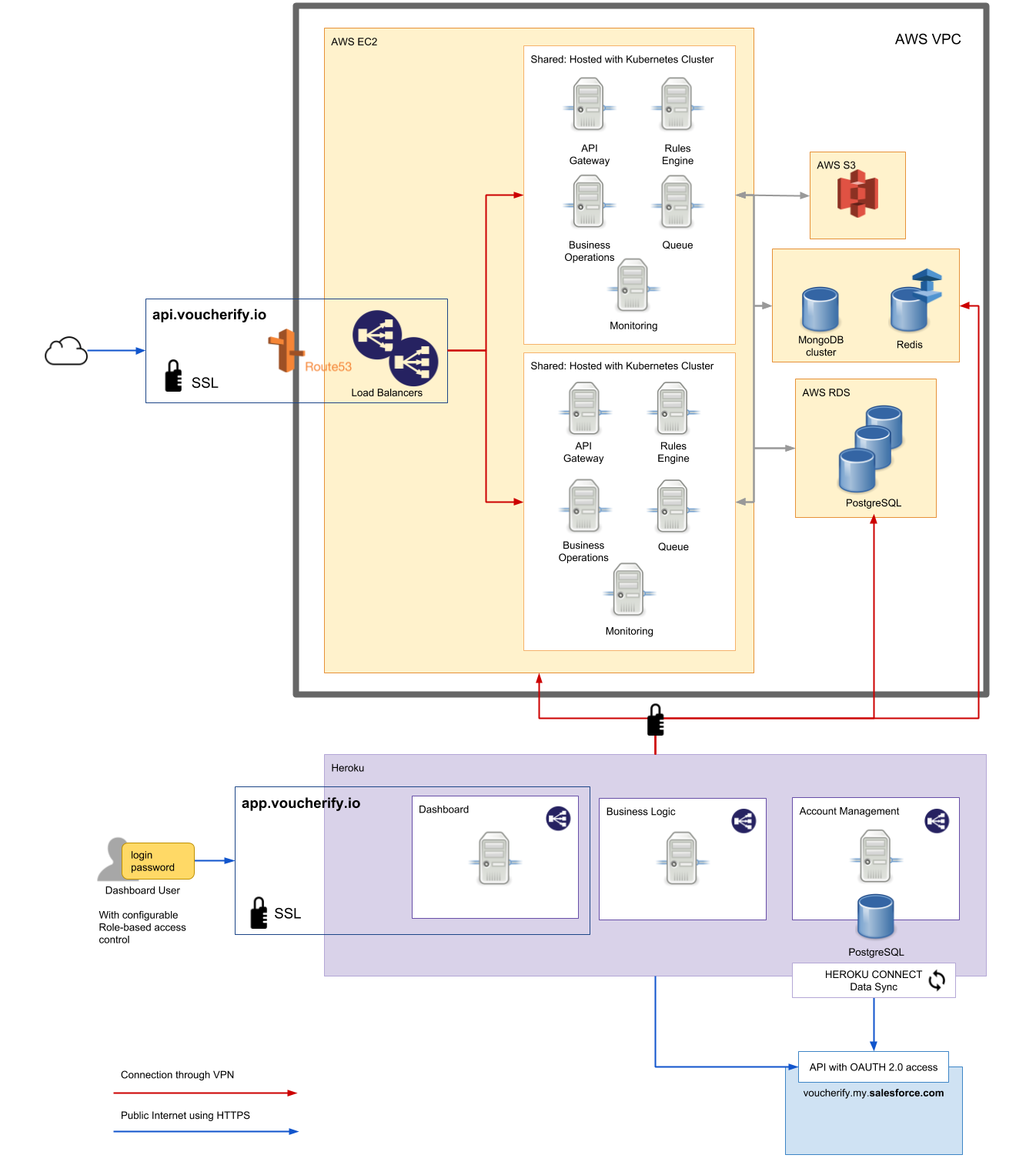
负载:我们有一百多位客户,每月会产生数百万的API调用,其中包括常规请求以及一些开销巨大的请求,例如批量导入/导出,或与第三方集成系统同步等。
为何一开始使用Heroku?
