@danren-aa120
2019-09-20T07:57:17.000000Z
字数 2734
阅读 797
第4课 感知
无人驾驶第一课:从Apollo起步
GitHub:感知模块相关资源
无人驾驶车感知世界的四个核心任务:
1)检测。找出物体在环境中的位置;
2)分类。明确对象是什么;
3)跟踪。随时间的推移观察移动物体,如其它车辆、自行车和行人;
4)语义分割。将图像出的每个像素与语义类别进行匹配,如道路、汽车或天空。
计算机视觉利用摄像头图像和激光雷达点云图像,进行对象分类
图像分类器是将图像作为输入,并输出标识该图像的标签或类别的算法.
摄像头传回的RGB(红绿蓝)图像中,量化一个颜色的概念, 可以尝试这个RGB Slider。
激光雷达传感器创建环境的点云特征,点云中的每个点代表反射回传感器的激光束。点云告诉我们关于物体的形状和表面纹理,通过对点进行聚类和分析,这些数据提供了足够的对象检测、 分类或跟踪信息。
卷积神经网络对感知问题特别有效,其结束多维输入,包括定义大多数传感器数据的二维和三维形状。
障碍物检测方面,汽车首先需要知道障碍物的位置(即检测),其次是对它们进行分类。之后,汽车根据所感知的物体类型,来确定自身的路径和速度。
1)如何进行检测和分类呢?
可以先使用检测CNN来查找图像中的对象的位置,在对图像中的对象进行定位后,可以将图像发送给另一个CNN进行分类。也可以使用单一CNN体系对图像进行检测和分类,即在单个网络体系的末端附加两个头,一个是检测定位,一个则执行分类,一个经典的体系结构为R-CNN及其变体Fast R-CNN和Faster R-CNN,YOLO和SSD是具有不同类似形式的不同体系结构。
2)为什么下一步要进行跟踪?
跟踪可以解决检测物体被遮挡检测算法失败时的问题,跟踪的第一步为确认移动物体身份,将在上一帧中检测到的所有对象与当前帧中检测到的对象进行匹配,在确定身份后,我们可以使用对象的位置,并结合预测算法,预测其在下一个时间步的速度和位置,以帮助在下一帧中的相应对象。例如跟踪的任务含有测量不同帧中检测到的物体的相似性,为检测到的车辆赋予身份标识,估计在前一帧中检测到但在当前帧中被遮挡的车辆的位置等。
预测的任务是预见其他车辆未来的行为, 跟踪是观察过去和现在的行为。不过,跟踪观察到的信息对于预测来说是很重要的一个输入。
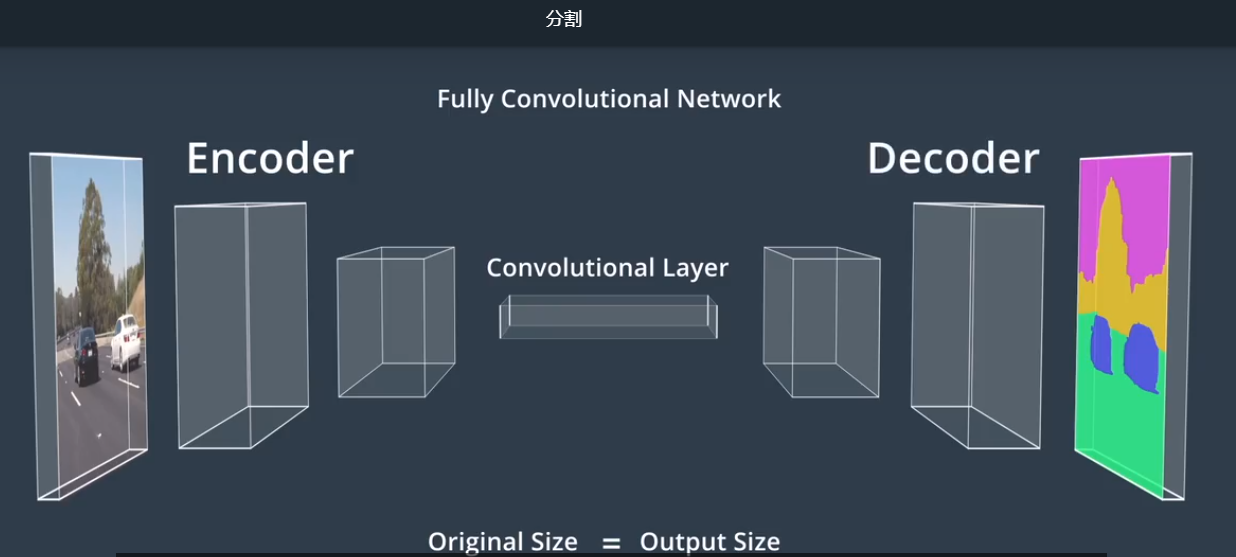
3)语义分割涉及对图像的每一个像素进行分类,用于尽可能详细地了解环境,并确定车辆可行驶区域。语义分割依靠全卷积网络(FCN),FCN用卷积层代替传统CNN末端的平坦层,因此网络中的每一层都是卷积层,所以叫全卷积网络。
Apollo感知
Apollo开放式软件栈可感知障碍物、交通信号灯和车道。
--对于三维对象检测,Apollo使用感兴趣区域(Region of Interest,RIO)来重点关注相关对象。其将RIO过了器应用于点云和图像数据,以缩小搜索范围并加快感知。然后通过检测网络反馈过了好的点云,输出用于构建围绕对象的三维边界框。
--交通信号灯用分类网络。
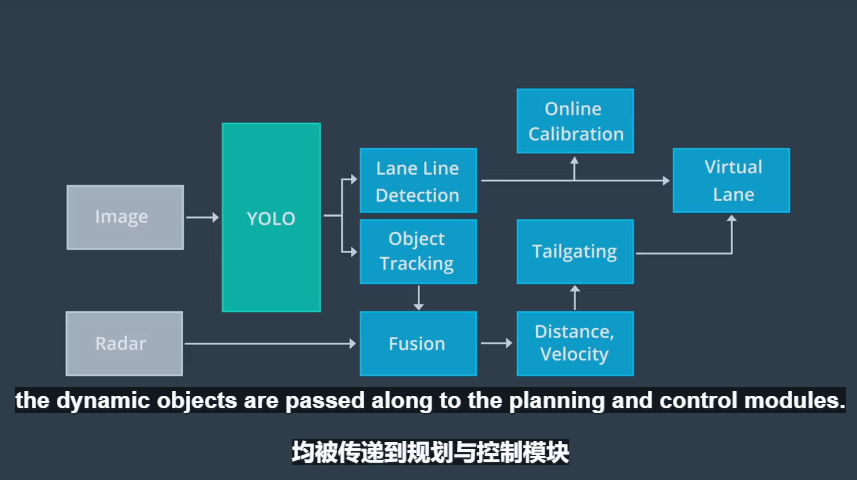
--Apollo使用YOLO网络来检测车道线和动态物体,其中包括车辆,卡车、骑车人和行人。在经过YOLO网络检测后,在线检测网络会并入来自其它传感器的数据,对车道线预测进行调整,形成虚拟车道;此外,对YOLO网络检测到的动态对象进行调整,以获得动态物体的类型、位置、速度、方向。虚拟通道和动态对象均被传递到规划与控制模块。
