@w1024020103
2017-03-15T06:47:22.000000Z
字数 4141
阅读 1060
Proj2 A simple query
CS61B
The purpose of this section is to illustrate how these various components are connected together to process a simple query. Suppose you have a data file, "some_data_file.txt", with the following contents:
1,1,1
2,2,2
3,4,4
You can convert this into a binary file that SimpleDB can query as follows:
java -jar dist/simpledb.jar convert some_data_file.txt 3
Here, the argument "3" tells conver that the input has 3 columns.
这部分的目的是为了展示这些不同的部分是如何连接在一起来处理一个简单的查询的。加入你有一个data文件,"some_data_file.txt", 内容如下:
1,1,1
2,2,2
3,4,4
你可以通过下列方法将它转化成DB能够查询的二进制文件:
java -jar dist/simpledb.jar convert some_data_file.txt 3
这里,“3”这个参数代表输入有3列。
The following code implements a simple selection query over this file. This code is equivalent to the SQL statement SELECT * FROM some_data_file.
以下代码将对这个文件实施一个简单的selection查询,这个代表与SQL语句 SELECT * FROM some_data_file是等价的。
package simpledb;import java.io.*;public class test {public static void main(String[] argv) {// construct a 3-column table schemaType types[] = new Type[]{ Type.INT_TYPE, Type.INT_TYPE, Type.INT_TYPE };String names[] = new String[]{ "field0", "field1", "field2" };TupleDesc descriptor = new TupleDesc(types, names);// create the table, associate it with some_data_file.dat// and tell the catalog about the schema of this table.HeapFile table1 = new HeapFile(new File("some_data_file.dat"), descriptor);Database.getCatalog().addTable(table1, "test");// construct the query: we use a simple SeqScan, which spoonfeeds// tuples via its iterator.TransactionId tid = new TransactionId();SeqScan f = new SeqScan(tid, table1.getId());try {// and run itf.open();while (f.hasNext()) {Tuple tup = f.next();System.out.println(tup);}f.close();Database.getBufferPool().transactionComplete(tid);} catch (Exception e) {System.out.println ("Exception : " + e);}}}
The table we create has three integer fields. To express this, we create a TupleDesc object and pass it an array of Type objects, and optionally an array of String field names. Once we have created this TupleDesc, we initialize a HeapFile object representing the table stored in some_data_file.dat. Once we have created the table, we add it to the catalog. If this were a database server that was already running, we would have this catalog information loaded. We need to load it explicitly to make this code self-contained.
我们创建的这个table有3个整数列。为了表达出这个属性,我们新建一个RowDesc对象,传给它一个Type对象组成的数组,以及选择性地传给它一个Column Names组成的字符串数组。一旦我们建好了这个RowDesc,我们就初始化一个HeapFile对象来代表储存在some_data_file.dat里的这个table。一旦我们建好了table,我们就把它加到catalog里面。如果有一个数据库服务器正在运行,我们就将能够载入这个catalog的信息。我们需要明确地载入它,以使得这个代码齐全独立。
Once we have finished initializing the database system, we create a query plan. Our plan consists only of the SeqScan operator that scans the tuples from disk. In general, these operators are instantiated with references to the appropriate table (in the case of SeqScan) or child operator (in the case of e.g. Filter). The test program then repeatedly calls hasNext and next on the SeqScan operator. As tuples are output from the SeqScan, they are printed out on the command line.
一旦我们完成数据库系统的初始化,我们就新建一个查询方法。我们的方法只由SeqScan这个运算符构成,它可以从磁盘扫描rows.通常来讲,这些运算符是和对适当的table的引用一起实例化的(比如SeqScan)或者是和它的字运算符一起实例化的(比如Filter)。测试程序重复地在SeqScan运算符里调用hasNext和Next。rows从SeqScan输出,也从命令行打印出来。
We strongly recommend you try this out as a fun end-to-end test that will help you get experience writing your own test programs for simpledb. You should create the file "test.java" in the src/java/simpledb directory with the code above, and place the some_data_file.dat file in the top level directory. Then run:
ant
java -classpath dist/simpledb.jar simpledb.test
Note that ant compiles test.java and generates a new jarfile that contains it.
