@w1024020103
2017-03-26T03:44:10.000000Z
字数 12845
阅读 1113
Proj2与SimpleDB的转换
CS61B
现在基本上把SimpleDB的基本功能实现,接下来就要完善细节,使现在的database能够满足Proj2的要求。
首先,把两者的一些命令相互对应:

SimpleDb.java跟Proj2的Main.java比较像,是用来运行类似DB客户端的;只是现在我要把SimpleDb.java里每一个query的过程写到Database.java里面。
从最基本的convert命令开始,Proj2是没有convert命令的,所以在Proj2里面我们要修改print,直接让它读取.tbl文件,在方法内部完成convert(也许还是dat文件),再打印出table的string representation.
<table name>
Print should return the String representation of the table, or an appropriate error message otherwise.
现在的问题就是如何process到这个table name?
Parse里面的正则表达式太多了,首次接触,我选一个creat tale相关的代码来做案例学习:
private static final String REST = "\\s*(.*)\\s*",COMMA = "\\s*,\\s*",AND = "\\s+and\\s+";private static final Pattern CREATE_CMD = Pattern.compile("create table " + REST);private static final Pattern CREATE_NEW = Pattern.compile("(\\S+)\\s+\\(\\s*(\\S+\\s+\\S+\\s*" +"(?:,\\s*\\S+\\s+\\S+\\s*)*)\\)");private static void eval(String query) {Matcher m;if ((m = CREATE_CMD.matcher(query)).matches()) {createTable(m.group(1));} else {System.err.printf("Malformed query: %s\n", query);}}private void createTable(String expr) throws RuntimeException {Matcher m;if ((m = CREATE_NEW.matcher(expr)).matches()) {createNewTable(m.group(1), m.group(2).split(COMMA));} else if ((m = CREATE_SEL.matcher(expr)).matches()) {createSelectedTable(m.group(1), m.group(2), m.group(3), m.group(4));} else {System.err.printf("Malformed create: %s\n", expr);stupidOutPut = "ERROR: .*";}}private void createNewTable(String name, String[] cols) throws RuntimeException {//check whether the input type is validif (!checkCreateType(cols)) {stupidOutPut = "ERROR: .*";return;}DataTable newDTToCreate = create(name, cols);database.put(name, newDTToCreate);tableName.add(name);stupidOutPut = "";return;}public DataTable create(String name, String[] colNames) throws RuntimeException {try {//initiate new table.int cap = colNames.length;DataTable newTable = new DataTable(cap);colNames = processCreateColNames(colNames);newTable.initiate(colNames);//add new table into database.return newTable;} catch (RuntimeException e) {System.out.println("Create failed");stupidOutPut = "ERROR: .*";return null;}}
首先来看REST,COMMA, AND这几个常量究竟是什么:
REST =
"\\s*(.*)\\s*",
COMMA ="\\s*,\\s*",
AND ="\\s+and\\s+";
\\s+ matches sequence of one or more whitespace characters.
\\s matches single whitespace character.
.是另一个元字符,匹配除了换行符以外的任意字符
* 同样是元字符,不过它代表的不是字符,也不是位置,而是数量——它指定*前边的内容可以连续重复使用任意次以使整个表达式得到匹配
.* 连在一起就意味着任意数量的不包含换行的字符
注:
* 重复零次或更多次
+ 重复一次或更多次
REST = "\\s*(.*)\\s*",就是中间有任意数量不包含换行符的字符,并且这些字符被分为一组且为第一组,两边是任意数量的空白符;
COMMA = "\\s*,\\s*", 就是一个逗号,,两边有任意数量的空白符;
AND = "\\s+and\\s+"; 中间一个and,两边任意多的一个以上空白符;
再看下面这段代码:
private static final Pattern CREATE_CMD = Pattern.compile("create table " + REST);private static final Pattern CREATE_NEW = Pattern.compile("(\\S+)\\s+\\(\\s*(\\S+\\s+\\S+\\s*" +"(?:,\\s*\\S+\\s+\\S+\\s*)*)\\)");
