@songying
2019-01-03T13:25:48.000000Z
字数 4886
阅读 5077
BERT: Bidirectional Encoder Representations from Transformers
pre-trained-language-model
参考: https://www.jiqizhixin.com/articles/2018-10-12-13
值得一看的paper
[1]Improving language understanding with unsupervised learning
[2] Attention is all you need.
Abstract
Bert: Bidirectional Encoder Representations from Transformers。
通过添加一个额外的输出层来进行微调就能获得很好的结果。
Introduction
目前在下流任务中使用预训练语言模型有两种方式:
- feature-based: 如ELMO, uses tasks-specific architectures that include the pre-trained representations as additional features. (将pre-trained representations 作为额外的特征)
- fine-tuning:如 OpenAI GPT, 引入了minimal task-specific parameters, 通过简单地微调预训练参数在下游任务中进行训练。
在之前的工作中, 两种方法在预训练中采用相同的目标函数,且它们都没有采用双向语言模型来学习通用语言表示。
我们认为目前的方法严重限制了pre-trained representation 且主要的限制在于标准的语言模型是单向的。我们通过Bert来解决这个问题。Bert提出一种新的 pre-training objective: masked language model。
本文贡献如下:
- 我们论述了 bidirectional pre-training for language representations 的重要性。
- 我们展示了 pre-trained representations 消除了 the needs of many heavily engineered
task-specific architectures。 - BERT 在 11 个任务上都取得了state-of-art效果
2. 相关工作
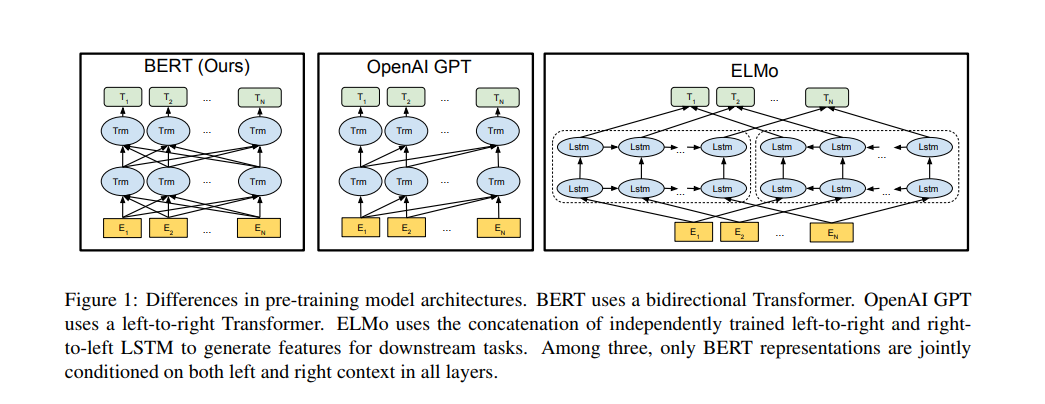
2.1 Feature-based Approaches
即获得词的向量表示,如Word2Vec,Glove,ELMO。
2.2 Fine-tuning Approaches
先在语言模型上进行预训练模型,然后将模型迁移到下游任务中。这种方法的优点在于大大减少了下游任务学习时的参数量。
2.3 Transfer Learning from Supervised Data
不需要看,只是讲述迁移学习很有用。
3. BERT
本节引入了BERT并讲述了它的细节。
- 简述了模型结构以及BERT的 input representation。
- 引入 the pre-training tasks,这部分实本文核心。
- 讲述预训练过程和微调过程
- 比较 BERT 和 OpenAI GPT。
3.1 Model Architecture
Bert 模型结构上是一个多层,双向 Transformer encoder。
我们假定层数为 L, 隐层size为 H, self-attention heads 数目为A,那么有:
- : L = 12, H=768, A= 12, 参数数量 110M
- : L = 24, H=1024, A= 16, 参数数量 340M
与 OpenAI GPT 模型大小相同,主要是为了二者之间比较。 在下文,我们将双向Transformer称为 “ Transformer encoder”, 将单向(仅左)的Transformer称为 “Transformer decoder”。
3.2 Input Representation
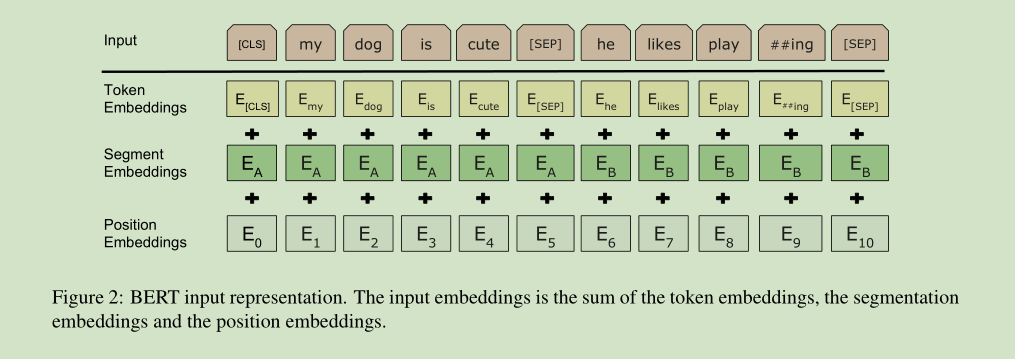
我们的 Input Representation 能够清楚的表示单一文本句子或句子对(如[Question, Answer])。每个给定的token, 它的 input representation 是由 corresponding token, segment, 和 position embeddings 集合而成的。如图2所示。
细节如下:
- We use WordPiece embeddings with a 30,000 token vocabulary. We denote split word pieces with ##.
