@wanghuijiao
2021-08-02T07:45:46.000000Z
字数 4152
阅读 1963
项目管理工具调研报告 MLflow & metaflow & 其他
快速调研
0. 前言
参考资源
1. 深度学习项目完整生命周期总结
项目开发周期需求 vs MLflow 提供的支持
- 0、数据集:标注与版本管理 --> 不支持
- 1、模型运行中,算法训练实验难于追踪:超参数、模型参数、运行结果输出(损失、各项指标)跟踪 --> MLflow Tracking
- 2、模型训练后,算法脚本难于重复运行:项目打包复现,包括代码版本、运行环境、训练测试以及数据处理等打包,并拟合所有算法框架 --> MLflow Projects
- 3、模型部署:部署到不同硬件平台,以及模型管理 --> MLflow Models
- 4、协同管理:多人协同,全阶段模型管理 --> MLflow Model Registry
2. MLflow & metaflow 功能汇总
- metaflow to do
| 功能 | 特性 | MLflow |
|---|---|---|
| 本地跟踪 | 支持离线运行 | √ |
| MLflow Tracking:跟踪记录 | 参数、模型指标跟踪、可视化UI界面 | √ |
| UI界面上通过参数或度量值搜索模型 | √ | |
| 并行运行多组实验调参 | √ | |
| MLflow Projects:打包项目环境和代码,用于复现实验 | 环境打包(Conda\Docker) | √ |
| 命令行一键复现实验 | √ | |
| MLflow Models:封装与模型部署 | 支持模型封装成python或ONNX风格 | √ |
| 支持打包为Docker镜像 | √ | |
| MLflow Model Registry:协同管理多个模型 | 模型版本控制 | √ |
| 阶段转换(研发->应用) | √ | |
| 以上功能可视化UI界面管理 | √ | |
| 数据集管理 | 标注、版本管理 | × |
- “√”代表支持,“×”代表不支持,“--”代表不确定
3. 博客阅读笔记
3.1 一文看懂机器学习项目的完整生命周期
- 机器学习项目的生命周期
- 问题定义
- 定义问题,并关注大局
- 数据处理
- 获取数据
- 探索性的数据分析
- 清洗数据,为接下来的模型做准备
- 模型方案
- 探索不同的模型并挑选合适的模型
- 对模型进行微调,集成为更好的模型
- 解决方案呈现
- 部署维护
- 部署、监控并维护系统
- 问题定义
3.2 A Complete Machine Learning Project Walk-Through in Python 系列
3.2.1 Part One
作者总结的完整的机器学习项目完整周期:
- 数据清理和格式化
- 探索性数据分析
- 特色工程与选择
- 比较几种机器学习模型的性能指标
- 在最佳模型上执行超参数调优
- 评估测试集中的最佳模型
- 尽量解释模型的结果
- 得出结论并写一份文件翔实的报告
本篇主要介绍:
- 清理并结构化数据,执行探索性的数据分析,开发一组在我们的模型中使用的特性,并建立可以用来衡量性能的基线。
1)定义问题
- 理解问题以及可用数据
- 以一个监督回归机器学习问题为例:利用纽约市的建筑能源数据,开发了一个模型,可以预测建筑物的能源之星评分。构建的最终模型是一个梯度增强回归器,它能够预测测试数据上的能源之星得分在9.1分以内(1-100分)。
- 2)数据清理和格式化