参考:Java-正则表达式
这里CREAT_CMD是一个Pattern类,指定为正则表达式的字符串必须首先被编译为此类的实例。
即符合
"creat table + 任意数量空白符 + 任意数量不包含换行符的字符 + 任意数量空白符”
这样的字符串被编译成了CREAT_CMD这个Pattern实例。
看下面一段代码:
private static void eval(String query) {Matcher m;if ((m = CREATE_CMD.matcher(query)).matches()) {createTable(m.group(1));} else {System.err.printf("Malformed query: %s\n", query);}}
这里就是Pattern类和Matcher类的用法了,一个简单的用法实例:
Matcher.matches()
Matcher类提供三个匹配操作方法,三个方法均返回boolean类型,当匹配到时返回true,没匹配到则返回false
matches()对整个字符串进行匹配,只有整个字符串都匹配了才返回true
Java代码示例:
Pattern p=Pattern.compile("\\d+");Matcher m=p.matcher("22bb23");m.matches();//返回false,因为bb不能被\d+匹配,导致整个字符串匹配未成功.Matcher m2=p.matcher("2223");m2.matches();//返回true,因为\d+匹配到了整个字符串
那我们的代码意思就是:如果query是CREAT_CMD所编译的正则表达式字符串内容,也就是说query满足一下内容:
"creat table + 任意数量空白符 + 任意数量不包含换行符的字符 + 任意数量空白符”
就执行
createTable(m.group(1));
回到createTable()的代码:
private void createTable(String expr) throws RuntimeException {Matcher m;if ((m = CREATE_NEW.matcher(expr)).matches()) {createNewTable(m.group(1), m.group(2).split(COMMA));} else if ((m = CREATE_SEL.matcher(expr)).matches()) {createSelectedTable(m.group(1), m.group(2), m.group(3), m.group(4));} else {System.err.printf("Malformed create: %s\n", expr);stupidOutPut = "ERROR: .*";}}
这段代码就是区分createTable(m.group(1))里的m.group(1)这里给的信息是reate new table还是 create selected table.
那么这里的m.group(1)是哪一组呢?
看到之前的REST常量:
REST =
"\\s*(.*)\\s*",
以及
private static final Pattern CREATE_CMD = Pattern.compile("create table " + REST);
不难得出我们写命令:
create table
<table name>(<column0 name><type0>,<column1 name><type1>, ...)时,
group(1)就是除开create table之后的的
<table name>(<column0 name><type0>,<column1 name><type1>, ...)(除开他们整体前后的空格)
当我们写
create table
<table name>as<select clause>
group(1)就是
<table name>as<select clause>(除开他们整体前后的空格)
CREAT_NEW这个Pattern类所编译的正则表达式更为复杂,
"(\\S+)\\s+\\(\\s*(\\S+\\s+\\S+\\s*" + "(?:,\\s*\\S+\\s+\\S+\\s*)*)\\)"
(\\S+)第一个分组, 匹配任意一个或多个非空白符的字符
\\s+ 匹配任意一个或多个空白符
\\( 匹配左括弧 (
\\s* 匹配零个或多个空白符
(\\S+\\s+\\S+\\s*" + "(?:,\s*\\S+\\s+\\S+\\s*)) 第二个组
组内内容: \\S+\\s+\\S+\\s 加上零个或多个(?:,\s*\S+\s+\S+\s*)
任意一个或多个非空白符的字符 + 匹配任意一个或多个空白符 + 任意一个或多个非空白符的字符 + 匹配零个或多个空白符
(?:,\\s*\\S+\\s+\\S+\\s*) 第三个组
组内内容:?:,\\s*\\S+\\s+\\S+\\s*
不捕捉该组,
一个逗号“,”+ 任意零个或多个空白符+任意一个或多个非空白符的字符+任意一个或多个空白符+任意一个或多个非空白符的字符+任意零个或多个空白符
\\)右括弧
那个?:是用来干嘛的呢?这样标记后,对应的group就不能被捕捉,那个小组就不能通过m.group()被找到了.
create table <table name> (<column0 name> <type0>, <column1 name> <type1>, ...)
CREAT_NEW这个Pattern编译的正是creat table 后面输入的 <table name> (<column0 name> <type0>, <column1 name> <type1>, ...)
具体请参考:
java正则表达式的捕获组
加入刚才的query是匹配CREAT_NEW的正则表达式的,
那么现在createTable(m.group(1))就等同于
createTable(
<table name>(<column0 name><type0>,<column1 name><type1>, ...))
