@w1024020103
2017-03-18T13:19:14.000000Z
字数 7565
阅读 1237
Proj2 2.1 Filter and Join
CS61B
2.1. Filter and Join
1.3. Implementation hints
As before, we strongly encourage you to read through this entire document to get a feel for the high-level design of SimpleDB before you write code.
与以往一样,我们强烈建议你读完这整个文档来,变得对DB的设计有感觉。
We suggest exercises along this document to guide your implementation, but you may find that a different order makes more sense for you. As before, we will grade your assignment by looking at your code and verifying that you have passed the test for the ant targets test and systemtest. See Section 3.4 for a complete discussion of grading and list of the tests you will need to pass.
Here's a rough outline of one way you might proceed with your SimpleDB implementation; more details on the steps in this outline, including exercises, are given in Section 2 below.
Implement the operators Filter and Join and verify that their corresponding tests work. The Javadoc comments for these operators contain details about how they should work. We have given you implementations of Project and OrderBy which may help you understand how other operators work.
写Filter和Join并且通过相应的测试。这些运算符的Javadoc注释包含了他们应该如何工作的具体信息。我们提供了Project和OrderBy这两个运算符的写法,可能会帮助你理解其他运算符如何工作。
Implement IntegerAggregator and StringAggregator. Here, you will write the logic that actually computes an aggregate over a particular field across multiple groups in a sequence of input tuples. Use integer division for computing the average, since SimpleDB only supports integers. StringAggegator only needs to support the COUNT aggregate, since the other operations do not make sense for strings.
Implement the Aggregate operator. As with other operators, aggregates implement the DbIterator interface so that they can be placed in SimpleDB query plans. Note that the output of an Aggregate operator is an aggregate value of an entire group for each call to next(), and that the aggregate constructor takes the aggregation and grouping fields.
Implement the methods related to tuple insertion, deletion, and page eviction in BufferPool. You do not need to worry about transactions at this point.
写在BuffeRrPool里关于插入行、删除行、页收回等方法。现在你不需要担心transactions.
Implement the Insert and Delete operators. Like all operators, Insert and Delete implement DbIterator, accepting a stream of tuples to insert or delete and outputting a single tuple with an integer field that indicates the number of tuples inserted or deleted. These operators will need to call the appropriate methods in BufferPool that actually modify the pages on disk. Check that the tests for inserting and deleting tuples work properly.
Note that SimpleDB does not implement any kind of consistency or integrity checking, so it is possible to insert duplicate records into a file and there is no way to enforce primary or foreign key constraints.
写Insert和Delete运算符。想所有的运算符一样,Insert和Delete实施DbIterator,接受一连串rows,执行insert或者delete操作,再输出一个包含了一个整数项的row,表示了刚刚insert了或delete的row数。这些运算符需要调用BufferPool里适当的方法,以达到实际上修改磁盘上的pages的效果。确保insert和delete的测试通过。注意到,db不会做任何一致性或完整性测试,所以有可能会在一个文件里插入重复的行,而且没有办法实现强制性的primary key或foreign key的限制。
At this point you should be able to pass all of the tests in the ant systemtest target, which is the goal of this lab.
You'll also be able to use the provided SQL parser to run SQL queries against your database! See Section 2.7 for a brief tutorial and a description of an optional contest to see who can write the fastest SimpleDB implementation.
现在你应该都通过了systetest的测试,这也是本次lab的主要目的。你将能够是有提供的SQL parser来对你的数据库实现SQL命令。看section2.7的教程。
Finally, you might notice that the iterators in this lab extend the Operator class instead of implementing the DbIterator interface. Because the implementation of next/hasNext is often repetitive, annoying, and error-prone, Operator implements this logic generically, and only requires that you implement a simpler readNext. Feel free to use this style of implementation, or just implement the DbIterator interface if you prefer. To implement the DbIterator interface, remove extends Operator from iterator classes, and in its place put implements DbIterator.
