@liuhui0803
2018-03-22T04:23:45.000000Z
字数 6962
阅读 3121
数据工程师新手指南——上篇
数据科学 软件开发 创业公司 编程
摘要:
这一有关数据科学系列文章的第一篇,重点介绍了分析工作涉及到的不同技术层,以及一些基础性的工作,例如数据仓库的构建。此外还简要探讨了构建ETL时涉及的不同框架与范式。
正文:
本文最初发布于Robert Chang的博客,经原作者授权由InfoQ中文站翻译并分享。阅读英文原文:A Beginner’s Guide to Data Engineering — Part I。
写作动机
随着在数据科学领域的经验逐渐丰富,我越来越确信,数据工程是任何数据科学家最重要也最基础的必备技能之一。我发现无论项目评估、就业机会,甚至职业成长等方面均是如此。
在早前的一篇文章中,我曾提出数据科学家的主要能力在于将数据转换为价值,但这样的能力大小主要取决于其所在公司数据基础架构的完善程度,以及数据仓库的成熟度。这意味着数据科学家必须极为了解数据工程,才能妥善判断自己的技能是否与企业的现状和需求相匹配。此外我所认识的很多知名数据科学家不仅擅长数据科学领域,而且都能从战略上将数据工程作为自己的毗邻学科,进而驾驭更大规模、有着更广大目标,他人往往无法驾驭的项目。
尽管很重要,但数据工程方面的教育其实很欠缺。从起源的角度来考虑,很多时候为了接受有关数据工程的培训,唯一可行的方式是从实践中学习,但有时这就太迟了。我曾十分有幸能够与一些数据工程师合作,他们很耐心地教我掌握这个课题,但并非每个人都能有这样的机会。因此我撰写了这一系列新手指南,对我学到的内容进行了简单总结,希望能让更多人获益。
本新手指南的内容安排
这一系列文章的涵盖范围无论从哪方面来看都不会十分全面,并且内容主要围绕Airflow、数据批处理以及SQL类语言。然而除此之外,读者也可以自行学习有关数据工程的基础知识,希望这些内容能让你产生兴趣,并在这个依然快速发展的新兴领域中取得一定的成果。
- 上篇(本文)将从较高角度进行整体式介绍。我会将个人经历与专家见解结合在一起带你思考数据工程到底是什么,为何充满挑战,以及这个课题如何帮助你和你的公司成长。本文的目标读者主要是有抱负的数据科学家,他们可能希望了解一些基础知识,进而评估新的工作机会;或者可能是早期阶段的创业者,他们可能希望组建公司的第一个数据团队。