看到这里:
createNewTable(m.group(1), m.group(2).split(COMMA));
m.group(1)代表tablename,
m.group(2)代表用","隔开的column names,用一个数组保存每个column name
而creatNewTable()的代码是:
private void createNewTable(String name, String[] cols) throws RuntimeException {//check whether the input type is validif (!checkCreateType(cols)) {stupidOutPut = "ERROR: .*";return;}DataTable newDTToCreate = create(name, cols);database.put(name, newDTToCreate);tableName.add(name);stupidOutPut = "";return;}
create()的代码:
public DataTable create(String name, String[] colNames) throws RuntimeException {try {//initiate new table.int cap = colNames.length;DataTable newTable = new DataTable(cap);colNames = processCreateColNames(colNames);newTable.initiate(colNames);//add new table into database.return newTable;} catch (RuntimeException e) {System.out.println("Create failed");stupidOutPut = "ERROR: .*";return null;}}
最后又回去写convert,因为原SimpleDB都是先把文件转化成.dat文件在处理的。真的被这个Proj2搞了太久了,SimpleDB的参考书是一部大头,根本不可能短时间消化,所以我已经不要求自己完全掌握这个数据库到底怎么运行的,我现在只要求自己至少写出proj2要求的print一个table的内容,其他的都可以以后再做。
注意到convert()里面的HeapFileEncoder()有这样一段Javadoc:
/** Convert the specified input text file into a binary* page file. <br>* Assume format of the input file is (note that only integer fields are* supported):<br>* int,...,int\n<br>* int,...,int\n<br>* ...<br>* where each row represents a row.<br>* <p>* The format of the output file will be as specified in HeapPage and* HeapFile.** @see HeapPage* @see HeapFile* @param inFile The input file to read data from* @param outFile The output file to write data to* @param npagebytes The number of bytes per page in the output file* @param numFields the number of fields in each input line/output row* @throws IOException if the input/output file can't be opened or a* malformed input line is encountered*/// HeapFileEncoder.convert(sourceTblFile,targetDatFile,// BufferPool.PAGE_SIZE,numOfAttributes,ts,fieldSeparator);public static void convert(File inFile, File outFile, int npagebytes,int numFields, Type[] typeAr, char fieldSeparator)
这里在讲,必须要是全部是int类型的列才能转换,那现在我必须把这个改成不管是int还是string都可以转换才行。
看到HeapFileEncoder.convert方法的代码,用到了BufferedReader.read()方法,于是查阅了相关信息,用法如下:
我們先準備一個文字檔 test.txt 內容如下 :
1.裘千尺
2.小龍女
3.楊過
4.公孫綠萼
5.郭靖
用 BufferedReader 繼承自 Reader 類別的 read() 方法來讀取, 但此方法是一次讀取一個字元, 讀到檔尾時會傳回 -1, 但其傳回值型態是 int, 亦即字元的整數編碼, 因此顯示時必須用 (char) 來強制轉型才會顯示原始檔案內容, 如下列範例 2 所示 :
測試範例:
import java.io.*;public class file2 {public static void main(String[] args) {try {FileReader fr=new FileReader("test.txt");BufferedReader br=new BufferedReader(fr);int ch;while ((ch=br.read()) != -1) {System.out.print((char)ch);}}catch (IOException e) {System.out.println(e);}}}
這樣就不會像 readLine() 那樣會自動刪除列尾的跳行字元了, 即使用 print 也會輸出完整內容 :
H:\Java\JT>java file2
1.裘千尺
2.小龍女
3.楊過
4.公孫綠萼
5.郭靖
如果沒有強制轉型為 char, 就會輸出編碼值 :
H:\Java\JT>java file2
4946350322131523610131050462356740845228991310514626954369421310524620844234033216033852131053463710138742
参考资料:Java 複習筆記 : 檔案處理
FileOutputStream 是用来把二进制数据写指定文件的:
/**In Java, FileOutputStream is a bytes stream class that’s used to handle raw binary data. To write the data to file, you have to convert the data into bytes and save it to file. See below full example.**/package com.mkyong.io;import java.io.File;import java.io.FileOutputStream;import java.io.IOException;public class WriteFileExample {public static void main(String[] args) {FileOutputStream fop = null;File file;String content = "This is the text content";try {file = new File("c:/newfile.txt");fop = new FileOutputStream(file);// if file doesnt exists, then create itif (!file.exists()) {file.createNewFile();}// get the content in bytesbyte[] contentInBytes = content.getBytes();fop.write(contentInBytes);fop.flush();fop.close();System.out.println("Done");} catch (IOException e) {e.printStackTrace();} finally {try {if (fop != null) {fop.close();}} catch (IOException e) {e.printStackTrace();}}}}
参考资料:
How to write to file in Java – FileOutputStream
此处还用到了几次continue,发现自己已经忘了continue的用法,下面回忆一下:
The continue Statement
`The continue statement skips the current iteration of a for, while , or do-while loop. The unlabeled form skips to the end of the innermost loop's body and evaluates the boolean expression that controls the loop. The following program, ContinueDemo , steps through a String, counting the occurences of the letter "p". If the current character is not a p, the continue statement skips the rest of the loop and proceeds to the next character. If it is a "p", the program increments the letter count.
