@wanghuijiao
2021-12-16T07:59:58.000000Z
字数 7603
阅读 11072
CVAT半自动标注:如何添加自己的预训练模型
技术文档
0. 前言
- CVAT提供了半自动标注功能提高标注效率,官方提供了一些预训练模型,比如detectron2库faster_rcnn、mask_rcnn、retinanet等,以及yolov3、siammask等,当官方提供的模型检测类别不满足需求或者精度不够时,如何添加个人的预训练模型呢?下文将介绍如何添加自己的预训练模型到CVAT。
- 本文档将重点介绍以下几个问题:
- 如何添加新模型库到CVAT
- 如何从已支持的模型库中添加新模型到CVAT
- 以下操作均在10.0.40.92上进行,10.0.40.92服务器上已经部署了CVAT,后续新增模块库和新模型均需要在10.0.40.92服务器上进行。前期CVAT部署相关操作此处按下不表,以下教程均默认在已有CVAT工具基础上进行新增操作。
1. 如何添加新模型库到CVAT
- 以yolov5为例,添加新库到CVAT需要
- 建立yolov5库的本地镜像
- 准备CVAT部署相关文件:function.yaml、main.py、model_handler.py、模型权重文件,比如yolov5s.pt
- 运行部署命令:
nuclio deploy ...
- 以新增yolov5库的yolov5s为例,说明如何新增yolov5s到CVAT半自动标注功能。
1.1 建立yolov5库的本地镜像
- 在10.0.40.92服务器上,下载yolov5库
git clone git@github.com:ultralytics/yolov5.git yolov5cd yolov5
- 在./yolov5路径下,准备Dockerfile_cvat,内容如下
FROM ultralytics/yolov5:latest # yolov5官方镜像RUN mkdir -p /opt/nuclio # 创建工作目录,该路径是CVAT默认工作路径,必须有WORKDIR /opt/nuclio # 指定工作目录COPY . /opt/nuclio # 复制当前路径下所有的文件到docker中
- 在yolov5路径下,运行以下命令,建立镜像,请自行替换 yolov5_whj_test:v1 为你自己的镜像名称和版本,建好镜像后自行测试建立的镜像是否可以成功运行。
docker build -t yolov5_whj_test:v1 -f Dockerfile_cvat .
1.2. 准备CVAT部署相关文件
- 在
/ssd/wanghuijiao/cvat/serverless/pytorch路径下,新建yolov5/yolov5s/nuclio文件夹。 - 准备function.yaml、main.py、model_handler.py、权重文件yolov5s.pt到
/ssd/wanghuijiao/cvat/serverless/pytorch/yolov5/yolov5s/nuclio,以下将详细说明如何准备function.yaml、main.py、model_handler.py三个文件。 function.yaml:nuclio工具的配置文件,用于部署预训练模型到CVAT,nuclio将yolov5s作为serverless function部署到cvat,可以理解为nuclio为yolov5s创建了一个可以接入到cvat的docker镜像+容器。建立镜像的过程是通过function.yaml配置的,更多请看nuclio官方教程.
metadata:name: pth.ultralytics.yolov5.yolov5s_xxx # 此项是CVAT的function名称,根据新模型名称自行更改namespace: cvatannotations:name: yolov5s_xxx # 此项是CVAT UI界面半自动标注功能处显示的模型名称,根据新模型名称更改type: detectorframework: pytorchspec: | # 此处记录yolov5s的检测类别信息,需要根据新模型的类别信息对应更改[{ "id": 1, "name": "head" },{ "id": 2, "name": "person" }]spec:description: yolov5_xxx from yolov5 # 此项是模型描述信息,根据新模型功能更改runtime: 'python:3.7'handler: main:handlereventTimeout: 30sbuild:image: cvat/pth.ultralytics.yolov5.yolov5s_xxx:vx # 镜像名称:镜像版本,根据需求自行更改baseImage: shuyh_cvat_yolo:v1 # yolov5在本地的基础镜像,根据1.1中的本地镜像名称自行替换directives: # 建立镜像的命令,类比Dockerfile内容,但目前不支持COPY、ADD等命令,RUN、WORKDIR命令可以preCopy:- kind: WORKDIRvalue: /opt/nuclio # cvat的默认路径,不需要更改triggers:myHttpTrigger: # 描述http触发,用于处理http请求,个人理解是处理来自前端的请求信号,默认不改maxWorkers: 1kind: 'http'workerAvailabilityTimeoutMilliseconds: 10000attributes:maxRequestBodySize: 33554432 # 32MBresources:limits:nvidia.com/gpu: 1 # GPU 最多使用数量限制,可根据需求更改platform: # 描述运行yolov5s时的重要参数,比如restartPolicy描述建立镜像失败时尝试的次数等信息,更多请看nuclio官方教程,默认不改attributes:restartPolicy:name: alwaysmaximumRetryCount: 3mountMode: volume
model_handler.py:加载模型,提供在gpu上推理一张图片的方法,重点注意返回值的格式
class ModelHandler:def __init__(self, weights='/opt/nuclio/yolov5s.pt', device='0', dnn=False):# 加载模型self.device = select_device(device)self.model = DetectMultiBackend(weights=weights, device=self.device, dnn=dnn)def infer(self, img0, conf_thres=0.25):'''推理一张图片,输出CVAT格式检测结果Args:img0 (array): image. 传入的图像必定是矩阵值,由前端传回的数据解析得到conf_thres (float): confidence threshold. 检测结果置信度,大于该值的结果才会被返回。Returns:[dict]: CVAT要求的推理结果格式,如下:[{"confidence": str, # 字符串格式的置信度"label": str, # 字符串格式的标签"points": [xtl, ytl, xbr, ybr], # xtl, ytl是bbox左上角横纵像素坐标,xbr, ybr是右下角横纵像素坐标值"type": "rectangle", # 标签形状,目标检测任务为长方形rectangle,其他还有多边形polygon等,具体请看官方文档。},]'''# img0 is BGRassert img0 is not Noneimgsz = img0.shape[:2]iou_thres = 0.45 # NMS IOU thresholdstride, names = self.model.stride, self.model.namesimgsz = check_img_size(imgsz, s=stride) # check image size# Padded resizeimg = letterbox(img0, imgsz, stride=stride, auto=True)[0]# Convertimg = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGBimg = np.ascontiguousarray(img)im, im0s = img, img0# Run inferenceself.model.warmup(imgsz=(1, 3, *imgsz), half=False) # warmupresults = []im = torch.from_numpy(im).to(self.device)im = im.float() # uint8 to fp16/32im /= 255 # 0 - 255 to 0.0 - 1.0if len(im.shape) == 3:im = im[None] # expand for batch dim# Inferencepred = self.model(im, augment=False, visualize=False)# NMSpred = non_max_suppression(pred, conf_thres, iou_thres, None, False, max_det=1000)# Process predictionsdet = pred[0]im0 = im0s.copy()if len(det):# Rescale boxes from img_size to im0 sizedet[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()# convert to cvat results formatfor *xyxy, conf, cls in reversed(det):# xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4))).view(-1).tolist()xtl = float(xyxy[0])ytl = float(xyxy[1])xbr = float(xyxy[2])ybr = float(xyxy[3])results.append({"confidence": str(float(conf)),"label": names[int(cls)],"points": [xtl, ytl, xbr, ybr],"type": "rectangle",})return results
main.py:CVAT接口脚本,通过init_context(context)、handler(context, event)两个接口函数完成加载模型,并返回特定格式的模型推理结果的功能。
def init_context(context):context.logger.info("Init context... 0%")# 模型权重文件在docker中的路径,cvat默认工作路径是/opt/nucliomodel_path = "/opt/nuclio/yolov5s_head_human.pt"# 加载模型,并初始化到contextmodel = ModelHandler(weights=model_path)context.user_data.model = modelcontext.logger.info("Init context...100%")def handler(context, event):# 拿到前端数据context.logger.info("Run yolov5s model")data = event.bodybuf = io.BytesIO(base64.b64decode(data["image"]))threshold = float(data.get("threshold", 0.25))# 解析图像,并转为需要的格式,上一步ModelHandler的infer输入要求是BGR格式,故此处转为BGRimage = Image.open(buf) # RGBimage = image.convert("RGB")# RGB转为BGRimage = np.array(image)[:, :, ::-1]# 推理一张图片results = context.user_data.model.infer(image, threshold)# 返回检测结果return context.Response(body=json.dumps(results), headers={},content_type='application/json', status_code=200)
1.3. 运行部署命令
- 在
/ssd/wanghuijiao/cvat路径下运行以下部署命令:
nuclio deploy --project-name cvat \ # 此处是nuclio项目名称,不用更改--path serverless/pytorch/yolov5/yolov5s_test/nuclio # 这是1.2节准备的yolov5s部署相关文件所在路径,请自行替换

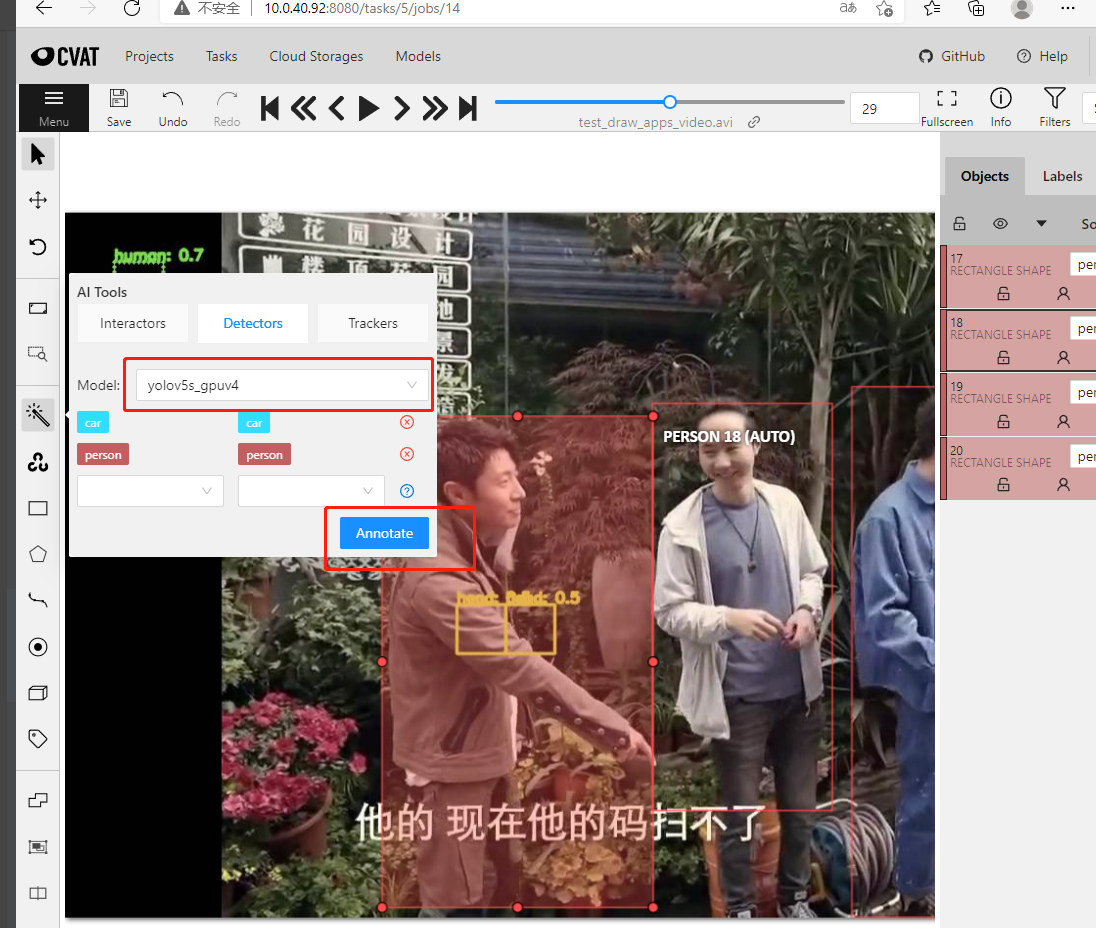
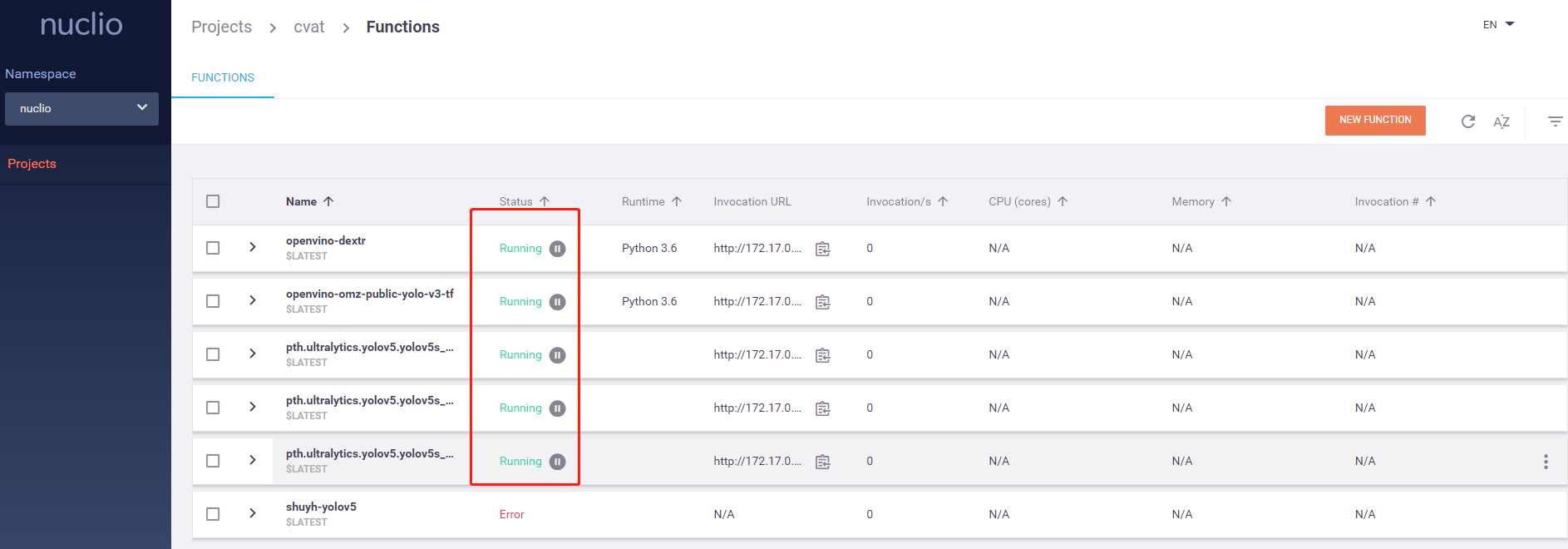
2. 如何从已支持的模型库中添加新模型到CVAT
- 一个库中的一系列模型用的都是同一套代码,所以新增已支持的库的新模型到CVAT只需要修改部分信息就可以快速的部署新模型。
- 以Yolov5库为例,新增yolov5s模型到CVAT分两步:
