@wanghuijiao
2021-07-19T10:01:54.000000Z
字数 3028
阅读 1791
GAIA 调研报告
快速调研
前言
结论:有什么是可以拿来用或者参考的?
- 数据搜索(Task-specific Data Selection, TSDS):从公开数据集选择合适子集进行数据扩充。
- 自动选取与下游特定任务相关的数据。
GAIA是个什么东西?用来解决啥问题?
- 是什么?
- 是一个迁移学习框架。
- 目前在目标检测任务上已取得了不错的效果,作者拟在分割任务上沿用这一套,这是一个持久的项目,可以持续关注。
- 解决啥问题?
- 产业化落地应用中,需要自行搜集数据、标注、模型选择、训练、调参、优化、部署等步骤,GAIA完成的就是这些事情。面向行业的视觉物体检测一站式解决方案。
- 通俗讲,GAIA可以为实际的目标检测应用场景自动生成符合需求(运行速度、精度)的模型。比如要在园区检测人(包含各种姿态、遮挡等等),将检测类别与自制数据集(也可以完全不输入自制数据集,模型可以自动在公开数据集中寻找可用数据)以及其他需求,如图像分辨率、模型深度和宽度等信息,输入GAIA系统,输出是一系列不同时延和精度的模型,这些模型已调参完毕并可以直接部署在不同平台上,如手机端,移动端,服务器等。
- 怎么用?
- 终端用户只需要在 GAIA 配置文件中设置检测的类别,输入简单的几行命令,GAIA 迅速响应,自主学习数据集选择、模型选择和超参数优化等过程,用户可以轻松、快速获得任意下游数据、任意耗时要求的自适应解决方案(图 1)。
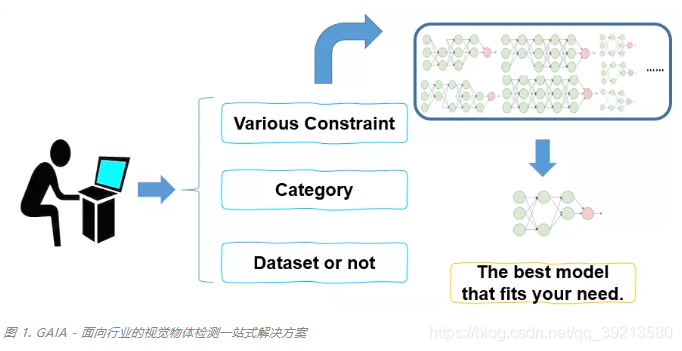
- 终端用户只需要在 GAIA 配置文件中设置检测的类别,输入简单的几行命令,GAIA 迅速响应,自主学习数据集选择、模型选择和超参数优化等过程,用户可以轻松、快速获得任意下游数据、任意耗时要求的自适应解决方案(图 1)。
- 怎么实现的?思路是?
- 模型搜索:用所有目标检测公开数据集预训练了一个大模型,然后在大模型基础上搜索小模型,并利用权重分享对小模型初始化,随后在小模型上用实际场景的特定任务的数据进行微调,最终输出一系列符合需求的小模型用来部署应用。
- 数据搜索:自动在现存的目标检测大型公开数据集上搜索相关数据用以训练。
数据集
- 上游数据集(训练大模型):Open Images,Objects365,MS-COCO,Caltech和CityPersons的集合,作者制定了统一的标签空间,共包含700个类别。
- 下游数据集(训练特定功能小模型):Universal Object Detection Benchmark(UODB)。UODB包括Pascal VOC [19], WiderFace [63], KITTI [20], LISA [44], DOTA [59], Watercolor [31], Clipart [31], Comic [31], Kitchen [21] and DeepLesions [61]等十个子集.
模型选型
- Faster RCNN&FPN 作为基本框架,ResNet作为网络原型,预训练大模型和小模型都基于ResNet。
实验精度如何?
