@wanghuijiao
2021-07-22T07:39:56.000000Z
字数 4599
阅读 2083
实验管理工具调研
快速调研
0. 前言
- 背景:
- a. 深度学习训练模型过程中产生了大量结果,难以直观进行比较;
- b. 超参数调参时没有集中的可视化图表进行对比,难以筛选模型;
- c. 模型的版本迭代管理困难;
- d. 模型部署时快速转换或封装成接口,供团队成员调用;
- e. 项目管理,需要很方便的了解团队其他人的进展,或将自己的模型性能分享给组内成员。
- 本篇重点调研了MLflow和Weights&Bias工具,对其功能支持进行了初步整理。
- 参考资料
按照项目开发周期有如下需求
- 1、模型运行中:超参数、模型参数、运行结果输出(损失、各项指标)跟踪 --> Tracking
- 2、模型训练后:项目打包复现(包括对环境、训练测试以及数据处理等各种代码打包)--> Projects
- 3、模型部署:部署到不同硬件平台,以及模型管理 --> Models
- 4、协同:多人协同?
- 5、数据集:标注与版本管理?
1. 功能支持
1.1 功能支持比较
| 功能 | 特性 | MLflow | Weights & Biases |
|---|---|---|---|
| 本地跟踪 | 支持离线运行 | √ | √ |
| 模型训练 | 模型参数跟踪 | √ | √ |
| 并行运行实验 | √ | √ | |
| 模型比较与搜素 | √ | √ | |
| 性能曲线可视化 | √ | -- | |
| 模型复现 | 记录模型版本 | √ | -- |
| 版本复现 | √ | -- | |
| 部署封装 | 模型打包与封装 | √ | -- |
| 协同管理 | 项目协同管理 | √ | -- |
| 查看系统指标 | 记录训练过程CPU和GPU使用率,用于调整硬件资源,提高效率 | × | √ |
- “√”代表支持,“×”代表不支持,“--”代表不确定
1.2 需求与功能支持拆解
从项目开发阶段角度考虑,可以将以上问题分为四类:模型训练,模型复现,部署封装,协同管理。以下将从工具的功能支持角度回答如何解决上述问题。
模型训练
- 问题a:深度学习训练模型过程中,产生了大量结果,难以直观进行比较;
- 需求:在实验中,需要更改模型结构或者在不同的数据集上试验模型,需要对不同结构的模型添加标签,并进行跟踪;
- 功能支持:
- 模型参数跟踪:跟踪模型相关的输入参数如超参数、版本、标签,输出文件如权重文件、性能指标等