- 中篇的技术深度更高一些。这篇文章将专注于Airbnb的开源工具Airflow,介绍如何以编程的方式创建、调度和监视工作流。尤其是我将通过演示介绍如何使用Airflow编写Hive批处理作业,如何使用星型模型(Star Schema)等技术设计表Schema,最终将介绍一些有关ETL的最佳实践。这篇文章的目标读者是希望掌握数据工程技能的新手数据科学家和数据工程师。
- 下篇将是这一系列文章的最后一篇,我将介绍一些高级数据工程模式、高级抽象以及扩展框架,借此简化ETL的构建并提高效率。经验丰富的Airbnb数据工程师曾教给我很多此类模式,我觉得这些见解对具备丰富经验,希望进一步优化工作流的数据科学家和数据工程师很有用。
我本人非常拥护将数据工程作为一个毗邻学科来学习,不过说出来也许会让你吃惊,几年前我的态度是截然相反的。我在自己的第一份工作中曾非常纠结数据工程这件事,动机上和情感上都有不小的纠结。
研究生毕业后,我的第一份业内工作
研究生毕业后,我在华盛顿邮报旗下一家关联性质的创业公司里任职数据科学家的工作。当时,满腔抱负的我确信他们可以提供能直接用于分析的数据,随后我就可以使用各种先进的技术帮助他们解决最重要的业务问题。
就职后很快发现,我的主要职责并不像自己设想的那么迷人。其实我当时的工作非常基础:维护一些关键流程,借此追踪网站的访客数,了解每位读者阅读内容花费的时长,以及人们点赞或转发我们文章的频率。这些工作当然也很重要,因为我们要将有关读者的各类见解提供给出版商,借此免费换得一些高质量内容。
然而暗地里,我一直希望能尽快完成手头工作,随后就有时间开发一些真正高级的数据产品,例如这里介绍的那些。毕竟这才是数据科学家的本职工作,我当时这样对自己说。过了几个月,一直没找到适合的机会,我对这家公司也绝望了。然而对于处在早期阶段的创业公司(需求方)或数据科学家新手(供给方)来说,对我这样的亲身经历可能并不是完全陌生,毕竟双方在这个新的人才领域都没什么经验。

图源:正在勤奋开发ETL流程的我(中央穿蓝衣的人)
反思这段经历,我意识到自己所感受到的挫折,其根源在于对现实世界中的数据项目到底是如何进行的,实在是知之甚少。我被他们直接丢到了满是原始数据的旷野中,但距离经过预先处理的,井然有序的.csv文件还有很远的路程。身处一个以这种情况为常态的环境,我觉得自己完全没有做好准备,哪都不对劲。