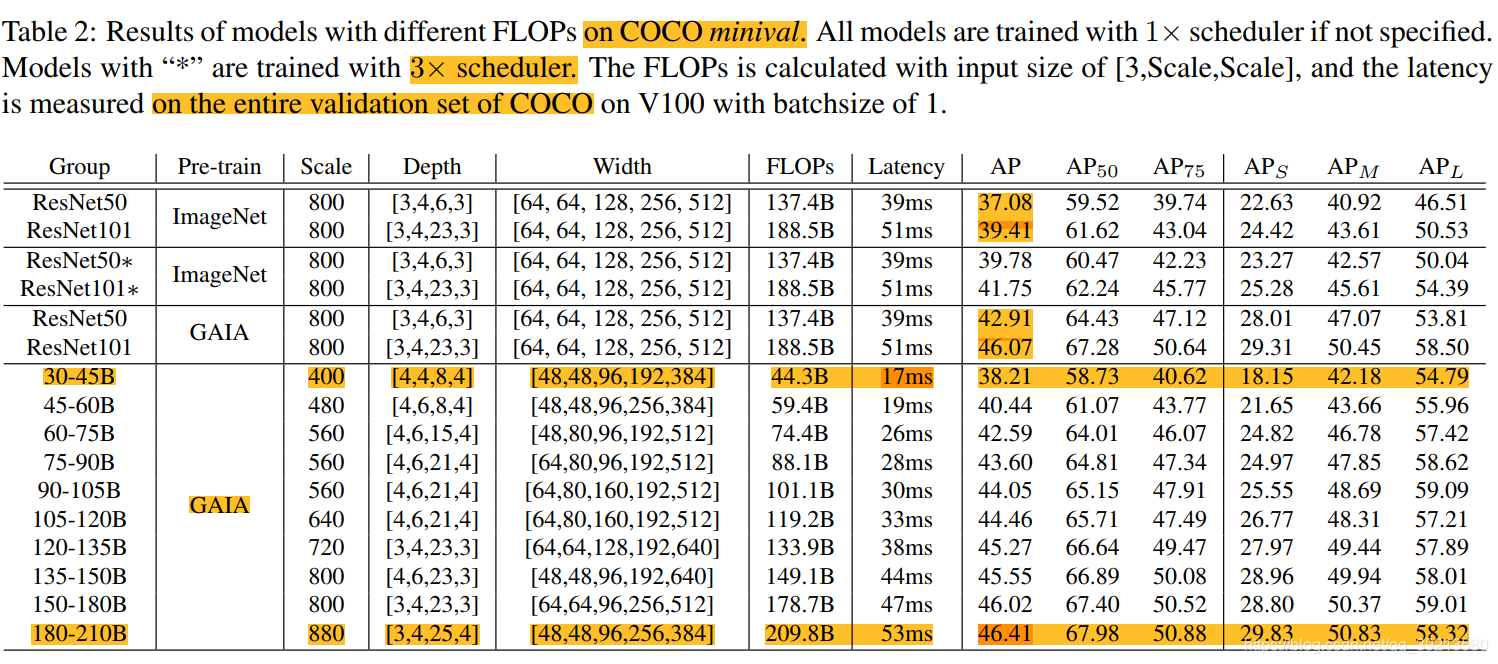
在COCO数据集上结果
- 表中GAIA是指GAIA用的公开数据集集合。仅将ImageNet替换成GAIA数据集,ResNet50和ResNet101的AP就分别涨了5.83%和6.66%,但是由于GAIA本身就包括COCO数据集,所以涨点也正常。
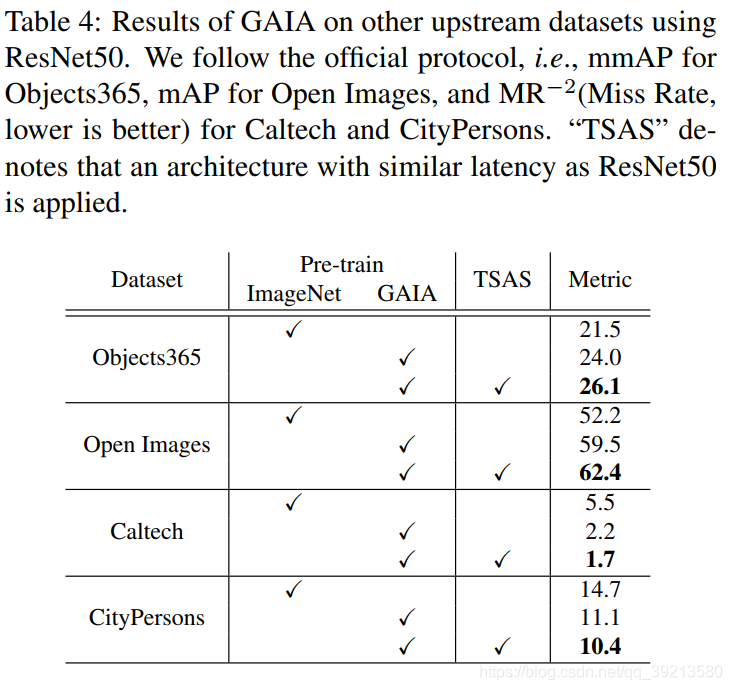
在其他上游数据集上结果
- 表中Pretrain一列用的是ResNet50模型结构,TSAS是模型搜索,是基于与ResNet50相同时延的网络结构(相当于模型大小一致)。比如第一行,在Objects365数据集上用GAIA数据集预训练的模型加上模型搜索(也就是在小模型上用Objects365数据继续微调过)后的结果明显上涨。(GAIA本身已经包括了Objects365,但添加TSAS前后还是有所上涨的,相当于速度不变,但精度提升!)