- 并行运行实验:在一个项目中运行多组实验
- 如何做?
- 效果如何?
- 问题b. 超参数调参时,没有集中的可视化图表进行对比,难以筛选模型;
- 需求:超参数调参时在同一种模型设置下不断修改超参数设置,为节约时间,需要同时跑很多组实验。之后根据性能指标进行对比分析。
- 功能支持:
- 模型比较与搜素:以实验为单位的不同超参数模型列表、比较,根据性能指标搜索对应模型等;
- 性能曲线可视化:在可视化界面中跟踪查看模型的性能指标曲线;
模型复现
- 问题c. 模型的版本迭代管理困难。
- 功能支持
- 记录模型版本:跟踪记录模型不同版本
- 版本复现:对指定版本的模型实验进行复现;
- 功能支持
部署封装
- 问题d. 模型部署时,快速转换或封装成接口,供团队成员调用;
- 功能支持:
- 模型打包与封装:将模型封装成如Python 函数形式,供他人调用,或是部署;
- 功能支持:
协同管理
- 问题e. 项目管理,需要很方便的了解团队其他人的进展,或将自己的模型性能分享给组内成员。
- 功能支持:
- 项目协同管理:用于解决团队内部模型结果分享,协同管理模型不同版本和开发阶段(如开发、产品、归档)等。
- 功能支持:
2. 如何使用 MLflow
2.1 MLflow组织结构简介
- MLflow由4个组件组成:跟踪(Tracking)、工程(Projects)、模型(Models)、模型注册(Model Registry),这四个组件可以单独使用,也可以组合使用。
- 跟踪(Tracking)
- 用于跟踪记录训练前后相关的各种参数、图片、权重文件等,提供可视化界面和API接口进行查看模型训练结果。
- 工程(Projects)
- 用来打包代码的。一个Project就是一个仅包含代码的文件夹或者Git项目,额外用一个文件来记录环境依赖和如何运行代码。MLflow可以从自动记录代码版本,所以可以从已有的Git项目中运行。
- 模型(Models)
- 用来打包模型的工具,可以将模型封装成不同格式,比如Python 函数,TensorFlow、Keras、ONNX等等。
- 模型注册(Model Registry)
- 提供了一个集中的模型存储,一组API和UI,用于协同管理MLflow模型的整个生命周期。它提供了模型版本控制、阶段转换(从开发阶段到产品或归档)以及注释。
- 跟踪(Tracking)
以下将简要介绍如何用MLflow实现“功能支持比较”表格中的功能特性,为前言部分中模型训练中面临的实际问题提供参考。