很多数据科学家职业生涯开始时都遇到过类似情况,而只有能快速意识到实情以及相关挑战的人才能最终取得成就。我本人也已经适应了这种新的现实,只不过速度很慢,步调很缓。一段时间来,我发现了工具化(Instrumentation)这个概念,适应了机器生成的日志,解析了很多URL和时间戳,更重要的是,学会了SQL(是的,你也许会好奇,工作前我对SQL的唯一了解仅仅来自Jennifer Widom的MOOC公开课)。
现在我已经理解了,分析重在仔细、聪明的计算。而面对我们身处的,始终充斥着各种喧嚣和炒作的世界,这些基础工作尤为重要。
分析的层次划分
很多倡议者认为数据科学领域存在的“棱角”和媒体时不时渲染的美好未来之间存在矛盾,在这其中我最喜欢Monica Rogati的观点,她对迫不及待希望拥抱AI的公司提出了一些告诫:
人工智能可以认为处在需求金字塔的最顶端。没错,自我实现(的AI)很棒,但首先你得有食物、饮水以及容身之处(数据读写、收集以及基础架构)。
下面这个框架体现了很多技术间的透视关系。在任何一家企业可以优化业务效率或构建更智能的数据产品前,必须首先完成很多基础工作。这一过程类似于我们每个人必须首先满足食物和饮水等最基本的生存需求,随后才能最终实现自我。这也意味着企业必须根据自身需求雇佣数据方面的人才。对于创业公司来说,如果雇佣的第一个数据领域的专家只懂得建模,但不精通,甚至完全不懂如何构建作为其他工作前提要求的基础层,那么最终的结果将会是灾难性的(我将其称之为“乱序招聘问题”)。
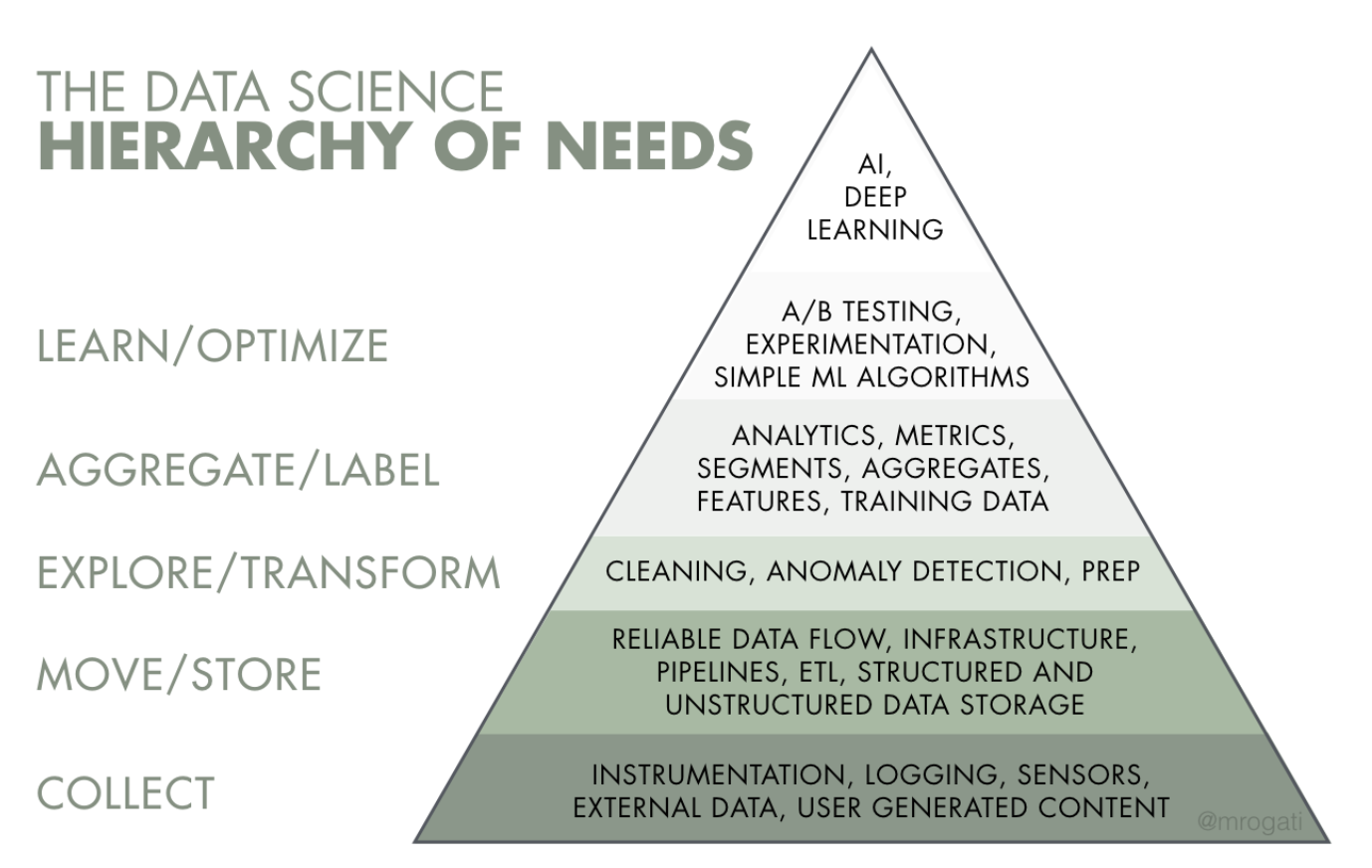
来源:Monica Rogati的文章“AI需求的层次结构”
然而很多企业并未意识到,我们现有的大部分数据科学培训课程、学术机构以及专家都趋向于专注在这座知识金字塔的顶端。就算一些鼓励学生们通过公开API调整、准备或访问原始数据的新课程,其中大部分也不会教大家如何妥善设计表Schema或构建数据管道。现实世界中数据科学项目必不可少的关键组成元素就这样在“转换”中遗失了。
好在就如同软件工程可以用来从专业角度区分前端工程、后端工程以及站点可用性工程,我觉得日渐成熟的数据科学领域也会如此。随着时间发展,人才的具体组成将愈加专精化,会出现越来越多具备足够技能和经验,可以顺利打造出数据密集型应用程序所需底层平台的人才。