最后,你会注意到iterators继承了Operator而不是继续采用DbIterator借口,因为写next/hasNext方法经常重复、恼人、容易错,而Operator把这个逻辑实现得很通用,而且只需要你实现一个更简单的readNext. 请对这类实现变得xigua习惯,或者你也可以继续使用DbIterator如果你坚持的话。要实施DbIterator借口的话,在iterator类里删掉extends Operator,然后用implements DbIterator代替。
You may also wish to consult the JavaDoc for SimpleDB.
Recall that SimpleDB DbIterator classes implement the operations of the relational algebra. You will now implement two operators that will enable you to perform queries that are slightly more interesting than a table scan.
回想起db的DbIterator类实施了关系代数的运算。现在你要实施两个运算,它们会使你能够在db上实行一些比table扫描更有趣的命令。
Filter: This operator only returns tuples that satisfy a Predicate that is specified as part of its constructor. Hence, it filters out any tuples that do not match the predicate.
Filter:这个运算符只会返回满足Predicate要求的rows,这个要求是构造函数的一部分。因此,它可以过滤掉那些不满足这个predicate的rows.
Join: This operator joins tuples from its two children according to a JoinPredicate that is passed in as part of its constructor. We only require a simple nested loops join, but you may explore more interesting join implementations. Describe your implementation in your lab writeup.
Join:这个运算符会从它的children里连接rows,连接规则被作为JoinPredicate成为构造函数的一部分。我们仅仅要求一个简单的循环join,但是你可以探索更有趣的join.你要把你的方法写在lab writeup里面。
Exercise 1. Implement the skeleton methods in:
src/simpledb/Predicate.java
src/simpledb/JoinPredicate.java
src/simpledb/Filter.java
src/simpledb/Join.java
At this point, your code should pass the unit tests in PredicateTest, JoinPredicateTest, FilterTest, and JoinTest. Furthermore, you should be able to pass the system tests FilterTest and JoinTest.
写到Filter的fetchNext()方法时遇到一些问题,原先的写法是:
* @return The next Row that passes the filter, or null if there are no* more Rows* @see Predicate#filter*/protected Row fetchNext() throws NoSuchElementException,TransactionAbortedException, DbException {// some code goes hereif(child == null){throw new NoSuchElementException();}else if(!child.hasNext()){return null;}else{Row r = child.next();if(r == null){return null;}else{if (p.filter(r)){return r;}}}return null;}
一直通不过FilterTest, 完全不知道错在哪儿,参考了大神的代码,改成下面这样:
protected Row fetchNext() throws NoSuchElementException,TransactionAbortedException, DbException {// some code goes hereif(child == null){throw new NoSuchElementException();}else if(!child.hasNext()){return null;}else{Row r = child.next();if(r == null){return null;}else{if (p.filter(r)){return r;}}return fetchNext();}}
测试完全通过。
前面的open()方法不知道为什么要用到关键词super,在Filter的Dbiterator child open之前要先父类Operator的open().
public void open() throws DbException, NoSuchElementException,TransactionAbortedException {super.open();this.child.open();}
写close()的时候注意到父类的close方法的javadoc有写:
/*// * Closes this iterator. If overridden by a subclass, they should call// * super.close() in order for Operator's internal state to be consistent.// *///
所以在Filter的close()之后又写了父类的close():
public void close() {// some code goes herethis.child.close();super.close();}
后面这两个方法不是很清楚意图,但比较简单:
@Overridepublic DbIterator[] getChildren() {// some code goes here//do not know why this method.return new DbIterator[] {child};}@Overridepublic void setChildren(DbIterator[] children) {// some code goes herethis.child = children[0];}
后来发现父类Operator.java里其实有很多提示,比如getChildren()和setChidren的javadoc说得非常清楚,如果认真读了再写代码真的就是傻瓜题目。所以以后写代码的时候一定要注意子类父类之间的联系,会让coding变得更简单。
Operator是一个abstract class,而且implements DbIterator,以前没接触过abstact class.