2.2 MLflow安装
- 直接pip安装即可
pip install mlflow
2.3 模型训练跟踪
模型参数跟踪:
- 效果:跟踪的参数包括输入的超参数和输出的性能指标,MLflow会根据这些值记录训练过程,用户可通过UI界面进行查询、搜索和对比结果。
- 使用跟踪API:
- 添加以下代码到模型训练代码中,就可以开始跟踪模型参数(Parameter)、性能指标(Metric)以及模型输出文件(Artifacts)等。
记录模型版本
- 同样,跟踪API也可以记录模型版本。可以通过UI或者API记录。
import osfrom random import random, randintfrom mlflow import log_metric, log_param, log_artifactsif __name__ == "__main__":# Log a parameter (key-value pair)log_param("param1", randint(0, 100))# Log a metric; metrics can be updated throughout the runlog_metric("foo", random())log_metric("foo", random() + 1)log_metric("foo", random() + 2)# Log an artifact (output file)if not os.path.exists("outputs"):os.makedirs("outputs")with open("outputs/test.txt", "w") as f:f.write("hello world!")log_artifacts("outputs")
- 并行运行实验
- 效果: 调超参数时,需要设置很多种参数组合,跑同一组实验,MLflow可以同时记录多组实验,并行运行并逐一记录。
- MLflow是以runs为单位进行记录一次实验的,因此要并行运行多组实验,可以多开几个runs:
with mlflow.start_run():mlflow.log_param("x", 1)mlflow.log_metric("y", 2)...
性能曲线可视化
- 终端运行
mlflow ui,然后从http://localhost:5000查看可视化界面。
- 终端运行
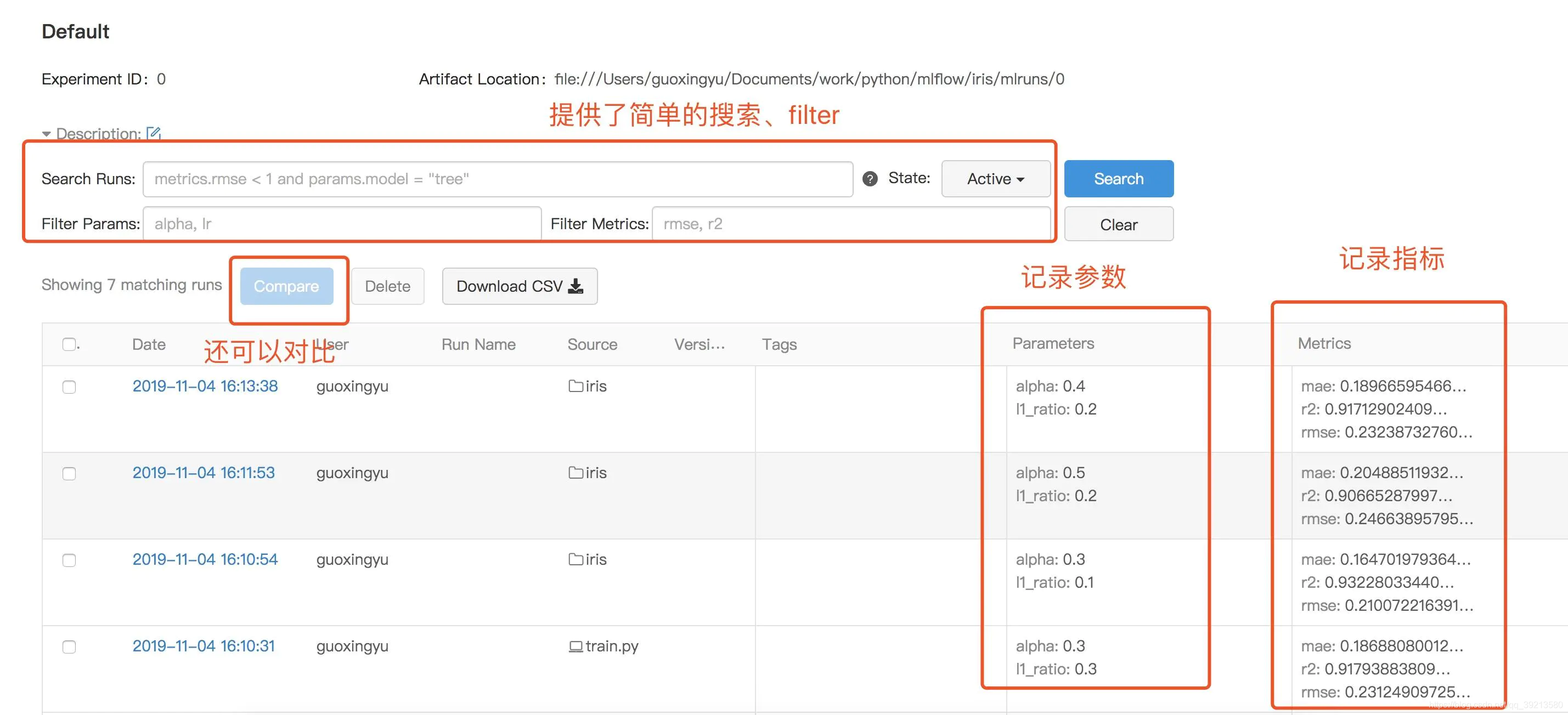