对数据科学家而言,这种未来设想到底意味着什么?我并不想争论说每个数据科学家都必须成为数据工程领域的专家,然而我也确实认为每个数据科学家都必须对这些基本信息有所了解,这样才能更好地评估项目以及工作机会,真正实现学以致用。如果你发现自己需要解决的很多问题都要求自己具备更深入的数据工程技能,那么就绝对有必要付出时间精力学习数据工程。实际上我在Airbnb的工作过程中就是这样做的。
构建数据基础和数据仓库
无论你对数据工程的学习抱有怎样的目的或多强烈的兴趣,都必须首先明白数据工程的重点所在。Airflow的原作者Maxime Beauchemin在数据工程师的崛起一文中将数据工程总结为:
数据工程领域可以看作商业智能和数据仓库的超集,同时也包含更多源自软件工程的要素。这一学科还蕴含了所谓的“大数据”分布式系统运维所需的相关技能,以及与庞大的Hadoop生态、流处理,以及大规模计算有关的概念。
在数据工程师需要负责的各种重要任务中,最吃香的能力之一是设计、构建、维护数据仓库。与零售商在自己的仓库中存储商品并包装销售的做法类似,我们需要在数据仓库内对原始数据进行转换,并存储为可查询的格式。
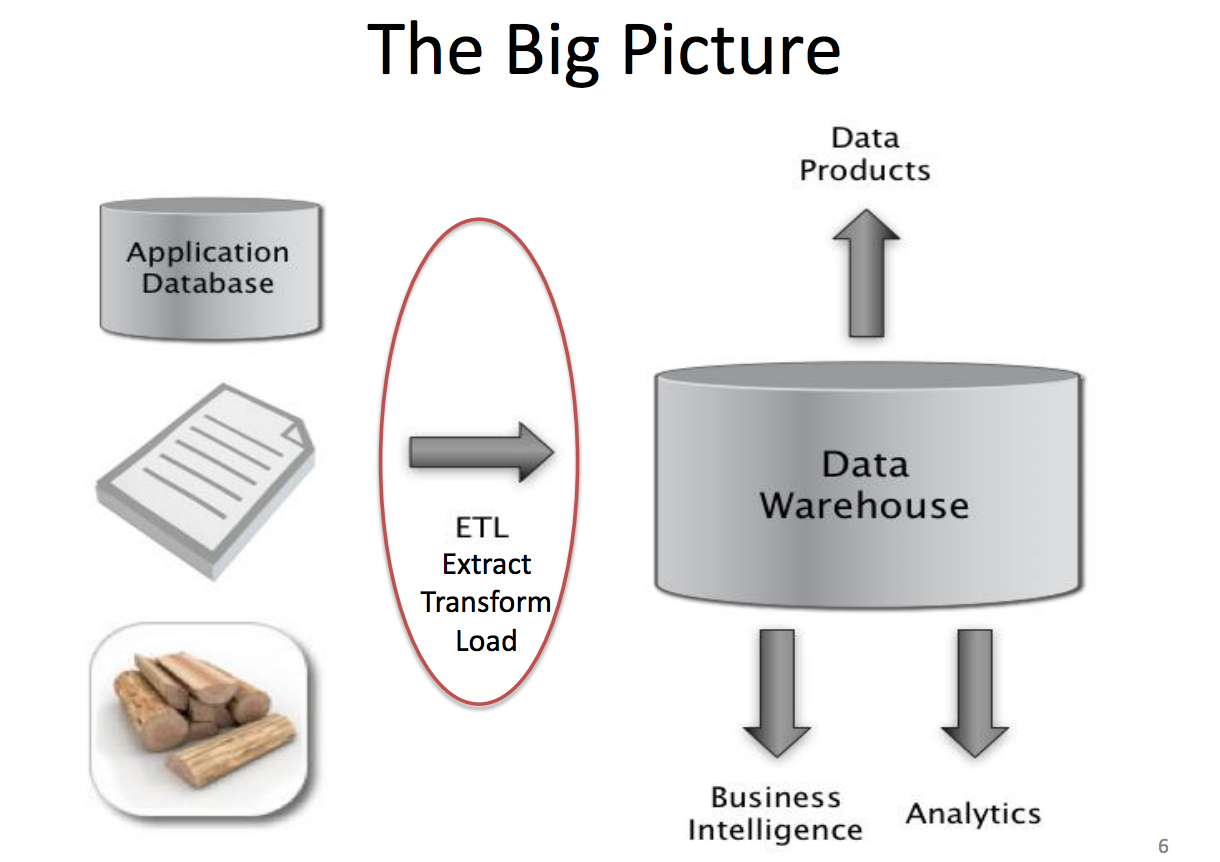
来源:Jeff Hammerbacher的UC Berkeley CS 194课程讲义
在很多方面,数据仓库都是实现更高级分析操作,实现商业智能、在线实验以及机器学习必不可少的引擎和燃料。下文列举了几个具体示例,从中也可以看出数据仓库在处于不同阶段的企业中所扮演的重要角色:
- 500px构建的分析系统:Samson Hu撰文介绍了500px希望在“市场匹配”的状况下更进一步增长的过程中面临的挑战。他详细介绍了从零开始构建数据仓库的全过程。
- 扩展Airbnb的实验平台:Jonathon Parks介绍了Airbnb的数据工程团队如何构建专用数据管线,为实验性报表框架等内部工具提供支持的做法。这些成果对Airbnb产品开发文化的塑造和扩展至关重要。
- Airbnb使用机器学习技术预测房屋价值:由我本人撰写的这篇文章介绍了为何在构建批处理训练和脱机计分机器学习模型时会需要在前期进行大量有关数据工程的准备工作。本文还特别介绍了特征工程、构建和回填训练数据等很多类似于数据工程的任务。