当我们在2015年上线Voucherify时,Heroku曾是最完美的解决方案。它为我们提供了极具成本效益的托管方式以及完善的持续部署工作流程。任何曾经用过Heroku的人都会明白将其与GitHub集成的过程会有多简单,以及部署速度能够有多快。此外Heroku还提供了完善的文档,并且社区也充满了活力。
借此我们可以更好地专注于自身产品的迭代,并且在很长一段时间(对我们来说,是大约16个月)里不需要为DevOps工作委派专职人员。托管在Heroku上最大的好处在于速度。我们只需要构建、发布、扩展,完全无需考虑基础架构问题(部署脚本、缩放、安全性等)。此外速度方面的收益还体现在Heroku遍布全球的数据中心为我们提供的低延迟访问体验,对我们来说这一点非常重要,因为我们这个以API为先的平台最重要的事情是确保开发者获得一流体验,我觉得任何开发者面对卡顿的响应都不会感到开心。
转折点
Heroku本来挺好,但我们的平台开始逐渐变得更加动态化。新的企业客户希望每天调用数万次API,原本我们采用了“游击队”式的方法缩放Dyno,但这样的做法开始变得越来越昂贵。我们已经明白,长远来看,这种架构的缩放性已经无法满足我们的要求。毕竟作为一家已经起步的企业,我们必须快速加以应对。
当时我们的成本是这样的:
- API服务 — 750美元(仅包括处理流量的Dyno,不包括数据库)
- Web仪表盘 —$50美元
- 处理更多API流量的另一个Dyno,至少50美元
- 对于大批量操作(导入、导出),我们需要更大内存更大规模的容器,因此每个Web Dyno的成本将增长至250美元
但价格并非我们决定弃用Heroku的唯一原因。
首先,我们开始遇到一些很奇怪,并且难以调试的基础架构问题。有好几次我们注意到平台遇到了问题,无法获得确定性的响应结果。调查问题的过程中,却(在很久很久之后)发现问题源自Heroku本身。他们的服务状态页面不能及时更新。有时候他们的反应速度很快,但有时候我们只能自行尝试解决,因为等他们来处理还要多等好几个小时。
其次,Heroku(估计其他PaaS也是如此)的资源利用率很低。Heroku只关心硬件的资源结构,但据我们所知,这样的资源限制策略虽然很重要并且合理,但毕竟每个应用程序都有各自的特点,因此相关的CPU/内存利用率配置文件也需要酌情调整。为了升级更大的内存,我们还得为额外的CPU资源付费,但这些CPU资源我们根本不需要。如果需要进一步缩放应用,情况还会更严峻,不必要的成本也会更高。就以我们的情况来说吧,我们的基础架构工程师Tom曾经说过:
现在,每月支付相同费用(750美元,仅服务,不包括数据库)的情况下,我们再也不需要头疼批量操作的问题,因为目前的资源利用率更合理。更重要的是,我们的流量翻了六倍。
第三,缺乏私有IP地址。我们曾经收到通知说自己的应用程序发送了大量垃圾信息,但实际并非如此。更重要的是,我们的一些企业客户会通过安全策略控制出站通信,为了设置自己的防火墙,他们询问我们的IP地址,而在使用Heroku的情况下甚至这样的要求我们都无法满足。
最后,加载项极为有限。Heroku的一些加载项无法兼容Voucherify集成的最新版软件。例如Compose加载项只能用于2.6版的软件。
结合所有这些因素,继续使用Heroku只能导致我们浪费更多资金和时间。
拯救者AWS
为何选择AWS?我猜答案可能会让一些人失望,但毕竟AWS是目前最流行的云提供商,我们也从以往的项目中积累了丰富的经验。事先我们并没有进行调研,此外我们的数据库实例原本就已经托管在AWS的同一个区域中。
迁移过程——如何确保所有系统不中断运行
我们的API需要出处理全球成千上万的优惠券兑换请求,如果API停机,全球会有大量用户感到沮丧,并认为自己刚刚结账换来的优惠券就已经失效了。或者可能会让某些用户无法使用生日礼券支付自己期待已久的无人机。这样令人不悦的情况会很快引起我们企业客户的关注,进而让他们对我们的服务感到失望,这种局面是我们最不想看到的。
因此我们采取了一种循序渐进的,以可用性为最高要务的迁移策略。我们的做法如下:
- 首先通过Bash脚本迁移一个应用程序。在确定了所有细节(依赖项、安全补丁等)之后,脚本的运行就变成了常规的IT维护任务。为此我们选择了容器技术,因为我们的API需要通过一组服务器运行,并且需要具备负载均衡、自动缩放、故障转移等能力(Heroku自带这些功能),相关的编排工作是通过Kubernetes实现的,相比Mesos和Docker Swarm,Kubernetes似乎有着最大规模的社区。
- Kubernetes内建了对Google Cloud Platform的支持,但并未直接支持AWS,因此我们使用StackPoint简化k8s的配置。通过这种方式,我们就不需要花费大量时间来配置AWS群集。StackPoint最棒的地方在于,可以提供与节点数量无关的统一费率。使用k8s的其他好处在于,我们可以在需要时将群集迁移至其他云平台,这让我们喜出望外,因为最近就有客户询问是否能提供AWS之外的其他托管选项。通过这样的方式,我们可以随时在其他区域创建群集,而整个过程可以在15分钟内顺利完成。
- 引入了k8s监视平台:Prometheus + Grafana。我们计划令行撰文介绍具体做法,如果你也关注这个问题,不妨订阅我们的博客。
- 通过计算Heroku平台当前的资源使用率,为所需容器资源设置基准线,并作为选择EC2节点规模的依据。
通过Route53对流量逐步进行重路由:
- 10% AWS — 90% Heroku
- 25% — 75%
- 50% — 50%
- 100% AWS
结果
最终我们获得了一个更可预测的平台,并且面对未来几个月的流量增长也获得了更稳妥的保障。我们的几个服务依然会使用Heroku,例如仪表盘,因为这样做更易于部署,并且这些服务实际上并不需要那么多资源。另外Heroku Connect也值得一提,我们很喜欢这个服务,该服务可以简化我们与Salesforce的同步。
最后,我们还将自己的Postgres实例搬离了Heroku。在不影响生产运作的前提下执行该任务需要应用一些很有趣的技巧,随后我们也将专门介绍,敬请关注!