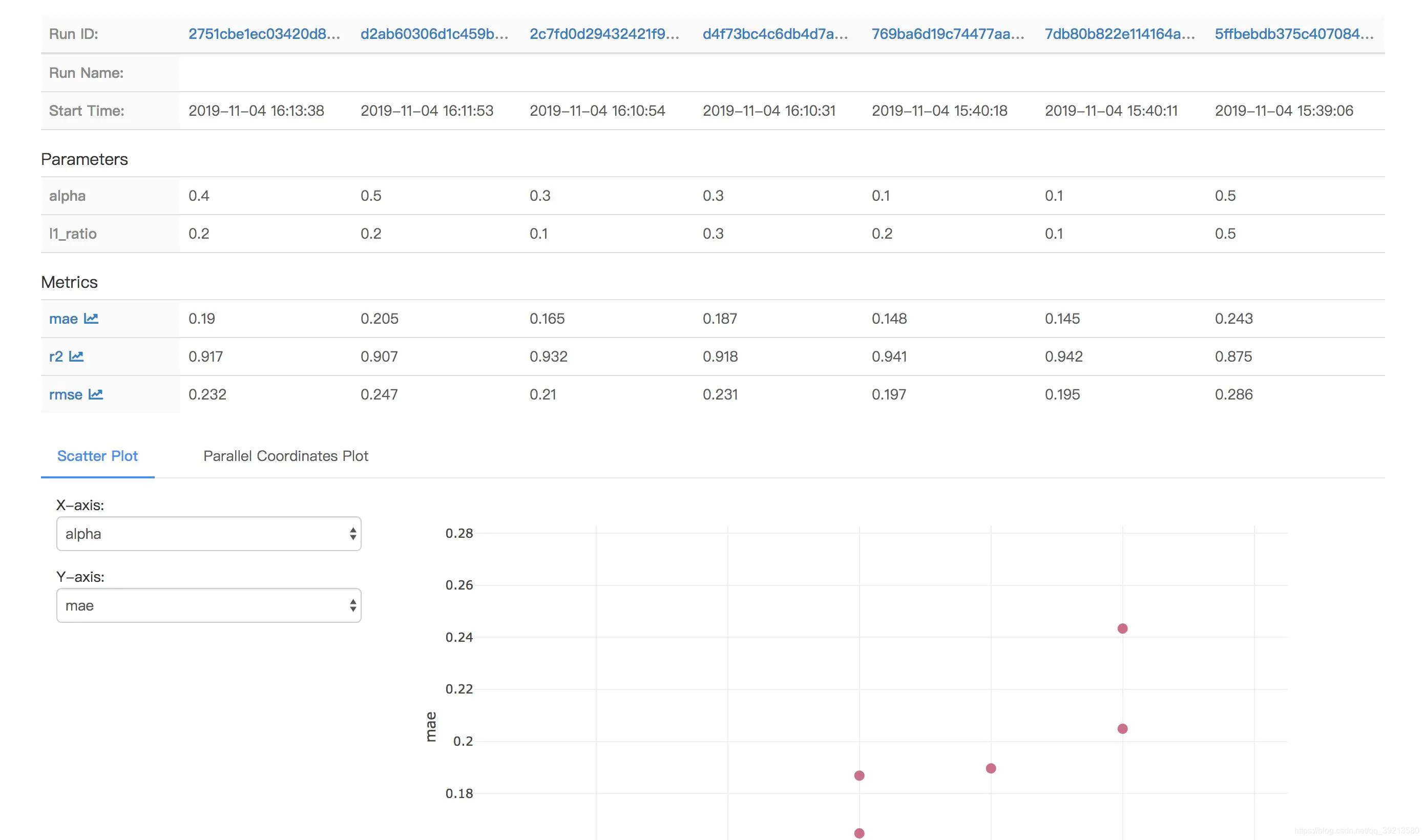
模型比较与搜索
- 可以直接在可视化界面中进行比较与搜索,也可以用外部工具如Pandas进行分析,详情请见Querying Runs Programmatically
UI界面示例:可以在UI界面中搜索、对比实验结果
2.4 模型复现
- 顾名思义,就是让别人能够快速复现你的代码。
- 这部分是通过MLflow Project组件实现的, 任何git库或者本地目录都可以作为MLflow Project使用,MLflow Project仅仅只是包含代码,关于环境依赖可以用conda.yaml配置。
- conda.yaml文件可以指明要复现的项目名称、入口点(即项目地址和版本)、环境依赖等。
- 版本复现具体方法:
- 根据项目名称和对应超参数值就可以通过命令行运行对应模型,复现实验效果。(-P指定超参数)
mlflow run ${project_name} -P alpha=0.5 -P l1_ratio=0.1 - 或者通过git hash值进行复现对应版本:
mlflow run git@github.com:mlflow/mlflow-example.git -P alpha=0.5
- 根据项目名称和对应超参数值就可以通过命令行运行对应模型,复现实验效果。(-P指定超参数)
2.5 部署封装
- 该功能由MLflow Models模块实现,MLflow Models是打包机器学习模型的一种标准格式,能够用于不同的下层工具中,比如PyTorch\Keras\TensorFlow\ONNX\MXNet\Scikit-learn等等。总而言之,就是一种通用封装协议。
- 模型打包与封装,以Pytorch封装为例:
- 模型保存:用
mlflow.pytorch.save_model()和mlflow.pytorch.log_model()保存PyTorch模型为MLflow通用格式, - 模型加载:用
mlflow.pytorch.load_model()加载MLflow模型为PyTorch模型。
- 模型保存:用
- 应用示例:
- 用MLflow Models可以将模型很快的转换为通用格式,快速部署在产品上,比如在服务器上用Pytorch模型开发训练Yolov4,想要在Jetson Nano上部署,就可以先在服务器上用
