@fanxy
2020-05-17T11:13:24.000000Z
字数 11251
阅读 18755
第十三讲 极值理论、分位数估计与VaR
樊潇彦 复旦大学经济学院 金融数据
setwd("D:\\..\\Ch13")install.packages("sm","quantreg","evir")## 调用library(sm)library(quantreg)library(evir)library(stats)library(fPortfolio)library(RQuantLib)library(qcc)library(rugarch)library(fGarch)library(zoo)library(tseries)library(forecast)library(timeSeries)library(tidyverse)library(readxl)library(ggplot2)
1. 风险测度
根据巴塞尔协议,金融风险被分为三类:市场风险、信用风险和操作风险。一个与基本金融理论一致的市场风险测度 应满足下面四个条件( 为随机变量,):
1. 次可加性:
2. 单调性:
3. 正齐性:
4. 变换不变性:
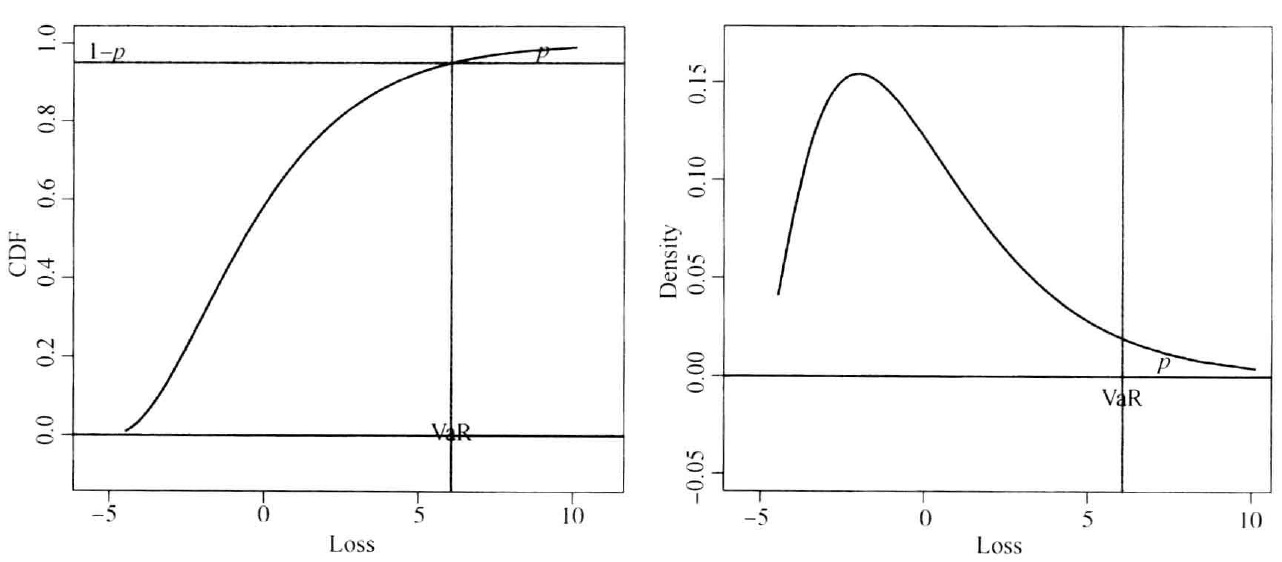
1.1 风险值(Value at Risk, VaR)
一个金融头寸在时刻 的价值记为 ,在接下来的 期的损失
假定随机变量 的累积分布函数为 ,我们把 定义为一个可能面临的巨大损失:
对于一元函数,VaR 就是损失分布的 分位数。相应地有:
- 对于正态分布、学生分布等常用分布,VaR的计算非常方便。
- 损失变量服从正态分布 :
- 标准化损失变量 服从自由度为 的学生分布 :
- 损失变量服从正态分布 :
mn=0.01; sd=2; p=0.05; q=1-p; nu=5 # 参数设定set.seed(1)rn=rnorm(1000) # 模拟数据rt=rt(1000,nu) # 可以用 plot(density(rn)) 命令画密度线y = c(rn,rt)g = factor(rep(c("r_n","r_t"), each=1000)) # 用因子变量标记两组library(sm)sm.density.compare(y, g) # 合并做图,进行比较legend("topright", levels(g), fill=2+(0:nlevels(g)))title(main="正态分布和学生分布密度曲线")z=qnorm(q); t=qt(q,nu)VaR_n=mn+z*sd # (7-2)正态分布VaRVaR_t=mn+t*sd # (7-3)学生分布VaRdata.frame(VaR_n, VaR_t)
- 当损失服从正态分布时,VaR是一致风险度量;但一般而言,VaR并不满足一致性条件。
- VaR 只是右尾概率的p分位数,并没有描述实际尾部行为。
1.2 期望损失(Expected Shortfall, ES)
定义 ES 为损失 时的期望值,也称为条件或尾部风险值(CVaR,TVaR)。
- 损失变量服从正态分布 :
- 标准化损失变量 服从自由度为 的学生分布 :
fz=dnorm(z); ft=dt(t,nu)ES_n=mn+fz/p*sd # (7-6)正态分布ESES_t=mn+ft/p*sd*(nu+t^2)/(nu-1) # (7-7)学生分布ESdata.frame(ES_n,ES_t)
1.3 风险度量制()方法
定义第 期的损失率:
第 期建仓并持有 期的损失率和相应的风险值为:
如果 服从无漂移的 IGARCH(1,1) 过程:
则基于信息 的条件期望:
从而有:
因此损失率服从正态分布 ,相应有 VaR 计算的时间平方根准则(squqre root of time rule):
需要注意的是,当损失率不满足均值为零、方差均值为零的特殊IGARCH(1,1)的假设,上述准则就失效了。