- 准备文件:function.yaml、main.py、model_handler.py、yolov5_xxx.pt
- 运行部署命令:
nuctl deploy ...
2.1 准备文件
- 需要准备的文件
- function.yaml:nuclio工具的配置文件,用于部署预训练模型到CVAT
- main.py:CVAT接口脚本,通过init_context(context)、handler(context, event)两个接口函数加载模型,并返回特定格式的模型推理结果。
- model_handler.py:模型初始化脚本,加载模型,提供推理一张图片的方法
- yolov5_xxx.pt:自己预训练的权重文件名称
- 目前CVAT已经部署了Yolov5s模型,新增yolov5系列模型时只需要在已有Yolov5s准备文件基础上稍微改写部分信息即可;假如新模型名为yolov5_xxx,复制
/ssd/wanghuijiao/cvat/serverless/pytorch/yolov5/yolov5s_head_person文件夹到/ssd/wanghuijiao/cvat/serverless/pytorch/yolov5/yolov5_xxx路径下
a. 把准备好的预训练模型yolov5_xxx.pt拷贝到/ssd/wanghuijiao/cvat/serverless/pytorch/yolov5/yolov5_xxx/nuclio路径下
b. 进入/ssd/wanghuijiao/cvat/serverless/pytorch/yolov5/yolov5_xxx/nuclio, 改写function.yaml为:
metadata:name: pth.ultralytics.yolov5.yolov5s_xxx # 此项是CVAT的function名称,根据新模型名称自行更改namespace: cvatannotations:name: yolov5s_xxx # 此项是CVAT UI界面半自动标注功能处显示的模型名称,根据新模型名称更改type: detectorframework: pytorchspec: | # 此处需要根据新模型的类别信息对应更改[{ "id": 1, "name": "head" },{ "id": 2, "name": "person" }]spec:description: yolov5_xxx from yolov5 # 此项是模型描述信息,根据新模型功能更改runtime: 'python:3.7'handler: main:handlereventTimeout: 30sbuild:image: cvat/pth.ultralytics.yolov5.yolov5s_xxx:vx # 镜像名称:镜像版本,根据需求自行更改baseImage: shuyh_cvat_yolo:v1 # yolov5的基础镜像,不需要更改directives:preCopy:- kind: WORKDIRvalue: /opt/nucliotriggers:myHttpTrigger:maxWorkers: 1kind: 'http'workerAvailabilityTimeoutMilliseconds: 10000attributes:maxRequestBodySize: 33554432 # 32MBresources:limits:nvidia.com/gpu: 1 # GPU 最多使用数量限制,可根据需求更改platform:attributes:restartPolicy:name: alwaysmaximumRetryCount: 3mountMode: volume
c. 改写main.py
- 只需要更改init_context(context)函数中预训练模型路径model_path = "/opt/nuclio/yolov5s_head_human.pt"为model_path = "/opt/nuclio/yolov5_xxx.pt",yolov5_xxx.pt是此次要部署的预训练模型权重名称,此权重文件应该放在/ssd/wanghuijiao/cvat/serverless/pytorch/yolov5_xxx路径下。
d. model_handler.py内容不需要更改。
2.2 运行部署命令
- 在
/ssd/wanghuijiao/cvat路径下运行如下命令
nuctl deploy --project-name cvat \--path serverless/pytorch/yolov5/yolov5s_head_person/nuclio # 准备文件所在路径,对应更改
