@zsh-o
2019-04-18T08:13:53.000000Z
字数 11211
阅读 3676
Variational Mode Decomposition
数学
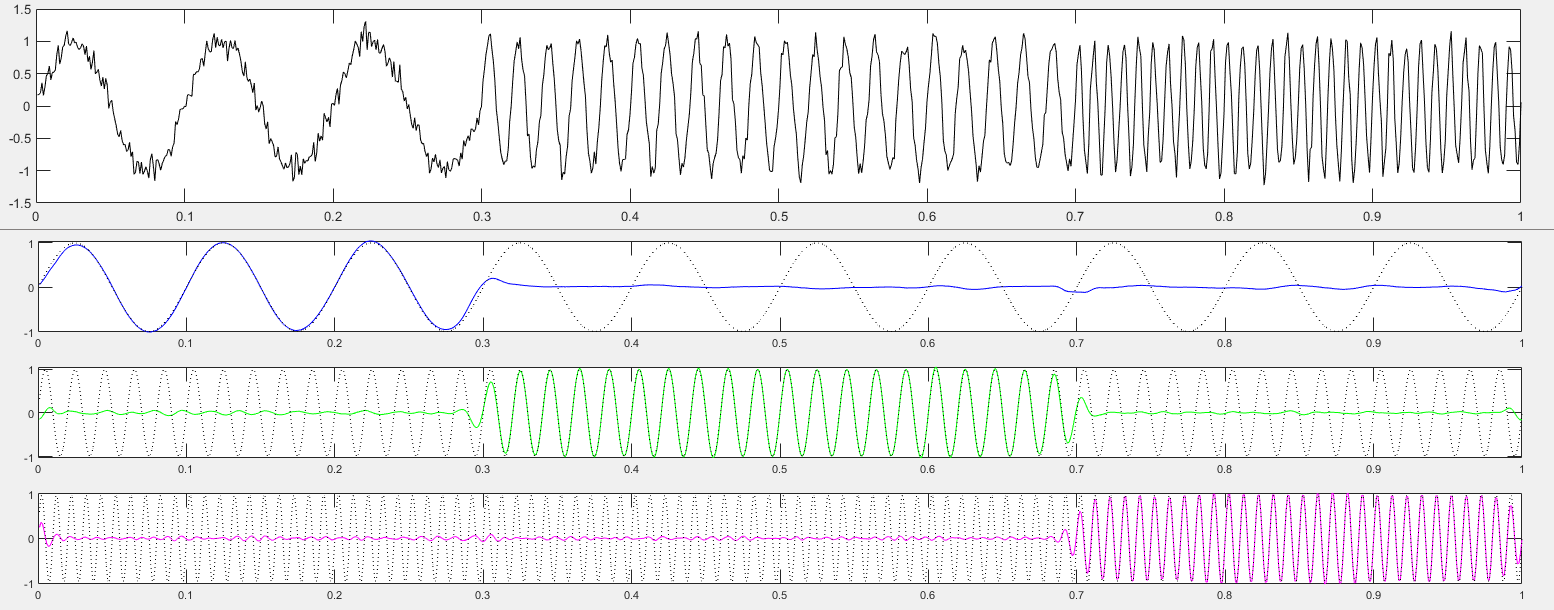
这一篇写一下变分模态分解(原始论文:Variational Mode Decomposition),跟原始论文思路思路一致但有一点点不太一样,原始论文写的很好,但我不是通信专业没有学过信号相关课程一开始看起来有点费劲。模态分解认为信号是由不同“模态”的子信号叠加而成的,而变分模态分解则认为信号是由不同频率占优的子信号叠加而成的,其目的是要把信号分解成不同频率的子信号。变分模态分解的分解结果如图所示
基础
一开始论文看不懂的原因是缺少相关前置知识,但一旦顺下来就会感觉其实没有那么难,难的是作者的思路很巧妙,先写下我遇到的这些知识盲点
第一点是傅立叶变换的微分性质,的傅立叶变换为,其导数的傅立叶变换为
另一点是解析信号,现实世界只能采集实信号,但实信号有很多不好用的性质,如存在负频率,无法直接得到调制频率后的实信号等。
设原始信号是一个实信号
matlab脚本
clear;close all;clc;t = 1:0.01:10;%%f1 = sin(20*t).*(t-5).^2;subplot(3,1,1);plot(f1);ylim([-25 25]);%%f2 = sin(50*t).*(t-5).^2;subplot(3,1,2);plot(f2);ylim([-25 25]);%%H = hilbert(f1);f_hat = H.*exp(1i*30.*t);subplot(3,1,3);plot(real(f_hat));ylim([-25 25]);
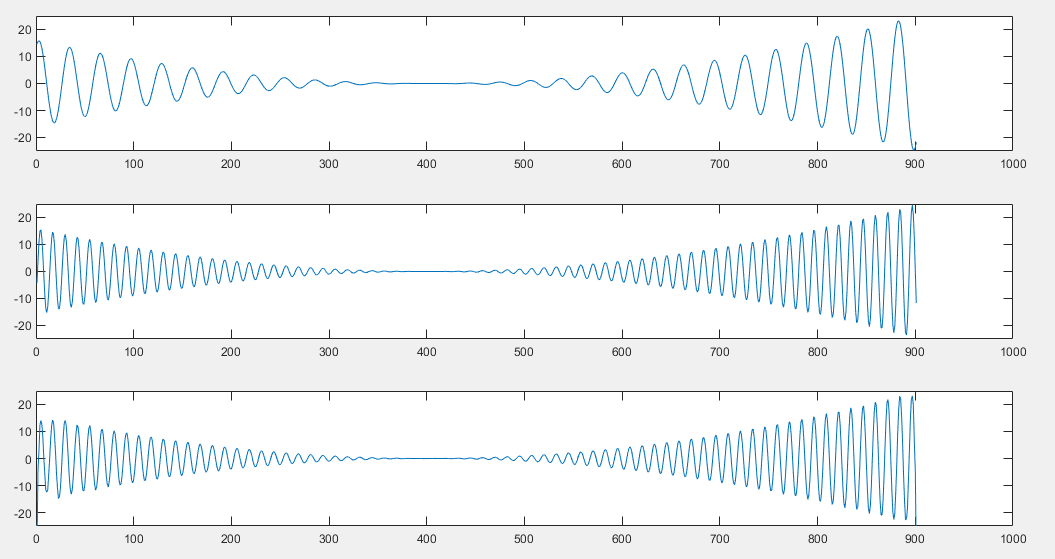
matlab的hilbert函数包括希尔伯特变换和解析函数转换两部分,直接得到实信号的解析信号,其中希尔伯特变换
正文
接下来我们看看如何一步一步得到变分模态分解的思路
原论文通过一个信号降噪问题进行说明,现需要对采样信号进行降噪重构,假设观测信号是由原始信号叠加一个独立的高斯噪音
下面解这个式子,首先来看一下直接最小化泛函能不能解出来
由上面的傅立叶变换的微分性质知道,用傅立叶变换在复数域很方便可以把微分约掉,而且还有一个叫什么Plancherel傅立叶等距映射的东西,时域的L2范数与傅立叶变换到的频率域的L2范数等距,故上面的最小化的项可以直接用傅立叶变换转换到频域
