@wanghuijiao
2021-02-04T06:42:39.000000Z
字数 1942
阅读 2395
[论文阅读笔记]AU R-CNN: Encoding Expert Prior Knowledge into R-CNN for Action Unit Detection
学习笔记
0. 前言
相关资料:
论文基本信息
- 领域:人脸运动单元,表情识别
- 作者单位:清华大学,博士
- 发表时间:2019
- 期刊:Neuro Computing
- 一句话总结
- 提出了AU R-CNN结构,在BP4D达到了63%的AU平均检测精度。
1. 要解决什么问题
- 解决:识别一段视频中每一帧图像的人脸上出现了哪些AU。
- AU解释: Action Unit,FACS (Facial Action Coding System) 是人脸国际标准组织定义了44种人脸运动单元(AU),这些运动单元可以组合表示人脸表情所有可能的表情(包含皱眉,抿嘴等),AU 是组成人脸表情的基石。
- 其他算法存在的缺点:
- 已有的方法虽然提出了 AU center 的概念作为 AU 发生的重要区域,并被定义为人脸关键点的附近,这种定义粗糙而位置不精确。AU发生在人脸肌肉运动的特定区域,但不一定是某个 landmark 附近。
- 已有的研究使用CNN去识别整张脸的图像,而非局部区域的AU。
- 人脸 AU 识别是一个多 label 的分类问题,这种多label的约束可以被限制在更细的粒度上:人脸的局部区域上,从而达到更高的精度。
2. 用了什么方法
2.1 论文贡献
- 利用AU的先验知识,结合Regional Convolutional neural networks(R-CNN),提出了AU R-CNN网络,直接关注人脸与AU相关的区域。两点贡献:
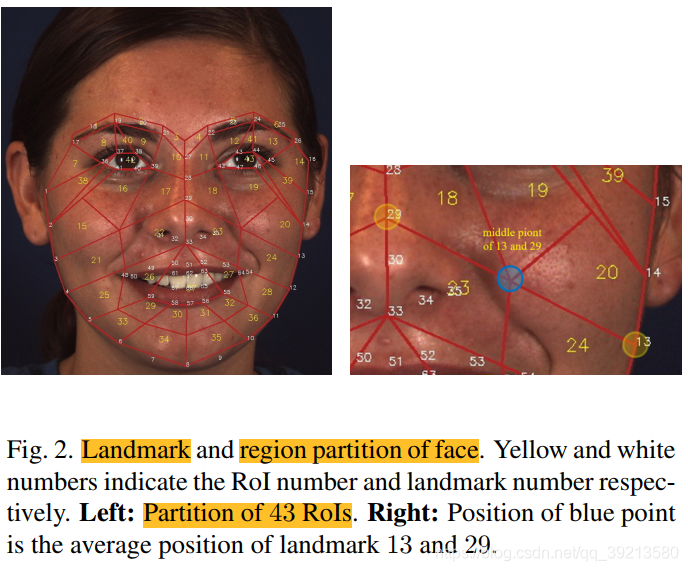
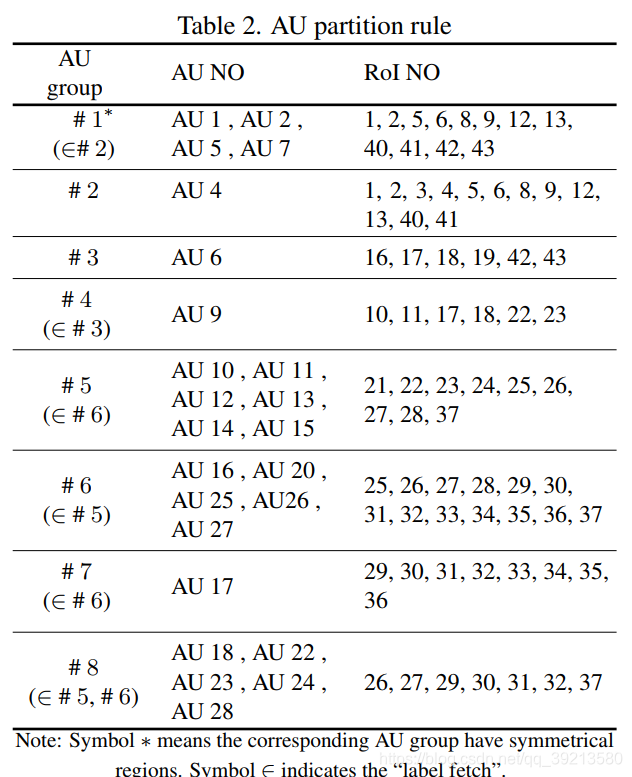
- AU R-CNN直接观测到了与AU位置相关的不同的人脸区域。作者定义了AU分区规则(AU Partition Rule),将区域定义的专家先验知识(各个AU的定义)与RoI级别的标签定义联系起来。这种设计取得了相当可观的好效果。
- 作者集成了不同的模型到AU R-CNN中,然后研究分析了不同动态模型性能表现背后的原因。
- 实验结果表明,只有静态RGB图像信息,没有基于光流的AU R-CNN优于融合了动态模型的AU R-CNN。
2.1 具体方法
为什么要划分AU AU检测是一个多标签分类任务。人脸是一个高度结构化的图片,标准CNN这种对整张图片贡献一个卷积核的方式无法捕获到微妙的外观改变。针对这个问题,作者定义了AU分区规则,如此一来可以将人脸图片看作是一组独立区域,而AU R-CNN用来识别每个区域。整个过程包括2步:
- 1、获取人脸关键点,然后人脸被分区为基于AU分区规则和关键点坐标的区域。这一步会产生AU掩膜,专家先验知识会编码到掩膜中。
- 2、人脸图片作为AU R-CNN backbone的输入,产生的特征map和AU 掩膜的最小bbox会一同作为RoI pooling 层的输入。全连接层的输出可视为分类概率。在学习过程中,图像级的ground truth标签也被划分为roi级。然后,我们使用“位或”操作符将roi级别的预测标签合并到图像级别的预测标签。(所以输入是人脸图片+AU掩膜bbox,输出是AU区域的分类概率???)
AU 划分过程:
- 人脸关键点 -> RoI区域+AU定义 -> AU Mask -> The minimum bounding box around each AU mask


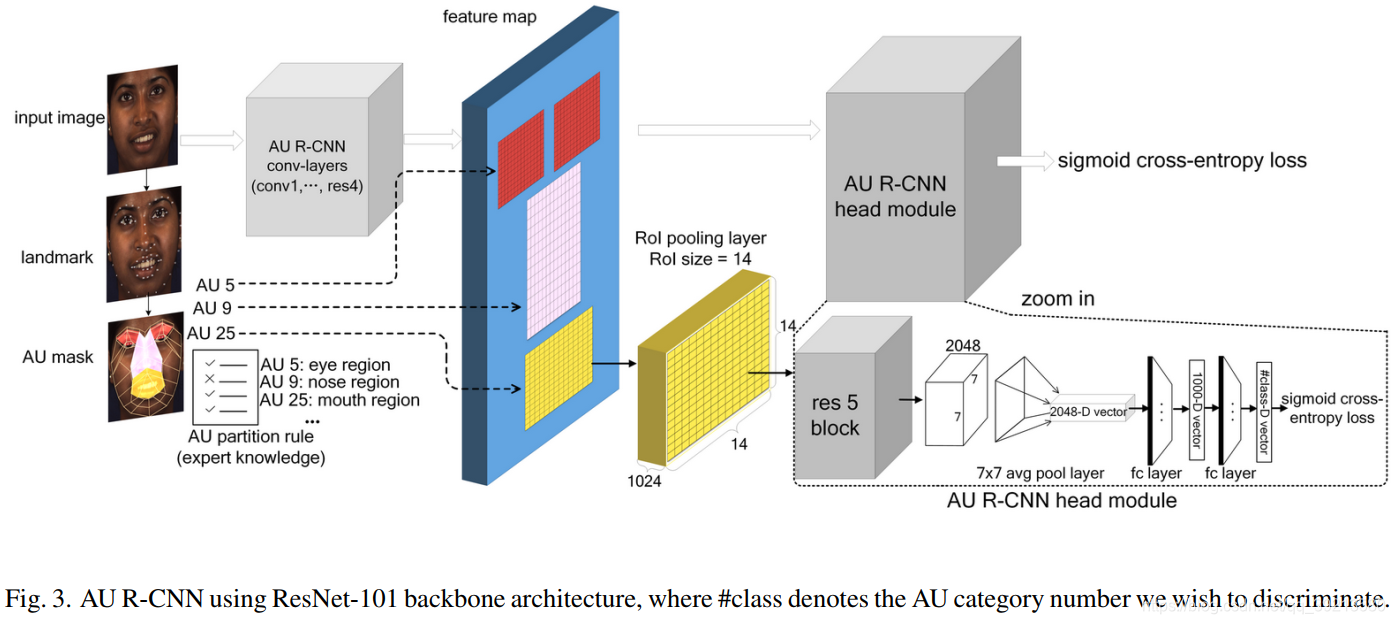
- 如下图,AU R-CNN有两个模块,特征提取模型+head。
backbone 选用ResNet-101或者VGG。图中特征提取模块由卷积层(ResNet-101的conv1,avg-pool和fc层)产生特征map,head模块包括RoI pooling层和顶层(res5,avg-pool,fc)。AU掩膜得到后,不相关区域被排除在外。然而,由于AU掩膜是多边形,没法直接送入fc层,所以引入了Faster R-CNN的RoI pooling层,RoI pooling 层用来转换举行RoI中的特征为固定尺度的H*W的特征map。为了使用RoI 池化层,AU mask被转化为最小的bbox作为输入。RoI 池化层需要一个名叫 “RoI size”的参数,表示池化层之后的RoI的高和宽。作者在ResNet-101 backbone实验中设为14*14,VGG-16和VGG-19中是7*7。
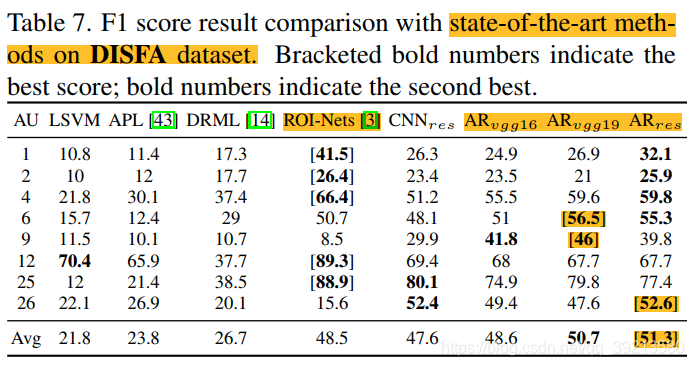
3. 效果如何
- 精度
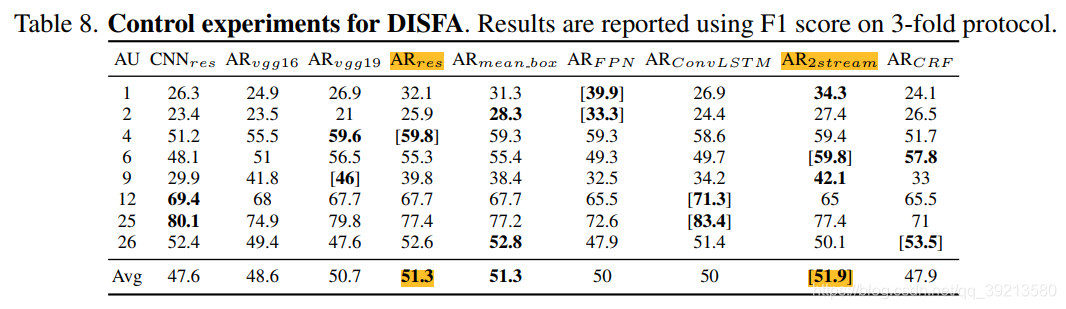
- On DISFA
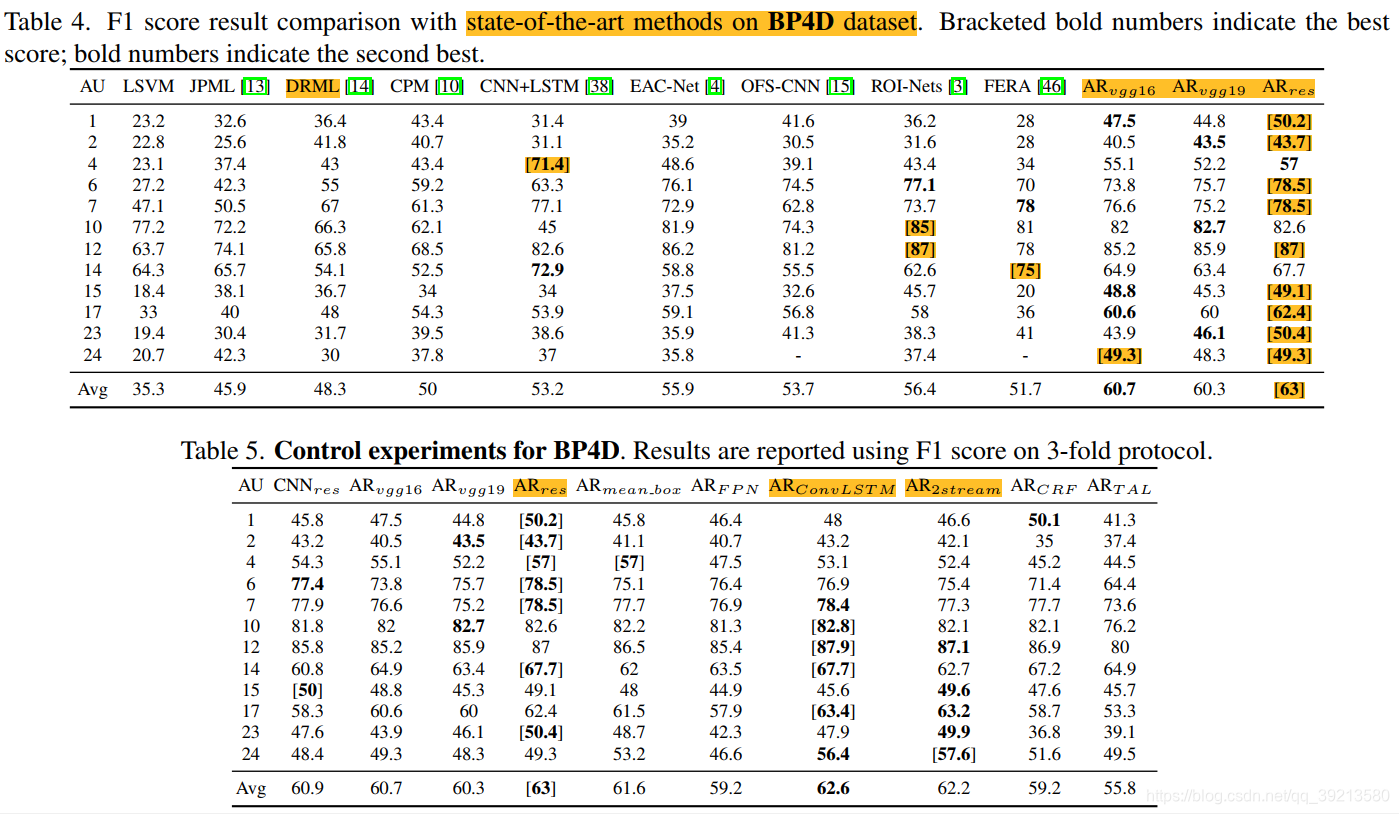
- On BP4D
- 速度
- VGG-19 on 512*512: 27.4ms
- GPU: Nvidia Geforce GTX 1080Ti GPU
4. 还存在什么问题&有什么可以借鉴
- 复现后再看。