最近正在做的部分的uml图:

写Join的时候,发现这里用的是Inner join,而Proj2要求的是Natural join,两者之间的区别是返回的列数不一样。
比如有两张表:

Inner Join:
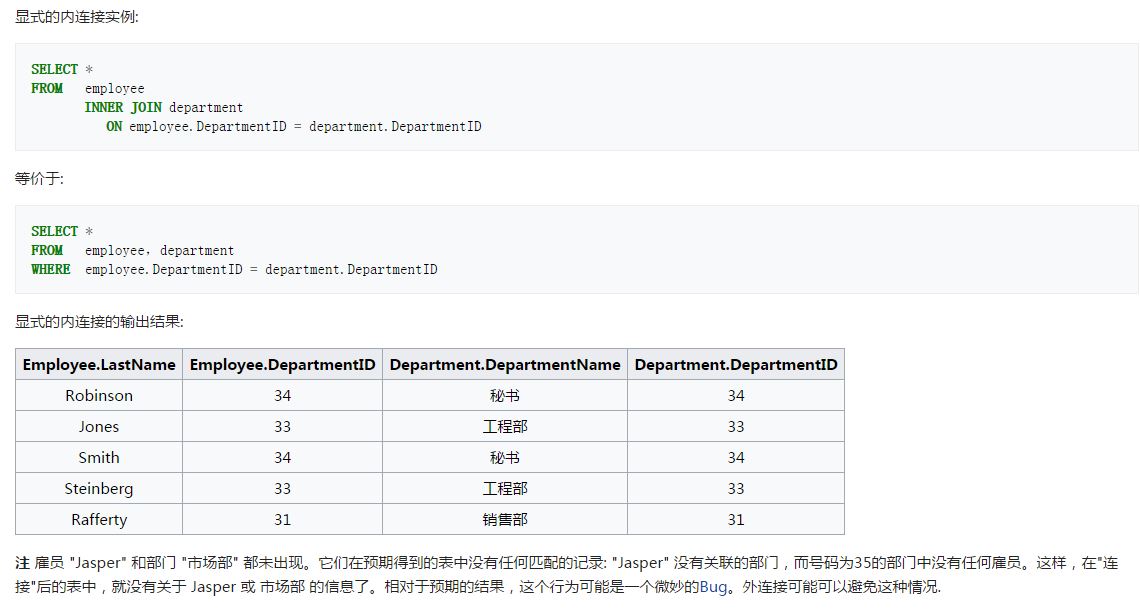
Natural Join:

下面是实现natrual join过程的一个例子:
先是笛卡尔叉乘、然后取出两原始表中有相同名字的列里有相同值的行,最后再去掉相同名字的两列中的一个重复列,得到最终结果。



Join写起来有些无从下手的感觉,参考了大神的代码,发现写了个helper method joinRows().但这个方法实施也不大看得懂缘由,抄了大部分. 又必须要把这里的Join改成natural join,这里的javadoc是这么说的:
Note that the Rows returned from this particular implementation of Join
* are simply the concatenation of joining Rows from the left and right
* relation. Therefore, if an equality predicate is used there will be two
* copies of the join attribute in the results. (Removing such duplicate
* columns can be done with an additional projection operator if needed.)
*
这里说最后要删除重复的列,只需要一个附加的projection 运算。
没懂这个project怎么用,就自己动手写了半天去掉重复列的方法,可是这里提供的table都没有columnNames,没办法通过去掉相同的列名来删除列, 最后才发现空指针,等于白写了。
一直犹豫该继续写完Insert delete那些再来改动还是现在就改,现在决定了,就算最后只完成了Join,print,load,这几个命令,我也满意,但绝对不能不按照Proj2的要求来,。现在就开始修改读取tbl文件、打印table的方法,一直到正确地完成Join再继续。
ra然后,在看到下面这张图时,发现做insertRow的时候可以学会一种创建数据的方法,就不用convert了,看来还是先完成insert,delete再继续改造成proj2的比较好!

