@zsh-o
2018-08-14T02:03:21.000000Z
字数 4257
阅读 1535
3 - k近邻
《统计学习方法》
%matplotlib inlineimport numpy as npfrom matplotlib import pyplot as pltepsilon = 1e-5
import pydotfrom IPython.display import Image, displaydef viewPydot(pdot):plt = Image(pdot.create_png())display(plt)
def kNN(x, X, Y, k, p): # y [0, N-1]m,n = X.shapeclass_N = np.max(Y) + 1diffs = np.abs(np.tile(x, (m, 1)) - X)if p is np.inf:diss = np.max(diffs, axis=1)else:diss = np.power(np.sum(np.power(diffs, p), axis=1), 1./p)args = np.argsort(diss)[:k]countY = np.zeros(class_N)for index in args:countY[index] = countY[index] + 1return np.argmax(countY)
例3.1
X = np.array([[5,1],[4,4],])Y = np.array([[0],[1],])
for i in range(1,6):print("%d -> %d"%(i, kNN(x=np.array([1,1]), X=X, Y=Y, k=1, p=i)))
1 -> 0
2 -> 0
3 -> 1
4 -> 1
5 -> 1
最近邻性能分析
《西瓜书》给出了最近邻的性能分析,这里只是只是表示最近邻(用距离最近的训练样本的类别作为输入的类别)
在大样本(独立同分布,且样本量无穷)下最近邻规则的泛化错误率不超过贝叶斯最优分类器(所有概率关系已知)的错误率的两倍
测试样本为,其最近邻样本为,则最近邻分类器出错的概率为的标记与不同的概率
这里的概率均是在所有概率已知的情况下的分析,泛化错误率,则贝叶斯最优分类器的结果为
对应的错误率为
由于样本符合独立同分布且有无限的样本,所以对任意的和任意小正整数,在附近范围内总能找到一个训练样本;换成人话就是,在无限样本且符合独立同分布下,样本与其近邻无限靠近,故
还有个关于最近邻的不等式,是《西瓜书》习题上的,是上面不等式的细化,设R为在整个n个样本集中的错误率的期望
整理
由柯西-施瓦茨不等式得到
可以得到
最后有
则对所有数据集
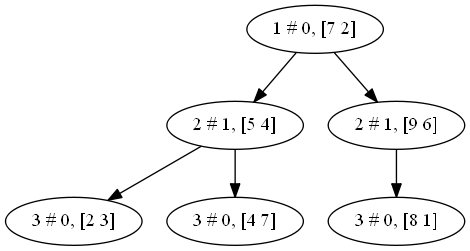
kd树
A = np.array([[2,3],[5,4],[9,6],[4,7],[8,1],[7,2]])
def D(X):return np.mean(np.power(X - np.mean(X,axis=0), 2), axis=0)
class Node(object):def __init__(self, p=None, dim=None, lc=None, rc=None):self.p = pself.dim = dimself. lc = lcself.rc = rcself.visited = False
def kd_Tree(X):if(len(X) == 0):return None;N = X.shape[0]## 选择需要划分的维度Ds = D(X)dim = np.argmax(Ds)X = np.array(sorted(X, key=lambda x:x[dim]))root = Node()root.p = X[int(N/2)]root.dim = dimroot.lc = kd_Tree(X[:int(N/2)])root.rc = kd_Tree(X[int(N/2)+1:])return root
搜索
搜索也很简单,首先按照二分的方法搜索找到最优的候选叶子节点,然后向上回溯,查看父节点的未访问到的节点是否有小于候选节点与目标节点距离,小于则更新候选节点
判断目标节点到该轴的距离是否小于最小距离
def kd_search(root, x):global min_disglobal min_nodemin_dis = np.infmin_node = Nonedef _search(t): ## 递归global min_disglobal min_nodeif ((x[t.dim] < t.p[t.dim]) & (t.lc is None)) | ((x[t.dim] >= t.p[t.dim]) & (t.rc is None)): ## 叶子节点,二分查找的最优候选节点dis = np.sqrt(np.sum(np.power(t.p - x, 2)))if dis <= min_dis:min_dis = dismin_node = t.pt.visited = Truereturnelse:if x[t.dim] < t.p[t.dim]:_search(t.lc)else:_search(t.rc)if np.abs(x[t.dim] - t.p[t.dim]) >= min_dis:t.visited = Trueelse:if x[t.dim] > t.p[t.dim]:_search(t.rc)else:_search(t.lc)dis = np.sqrt(np.sum(np.power(t.p - x, 2)))if dis <= min_dis:min_dis = dismin_node = t.pt.visited = True_search(root)return min_node, min_dis
tree = kd_Tree(A)
kd_search(tree, np.array([4,3]))
(array([5, 4]), 1.4142135623730951)
dot = pydot.Dot()global levellevel = 1def create_dot(p):global levelp_name = "%d # %d, %s" % (level, p.dim, str(p.p))dot.add_node(pydot.Node(name=p_name))if p.lc is not None:level = level + 1c = p.lcc_name = "%d # %d, %s" % (level, c.dim, str(c.p))dot.add_edge(pydot.Edge(dst=c_name, src=p_name))create_dot(c)level = level -1if p.rc is not None:level = level + 1c = p.rcc_name = "%d # %d, %s" % (level, c.dim, str(c.p))dot.add_edge(pydot.Edge(dst=c_name, src=p_name))create_dot(c)level = level -1
create_dot(tree)viewPydot(dot)