continue会跳到最内部的循环的尾部,然后再次回到控制循环的boolean问句,继续循环。比如uzheli,continue会跳过for loop内部后面的numPs++,而直接跳到最尾部,继续for loop当i=i+1时的循环。
class ContinueDemo {public static void main(String[] args) {String searchMe = "peter piper picked a " + "peck of pickled peppers";int max = searchMe.length();int numPs = 0;for (int i = 0; i < max; i++) {// interested only in p'sif (searchMe.charAt(i) != 'p')continue;// process p'snumPs++;}System.out.println("Found " + numPs + " p's in the string.");}}
Here is the output of this program:
Found 9 p's in the string.
然后是ByteArrayOutputStream,也是首次看到:

public void writeTo(OutputStream outSt)
Writes the entire content of this Stream to the specified stream argument.
将字节数组输出流的内容写入另外一个输出流
参数 (outSt要写入的输出流)
ByteArrayOutputStreamwriteTo.javapackage net.howsoftworks;import java.io.ByteArrayOutputStream;public class ByteArrayOutputStreamwriteTo{public static void main(String[] args) throws Exception {byte[] byteArr = new byte[]{0x61, 0x62, 0x63, 0x64, 0x65, 0x66, 0x67,0x30, 0x31, 0x32, 0x33, 0x34, 0x35};ByteArrayOutputStream os = new ByteArrayOutputStream();os.write(0x41);os.write(byteArr, 1, byteArr.length - 1);System.out.println("output stream content : " + os.toString());ByteArrayOutputStream os2 = new ByteArrayOutputStream();os.writeTo(os2);System.out.println("output stream2 content : " + os2.toString());}}
输出:
output streamm content : Abcdefg012345
output stream2 content : Abcdefg012345
参考资料:
Java ByteArrayOutputStream Example
ByteArrayOutputStream再次理解
Creating a file from ByteArrayOutputStream in Java.