如果不具备数据仓库这个基础,与数据科学有关的所有活动或者会极为昂贵,或者将完全无法扩展。例如,如果不具备妥善设计的商业智能数据仓库,数据科学家可能将无法针对相同的基本问题给出不同结果,而这还是最好的情况;最糟糕的情况下,数据科学家可能会无意中直接针对生产数据库进行查询,导致生产事务延迟或中断。同理,如果不具备实验性的报表流程,也许就只能通过非常原始的重复性手工操作进行实验性质的深度探索挖掘。最终,如果无法通过适当的数据基础架构为标签集合(Label collection)或特征计算提供支持,训练数据本身的筹备也将会耗费大量的时间。
ETL:提取、转换和加载
上述所有示例都遵循了ETL这一常见模式,ETL代表“提取、转换和加载”,这三个概念性的步骤决定了大部分数据管道的设计方式和构造,可以充当将原始数据转换为可分析数据的蓝图。为了更精确地理解这个流程,我从Robinhood的工程博客中找了一张很实用的图片:
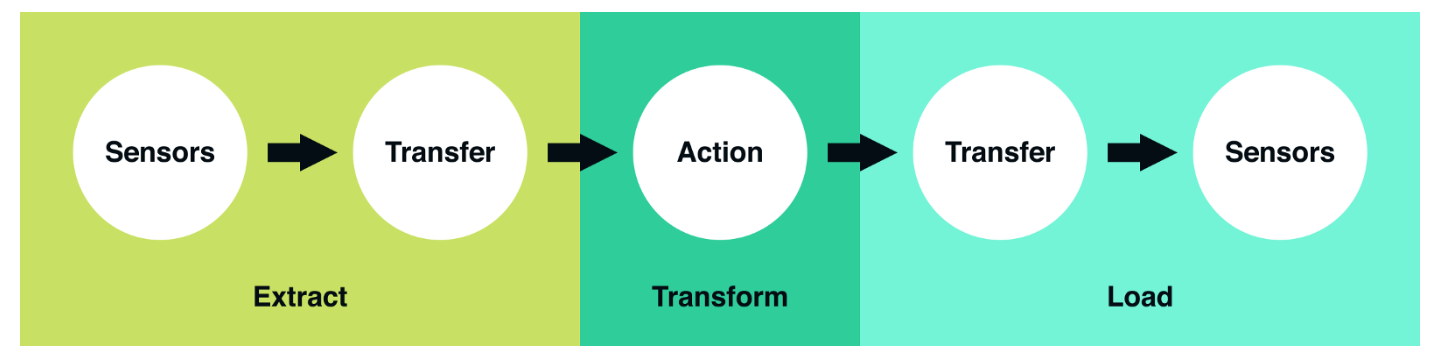
来源:Vineet Goel名为Robinhood为何使用Airflow?”的文章
- 提取:在这一阶段,传感器等待上游数据源加载(例如上游数据源可能是计算机或用户生成的日志、关系型数据库副本、外部数据集等)。加载完成后,需要将数据从源位置移出以便进一步转换。
- 转换:这是所有ETL作业的核心,通过应用业务逻辑并执行筛选、分组、聚合等操作将原始数据转换为可分析的数据集。这个步骤需要对业务以及不同领域的知识有全面理解。
- 加载:最后加载处理完成的数据并将其移动到最终位置。通常这类数据集可被最终用户直接使用,或充当后续ETL作业的上游数据源,借此形成所谓的数据族系(Data lineage)。
虽然所有ETL作业都遵循这样的通用模式,但实际作业本身在用法、工具以及复杂度等方面可能各不相同。下文列举了一个非常简单的Airflow作业范例:

airflow_toy_example_dag.py
来源:DataEngConf SF 2017研讨会上Arthur Wiedmer的分享
上述范例可在到达执行日期后等待一秒钟的传递操作,随后直接输出每天的日期,但现实世界中的ETL作业往往更复杂。例如,我们可能会通过一个ETL作业从生产数据库中提取一系列CRUD操作,并派生出各种业务事件,例如用户注销。随后可通过另一个ETL作业接受实验性的配置文件,计算该实验的相关指标,最终向UI输出p值和置信区间,借此告诉我们产品方面的相关变化是否有益于防止用户流失。此外还有其他示例,例如通过批处理ETL作业每天计算机器学习模型的特征,借此预测用户是否会在未来几天里流式。这样的做法有着无穷的可能性!