# P266:IBM股票da=read.table("d-ibm-0110.txt",header=T)head(da)ibm=log(da[,2]+1)source("RMfit.R")mm=RMfit(ibm)# 用rugarch包复制结果library(rugarch)igarch=ugarchspec(variance.model = list(model="iGARCH"),mean.model = list(armaOrder=c(0,0),include.mean=F), # 均值方程截距为0fixed.pars=list(omega=0)) # 方差方程截距为0igarch.fit=ugarchfit(spec=igarch, data=ibm)igarch.fcst = ugarchforecast(igarch.fit, n.ahead=1)ibm_sd=as.numeric(igarch.fcst@forecast$sigmaFor) # 预测sigma_T(1)names(igarch.fit@fit)c(alpha=1-as.numeric(igarch.fit@fit$coef[2]),sd=as.numeric(igarch.fit@fit$se.coef),ibm_sd=ibm_sd) # 回归结果ibm_mn=0; p=c(0.05,0.01,0.001); q=1-pz=qnorm(q)ibm_VaR_n=ibm_mn+z*ibm_sd # VaRfz=dnorm(z)ibm_ES_n=ibm_mn+fz/p*ibm_sd # ESdata.frame(p, ibm_VaR_n, ibm_ES_n)# P267:汇率da1=read.table("d-useu0111.txt",header=T)head(da1)rt=diff(log(da1[,4]))m2=RMfit(rt)
2. VaR计算的计量经济学方法
2.1 基于ARIMA-GARCH模型参数估计
为损失率 建立ARIMA(p,q)-GARCH(m,n)模型:
- 单期:
在模型估计的基础上,可以在最后一期预测下一期的收益率和波动率 。进而在假定 的分布的基础上,计算 和 。
# P271:IBM股票xt=-ibm # 计算多头损失率library(fGarch)m1=garchFit(~garch(1,1),data=xt,trace=F)m1 # P270估计结果m1pre1=as.numeric(predict(m1,1)) # 提前一步预测source("RMeasure.R")m11=RMeasure(mu=m1pre1[1],sigma=m1pre1[2])m2=garchFit(~garch(1,1),data=xt,trace=F,cond.dist="std") # 学生分布m2 # P271估计结果m2pre1=as.numeric(predict(m2,1))m22=RMeasure(mu=m2pre1[1],sigma=m2pre1[2],cond.dist="std",df=as.numeric(m2@fit$coef[5])) # 与P271结果不符# 用rugarch包复制结果sgarch_n=ugarchspec(variance.model = list(model="sGARCH"),mean.model = list(armaOrder=c(0,0),include.mean=T),distribution.model = "norm") # 正态分布sgarch_n.fit=ugarchfit(spec=sgarch_n, data=xt)sgarch_n.fcst = ugarchforecast(sgarch_n.fit, n.ahead=1)xt_nsd=as.numeric(sgarch_n.fcst@forecast$sigmaFor)xt_nmn=as.numeric(sgarch_n.fit@fit$coef[1])p=c(0.05,0.01); q=1-pz=qnorm(q)xt_VaR_n=xt_nmn+z*xt_nsdfz=dnorm(z)xt_ES_n=xt_nmn+fz/p*xt_nsddata.frame(p, xt_VaR_n, xt_ES_n) # P270结果sgarch_t=ugarchspec(variance.model = list(model="sGARCH"),mean.model = list(armaOrder=c(0,0),include.mean=T),distribution.model = "std") # 学生分布sgarch_t.fit=ugarchfit(spec=sgarch_t, data=xt)sgarch_t.fcst = ugarchforecast(sgarch_t.fit, n.ahead=1)xt_tsd=as.numeric(sgarch_t.fcst@forecast$sigmaFor)xt_tmn=as.numeric(sgarch_t.fit@fit$coef[1])nu=as.numeric(sgarch_t.fit@fit$coef[5])t=qt(q,nu)xt_VaR_t=xt_tmn+ t*xt_tsdfz=dnorm(z); ft=dt(t,nu)xt_ES_t=xt_tmn+ft/p*xt_tsd*(nu+t^2)/(nu-1)data.frame(p, xt_VaR_t, xt_ES_t) # P271结果
- 多期
当 服从正态分布时,在第 的提前 步预测的损失率服从正态分布,均值和方差为:
但是当 服从学生分布等非正态分布时, 不服从学生分布,此时需要通过数值模拟计算 和 。
# P274M1=predict(m1,15) # 正态分布pmean=sum(M1$meanForecast)pvar=sum((M1$meanError)^2)pstd=sqrt(pvar)M11=RMeasure(pmean,pstd)# P275vol=volatility(m2) # 学生分布a1=c(1.922*10^(-6),0.06448); b1=0.9286; mu=-4.113*10^(-4)ini=c(ibm[2515],vol[2515])set.seed(1) # 如果设不同的随机种子,结果与教材差别很大source("SimGarcht.R") # 模拟数据mm=SimGarcht(h=15,mu=mu,alpha=a1,b1=b1,df=5.751,ini=ini,nter=30000)rr=mm$rtnmean(rr)q=quantile(rr,c(0.95,0.99)) # VaRidx=c(1:30000)[rr>q[1]]mean(rr[idx]) # ES_0.95idx=c(1:30000)[rr>q[2]]mean(rr[idx]) # ES_0.99
2.2 基于分位数回归
- 样本分位数
将损失率的样本数据从小到大排列:
对于分位数 ,记 ( 和 分别为满足这一条件的最小和最大整数),。 分位的样本估计值(即VaR)和ES分别为:
# P277:样本分位数quantile(xt,0.95)sxt=sort(xt)0.95*2515es=sum(sxt[2390:2515])/(2515-2389)es
- 分位数回归
与一般的线性回归 不同,分位数回归的系数与解释变量 所处的分位数有关:
如果解释变量 , 就是 的分位数。否则 表示不同水平 的 对 的影响不同,如收入对食品支出的分位数回归:
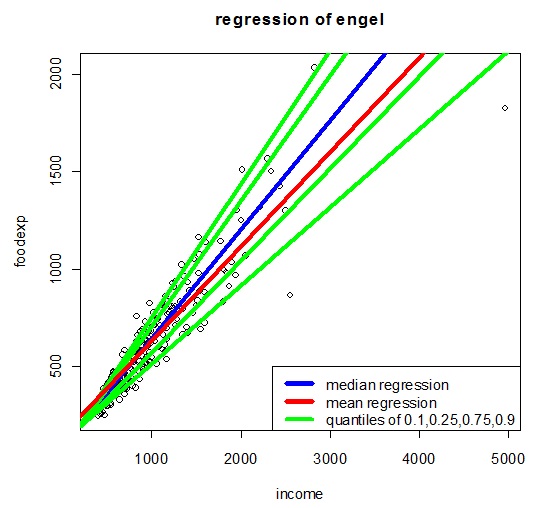
# P279:分位数回归dd=read.table("d-ibm-rq.txt",header=T)head(dd)dd[,3]=dd[,3]/100library(quantreg)mm=rq(nibm~vol+vix,tau=0.95,data=dd) # q=0.95summary(mm)names(mm)fit=mm$fitted.valuestdx=c(2:2515)/252+2001plot(tdx,dd$nibm,type='l',xlab='year',ylab='neg-log-rtn') # 图7-7lines(tdx,fit,col='red')mm=rq(xt~vol+vix,tau=0.99,data=dd) # q=0.99,与P280结果不同summary(mm)

3. 极值理论