传感器数据比较

上图中第一行为障碍物检测。与激光雷达和摄像头相比,雷达分辨率较低,尤其是在垂直方向,分辨率非常有限。分辨率低意味着来自静态物体的反射可能产生问题,因此雷达通常会忽视静态物体,但动态物体可以,所以上上图针对动态物体跟踪选用Radar。雷达使用无线电波,而激光雷达则使用红激光束来确定传感器和附近对象的距离。目前,激光雷达还不能直接测量对象的速度,必须使用两次或多次扫描之间的位置差来确定,而雷达则通过多普勒效应来直接测量速度。
感知模块输入是:
128通道激光雷达数据(网络频道/阿波罗/传感器/ velodyne128)
16通道激光雷达数据(网络频道/阿波罗/传感器/ lidar_front,lidar_rear_left,lidar_rear_right)
雷达数据(网络频道/ apollo / sensor / radar_front,radar_rear)
图像数据(网络频道/阿波罗/传感器/摄像头/前6mm,前_12mm)
雷达传感器校准的外部参数(来自YAML文件)
前置摄像头校准的外在和内在参数(来自YAML文件)
主机的速度和角速度(网络频道/阿波罗/定位/姿势)
The perception module inputs are:
128 channel LiDAR data (cyber channel /apollo/sensor/velodyne128)
16 channel LiDAR data (cyber channel /apollo/sensor/lidar_front, lidar_rear_left, lidar_rear_right)
Radar data (cyber channel /apollo/sensor/radar_front, radar_rear)
Image data (cyber channel /apollo/sensor/camera/front_6mm, front_12mm)
Extrinsic parameters of radar sensor calibration (from YAML files)
Extrinsic and Intrinsic parameters of front camera calibration (from YAML files)
Velocity and Angular Velocity of host vehicle (cyber channel /apollo/localization/pose)
传感器数据融合
Apollo主要使用卡尔曼滤波算法,算法第一步为预测状态,第二步为更新测量结果(误差结果更新),更新分为对各类传感器数据同步更新和异步更新。
感知模块输出是:
3D障碍物跟踪航向,速度和分类信息(网络频道/阿波罗/感知/障碍物)
交通灯检测和识别的输出(网络频道/阿波罗/感知/交通灯)
The perception module outputs are:
The 3D obstacle tracks with the heading, velocity and classification information (cyber channel /apollo/perception/obstacles)
The output of traffic light detection and recognition (cyber channel /apollo/perception/traffic_light)