可以看到得到的相当于对观测信号在在频率段进行滤波,过滤掉了高频部分,这说明加了该导数的L1正则约束与上面的直观感觉是一样的,过滤掉了高频部分,减弱的波动
再往下进行,模态分解需要把原始信号分解成多个子信号的和,我们为了和原文对应修改一下符号表示,表示观测的采样信号,表示分解得到的基函数,则上面的约束对象变为
到现在为止我们发现每个基函数都会趋向于每次的剩余信号分量的低频部分,这与我们原始的假设“每个基函数都有不同的频率分量”是相悖的,但根据上面的低通滤波的性质,每个基函数进行特定频率的滤波应该就能解决这个问题了,那么上面的式子就简单的变为
由上面的一步一步的演化发现,基函数对剩余信号的低通滤波是由导数的L2正则最小化带来的,要得到基函数的中心频率约束也要从这个地方入手,由上面的推导可知每个基函数都会被约束到频率附近,那么我们把基函数的频率增加各自的中心频率得到,并保证即可,则相当于对每个基函数乘以了一个,这里需要对频率进行变换,我们沿用文章开头的解析信号的性质,认为是一个复数的解析信号,同样也需要把观测信号预先转化为解析信号,下文默认都是解析信号,则每一个基函数转换频率后的导数变为
反傅立叶变换
至此,约束变为
傅立叶变换
最后,为了保证每个点处的重构信号与原信号尽可能相似,增加了每个点处的重构约束,其实这一项并不是必需的,最终的约束对象为
最后整理一下更新公式:
代码
%matplotlib inlinefrom matplotlib import pyplot as pltimport numpy as npfrom scipy.signal import hilbert
T = 1000fs = 1./Tt = np.linspace(0, 1, 1000,endpoint=True)
f_1 = 10f_2 = 50f_3 = 100mode_1 = (2 * t) ** 2mode_2 = np.sin(2 * np.pi * f_1 * t)mode_3 = np.sin(2 * np.pi * f_2 * t)mode_4 = np.sin(2 * np.pi * f_3 * t)f = mode_1 + mode_2 + mode_3 + mode_4 + 0.5 * np.random.randn(1000)
plt.figure(figsize=(6,3), dpi=150)plt.plot(f, linewidth=1)
[<matplotlib.lines.Line2D at 0x7fac533f6780>]