ETL框架的选择
在构建ETL的过程中,不同公司可能会采取不同的最佳实践。过去多年来,很多企业通过不懈努力总结了构建ETL的过程中可能会遇到的通用问题,并开发了各种框架帮助我们妥善解决这些问题。
在数据批处理的世界中,目前存在好几个开源的竞品。例如Linkedin开源了自己的Azkaban,该产品可以简化Hadoop作业依赖项的管理工作;Spotify在2014年开源了自己基于Python的Luigi框架;Pinterest也开源了Pinball;Airbnb则在2015年开源了Airflow(同样基于Python)。
每种框架都有自己的优势和局限,对此很多专家已经进行了细致的比较(可参阅这里以及这里)。无论选择哪种框架,都需要考虑下列几个重要功能:
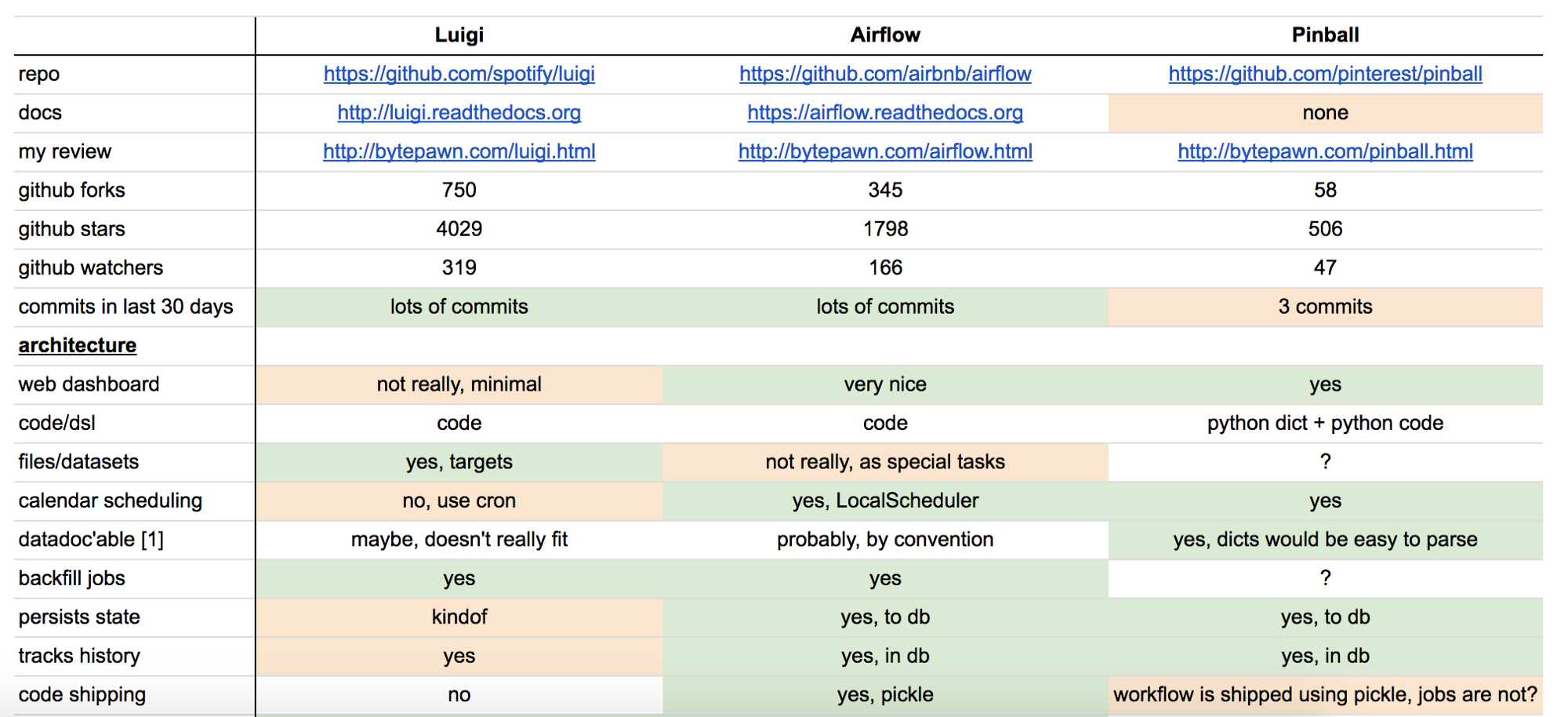
来源:Marton Trencseni对Luigi、Airflow,和Pinball的对比
- 配置:ETL本质上就很复杂,我们必须能简洁地描述数据管道内的数据流动方式。因此有必要对ETL的创建方式进行评估。是否能通过图形界面配置,还是要使用面向特定领域的语言或代码?目前“配置即代码”的概念非常流行,这种方式可以让用户以编程的方式构建表达式管道,并且可定制。
- 图形界面、监视、警报:需要长时间运行的批处理作业不可避免会在运行过程中出错(例如群集失败),哪怕作业本身并不包含Bug。因此监视和警报能力对长期运行作业的追踪工作至关重要。框架对作业进度提供可视化信息的能力如何?能否以及时准确的方式提供警报或通知?
