@wanghuijiao
2021-01-22T05:51:04.000000Z
字数 4649
阅读 2619
解决数据不均衡:为FairMOT添加WeightedRandomSampler
实验报告
0 前言
- 问题背景: FairMOT训练集AVA\曼孚\hik等类别数据分布不均衡,对'lie'类别检测精度低。
1. 添加到FairMOT后的效果
- mAP(iou=0.5)略有提升,但是lie的ap仍旧很低
# ap_now:E15-1 epoch=4; ap_before:E14 epoch=10# 测试集:AVA_manfu_hik.val+------------+-------+-------+--------+-------+---------+| class | gts | dets | recall | ap_now|ap_before|+------------+-------+-------+--------+-------+---------+| stand | 18092 | 46136 | 0.804 | 0.276 | 0.259 || sit | 12715 | 32296 | 0.824 | 0.283 | 0.214 || squat | 238 | 1764 | 0.752 | 0.134 | 0.000 || lie | 989 | 12472 | 0.817 | 0.078 | 0.038 || half_lie | 1754 | 23154 | 0.808 | 0.081 | 0.071 || other_pose | 43 | 33 | 0.000 | 0.000 | 0.000 || person | 33831 | 69055 | 0.838 | 0.356 | 0.356 |+------------+-------+-------+--------+-------+---------+| mAP | | | | 0.173 | 0.134 |+------------+-------+-------+--------+-------+---------+
- Demo:
10.0.10.56:/ssd01/wanghuijiao/FairMOT/output/output_video_E15_2/e15_0_hik5_ct0.1_dt0.2_nms0.2.mp4
2. 实验结论
结论
- 相较于之前的实验,效果有所提升,如下图1,之前的模型完全无法检测到类似形态,添加WeightedRandomSampler(以下简称WRS)之后可对类似摔倒前姿态进行检测。(图中3.72实为0.372,后期添加NMS对lie概率人为*10)。
- 添加WRS之后,训练速度明显加快。

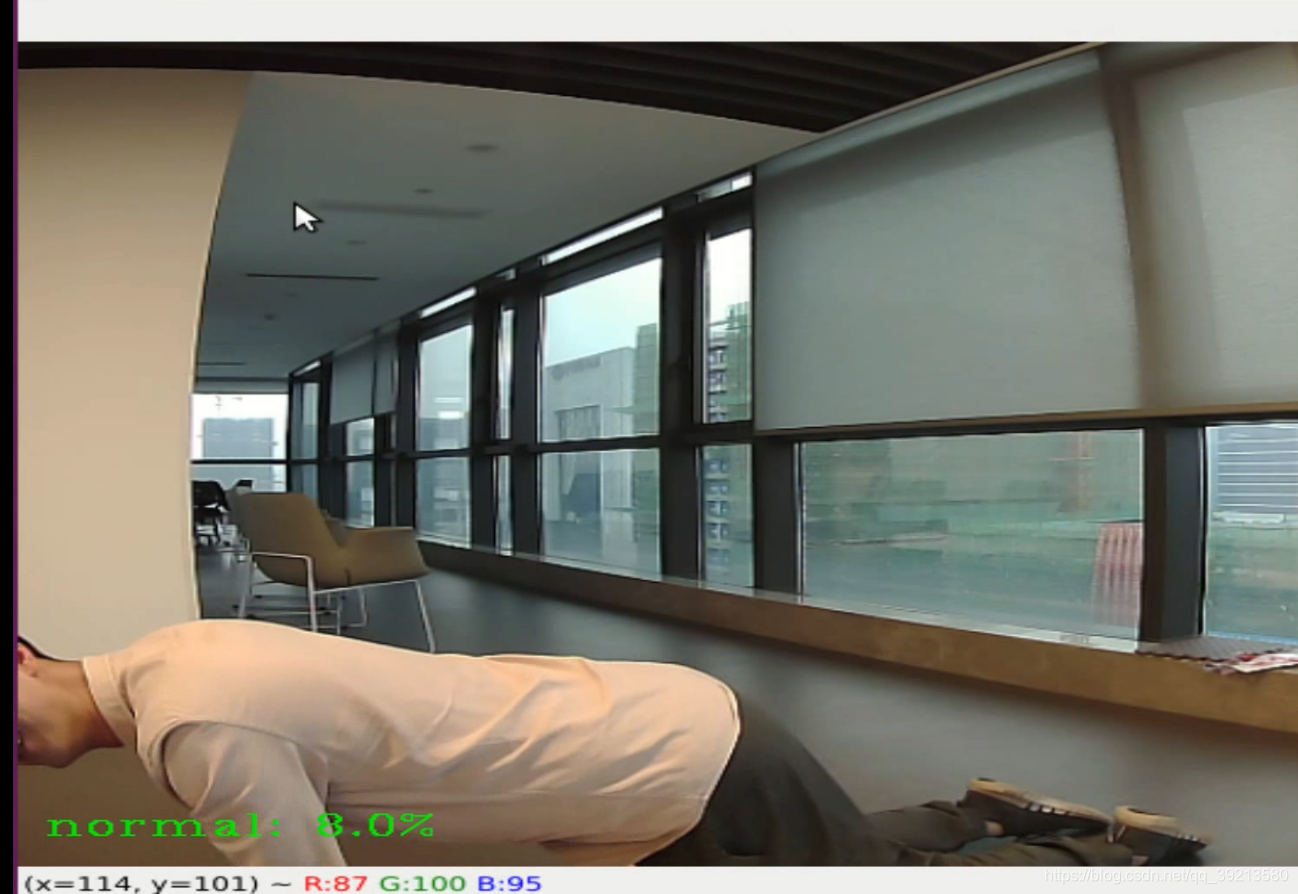
- 但是对于完全倒地的形态目前还无法检测到,已经尝试了将"lie"样本的weights提高后finetune,模型效果仅仅是对已经可以检测到的形态中lie的类别概率进行了提升,如下图姿态的人体仍旧无法检测到。
拟尝试解决方案
- 之前手动标记了如图中所示姿态的部分数据,但是相较于所有lie样本而言,数量较少,下一步拟尝试对该部分样本进行水平翻转、随机裁剪、颜色光照对比度随机增强的方法进行数据增强,增大这部分数据量,继续训练。
3. WeightedRandomSampler 源码解析及使用示例
- 加权随机采样
WeightedRandomSampler - 官方源码
class WeightedRandomSampler(Sampler[int]):r"""Samples elements from ``[0,..,len(weights)-1]`` with given probabilities (weights).Args:weights (sequence) : a sequence of weights, not necessary summing up to onenum_samples (int): number of samples to drawreplacement (bool): if ``True``, samples are drawn with replacement.If not, they are drawn without replacement, which means that when asample index is drawn for a row, it cannot be drawn again for that row.generator (Generator): Generator used in sampling.Example:>>> list(WeightedRandomSampler([0.1, 0.9, 0.4, 0.7, 3.0, 0.6], 5, replacement=True))[4, 4, 1, 4, 5]>>> list(WeightedRandomSampler([0.9, 0.4, 0.05, 0.2, 0.3, 0.1], 5, replacement=False))[0, 1, 4, 3, 2]"""weights: Tensornum_samples: intreplacement: booldef __init__(self, weights: Sequence[float], num_samples: int,replacement: bool = True, generator=None) -> None:if not isinstance(num_samples, _int_classes) or isinstance(num_samples, bool) or \num_samples <= 0:raise ValueError("num_samples should be a positive