- 清除错误数据 (Pandas)
- 3)探索性数据分析
- 了解数据长什么样,能告诉我们什么(用图表各种可视化工具分析,比如 matplotlib)
- 寻找与目标相关的变量,建立联系
- 4)特征工程与选择
- 去掉一些与其他特征极其相关的特征,留下影响最显著的主要特征。一句话就是,删繁就简。
- 5)比较几种机器学习模型的性能指标
- 比如平均绝对误差,可以选一种然后在不同的任务中使用它。
- 划分训练集和测试集:7:3划分
3.2.2 Part Two
本篇主要介绍:
- 实现和比较几种机器学习模型,执行超参数调优以优化最佳模型,并在测试集中评估最终模型。
6)缺失值填补和特征缩放:
- 特征缩放指Normalization和Standardization,特征值范围对SVM和K近邻算法影响较大,可以将特征值缩放到0-1之间。这俩是几乎所有机器学习都需要的俩步骤。
7)评估和比较几种机器学习模型:
- 使用默认超参数训练各种基本模型,然后用统一的指标查看不同模型的结果,选最优模型进行超参数调优。
8)在最佳模型上执行超参数调优
- Scikit-Learn 支持超参数评估,后续自行查询。
- 每个机器学习的最优都是不同的,解决办法就是躲在几个数据集上尝试训练和测试。
- 用交叉验证随机搜索方法调超参:
- 随机搜索:定义一个网格,随机选择一些超参数组合进行搜索。
- 交叉验证:将训练集分为K份,每次在K-1个子集上训练然后在第K个子集上验证,这个过程重复K次, 计算一个平均误差作为最后的性能评估。
- 使用交叉验证寻找超参数过程如下:
- 建立一个超参数网格进行评估
- 随机抽样超参数的组合
- 使用选定的组合创建一个模型
- 使用k折交叉验证对模型进行评估
- 确定哪个超参数工作得最好
- 以上过程可以使用Scikit-learn的 RandomizedSearchCV 实现。
- 9)评估测试集中的最佳模型
- 基础模型和调优后的模型在测试集上用同一指标测试,比较调优带来的性能提升(调优是以大量训练时间换性能提升的权衡)。
3.2.3 Part Three
- 本篇尝试对模型进行理解和解释。
- 只大致撇了一眼,细节后续需要的话再花时间看吧,
- 10)解释模型结果
- 特征的重要性:统计最影响结果的几项特征
- 可视化单个决策树:由于本文选用的是 Gradient Boosted Regressor,所以针对此模型,选用的是可视化其中一颗决策树,来分析中间过程。
- LIME:本地可解释模型不可知解释,这是一个用来解释机器学习预测过程的工具。
- 11)得出结论并记录工作
3.3 CS194 Full Stack Deep Learning(1) Setting up Machine Learning Projects
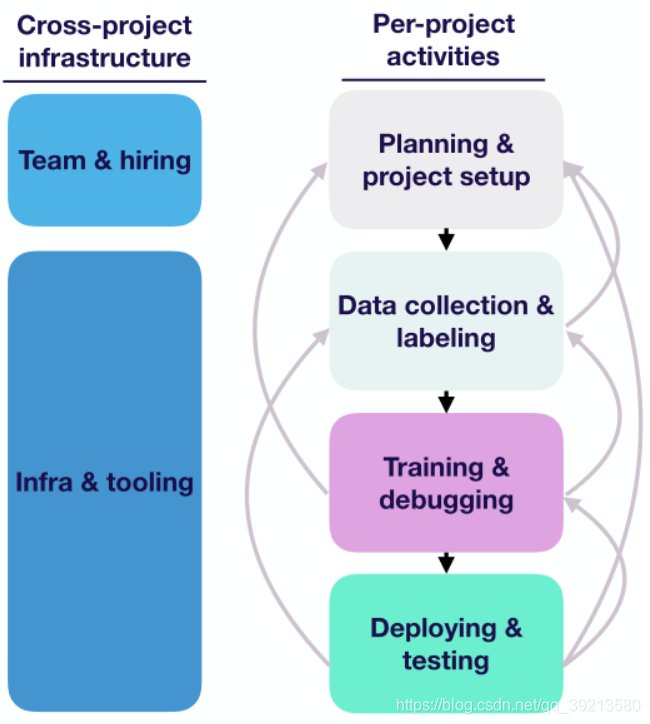
- 生命周期四个阶段(如下图右)
- 规划&项目启动:决定要研究的内容,期望达到的目标,完成项目需要多少资源。
- 数据采集&标注:确定需要训练的目标对象、设置传感器(如摄像头)采集数据,标注数据。
- 训练&调试:使用opencv实现一些baseline,文献综述了解最新、最强技术并复现,改进模型。
- 部署&测试:在实验室环境部署,进行测认识防止退化(写好日志系统,出问题时方便回顾、定位问题),在生产环境中部署。
- 各阶段之间的关系(如下图右)
- 数据 -> 规划:发现数据太难获取,或太难标注,可用其他更容易标注的方法来解决问题。