mlflow.pytorch.save_model()和mlflow.pytorch.log_model()保存PyTorch模型为MLflow通用格式,在Jeston Nano上用MLflow对ONNX的支持函数mlflow.onnx.load_model()加载模型。
- 用MLflow Models可以将模型很快的转换为通用格式,快速部署在产品上,比如在服务器上用Pytorch模型开发训练Yolov4,想要在Jetson Nano上部署,就可以先在服务器上用
2.6 协同管理
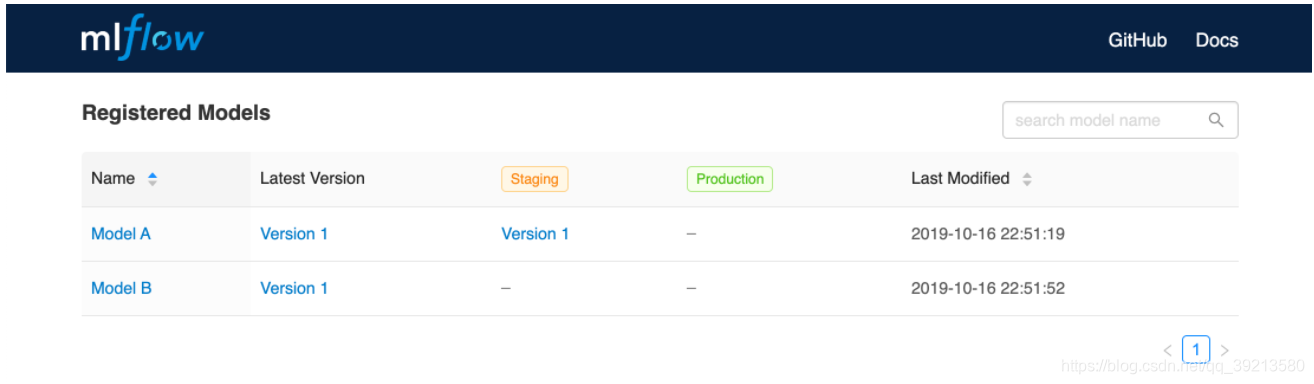
- 项目协同管理
- MLflow Model Registry 是一个集中管理模型中心,任何模型只要先用对应工具的加载函数
mlflow.<model_flavor>.log_model()(如mlflow.<pytorch>.log_model())加载,就可以在UI界面中进行后续的添加、修改、更新、转换或删除操作,可以对模型开发阶段进行标注,也可以进行版本控制。 - 有两种管理方式:通过UI界面管理或者API。
- 注册效果如图所示:
- MLflow Model Registry 是一个集中管理模型中心,任何模型只要先用对应工具的加载函数
3. Weights & Biases
- (稍后详细补充)
功能支持
- 1.不支持本地,只能通过注册账号,线上查看结果
- 2.跟踪损失或准确率等评价指标、保存文件(会上传到W&B)、为实验设置超参数。
- 3.可以跨平台:Jupter\PyTorch\TensorFlow\Keras\Scikit\fast.ai\LightGBM\XGBoost;跨环境:本地部署+私有云(AWS\Azure\Google Cloud\Kubernetes)
- 工具
- 仪表盘:跟踪实验、可视化结果;
- 报告:保存和分享可复制的成果/结论;
- 扫描(Sweeps):通过调节超参数来优化模型;
- 制品(Artifacts):数据集和模型版本化,流水线跟踪。
功能
- 项目页:在一个项目仪表盘上比较很多不同的实验。每次运行项目中的一个模型,都会在图形和表格中添加一行。在左侧栏中点击表格图标,即可展开表格并能看到所有超参数和指标(Metric)。可以创建多个项目来组织你的运行,并用表格为你的运行添加标签和注释。


- 自定义可视化:为方便探究结果,可添加平行坐标图、散点图及其他高级可视化工具。

- 报告:在你的实时图形和表格旁边添加一个Markdown面板,用以描述自己的研究成果。

- 集成:该工具可以集成到很多框架中,如PyTorch,Keras,XGBoost等