- We use learned positional embeddings with supported sequence lengths up to 512 tokens.
- The first token of every sequence is always the special classification embedding ([CLS]). The final hidden state corresponding to this token is used as the aggregate sequence representation for classification tasks. For nonclassification tasks, this vector is ignored.
- Sentence pairs are packed together into a single sequence. We differentiate the sentences
in two ways. First, we separate them with a special token ([SEP]). Second, we add a
learned sentence A embedding to every token of the first sentence and a sentence B embedding to every token of the second sentence. - For single-sentence inputs we only use the sentence A embeddings.
3.3 Pre-training Tasks
BERT 使用两个新的无监督预测任务来训练。
Task 1. Mased LM
为了训练深度双向表征,我们随机遮蔽输入 token 的某些部分,然后预测被遮住的 token。我们将此称为“masked LM”(MLM,类似于我们的完形填空)。在这种情况下,对应于遮蔽 token 的最终隐藏向量会输入到 softmax 函数中,并如标准 LM 中那样预测所有词汇的概率。在所做的所有实验中,我们随机遮住了每个序列中 15% 的 WordPiece token。
虽然该方法能够获得双向预训练模型,但该方法有两个弱点:
we are creating a mismatch between pre-training and fine-tuning, since the [MASK] token is never seen during fine-tuning. 为了减轻该问题, we do not always replace “masked” words with the actual [MASK] token. 具体做法如下:
假如我们有一句话, my dog is hairy , 被选中的词为hairy,数据生成器并不总是将hairy替换为[MASK],此时的过程如下:
- 80% 情况下: 用[MASK] 替换 hairy
- 10% 情况下: 随机选一个词如apple 来替换hairy
- 10%: 不改变这句话
only 15% of tokens are predicted in each batch, which suggests that more pre-training steps may be required for the model to converge.
Task 2. Next Sentence Prediction
语言模型不能获取两个句子之间的关系,因此我们预训练了一个 binarized next sentence prediction task, 该任务可以从任意单语语料库中轻松生成。 具体来说,我们选定一个句子A,B作为预训练样本,B有50%的可能是A的下一句,也有50%的可能是凯子语料库的随机句子。举例而言:
- Input: [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label: IsNext
Input: [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
- Label: NotNext
其中, NotNext 句子是完全随机选的。
3.4 Pre-training Procedure
预训练数据集采用 BooksCorpus(800M)和English Wikipedia 语料。
为了生成每个训练输入序列,我们从语料库中抽取两段文本,我们将其称为“句子”,尽管它们通常比单个句子长得多(但也可以短一些)。第一句记做 A embedding,第二句记做 B embedding。 50% 的情况下B是A的真正后一句话, 50%情况下B是一个随机句子。两个句子的总长度 <= 512 个 tokens。
我们设 batch_size = 256 ,则有256 sequences * 512 tokens = 128,000 tokens/batch, 训练步数为1000000步,大约33亿 word corpus 中的40个epoch。优化算法采用 Adam, 学习率设为 1e-4, , L2 权重衰减为 0.01。 在所有层使用dropout, 概率为0.1. 我们采用gelu激活函数而非relu。 训练损失为 the sum of the mean masked LM likelihood and mean next sentence prediction likelihood.
- 在 16个TPU芯片上进行训练
- 在 64个TPU 芯片上进行训练
3.5 Fine-tuning Procedure
以分类问题为例, BERT的微调是很简单的。 我们将BERT输出层的隐层状态用于分类层的输入, 我们将该隐层状态记为 。微调时需要加入的参数为分类层的参数 , 其中,K是分类标签数。则有 , BERT所有的参数以及W都一起来最大化损失函数。
超参数设置:
- Batch size: 16, 32
- Learning rate(Adam): 5e-5, 3e-5, 2e-5
- Number of epoches: 3, 4
- dropout: 0.1
我们发现大数据集(100k+)对超参数没有小数据集那么敏感。
3.6 Comparison of BERT and OpenAI GPT
- GPT is trained on the BooksCorpus (800M words); BERT is trained on the BooksCorpus (800M words) and Wikipedia (2,500M words).
- GPT uses a sentence separator ([SEP]) and classifier token ([CLS]) which are only introduced at fine-tuning time; BERT learns [SEP], [CLS] and sentence A/B embeddings during pre-training.
- GPT was trained for 1M steps with a batch size of 32,000 words; BERT was trained for 1M steps with a batch size of 128,000 words.
- GPT used the same learning rate of 5e-5 for all fine-tuning experiments; BERT chooses a
task-specific fine-tuning learning rate which performs the best on the development set.