Java ByteArrayOutputStream Class
接下来还有一个DataOutputStream,也是第一次见到,它可以向输出流里直接写基础类型的数据:比如int,float,double等等:
A data output stream lets an application write primitive Java data types to an output stream in a portable way. An application can then use a data input stream to read the data back in.
下面是用法举例:
//Java program to demonstrate DataOutputStream// This program uses try-with-resources. It requires JDK 7 or later.import java.io.*;class DataOutputStreamDemo{public static void main(String args[]) throws IOException{//writing the data using DataOutputStreamtry ( DataOutputStream dout =new DataOutputStream(new FileOutputStream("file.dat")) ){dout.writeDouble(1.1);dout.writeInt(55);dout.writeBoolean(true);dout.writeChar('4');}catch(FileNotFoundException ex){System.out.println("Cannot Open the Output File");return;}// reading the data back using DataInputStreamtry ( DataInputStream din =new DataInputStream(new FileInputStream("file.dat")) ){double a = din.readDouble();int b = din.readInt();boolean c = din.readBoolean();char d=din.readChar();System.out.println("Values: " + a + " " + b + " " + c+" " + d);}catch(FileNotFoundException e){System.out.println("Cannot Open the Input File");return;}}}
Output:
Values: 1.1 55 true 4
参考资料:
DataOutputStream.write
Java.io.DataOutputStream in Java
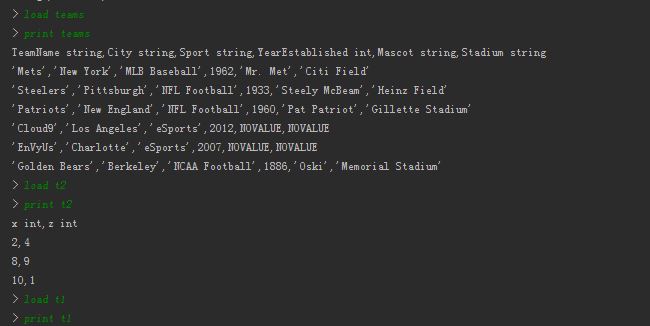
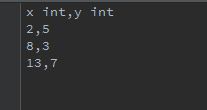
t1的实际内容是:
现在我打印t1情况如下:
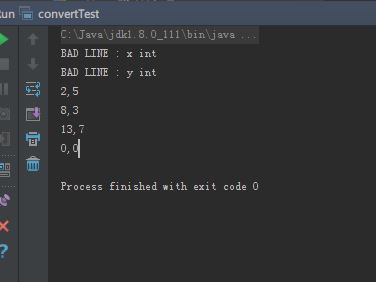
发现为什么前两行会是BAD LINE: x int了,是由以下代码引起:
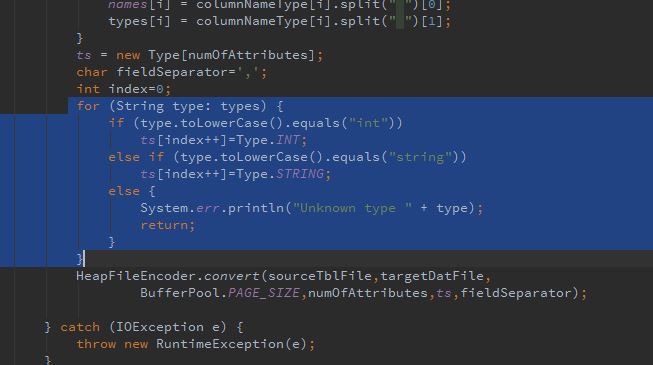