integer ""value, but got num_samples={}".format(num_samples))if not isinstance(replacement, bool):raise ValueError("replacement should be a boolean value, but got ""replacement={}".format(replacement))self.weights = torch.as_tensor(weights, dtype=torch.double)self.num_samples = num_samplesself.replacement = replacementself.generator = generatordef __iter__(self):rand_tensor = torch.multinomial(self.weights, self.num_samples, self.replacement, generator=self.generator)return iter(rand_tensor.tolist())def __len__(self):return self.num_samples
class WeightedRandomSampler(Sampler):r"""Samples elements from ``[0,..,len(weights)-1]`` with given probabilities (weights)."""def __init__(self, weights, num_samples, replacement=True):# ...省略类型检查# weights用于确定生成索引的权重self.weights = torch.as_tensor(weights, dtype=torch.double)self.num_samples = num_samples# 用于控制是否对数据进行有放回采样self.replacement = replacementdef __iter__(self):# 按照加权返回随机索引值return iter(torch.multinomial(self.weights, self.num_samples, self.replacement).tolist())
对于Weighted Random Sampler类的__init__()来说,replacement参数用于控制采样是否是有放回的(Ture为放回抽样);num_sampler用于控制生成的个数;weights参数对应的是“样本”的权重而不是“类别的权重”。其中__iter__()方法返回的数值为随机数序列,只不过生成的随机数序列是按照weights指定的权重确定的,测试代码如下:
# 位置[0]的权重为0,位置[1]的权重为10,其余位置权重均为1.1weights = torch.Tensor([0, 0.5, 0.1, 0.1, 0.1, 0.1, 0.1])wei_sampler = sampler.WeightedRandomSampler(weights, 6, True)# 下面是输出:index: 1index: 2index: 3index: 4index: 1index: 1
4. 加入FairMOT之前需要准备什么
- 为训练集图片生成对应的权重值文件
- 脚本位置(10.0.10.56):
/ssd01/wanghuijiao/FairMOT/src/weights_generate.py - 使用:输入
.train,输出按图片顺序的对应权重值文件.weights - 数据分布(每张图片对应一个主标签)
- 主标签选择策略
- 标签优先级:lie > half_lie > squat > sit > stand > other
- 具体而言:按照优先级筛选标签,优先选择级别高的标签作为主标签,与图片内标签数量无关。
- 分布:
stand: 83410, sit: 66170, squat: 714, lie: 6004, half: 10063, other: 10
- 主标签选择策略
- 权重赋值策略
stand: 1/stand_numsit: 1/sit_numsquat: 1/(squat_num*10)lie: 1/lie_num(后续尝试将hik对应的lie图片的权重*100来finetune模型,效果没有明显提升)half_lie: 1/half_lie_numother: 1/stand_num(other_pose的数量太少了,且模型目标是对前5种检测精度要求较高,因此赋予与stand相同的权重)
- 脚本位置(10.0.10.56):
5. 添加到FairMOT需要做什么
- 解析权重值文件
- 添加
Sampler
# 加载weights listwith open(opt.weights_dir,'r') as file:line = file.readlines()weights = line[0][1:-2].split(', ')weights = list(map(float, weights))# list -> Tensorweights = torch.Tensor(weights)sampler = torch.utils.data.sampler.WeightedRandomSampler(weights, len(weights), replacement=True)# Get dataloadertrain_loader = torch.utils.data.DataLoader(dataset,batch_size=opt.batch_size,shuffle=False,num_workers=opt.num_workers,pin_memory=True,drop_last=True,sampler=sampler)