我们强烈建议你尝试这个端对端的测试,来帮助你积累写自己的DB测试程序的经验。你应该在src/java/db directory里面新建一个"test.java"文件,将上面的代码写进去,然后将some_data_file.dat放在最顶部的目录里,然后运行:
`ant
java -classpath dist/simpledb.jar simpledb.test
注意:ant会编译test.java而且产生一个包含test.java的新的jarfile。
分析:
题目中说要用java jar dist/simpledb.jar convert some_data_file.txt 3这个命令行去执行转换工作,实际上就在IntelliJ里run一下db/SimpleDb.java就行,注意把运行需要的参数写在:Run > Edit Configurations > Program Argument里面写好convert some_data_file.txt 3,然后运行SimpleDb,可以看到项目目录下面生成了some文件_data_file.dat这个文件。
因为proj2里面table都是放在.tbl文件里的,我把这里的convert方法里稍微改动了一下,使得原来方法将.txt文件转换成.dat文件改为了从.tbl文件转换成.dat文件:
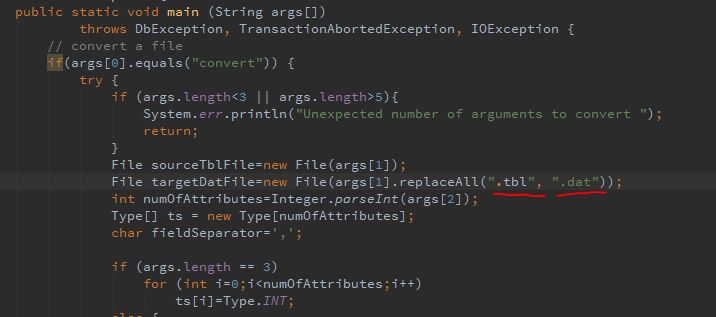
convert命令试出来没什么问题,然后我试了一下print命令,出问题了:
我的table contents是这样的:
1,1,1
2,2,2
3,4,4
可是print出来却只有两行:
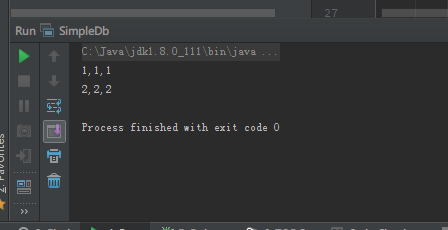
而且非常奇怪,当我把table contents增加到4、5、6行,或者减少到1、2行,就可以完全print正确:
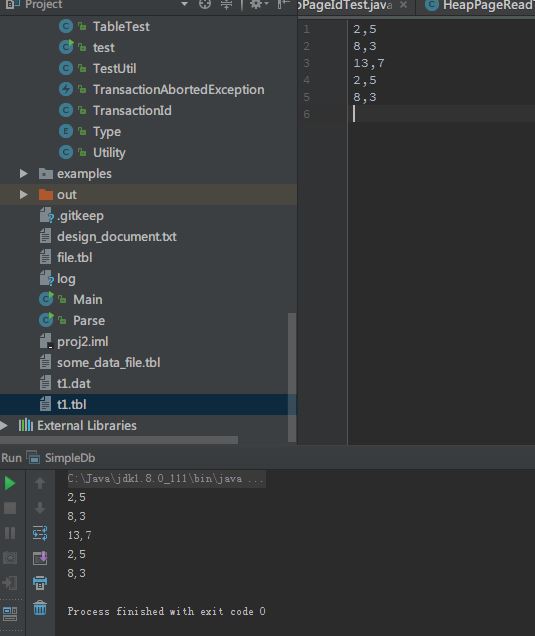
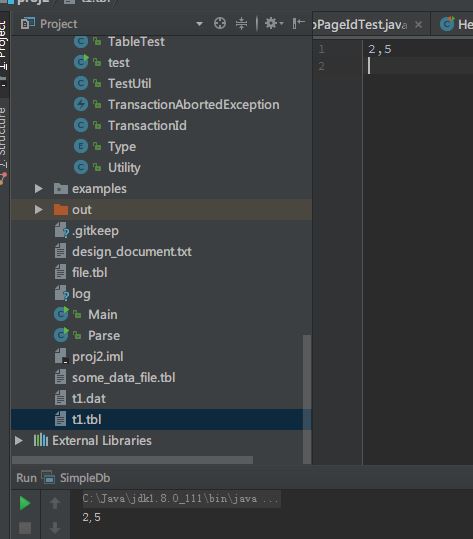
更奇怪的是,过了一会儿,三行也没毛病了:
这个simple query的作用只是让我通过一个test了解一下整个database的结构,可是它里面print的格式跟proj2的要求的格式还是有差别的,所以还需要后续的调整。并且,simpledb.java在proj2里面也是不存在的,我需要调整到Database.java以及Parse.java、Main.java等等
