@zsh-o
2018-06-07T10:06:15.000000Z
字数 7424
阅读 4765
Expectation Maximisation (EM)
机器学习
最近在看混合模型,但发现最基本的EM都没有真正学懂,看Richard的课件很有启发,整理一下,主要是高斯混合模型下的EM的公式推导和收敛证明
单高斯分布的极大似然估计(Maximum Likelihood Estimation)
假设数据是由单个高斯分布产生的 ,我们有观测值 ,需要根据这些观测值估计出高斯分布的参数 和 ,由于单个高斯很简单,只需要最大化似然概率即可
高斯混合模型(Gaussian Mixture Model)
概率模型是对观测数据概率的估计,混合模型采用多个分布线性组合的方法来估计数据的真实分布,K个高斯概率密度的叠加
如果把 看作是每个出现的概率 ,那么模型等价于一个条件概率,那么生成的路径需要经过两个步骤,首先从概率 得到一个分布,然后再在这个分布中得到 ,那么其边缘概率密度为
虽然在路径上其最终是由单个分布产生的,但其在整个分布上来说是由多个基本分布线性叠加的(求期望,把积分掉), 那么的后验分布 表示观测属于每一个的概率, 是一个离散概率 , 根据贝叶斯公式得
其对数似然为
由于对数里面有一个求和式, 的方法太复杂
引入隐变量, z服从多项式分布, 表示有k个状态, 每次以一定的概率从这些状态中选择一个, 代表第个观测值是从第个分布产生的, 则可以表示成
EM
用以迭代的方法估计具有隐变量的概率模型, 思想是
- E-step: 在现有 下最大化似然下界, 计算隐变量 的期望 作为其下界
- M-step: 在上面 下计算参数列表 来最大化似然
Jensen不等式
为凸函数, , 当为向量,如果其hessian矩阵H是半正定的()。如果或者, 是严格凸函数
Jessen不等式: 如果是凸函数, 。当且仅当 是常量 的时候,
EM推导
引入隐变量z之后的对数似然函数为
这里定义是关于的函数, 并且 , 函数的期望 , 那么对于上式来说, 对应 表示 的概率, 对应 表示 的函数,而且为凹函数, 最后根据Jensen不等式
在这里我们要最大化这个似然函数的下界,也即是使函数 为常数
对公式进行变换,
执行完上面E-step之后下界重合, 这时取等号, 似然变为
现在要对公式求导再等于0求方程得到最优的参数列表
这时得到 步的似然函数 , 现在要证明EM的收敛性只需要证明 ,
GMM
E-step: 已知, 求此时的
M-step: 已知,求此时的
计算 :
利用拉格朗日乘数法添加约束项
求导得
对上式整理并相加得
由于
得到
则,
计算 :
对 求偏导得
得
计算 :
上面式子对 求偏导得
得
由公式可以得到, 和 是通过 对观测数据进行加权平均
从KL散度角度解释EM
KL散度角度是用 来估计 的后验概率 , 则其KL散度为
这里 是上面说的对数似然, 是kl散度, 在变分推理里面叫变分自由能, 是一个泛函, 当 时等号成立
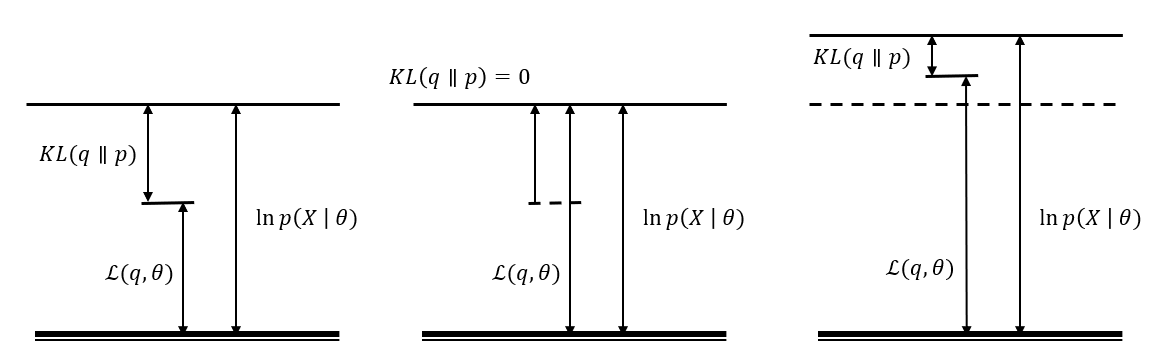
在EM的E步骤里此时的 是已知的保持其固定, 我们通过最小化kl散度的下界也即 , 使得 达到其上界
在M步骤里, 保持 求此时的 使 最大化, 这时三个值的上界都提高了
