@zsh-o
2018-08-26T12:39:36.000000Z
字数 6323
阅读 1572
2 - 感知器
《统计学习方法》
%matplotlib inlineimport numpy as npfrom matplotlib import pyplot as plt
epsilon = 1e-5
原始形式
输入空间,输出空间,映射如下
有一点需要注意的是感知机假设数据集是线性可分的,也就是会有一个分割超平面会把数据集完全正确的分隔开
输入空间中一点到超平面的距离为
由于在超平面下的分类结果为
误分类点可判定为
损失函数设定为误分类点的集合为到超平面的总距离为,
不考虑,损失函数为
最小化需要对其求梯度
进行梯度下降的时候需要注意,每次只选取一个误分类点进行梯度下降
如果原始数据集线性不可分,会陷入无限循环
def perceptron(X, Y, eta):w = np.zeros(X.shape[1])b = 0M = []def get_M():M.clear()for index, (x, y) in enumerate(zip(X, Y)):if y*(np.dot(w, x) + b) <= 0:M.append(index)return Mwhile len(get_M()) > 0:i = np.random.choice(M)x, y = X[i], Y[i]w = w + eta * y * xb = b + eta * yreturn w, b
例2.1
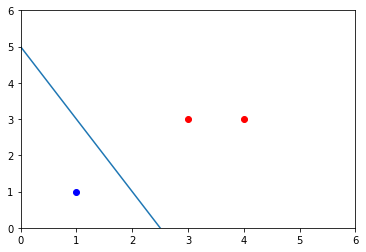
## 例2.1X = np.array([[3,3],[4,3],[1,1]])Y = np.array([[1], [1], [-1]])w, b = perceptron(X, Y, 1)w, b
(array([2., 1.]), array([-5]))
postive_X = X[np.where(Y>0)[0]]plt.plot(postive_X[:,0], postive_X[:,1], 'ro')negative_X = X[np.where(Y<0)[0]]plt.plot(negative_X[:,0], negative_X[:,1], 'bo')aX = np.arange(0, 6, 0.1)aY = (-b - w[0]*aX)/(w[1]+epsilon)plt.axis([0,6, 0, 6])plt.plot(aX, aY)
算法收敛性
需要证明算法的迭代次数存在上界,,经过有限次迭代可以得到一个将训练数据集完全正确划分的分离超平面。这个证明是Novikoff在1962年给出的,收敛证明很重要
定理 2.1 (Novikoff) 设训练数据集是线性可分的,其中,,,则
- 存在满足条件的超平面将训练数据集完全正确分开;且满足,对所有
- 令,则感知器在训练数据集上的误分类次数满足不等式
证明:
- 由于训练数据集是线性可分的,所以存在超平面使训练集完全正确的分开,可取该超平面为,并满足,故对所有的训练数据集
所以存在
- 设表示第次迭代得到的参数,并且第k次迭代中根据判别条件得到的误分类样例为,则和的更新为
即
现在推倒两个不等式:
- (1)
推倒:
- (2)
推倒:
结合上面几个不等式:
这个地方用了柯西-施瓦茨不等式的向量内积形式:,并且
整理得到
对偶形式
这个对偶形式的思想异常重要
对偶形式的基本思想为,将和表示为实例和标记的线性组合的形式,通过求解其系数而求得和。
书上这个地方给出了一种直观上的对偶问题的解释,而SVM中的对偶形式是由拉格朗日乘子法求出来的,但朗格朗日乘子法的核心思想也是:所构建的超平面需要满足在训练数据集上的约束,利用朗格朗日乘子法把该约束加到损失函数里面,可以求出来原始原始参数的用训练数据集的表示形式(这里是线性组合,SVM也是线性组合),把参数带入到损失函数里面,得到对偶形式
对于每次的误分类点,的迭代为
可把这个过程看成训练过程中的每次选取的误分类点均对其有影响,假设每个数据点误分类次数为,则该点的总影响为,则上式变为其对偶形式
故在迭代过程中每次选取误分类点,对应的更新方程为
表示第个实例点由于误分而进行更新的次数,实例点更新次数越多,意味着它距离分离超平面越近,也就越难正确分类。换句话说,这样的实例对学习结果影响最大