- 训练 -> 数据:出现过拟合,需要更多数据,发现数据不可靠(标注质量不行)
- 训练 -> 规划:发现计划难以实现,发现难以同时满足其他要求(比如又快又好)
- 部署 -> 训练:实验室环境下性能不够,需要进一步提升模型。
- 部署 -> 数据:发现训练数据与测试场景数据不匹配(之前的一些假设可能在实际场景中不成立),需要重新采集数据,寻找一些困难场景。
- 部署 -> 规划: 使用的性能指标不合适(不能为下游用户提供帮助),现实世界中达不到预期性能(需要对我们的要求进行回顾)。
- 总体内容如下:
- 如下图,右边是单个机器学习项目中的活动
- 左边是多个机器学习项目中共有的,主要是如何构建团队及通用工具。
3.4 The Machine Learning Lifecycle in 2021-中文翻译
- 这篇文章有很多工具推荐,日后有需要可以来此查找,此处出于篇幅考虑暂时不关注。
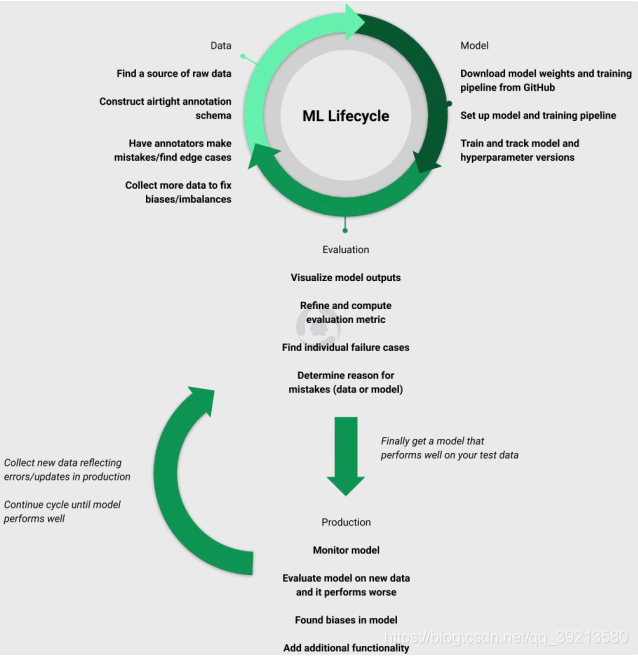
- 如上图,整个生命周期有四个阶段:数据、模型、评估、部署,这四个阶段是循环进行的。
- 第一阶段:数据
- 数据收集
- 定义注释模式
- 构建不良的注释模式将导致模棱两可的类和边缘案例,使其更加困难的训练模型。
- 数据注释
- 注释最大误差百分比2%
- 提升数据集和注释:
- 提升模型一般需要大量的样本挖掘(新增与模型不匹配的相似其他样本),再平衡已经基于偏差数据学习过的数据集,并且更新新标签和完善已经存在的注释和模式。
- 第二阶段:模型
- 探索现有的预训练的模型
- 构建训练循环:
- 数据在某些方面可能会与被用作预训练模型的有些不同。对于图像数据集,为模型设置培训路线时,需要考虑对象大小等输入分辨率。你也会需要调整模型的输出结构来匹配标签的类和结构。Pytorch lighting为有限代码提供一个简单的方法来扩展模型训练。
- 实验跟踪
- 由于迭代多次,模型众多,需要跟踪不同版本的模型、超参数以及数据,来一丝不苟的进行管理模型。(MLflow、Tensorboard)
第三阶段:评估
- 可视化模型输出:
- 在测试集上测试之前,先在训练集或验证集上可视化一下结果,可以排除一些基本错误比如数据类别标注错误。
- 选择正确的指标:
- 用一个或几个指标帮助比较模型的整体表现。(Scikit Learn —— 提供通用指标;Python, Numpy —— 开发自定义指标)
- 查看失败案例
- 查看假阳性和假阴性误判结果,有助于发现模型表现低于预期的原因。
- 制定解决方案
- 识别失败案例是找出改进模型表现的方法的第一步。在大多数情况下,它可以追溯到添加类似于您的模型失败的培训数据,但它也可以包括诸如更改流程中的预处理或处理后步骤或修复注释之类的内容。不论解决方案是什么,你只能通过了解模型失败的地方来解决它的问题。
- 可视化模型输出:
第四阶段:生产
- 监测模型
- 为确保模型在测试数据上依然按预期执行,测试您的部署与评估指标和参考速度有关。(MLflow)
- 评估新数据
- 在生产环境下使用模型意味着你将频繁地运行之前模型没有被测试过的全新数据。执行评估并深入到特定样本以查看模型在遇到任何新数据上的表现非常重要。
- 继续理解模型
- 模型中的一些错误和偏差可能根深蒂固,需要很长时间才能发现。你需要持续性地测试和验证你的模型,以发现各种边缘案例和趋势,如果客户发现这些可能会导致问题。
- 扩展能力
- 扩展新类,新数据。
- 监测模型
疑问
- metaflow 或 MLflow是咋支持超参数调优的?需要自行开启每一组超参数实验嘛?