class VMD:def __init__(self, K, alpha, tau, tol=1e-7, maxIters=200, eps=1e-9):""":param K: 模态数:param alpha: 每个模态初始中心约束强度:param tau: 对偶项的梯度下降学习率:param tol: 终止阈值:param maxIters: 最大迭代次数:param eps: eps"""self.K =Kself.alpha = alphaself.tau = tauself.tol = tolself.maxIters = maxItersself.eps = epsdef __call__(self, f):T = f.shape[0]t = np.linspace(1, T, T) / Tomega = t - 1. / T# 转换为解析信号f = hilbert(f)f_hat = np.fft.fft(f)u_hat = np.zeros((self.K, T), dtype=np.complex)omega_K = np.zeros((self.K,))lambda_hat = np.zeros((T,), dtype=np.complex)# 用以判断u_hat_pre = np.zeros((self.K, T), dtype=np.complex)u_D = self.tol + self.eps# 迭代n = 0while n < self.maxIters and u_D > self.tol:for k in range(self.K):# u_hatsum_u_hat = np.sum(u_hat, axis=0) - u_hat[k, :]res = f_hat - sum_u_hatu_hat[k, :] = (res - lambda_hat / 2) / (1 + self.alpha * (omega - omega_K[k]) ** 2)# omegau_hat_k_2 = np.abs(u_hat[k, :]) ** 2omega_K[k] = np.sum(omega * u_hat_k_2) / np.sum(u_hat_k_2)# lambda_hatsum_u_hat = np.sum(u_hat, axis=0)res = f_hat - sum_u_hatlambda_hat -= self.tau * resn += 1u_D = np.sum(np.abs(u_hat - u_hat_pre) ** 2)u_hat_pre[::] = u_hat[::]# 重构,反傅立叶之后取实部u = np.real(np.fft.ifft(u_hat, axis=-1))omega_K = omega_K * Tidx = np.argsort(omega_K)omega_K = omega_K[idx]u = u[idx, :]return u, omega_K