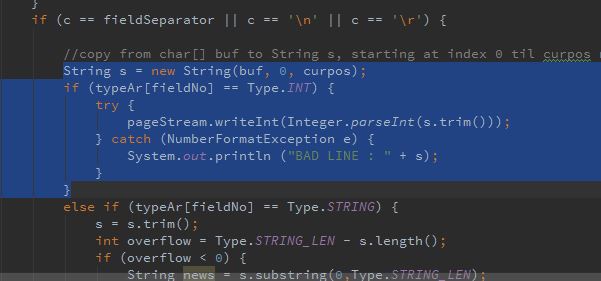
我t1的第一行其实是列名和列类型,但因为被识别成int类型,所以被当做数字了,然后根本不符合数字格式,所以报出NumberFormatException这个异常。
能否实现一个方法,第一行单独全部按照string打印,从第二行开始按照它的转换方法来依次打印?
为了测试如果全是string类型,不涉及int,打印会正常进行,我试了一下全是string的fans.tbl:
文件内容:
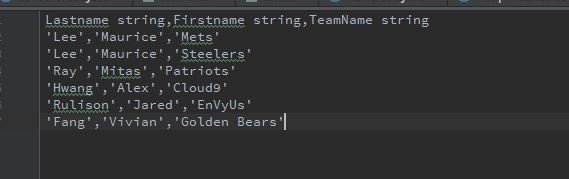
打印效果如下:
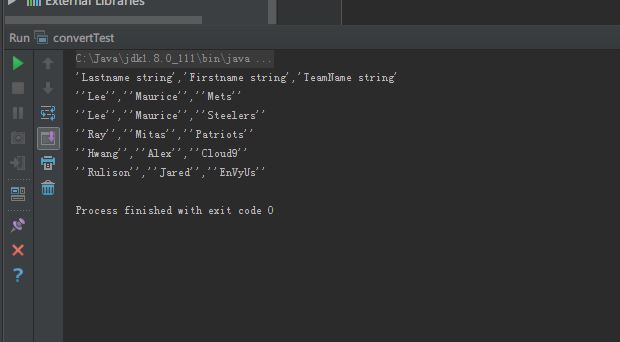
虽然双单引号和行数的细节还有差异,但今天终于没有报错了,似乎看到了久违的希望。
写了这么一行:
String firstLine = br.readLine();pageStream.writeInt(firstLine.length());pageStream.writeChars(firstLine);
出现了奇怪的现象:
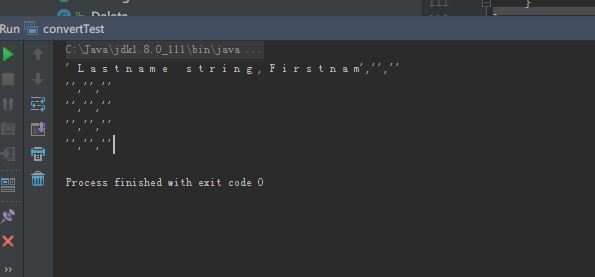
改动了一下,想把第一行看作是一个TYPE.String来转换,看样子转换成的.dat文件确实把第一行包括进去了(有细节的格式问题),但是现在问题似乎处在print上了,print的时候没办法识别出第一行row对象,因为搞不清楚每一column是什么type,需要进一步修改。目前其实我是把第一行看作一整个string,可能跟column number这些都发生了冲突。
String firstLine = br.readLine();firstLine= firstLine.trim();int overFlowFirstLine = Type.STRING_LEN - firstLine.length();if (overFlowFirstLine < 0) {String news = firstLine.substring(0,Type.STRING_LEN);firstLine = news;}pageStream.writeInt(firstLine.length());pageStream.writeBytes(firstLine);while (overFlowFirstLine-- > 0) {pageStream.write((byte) 0);}
目前的想法是:
第一行还是要按“,”隔开来读,也就是列数跟其他行一样,不能把第一行看成是一整个string.但是要手动将每一列的type设定为string,其他的就可以按照普通的转换方式来了。
当我观察了一下print出来的内容,我发现int类型的数字如果是被判断成string类型,打印出来的效果是一样的,所以我只要把所有的列都判断成string类型,那不管它实际上是string类型还是int类型,都可以成功按格式打印!
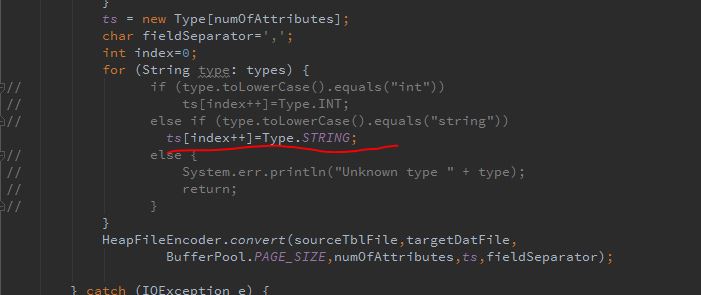
终于成功地打印出了一次完整的内容:
原.tbl文件:
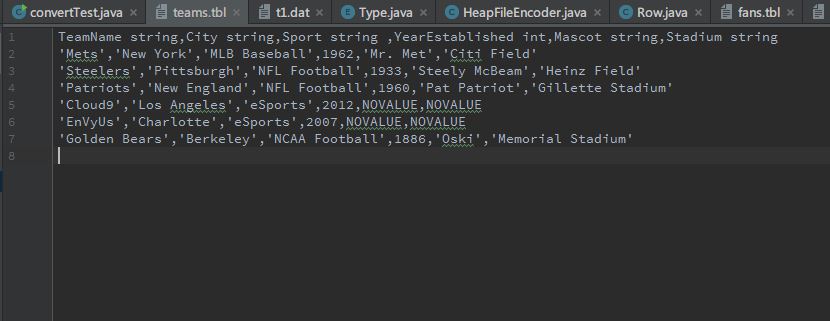
打印效果:
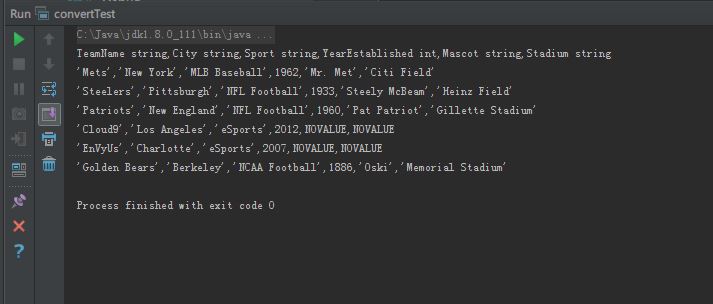
有时候打印会少最后一行,这时候把原tbl文件多加几行多打印几次,再删掉返回原状,就可以了,原因不明。
无论如何,里程碑式的进步啊,终于可以完全符合proj2的load,print了!
如图: