@songying
2019-01-07T03:54:04.000000Z
字数 1624
阅读 1910
Neural Responding Machine for Short-Text Conversation
Attention
值得一看的paper
Abstract
task:STC(Short-Text Conversation)
模型: NRM
本文提出了NRM模型,该模型采用通用的encoder-decoder 架构: 它将response的生成过程比作是规范为一个对输入文本表示的decoding 过程,其中,encoding 与 decoding都采用RNN。
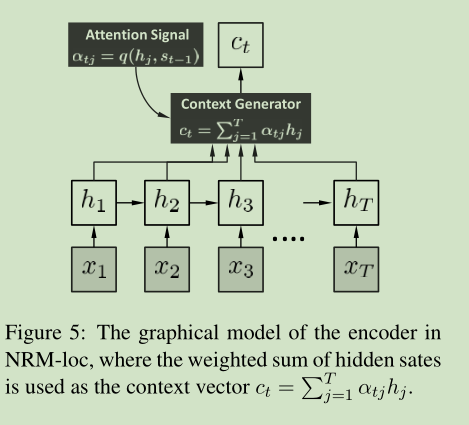
3. Neural Responding Machines for STC

NRM基本思想: 先建立post的一个表示,然后基于这个表示生成回答。 具体来说, encoder 将输入序列 转化成高维表示 , 然后利用attention机制,生成不同时刻t的上下文向量 , 然后 通过矩阵L(decoder一部分) 将 , 然后通过RNN,生成第t个单词 。
在NMT中, L将源语言的 representation 转化为目标语言。 但在NRM 中, L担任着更重要的角色:
it needs to transform the representation of post (or some part of it) to the rich representation of many plausible responses.
3.1 The computation in Decoder

上图就是模型的decoder部分,本质上是一个标准的RNN语言模型,只是添加了一个考虑 上下文。
第t个词的生成概率可以表达为:
- : 是one-hot 表示
- g(): 是一个softmax 激活函数
- : t时刻decoder的隐层状态, 有:
其中, 是一个非线性函数, 且L为 的参数。此处的 可以是logistic 函数, LSTM或GRU。 在本文中,我们使用GRU, 它的permance与LSTM接近,但参数更少,易于训练。
那么,此时的的计算如下:
在上述公式中, 是一个词 的词向量。。
3.2 The Computation in Encoder
我们考虑三种encoding方案:
- the global scheme
- the local scheme
- the hybrid scheme which combines 1 and 2
3.2.1 Global Scheme

我们采用RNN的最后一个hidden state 来作为句子的全局表示。但该方法有以下缺点:
a vectorial summarization of the entire post is often hard to obtain and may lose important details for response generation, especially when the dimension of the hidden state is not big enough .
3.2.2 Local Scheme