K = 4alpha = 2000tau = 1e-6vmd = VMD(K, alpha, tau)
u, omega_K = vmd(f)
omega_K
array([0.85049797, 10.08516203, 50.0835613, 100.13259275]))
plt.figure(figsize=(5,7), dpi=200)plt.subplot(4,1,1)plt.plot(mode_1, linewidth=0.5, linestyle='--')plt.plot(u[0,:], linewidth=0.2, c='r')plt.subplot(4,1,2)plt.plot(mode_2, linewidth=0.5, linestyle='--')plt.plot(u[2,:], linewidth=0.2, c='r')plt.subplot(4,1,3)plt.plot(mode_3, linewidth=0.5, linestyle='--')plt.plot(u[1,:], linewidth=0.2, c='r')plt.subplot(4,1,4)plt.plot(mode_4, linewidth=0.5, linestyle='--')plt.plot(u[3,:], linewidth=0.2, c='r')
[<matplotlib.lines.Line2D at 0x7fac532f4dd8>]
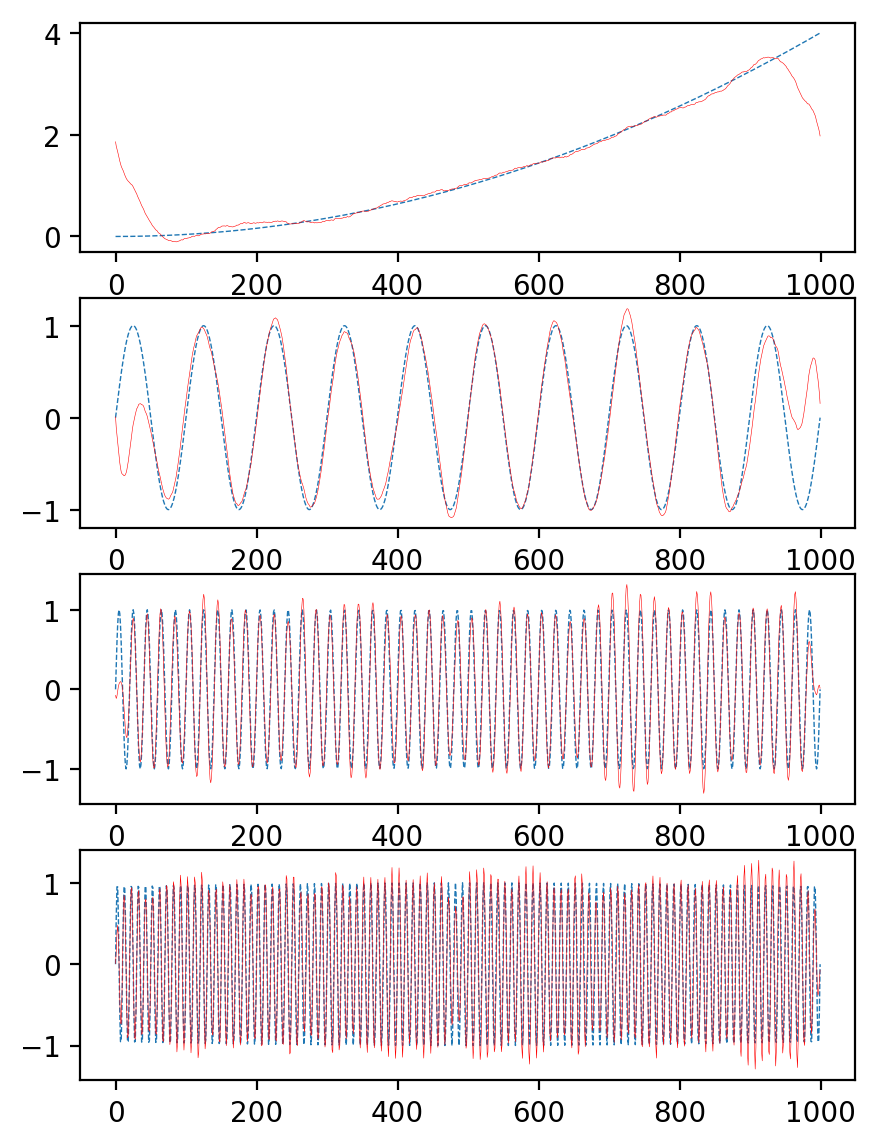
可以看到有比较强的端点效应,端点处会有重叠,文章原始论文中采用的方法是对称拼接的方法,把原信号复制一份然后拼成两半,一半对称放前面,一般对称放后面
%matplotlib inlinefrom matplotlib import pyplot as pltimport numpy as npfrom scipy.signal import hilbert
T = 1000fs = 1./Tt = np.linspace(0, 1, 1000,endpoint=True)
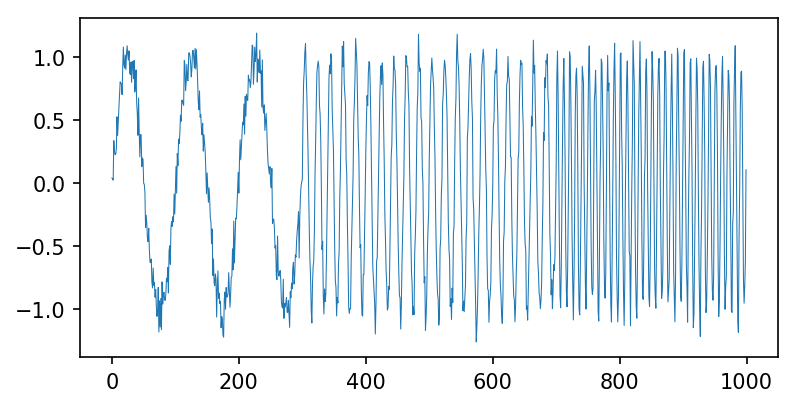