在下游数据集上结果

关于数据选择策略(TSDS)的结果:相似度策略效果提升最明显。

整体流程
上游数据集赋能
- GAIA会自动有效利用公开数据集进行数据筛选
- 简而言之,就是从公开数据集中找出来客户想要检测的物品类别的数据。
- 利用各种公开数据集,如 COCO、Object365、Open Images、Caltech、CityPersons、UODB 等主流目标检测数据集,GAIA 通过语义模型对类别建立语义相似度,将不同数据集中类别语义相似度大于阈值的归为同一类别,从而梳理出最终的类别和 ID 的映射关系。
全模型训练
- 价值是提供预训练模型
- 将神经网络架构搜索算法 NAS 与大规模预训练进行结合,提供涵盖各种 latency (潜在可能性)下的高性能预训练网络。然后对子网进行抽取,抽取时考虑网络深度、输入分辨率和网络宽度三种维度。
- 个人理解是先用大规模数据训练大型模型(超网),然后用大模型训练小模型(子网)。(上面说的神经网络架构搜索算法还没了解过,感觉超网和子网的概念属于这部分的知识点,这点理解的可能不准确,需要后续确认)。
特定下游任务数据选取
- 即使用户没有特定任务的带标签数据,GAIA也能在公开数据集中为其自动找到近似的数据。
- 有时候用户在具体的任务中,只能提供少量的带标签数据,此时,需要手动从开源数据集中找相同类别的数据来扩充数据集。GAIA 可以自动实现这个功能。
- 怎么实现?
- 用语义模型找到本地类别中语义信息最近似的类别,在该类别的上游数据集上通过模型映射向量的相似度找到域间差异最小的一部分图片。
下游模型选择
GAIA 已经测好所包含各种子网的 FLPOPS TABLE,以及多种硬件平台下的 LATENCY TABLE(图 6)。对于初级使用者而言,只需要在本地提供 FLPOPS、LATENCY 和硬件平台,就可以获得满足这些约束的性能最佳的子网。对于经验丰富的使用者,可通过 GAIA 提供的接口,自定义添加其他约束条件,轻松获取性能优异的定制化子网模型。
意思是说,作者根据实验设计了几种子网结构,所以只需要用户输入特定的选项就能组合出现有的子网结构,然后进行迁移学习?输出子网?
GAIA 数据搜索实现细节
- 数据搜索(Task-specific Data Selection, TSDS):从公开数据集选择合适子集进行数据扩充
- 给一个上游大规模数据集Ds,一个特定下游数据集Dt,数据选择的目标是,找到一个Ds的子集Ds*,使得在Dt与Ds*并集上训练的模型F在验证集Dt上取得的风险最小。
- 对于Ds和Dt,为每一个类别计算一个表征向量。对于每张图片和每个类别,表征向量V可以通过在所有实例上的Fc7层(盲猜用GAIA的预训练大模型提取的)的平均输出特征来获得。(一张图片里有不同的实例类别?每个类别在所有实例的特征上做平均?)然后对每个类别找最相关的数据,计算余弦距离,根据以下俩策略进行数据筛选。
- top-K: 选择排名前K的图片。
- 最相似:在P*Q的关系对中找最相似的图片。
- 收集图片直到满足数量要求,比如1000个。
有啥疑问?
- 子模型自动训练调参和优化不清楚
论文的贡献如下
- 我们演示了如何很好地结合迁移学习和权重共享学习,从而在各种架构上同时产生强大的预训练模型。
- 我们提出了一种高效可靠的方法来找到适合特定下游任务的网络架构。通过训练前和任务特定的架构选择,GAIA在10个下游任务中获得了令人惊讶的好结果,而没有对超参数进行独家调优。
- GAIA具有基于下游任务中每个类别的2张图像寻找相关数据的能力,以支持微调。这进一步扩展了GAIA在数据稀缺设置中的效用。
