@wanghuijiao
2021-07-13T10:53:43.000000Z
字数 15880
阅读 2201
球形机器人-数据采集、标注与模型训练
技术文档
1. 数据采集、标注与注意事项
1.0 代码包结构
- 由于以下内容强烈依赖代码包内脚本,故先对代码包内结构进行说明。如下图1.1所示,代码包内根目录下包含人脸识别算法insightface和目标检测算法object_detection两个文件夹,其中目标检测模型同时选用了Yolov4和Yolov5,因此,在object_detection路径下包含了Yolov4和Yolov5两个单独的模型,NHY_Yolo_dataset文件夹内是在南湖院搭建的演示场景下实拍数据集。
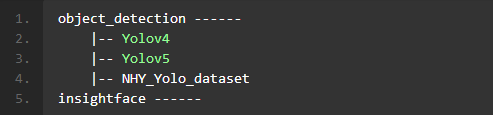
图1.1 代码包文件主结构
object_detection ------|-- Yolov4|-- Yolov5|-- NHY_Yolo_datasetinsightface ------
- 以下提及目录将以包内目录为准,例如
/insightface是指insightface文件夹,以下所有涉及路径指引之处在实际部署时请自行替换。
1.1 数据采集、数据筛选、注意事项(by 袁祖瑞)
1.1.1 数据采集
摄像头调试
若发现摄像头成像质量不佳,建议使用AMCap软件进行调试。
(1)在PC电脑上使用AMCap软件对摄像头调试曝光和焦点等属性,Options -> Video Devices–> Properties–>照相机控制。一般设置属性为自动。设置如下图1.2所示。
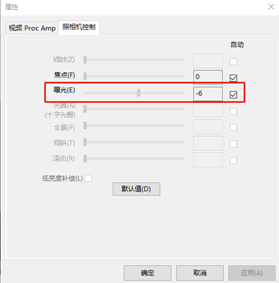
图1.2 照相机控制设置(2)在PC电脑上使用AMCap软件对摄像头调试帧率和分辨率等属性,Options -> Video Devices–> Capture Format–>数据流格式。帧率不低于20fps、分辨率不低于416*416。数据流格式设置界面如下图1.3所示。

图1.3 数据流格式设置界面
基于笔记本电脑的采集
目前,该摄像头无法通过接入手机的方式采集数据,此外,由于在开展数据采集工作时,球形机器人本体尚未制作完毕,因此,我们选择基于笔记本电脑的采集方式,尽可能以模仿机器人的角度和运动去拍摄视频。
操作步骤:- 1) 把摄像头连接到笔记本电脑上,然后用胶带固定在电脑的背面中间区域,其中,需要注意:
- 摄像头高度离底部边缘6cm左右,模拟机器人中摄像头的离地高度
- 把硬纸板(预估5厘米左右,以摄像头两侧实际在机器人被遮挡的距离为准)分别固定在相机的两侧,还原摄像头在机器人的实际视场角范围
2) 把视频采集的脚本代码
/NHY_Yolo_dataset/labelwork/save_video.py复制到笔记本电脑,在某个虚拟环境env中安装opencv,然后运行脚本代码,即可看到摄像头拍摄的视频。下图1.4是脚本在终端执行的效果。
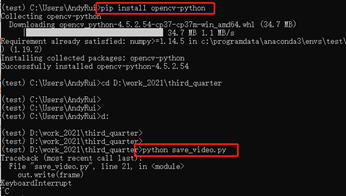
图1.4 视频采集脚本在终端内运行效果3) 让一个同事手持笔记本电脑在房间门口录制场景视频,先录制一小段背景视频,然后演员在特定场地中模拟实际场景,其中,需要注意:
- 电脑可放在门槛外侧,偶尔用手抖动摄像头模拟机器人运动带来的抖动
- 绑匪首领和绑匪成员穿道具服装,人质不用穿道具服装
- 演员们要走动以确保摄像头录制角度变换下的场景
- 首领和人质的人脸要确保被录制到一些清晰的片段
- 房间的灯要有开启和关闭的状态以确保摄像头录制亮度变换下的场景
- 录制至少2段视频,用于训练的视频时间不低于2分钟,用于测试的视频时间不低于30秒
- 4) 按“Control+C”快捷键结束视频录制,视频将保存在
/NHY_Yolo_dataset/labelwork目录下,每次的录制视频以时间形式作为文件名称,例如:2021-07-09_10-13-29.avi。
- 1) 把摄像头连接到笔记本电脑上,然后用胶带固定在电脑的背面中间区域,其中,需要注意:
基于机器人本体的采集
- 截止2021年7月8日,由于机器人本体尚未成功运行,故未在机器人本体上实施过数据采集,预计操作步骤与基于笔记本电脑采集相似。
1.1.2 数据筛选
视频抽帧与分工
- 使用
/NHY_Yolo_dataset/labelwork/getframe.py脚本对视频分帧得到图片,便于人工标注数据制作模型训练集。getframe.py共有4个参数:
- --path是输入视频路径;
- --outpath是输出路径,默认是“./output”;
- --fps是每秒抽多少帧,默认是5;
- --split是将抽帧的图像分多少个文件夹存放,便于多个人标注,默认是5。
- 例如,运行
python getframe.py --path 2021-06-25-10-47.avi --split 5,会生成5份等量的数据,然后即可将5份数据划分给5个人,分别负责各自的数据标注。划分结果如下图1.5所示:

图1.5 数据划分结果
1.2 数据标注与处理
1.2.1 Labelme安装与使用(by 袁祖瑞)
- 安装
- 1)在Windows系统下,打开终端窗口,若在Anaconda环境中尚未有虚拟环境env,先创建conda的虚拟环境;
conda create -n labelme_test python=3.6 #指定了版本号;若已有虚拟环境env,可选择进入某个env中 - 2)使用pip直接安装labelme:
pip install labelme
- 1)在Windows系统下,打开终端窗口,若在Anaconda环境中尚未有虚拟环境env,先创建conda的虚拟环境;
- 使用示例:
- 1)进入安装了labelme的虚拟环境env,直接输入labelme命令,即可打开labelme标注软件;效果如下图1.6所示:

图1.6 Labelme 安装过程 - 2)使用labelme软件打开相应的文件夹,依次标注里面的图片;Labelme界面如下图1.7所示:

图1.7 Labelme界面效果 - 3) 使用快捷键Control+R选中要标注的范围(矩形),输入标签,Labelme的标注界面如图1.8所示:

图1.8 Labelme 标注界面 - 4) 设置成自动保存标注结果,File -> Automatically,标注结果将以JSON格式保存在相应的文件夹中,Labelme 输出标签文件格式如图1.9所示:

图1.9 Labelme 输出标签文件格式
- 1)进入安装了labelme的虚拟环境env,直接输入labelme命令,即可打开labelme标注软件;效果如下图1.6所示:
1.2.2 目标检测标注(by 王慧娇)
标注规范&质检
标注规范
- 目标检测模型需要检测出人质、恐怖分子、人质和首领的人脸、窗、枪等物体,因此,用Labelme进行标注时,标签为'hostage'、'terrorist'、'face'、'gun'、'window'等5类,标注画框时注意:
- 'hostage'是露出脸的穿便服的人,框需要包含整个人体位置,尽可能完整包含人体又不包含太多无用的背景区域,当两人重叠时,被遮挡人遮挡程度大于50%则跳过不标;
- 'terrorist'是穿恐怖分子制服的人,标注标准同'hostage';
- 对人脸标注时,只需标注人质和恐怖分子首领的人脸,普通恐怖分子人脸是蒙面状态不需要标注。需要把人脸外轮廓露出来,大于90°侧脸不需要标,只标清晰可见的人脸,由于人脸框精度会直接影响后续人脸识别精度,因此标注需要格外谨慎,框要合理的贴近人脸轮廓线进行标注,切勿过大或过小;
- 'gun'枪支标注时,只标肉眼可分辨的枪支,部分由于反光,逆光,遮挡等问题导致枪支肉眼难辨的情况不标注;
- 'window'标注时,对于露出50%以上面积的窗进行标注,尽可能完整包含窗体;
- 标注示例,见图1.10和图1.11:

图1.10 合理标注示意图1

图1.11 合理标注示意图2
- 目标检测模型需要检测出人质、恐怖分子、人质和首领的人脸、窗、枪等物体,因此,用Labelme进行标注时,标签为'hostage'、'terrorist'、'face'、'gun'、'window'等5类,标注画框时注意:
质检
- 用脚本
/NHY_Yolo_dataset/labelwork/draw.py将标注结果画在图片上,用于检验查看标注结果。draw.py共有2个参数:
- --path是txt标注结果所在路径;
- --outpath是存储路径。
- 用脚本
训练集格式说明
- Yolo需要的训练数据的每张图片对应一个同名的txt标签文件,txt内包含了整个图片内所有框的信息,每个框的标签格式为
<object-class> <x_center> <y_center> <width> <height>其中,<x_center> <y_center> <width> <height>是相对坐标,需要用绝对坐标除以图片长和宽,即x_center = x_center_absolute/image_width, y_center = y_center_absolute/image_height和width = width_absolute/image_width,height = height_absolute/image_height。
自制数据集格式转换
- Labelme输出的是与图片同名的json格式的标签,需要用
/NHY_Yolo_dataset/labelwork/json2yolo.py脚本将标签转为txt格式。json2yolo.py共有1个参数,--path是标注json结果所在路径。
1.2.3 人脸识别标注(by 王慧娇)
标注规范&质检
1)裁剪、对齐 人脸识别模型的训练数据需要先用人脸检测算法如MTCNN、Retinaface先进行裁剪、对齐操作,并统一缩放到112*112尺寸。此处提供脚本可以直接对图片或视频中的人脸进行检测、裁剪并对齐缩放操作,并把处理后的人脸保存下来。脚本见:
/insightface/retinaface_arcface/deploy_slim/get_not_aligned_faces.sh。命令说明如图1.12所示:

图1.12 裁剪对齐人脸命令cd /insightface/retinaface_arcface/deploy_slimpython get_not_aligned_faces.py \--input_video /insightface/dataset/nhy_data/train/2021-06-25_15-11-56.avi \--img_save_dir /insightface/dataset/nhy_data/train_images_no_align_ex11/ \--det 2 \--align 1 \--interval 6 \--margin 44# --det 值为2时,用Retinaface模型检测人脸,为0时,用MTCNN检测# --align 值为1,表示做对齐操作;为0,不对齐# --interval 表示每$interval帧取一帧做人脸检测# --margin 表示检测到人脸框后,在统一尺寸到112*112前,对人脸框上下左右外扩几个像素,为44时,表示向上下左右各扩22(44/2)像素。
执行上步裁剪对齐操作后,会得到一堆混杂在一起的人脸图片(112*112)。
2)手动给标签 对上一步得到的人脸图片进行手动按人脸身份(ID,identity)分类,ID序号从0到N,以ID命名子文件夹,分类的过程就是标注(子文件夹名即给定的ID标签)的过程。在分类过程中,对符合要求的人脸图片进行筛选。
- 标准如下:
- 人脸部分要求清晰,肉眼可分辨ID信息;
- 大角度侧脸如大于90°(以正视角度为0°,水平向左、右旋转),丢弃;
- 尽可能多均匀覆盖(0°-90°内)不同角度的侧脸;
- 覆盖不同光线:暗光、自然光、亮光;
示例:
- 符合要求的图片示例如图1.13所示:

图 1.13 符合要求的人脸图片示例 - 不符合要求的图片示例如图1.14所示:

图1.14 不符合要求的人脸图片示例
- 符合要求的图片示例如图1.13所示:
准备对齐后的人脸数据集, 并手动分类到按身份序号从 0-N 命名的子文件夹。文件组织结构示例,如图1.15所示:

图 1.15 人脸数据集文件组织结构示例1 ------|-- Jack_1.jpg|-- Jack_2.jpg|-- Jack_3.jpg2 ------|-- Rose_1.jpg|-- Rose_2.jpg
- 标准如下:
3)质检 浏览各子文件夹人脸图片,需要检查以下情况:
- 标签给错
- 图片质量不佳:图片本身分辨率低(原始人脸太小,导致缩放之后质量极差)、运动模糊(以肉眼无法明显分辨ID为准)、暗光、侧脸、曝光严重。
- 不同ID之间图片数量差异较大
4)建立图片库Gallery 由于人脸识别需要建立Gallery来作为人脸身份信息,以用于将测试图片与之对比计算相似度,进行匹配识别测试图片身份。
- 制作步骤同1)2)3),仅需要对子文件夹内图片进行重命名操作,以真实人名进行重命名(默认命名规则为 name_frameNo.jpg,如wanghuijiao_1.jpg),脚本在
/insightface/retinaface_arcface/deploy_slim/rename.py。同时,建立Gallery原则为:
- 覆盖所有测试人员的人脸注册图片;
- 每个ID有不同侧脸角度、光线、不同模糊程度的人脸,Gallery中与实测时人脸图片质量越近似,识别效果越好;
- 人脸图片根据测试时对齐与否选择是否进行对齐操作,比如:测试时对待测图片中的人脸实施对齐操作,则要求Gallery库中人脸也进行对齐和缩放(默认缩放到112*112),否则两者均不对齐。
- 所有ID的所有人脸注册图片均放置在一个文件夹内,示例如:
/insightface/retinaface_arcface/deploy_slim/0628_gallery
- 制作步骤同1)2)3),仅需要对子文件夹内图片进行重命名操作,以真实人名进行重命名(默认命名规则为 name_frameNo.jpg,如wanghuijiao_1.jpg),脚本在
训练集格式说明
- 然而,MXNet要求数据集为二进制形式,以 insightface 官方 MS1MV2-Arcface 数据集格式为例,训练集和验证集包括如下几部分。如图1.16所示:

图1.16 官方MS1MV2-Arcface数据集格式
faces_emore/train.idxtrain.recpropertylfw.bincfp_fp.binagedb_30.bin
其中,前三个是训练集,后三个.bin是验证集。因此需要将上节第 2)步标注得到的数据集图片转成训练时需要的格式。
自制数据集格式转换
- 本部分主要参考博客ArcFace/InsightFace使用自己数据训练/验证过程(1)(2)(3),制作自制数据集。
制作数据集脚本位置为
/insightface/recognition/datasets/self_dataset_script/make_self_dataset.sh,过程如下:1) 人脸数据集对齐:
- 直接用标注第 2)步得到的图片格式数据集。
2) 生成lst文件:
lst 文件格式:包括序号、图片路径、标签等三列信息。如下图1.17所示:

图 1.17 lst 文件格式示例1027 /insightface/dataset/nhy_data/splited_train_images_no_align_ex22/1/2021-06-25_15-11-56_1296_1.jpg 12296 /insightface/dataset/nhy_data/splited_train_images_no_align_ex22/2/2021-06-25_15-11-56_7050_0.jpg 25 /insightface/dataset/nhy_data/splited_train_images_no_align_ex22/0/2021-06-25_10-40-32_108_0.jpg 0
生成lst命令,如图1.18所示:

图1.18 生成lst命令cd /insightface/recognition/datasets/self_dataset_scriptpython -u face2rec2_m.py \--list True \--prefix /insightface/recognition/datasets/0629_ex0/ \--root /insightface/dataset/nhy_data/splited_train_images_no_align_ex0/ \--train-ratio 0.8 \--test-ratio 0.2 \--recursive True# 参数说明# --list:是否生成lst文件# --prefix:lst文件保存位置# --root:对齐后人脸数据存放位置# --train-ratio/--test-ratio:训练集和测试集的比例
3)制作property,生成rec文件
- 创建文件proprety,注意没有后缀,以文本形式打开,写上以下内容,如下图所示,第一个数字代表类别总数,第二个和第三个数字代表人脸的尺寸。
- rec文件是训练集训练时的格式,生成rec文件命令,如图1.19所示:
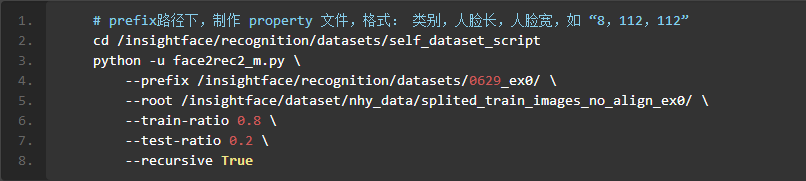
图 1.19 生成rec文件命令
# prefix路径下,制作 property 文件,格式: 类别,人脸长,人脸宽,如 “8,112,112”cd /insightface/recognition/datasets/self_dataset_scriptpython -u face2rec2_m.py \--prefix /insightface/recognition/datasets/0629_ex0/ \--root /insightface/dataset/nhy_data/splited_train_images_no_align_ex0/ \--train-ratio 0.8 \--test-ratio 0.2 \--recursive True
4)生成bin文件
制作pairs.txt
bin文件用于验证和测试,其内容是两两图片的结合,然后给出这两张图片的真实标签,1代表是同一个人,0代表不是同一个人,以此达到验证和测试的目的。首先我们需要把所有的人脸数据两两结合起来,如下所示,每一行是一个测试样本,其中前两个是两张图片的地址,最后一个数字代表这两张图片是不是同一个人,运行write_pairs.py,程序中修改人脸数据目录和生成的文件要保存的目录,制作pairs.txt。pair.txt格式如图1.20所示:

图1.20 pair.txt格式/insightface/dataset/nhy_data/test_images_no_align_ex0/2/2021-06-25_15-11-56_1578_0.jpg,/insightface/dataset/nhy_data/test_images_no_align_ex0/2/2021-06-25_15-11-56_1878_1.jpg,1/insightface/dataset/nhy_data/test_images_no_align_ex0/2/2021-06-25_15-11-56_1578_0.jpg,/insightface/dataset/nhy_data/test_images_no_align_ex0/2/2021-06-25_15-11-56_1314_0.jpg,1/insightface/dataset/nhy_data/test_images_no_align_ex0/2/2021-06-25_15-11-56_1878_1.jpg,/insightface/dataset/nhy_data/test_images_no_align_ex0/2/2021-06-25_15-11-56_1314_0.jpg,1
制作pairs.txt和bin文件命令,如图1.21所示:

图1.21 制作pairs.txt和bin文件命令# 修改write_pairs.py Line 33行路径, 制作pairs.txtpython write_pairs.py# 制作 bin 文件cd /insightface/recognition/common./build_eval_pack.sh
1.2.4 标注结果汇总(by 王慧娇)
目标检测
- 存放路径
/NHY_Yolo_dataset
- 文件说明
- 1.拍摄有5段avi视频,可以拿来做训练和测试。
- 2.文件夹data0624,data0625分别是
2021-06-24_14-50-56.avi和2021-06-25_15-11-56.avi抽帧产生的图片,在这些图片上使用labelme标注训练集。 - 3.traindata0624和traindata0625是用来训练的数据集。
人脸识别
存放路径和组织结构
/insightface/recognition/datasets下以日期进行版本管理,0628和0629_ex0是南湖院数据, 文件夹内包含了训练和验证需要的所有文件。对应训练集格式说明小节所展示的数据集格式,以0628为例,说明文件组织结构,如图1.22所示。

图1.22 自制训练集文件组织结构
property # 辅助文件,记录ID个数和训练集图片尺寸self_eval_1wp.bin #自制测试集test_images_no_align_ex0_pairs.txt # 制作bin测试集时辅助文件,记录1:1成对图片,以及标签test_images_no_align_ex0_pairs.bin # 自制测试集test.idx # 辅助文件,记录验证时乱序后图片读取顺序test.lst # 辅助文件,记录验证集图片序号、地址、标签test.rec # 训练时验证所用验证集文件,占训练数据0.2train.idx # 辅助文件,记录训练时乱序后图片读取顺序train.lst # 辅助文件,记录训练集图片序号、地址、标签train.rec # 训练时直接用到的文件,占训练数据0.8
1.3 模型训练
1.3.1 目标检测Yolov4(by 王慧娇)
环境配置
- 参考Yolov4源代码
- 所需依赖及版本要求:
CMake >= 3.18,CUDA >= 10.2,OpenCV >= 2.4,cuDNN >= 8.0.2,GPU with CC >= 3.0 - 环境安装及编译步骤如下图1.23(Linux平台):
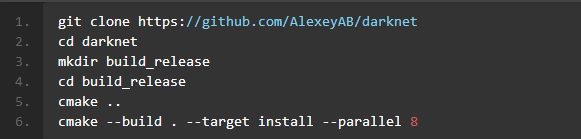
图1.23 环境配置命令
git clone https://github.com/AlexeyAB/darknetcd darknetmkdir build_releasecd build_releasecmake ..cmake --build . --target install --parallel 8
- 编译之前可以先对Makefile的配置做一些修改(Linux平台):
- GPU=1,编译过程使用CUDA,CUDA需要在
/usr/local/cuda目录下 - CUDNN=1,过意过程使用cuDNN v5-v7,cuDNN需要在
/usr/local/cudnn目录下 - CUDNN_HALF=1,使用单精度来训练和测试,可以在Titan V / Tesla V100 / DGX-2或一些更新的设备上获得测试性能3倍的提升,训练速度2倍的提升。
- OPENCV=1,编译过程中使用OpenCV 4.x/3.x/2.4.x,方便测试的时候可以使用视频和摄像头。
- DEBUG=1,编译debug版本的yolo。
- OPENMP=1,在多核CPU平台上使用OpenMP加速。
- LIBSO=1,编译生成darknet.so和可执行的库文件。
- GPU=1,编译过程使用CUDA,CUDA需要在
配置文件准备
- 准备训练图片和yolo格式支持的txt标注文件。在数据目录下准备
train.txt和test.txt,这两个文件中每一行是待训练图片的路径,train.txt中的数据用于训练,test.txt中的数据用于测试。 - 在
/object_detection/Yolov4/darknet/data目录下新建name.data文件,文件格式如下图1.24所示:
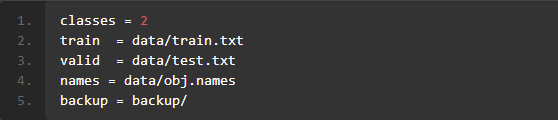
图1.24 name.data文件内容示例
classes = 2train = data/train.txtvalid = data/test.txtnames = data/obj.namesbackup = backup/
- 其中,classes表示目标类别数量;train表示训练数据的路径;valid表示测试数据的路径;Names表示目标类别的名称;backup表示训练结果存放路径。
- 在
datknet/data目录下新建name.names文件,文件格式如下图1.25所示:

图1.25 name.names 文件内容示例
facehostageterroristwindow
- 文件中每一行代表一个目标的名称。这里的名称和标注数据需要对应起来。
网络结构修改
- 网络定义的文件在
/object_detection/Yolov4/darknet/cfg目录下,以yolov4-tiny.cfg为例,
- 文件中batch设置训练一次使用的图片数量;
- width和height设置图像输入大小;
- learning_rate设置学习率;
- max_batches设置训练轮次,一般可以设置为目标数量*2000,但是不要少于6000;
- 设置steps为max_batches*0.8,max_batches*0.9,这里设置是为了调整学习率,一般学习率在max_batches*0.8,max_batches*0.9缩小10倍,具体缩小比例可以在scales中调整;
- 设置所有的classes为自定义数据集的目标数量;在网络结构中每个[yolo]层之前的[convolutional]中设置filters=(classes + 5)x3。
网络训练命令
- 网络训练之前可以下载预训练模型。训练命令如下:
/object_detection/Yolov4/darknet detector train [data] [cfg] [pretrain model] -map -gpus 0
- data数据集.data文件的路径,
- cfg是网络参数设置文件的路径,
- pretrain model是预训练模型路径,
- -map 用来在训练过程中显示map参数,
- -gpu用来设置用那个gpu来训练。
1.3.2 目标检测Yolov5(by 袁祖瑞)
环境配置
- 参考Yolov5源代码,Yolov5 模型训练必须使用 5.0 release 版本,commit id 为 f5b8f7d54c9fa69210da0177fec7ac2d9e4a627c。
- 所需依赖及版本要求:Python >= 3.6.0
- 环境安装及编译步骤如下(Linux平台):
pip install -r requirements.txt
数据&配置文件准备
- 准备训练图片和yolo格式支持的txt标注文件。在数据目录下准备train.txt和test.txt,这两个文件中每一行是待训练图片的路径,train.txt中的数据用于训练,test.txt中的数据用于测试。
- 在data目录下新建
your_name.taml文件,文件格式如下图1.26所示:
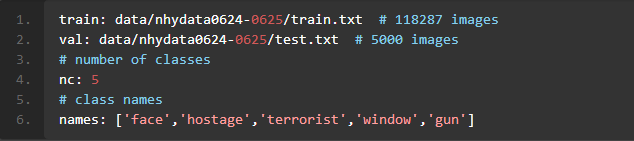
图1.26 配置文件格式示例
train: data/nhydata0624-0625/train.txt # 118287 imagesval: data/nhydata0624-0625/test.txt # 5000 images# number of classesnc: 5# class namesnames: ['face','hostage','terrorist','window','gun']
- 其中,nc表示目标类别数量;train表示训练数据的路径;valid表示测试数据的路径;names表示目标类别的名称,这里的名称和标注数据需要对应起来。
网络结构修改
- 网络定义的文件在model目录下,以yolov5s.yaml为例,文件中nc为自定义数据集的目标数量。
训练命令
- 网络训练之前可以下载预训练模型。训练命令如下图1.27所示:

图1.27 训练命令示例
python train.py \--data data/nhydata416.yaml \--cfg models/nhydata416_yolov5s.yaml \--img 416 \--weight yolov5s.pt \--batch-size 32 \--epoch 400# --data数据集.yaml文件的路径;# --cfg是网络参数设置文件的路径;# --img输入图像的分辨率;# --weight是预训练模型所在路径;# --batch-size是一次训练所用图片数量;# --epoch是训练轮次。
权重转为wts格式
目前训练均在服务器端进行,得到的权重文件格式为.pt格式,而在球形机器人端部署前需要将.pt格式转为wts格式,方便下一步进行模型部署时使用。模型转换脚本为/object_detection/Yolov5/gen_wts.py。
1.3.3 人脸识别Arcface(by 王慧娇)
环境配置
算法参考自deepinsight/insightface人脸识别算法部分, 选择用Mobilefacenet作为人脸识别网络。
本算法基于insightface MXNet版,故需要安装MXNet。环境配置命令如图1.28所示。

图1.28 环境配置命令
pip install mxnet-cu100 # mxnet-cu102
- 环境依赖:Python 3.X
训练命令&配置文件说明
- 配置文件说明
- 训练相关文件路径在
/insightface/recognition/ArcFace, 模型Backbone、数据集、训练参数等等信息均在该路径下的配置文件config.py内说明,模型结构、数据集、损失函数分别由‘network’、‘dataset’、‘loss’等字典控制,在‘default’字典中配置训练时选用的模型、数据集和损失函数以及学习率等超参数。
- 训练相关文件路径在
- 训练命令如图1.29所示:

图1.29 人脸识别模型训练命令
cd /insightface/recognition/ArcFaceCUDA_VISIBLE_DEVICES='4,5,6,7' python -u train.py \--dataset selfie \--network y1 \--loss arcface \--ckpt 2 \--verbose 50 \--lr 0.001 \--lr-steps 50,100,200 \--wd 0.0001 \--num_epoch 100 \--models-root ./models/y1_noPre_0629_ex0_noAlign_ex0# --dataset 对应配置文件内dataset字典所列信息,可选‘emore’、‘retina’、‘selfie’,‘selfie’是自定义数据集# --network Arcface提供了不同的Backbone结构可供选择,'y1'是mobilefacenet,其他可选:resnet100 -'r100'、'r100fc' 、resnet50-'r50'、 'd169'、 'd201'、 'y2'、 'm1'、 'm05'、 'mnas'、 'mnas05'、 'mnas025'、 'vargfacenet'等# --loss 损失函数,可选'arcface'、'nsoftmax'、'cosface'、'triplet'、'atriplet'# --ckpt 权重文件保存,模式'2'表示每次验证后都保存模型,模式'1'只保存验证精度最高的模型,'0'永不保存# --verbose 每50batch在验证集上验证一次模型性能# --lr 学习率# --lr-steps 学习率衰减batch数# --wd 权重衰减# --num_epoch 共训练多少epoch停止训练# --models-root 模型保存路径
权重文件位置
- 官方预训练Mobilefacenet模型路径:
/insightface/retinaface_arcface/models/MobileFaceNet_ArcFace - 用南湖院数据训练的模型:
/insightface/recognition/ArcFace/models/y1_noPre_0629_ex0_noAlign_ex0, epoch 0005
权重转为wts格式
与Yolov5模型转换相似,需要将人脸识别arcface-mobilefacenet模型权重文件从.params格式转为wts格式,方便下一步进行模型部署时使用。模型转换脚本为/insightface/retinaface_arcface/deploy_slim/gen_wts.py。
1.4 模型验证
1.4.1 目标检测Yolov4(by 王慧娇)
训练结果
- 训练结果在
/object_detection/Yolov4/darknet目录下会有图片保存(蓝色的线代表loss,红色的线代表map),如图1.30所示:

图1.30 Yolov4训练结果输出图
模型测试
- 模型训练完之后会保存
*. _best.weights,可以用这个权重文件来进行测试。测试命令可以如下图1.31所示:

图1.31 Yolov4模型测试命令
python darknet_save_video.py \--input test1.mp4 \--out_filename test1.avi \--weights /object_detection/Yolov4/darknet/backup/yolov4-tiny-nhy-416x416_best.weights \--ext_output \--dont_show \--config_file /object_detection/Yolov4/darknet/cfg/yolov4-tiny-nhy-416x416.cfg \--data_file /object_detection/Yolov4/darknet/data/nhydata.data`# --input 表示输入视频或者图片所在路径;# --out_filename 表示输出文件名;# --weights表示权重文件;# --config_file表示模型设置文件;# --data表示数据文件。
1.4.2 目标检测Yolov5 (by 袁祖瑞)
训练结果
- 训练结果在
/object_detection/Yolov5/runs/train目录下会有图片保存,例如图1.32所示(图中可以查看loss和map值):

图1.32 Yolov5训练结果 - 下图1.33可以查看PR曲线:

图1.33 Yolov5训练PR曲线结果
模型测试
- 模型训练完之后
/object_detection/Yolov5/runs/train目录下会保存best.pt,可以用这个权重文件来进行测试。测试命令可以如下图1.34:

图1.34 Yolov5 测试命令
python detect.py \--source /object_detection/Yolov5/darknet/test.mp4 \--save-txt \--weights ./runs/train/nhy0624-0625/weights/best.pt \--name nhy0624-0625 \--conf 0.25 \--img-size 416# --source表示输入视频或者图片所在路径;# --save-txt 表示保存检测结果到txt文件;# --weights表示权重文件;# --name表示测试结果保存路径;# --conf 0.25表示检测结果阈值;# --img-size表示输入图片大小。
1.4.3 人脸识别Arcface(by 王慧娇)
训练结果
会在终端输出如图1.35所示的信息提示,Train-acc是指在与训练级同分布的验证集上精度,Train-lossvalue是损失值,随训练的进行,Train-acc会逐步上升,Train-lossvalue会逐步下降,在两者开始变得上下震荡,不再单调下降(或上升)时停止模型训练。目前提供的在南湖院采集的数据上预训练模型在验证集上精度可达99.8%。

图1.35 人脸识别模型训练输出信息
模型验证
生成demo脚本:
/insightface/retinaface_arcface/deploy_slim/face_recognition.sh- 命令解析如图1.36所示:

图1.36 人脸识别模型测试命令
cd /insightface/retinaface_arcface/deploy_slimpython face_recognition.py \--model /insightface/recognition/ArcFace/models/y1_noPre_0629_ex0_noAlign_ex0/y1-arcface-selfie/model,0005 \--det 2 \--sim_threshold 0.7 \--input_video /insightface/dataset/nhy_data/train/2021-06-25_15-11-56_30s-1min.avi \--output_video_name ./results/0629_5_nopre_2021-06-25_15-11-56_30s-1min_0.7.mp4 \--photo_gallery ./0628_gallery \--align 0 \--margin 0# --model 要加载的权重文件# --det 2 用Retinaface检测# --sim_threshold 人脸识别相似度阈值# --input_video 要测试的视频# --output_video_name 识别结果的视频命名# --photo_gallery 人脸注册库# --align 人脸检测是否进行对齐操作,为0不做对齐,为1执行对齐# --margin 人脸检测后是否在缩放前对框进行外扩,为44时,上下左右各外扩22(44/2)个像素
- 命令解析如图1.36所示:
计算测试集精度脚本在:
/insightface/recognition/ArcFace/verification.sh,命令如图1.37所示:- 命令解析

图1.37 计算测试集精度命令
cd /insightface/recognition/ArcFacepython -u verification.py \--gpu 0 \--data-dir /insightface/recognition/datasets/0628 \--model '/insightface/recognition/ArcFace/models/y1_noPre_0629_ex0_noAlign_ex0/y1-arcface-selfie/model,0005' \--target self_eval_1wp,lfw \--batch-size 64# --gpu 使用0号gpu# --data-dir 测试集bin文件所在路径# --model 权重文件# --target 测试集名称# --batch-size 批数量
- 命令解析
生成的demo见:
/insightface/retinaface_arcface/deploy_slim/results/0629_5_nopre_2021-06-25_15-11-56_30s-1min_0.7.mp4