f_1 = 10f_2 = 50f_3 = 100mode_1 = np.sin(2 * np.pi * f_1 * t)mode_2 = np.sin(2 * np.pi * f_2 * t)mode_3 = np.sin(2 * np.pi * f_3 * t)f = np.concatenate((mode_1[:301], mode_2[301:701], mode_3[701:])) + 0.1 * np.random.randn(1000)
plt.figure(figsize=(6,3), dpi=150)plt.plot(f, linewidth=0.5)
[<matplotlib.lines.Line2D at 0x7fc2134b8630>]
class VMD:def __init__(self, K, alpha, tau, tol=1e-7, maxIters=200, eps=1e-9):""":param K: 模态数:param alpha: 每个模态初始中心约束强度:param tau: 对偶项的梯度下降学习率:param tol: 终止阈值:param maxIters: 最大迭代次数:param eps: eps"""self.K =Kself.alpha = alphaself.tau = tauself.tol = tolself.maxIters = maxItersself.eps = epsdef __call__(self, f):N = f.shape[0]# 对称拼接f = np.concatenate((f[:N//2][::-1], f, f[N//2:][::-1]))T = f.shape[0]t = np.linspace(1, T, T) / Tomega = t - 1. / T# 转换为解析信号f = hilbert(f)f_hat = np.fft.fft(f)u_hat = np.zeros((self.K, T), dtype=np.complex)omega_K = np.zeros((self.K,))lambda_hat = np.zeros((T,), dtype=np.complex)# 用以判断u_hat_pre = np.zeros((self.K, T), dtype=np.complex)u_D = self.tol + self.eps# 迭代n = 0while n < self.maxIters and u_D > self.tol:for k in range(self.K):# u_hatsum_u_hat = np.sum(u_hat, axis=0) - u_hat[k, :]res = f_hat - sum_u_hatu_hat[k, :] = (res - lambda_hat / 2) / (1 + self.alpha * (omega - omega_K[k]) ** 2)# omegau_hat_k_2 = np.abs(u_hat[k, :]) ** 2omega_K[k] = np.sum(omega * u_hat_k_2) / np.sum(u_hat_k_2)# lambda_hatsum_u_hat = np.sum(u_hat, axis=0)res = f_hat - sum_u_hatlambda_hat -= self.tau * resn += 1u_D = np.sum(np.abs(u_hat - u_hat_pre) ** 2)u_hat_pre[::] = u_hat[::]# 重构,反傅立叶之后取实部u = np.real(np.fft.ifft(u_hat, axis=-1))u = u[:, N//2 : N//2 + N]omega_K = omega_K * T / 2idx = np.argsort(omega_K)omega_K = omega_K[idx]u = u[idx, :]return u, omega_K
K = 3alpha = 2000tau = 1e-6vmd = VMD(K, alpha, tau)
u, omega_K = vmd(f)
omega_K
array([ 9.64477193, 50.06365397, 100.18114375])
plt.figure(figsize=(5,7), dpi=200)plt.subplot(3,1,1)plt.plot(mode_1, linewidth=0.5, linestyle='--')plt.plot(u[0,:], linewidth=0.2, c='r')plt.subplot(3,1,2)plt.plot(mode_2, linewidth=0.5, linestyle='--')plt.plot(u[1,:], linewidth=0.2, c='r')plt.subplot(3,1,3)plt.plot(mode_3, linewidth=0.5, linestyle='--')plt.plot(u[2,:], linewidth=0.2, c='r')
[<matplotlib.lines.Line2D at 0x7fc2134075c0>]
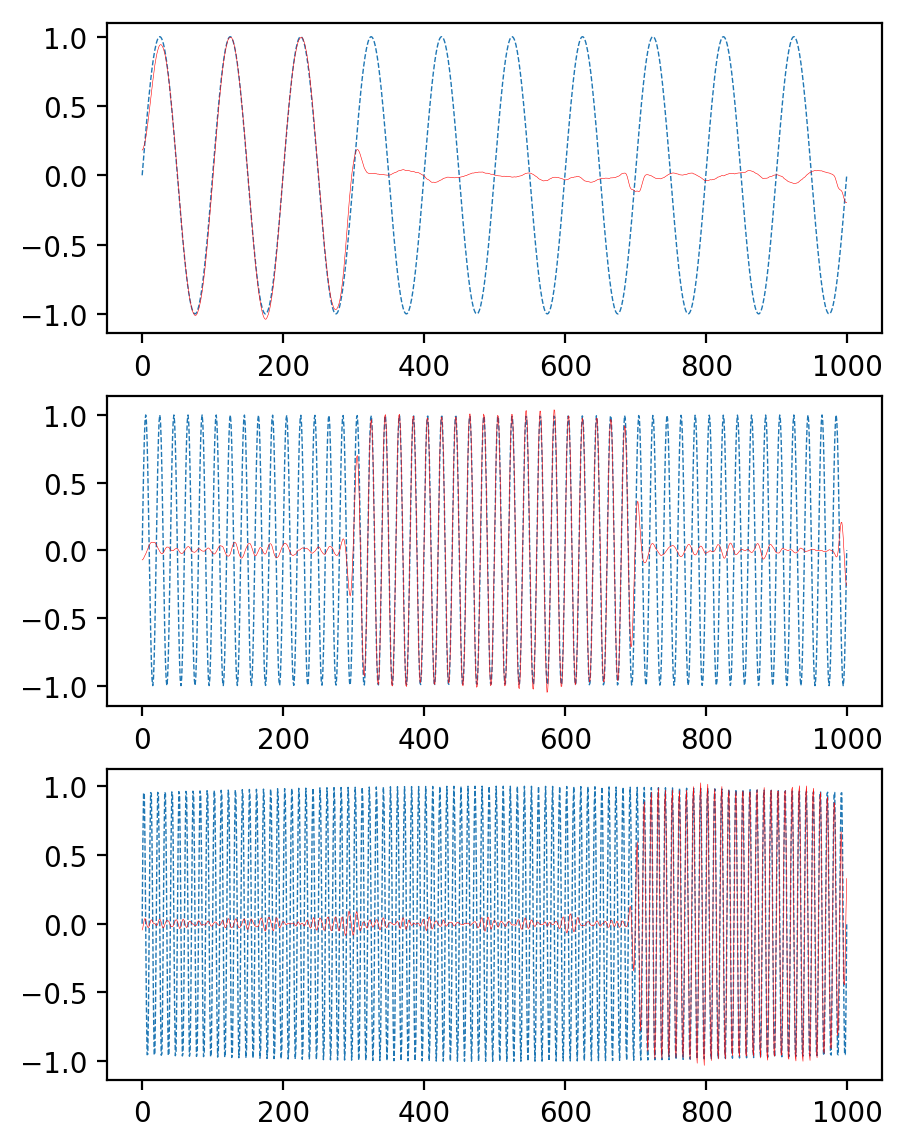
好像结果要好一点,VMD的一个缺点是K的值对结果有很大影响,但这个迭代过程,怎么开始怎么迭代怎么结束都可以自己控制,感觉可以按照自己的需求来定制怎么动态决定K