def perceptron_duality(X, Y, eta):alpha = np.zeros((X.shape[0], 1)) ## 整个过程中每个样本误分类的次数n_ib = 0M = []def get_M():M.clear()w = eta * np.sum(alpha * Y * X, axis=0)for index, (x, y) in enumerate(zip(X, Y)):if y*(np.dot(w, x) + b) <= 0:M.append(index)return Mwhile len(get_M()) > 0:i = np.random.choice(M)x, y = X[i], Y[i]alpha[i] = alpha[i] + 1b = b + eta * yw = eta * np.sum(alpha * Y * X, axis=0)return w, b, alpha
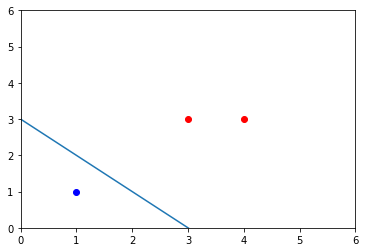
## 例2.2X = np.array([[3,3],[4,3],[1,1]])Y = np.array([[1], [1], [-1]])w, b, alpha = perceptron_duality(X, Y, 1)w, b
(array([1., 1.]), array([-3]))
postive_X = X[np.where(Y>0)[0]]plt.plot(postive_X[:,0], postive_X[:,1], 'ro')negative_X = X[np.where(Y<0)[0]]plt.plot(negative_X[:,0], negative_X[:,1], 'bo')aX = np.arange(0, 6, 0.1)aY = (-b - w[0]*aX)/(w[1]+epsilon)plt.axis([0,6, 0, 6])plt.plot(aX, aY)alpha
array([[2.],
[0.],
[5.]])
def perceptron_duality_gram(X, Y, eta):alpha = np.zeros((X.shape[0], 1)) ## 整个过程中每个样本误分类的次数n_ib = 0M = []Gram_Matrix = np.dot(X, X.T)def get_M():M.clear()for index, (x, y) in enumerate(zip(X, Y)):if y*(eta * np.sum(Gram_Matrix[index, :][:, np.newaxis] * Y * alpha) + b) <= 0:M.append(index)return Mwhile len(get_M()) > 0:i = np.random.choice(M)x, y = X[i], Y[i]alpha[i] = alpha[i] + 1b = b + eta * yw = eta * np.sum(alpha * Y * X, axis=0)return w, b, alpha
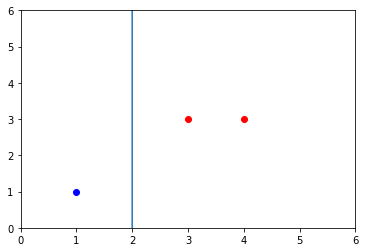
## 例2.2X = np.array([[3,3],[4,3],[1,1]])Y = np.array([[1], [1], [-1]])w, b, alpha = perceptron_duality_gram(X, Y, 1)w, b
(array([1., 0.]), array([-2]))
postive_X = X[np.where(Y>0)[0]]plt.plot(postive_X[:,0], postive_X[:,1], 'ro')negative_X = X[np.where(Y<0)[0]]plt.plot(negative_X[:,0], negative_X[:,1], 'bo')aX = np.arange(0, 6, 0.1)aY = (-b - w[0]*aX)/(w[1]+epsilon)plt.axis([0,6, 0, 6])plt.plot(aX, aY)alpha
array([[0.],
[1.],
[3.]])
柯西-施瓦茨不等式
有维向量,,其内积满足不等式
展开
当且仅当共线时等式成立,网上一共给出了三种证法
证法1
共线需要满足,对所有的成立,让
当,所有,此时不等式成立
当,因为恒成立,所以成立(极值点:)
证法2
证法2利用的二次方程组无解或有唯一解时判别式小于等于0,故