- 回填:数据管道构建完成后,通常还要时不时重新处理历史数据。理想情况下,没人愿意构建两个独立作业,一个用于回填历史数据,另一个用于计算当前或未来的指标。框架对回填的支持如何?能否用标准化的方式高效、可缩放地进行?这些重要问题都必须考虑。
作为Airbnb的员工,我当然喜欢使用Airflow,该技术以优雅的方式解决了我在数据工程相关工作中遇到的常见问题,对此我十分感激。目前已经有超过120家企业公开宣称在使用Airflow作为自己既成事实的ETL编排引擎,我甚至可以大胆猜测Airflow将成为以后新一代创业公司执行批处理任务时的标准。
两种范式:以SQL或JVM为核心的ETL
如上文所述,不同企业在构建ETL时可能选择截然不同的工具和框架,对于数据科学家新手,可能很难决定如何选择最适合自己的工具。
对我而言就是如此:之前在华盛顿邮报的实验室工作时,最初我们主要通过Cron进行ETL的调度,并将作业组织成Vertica脚本。在Twitter工作时,ETL作业使用Pig构建,不过现在他们已经转为使用Scalding,并通过Twitter自己的编排引擎调度。Airbnb的数据管道主要使用Airflow在Hive中开发。
在我数据科学家职业生涯的前几年,大部分时候我会直接使用公司确定的工具,提供什么就用什么。但在遇到Josh Will后,我的做法完全不同了,经过与他讨论,我意识到实际上ETL有两种典型范式,而数据科学家应当慎重决定到底要使用哪种范式。

视频来源:Josh Wills在@ DataEngConf SF 2016所做的主题演讲
- 以JVM为核心的ETL通常使用基于JVM的语言(例如Java或Scala)开发。这些JVM语言中的工程数据管道通常需要以更加命令式(Imperative)的方式考虑数据的转换,例如使用键值对。此时用户定义的函数(UDF)的编写过程会更为轻松,因为不需要再使用不同语言来编写,同样因为这个原因,测试作业也可以大幅简化。这种范式在工程师之间非常流行。
- 以SQL为核心的ETL通常使用诸如SQL、Presto或Hive等语言开发。ETL作业通常需要以声明式(Declarative)的方式定义,并且几乎一切都以SQL和表为核心。UDF的编写有时候会略微麻烦,因为必须使用另一种语言(例如Java或Python)编写,也正是因此,测试作业也会显得困难重重。这种范式在数据科学家之间非常流行。
作为曾经用过这两种范式构建ETL管道的数据科学家,我自然而然更倾向于使用以SQL为核心的ETL。实际上我甚至愿意说,作为数据科学家新手,如果使用SQL范式,你将能更快速地掌握数据工程。为什么?因为SQL远比Java或Scala容易学(除非你已经熟悉后两者),借此你可以将更多精力专注于数据工程最佳实践的学习,而不是在一个不熟悉的新语言基础上学习全新领域内的各种新概念。
新手指南上篇总结
本文介绍了分析工作涉及到的不同技术层,以及一些基础性的工作,例如数据仓库的构建,这是企业进一步扩展必不可少的前提需求。此外还简要探讨了构建ETL时涉及的不同框架与范式。不过需要学习和探讨的内容还有很多。
在这一系列的下一篇文章中,我将深入细节,介绍如何用Airflow构建Hive批处理作业。尤其是将介绍与Airflow作业有关的基础信息,并通过分区传感器和运算符等构造切实体验提取、转换和加载操作。我们将一起学着使用数据建模技术,例如星型架构来设计表。最后,我还将介绍一些极为实用的ETL最佳实践。