3.1 基本概念
极值理论(Extreme Value Theory, EVT)讨论 时服从独立同分布的随机变量的极大值 的统计性质。
根据 Fisher–Tippett–Gnedenko 定理,当 时,如果存在均值和标准差数列 和 ,使正规化的极大值随机变量 有渐进分布:
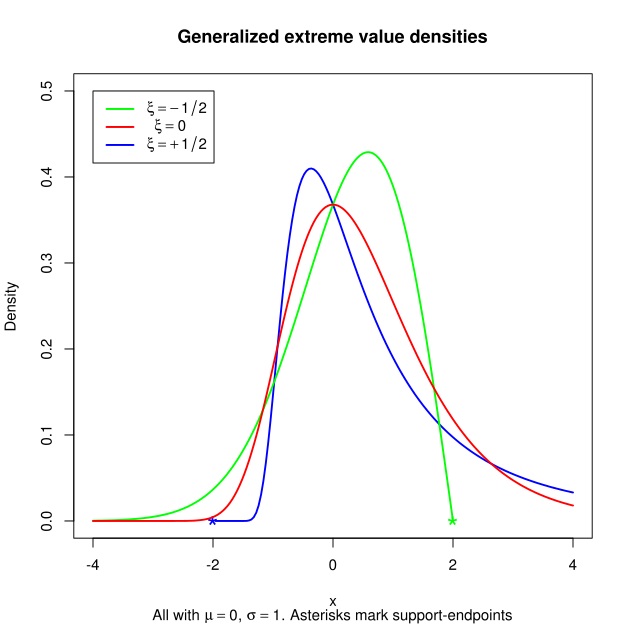
则称 服从广义极值分布(Generalized Extreme Value, GEV),相应的累积分布函数为:
其中 为位置参数(location parameter); 为尺度参数 (scale parameter); 为形状参数(shape parameter),控制极限分布的尾部行为,称 为尾部指数(tail index)。相应的概率密度函数为:
按照形状参数的取值范围,GEV又可分为三种类型:
1. 类型I:Gumbel 族,
2. 类型II:Frechet 族,
3. 类型III:Weibull 族,
3.2 估计
极值分布的三个重要参数:形状参数 (shape),位置参数 (location) 和尺度参数 (scale)。
- 分块经验估计
将样本至少分为三块(,每块平均有 个样本,),分别估计三个参数。evir包中的gev命令就用这一方法。 - 最大似然法
根据密度函数构造似然函数,进而估计参数。这一估计是无偏、渐近正态的,并在适当假设下是渐近有效的。 - 非参估计
Hill(1975)和Pickands(1975)提出以下估计量(Q为正整数):
Hill 估计仅对Frechet族适用,但当它适用时,比Pickands估计更有效。
# P285表7-1第一列source("Hill.R") # compile R scriptHill(ibm,110); Hill(xt,110)# P286表7-2,子区间长度为21个交易日library(evir)gev(ibm,block=21)$par.estsgev(xt,block=21)$par.ests# P287图7-11par(mfcol=c(1,2))m1=gev(xt,block=21)plot(m1)
3.3 应用
- 计算风险值
- 单期:
- 多期,持有 期和持有 1 期的风险值遵循 根法则。
- 单期:
- 计算收益率水平 (return level)
假定有 个长度为 的子区间,其中有1个子区间的最大值超过 ,即:
- 计算超出门限的峰值(Peaks Over Threshold, POT)
设定 为损失率的门限,POT方法关注第 次发生超过门限的巨大损失的时间 和程度 。根据POT理论,超额损失 的极限累积分布为广义帕累托分布(Generalized Pareto Distribution, GPD),在估计GPD函数参数的基础上,也可以计算 VaR 和 ES。
# P291:收益率水平m1=gev(xt,block=21) # n=21rl.21.12=rlevel.gev(m1,k.block=12) # g=12rl.21.12 # L=5.43% in (4.65%,6.76%)# P293:图7-12par(mfcol=c(2,1))qplot(xt,threshold=0.01,pch='*',cex=0.8,main="Loss variable of daily IBM log returns")meplot(ibm)title(main="Daily IBM log returns")# P294:表7-3m1=pot(xt,threshold=0.01) # pot命令m1$par.estsm2=pot(xt,threshold=0.012)m2$par.estsm3=pot(xt,threshold=0.008)m3$par.estsriskmeasures(m1,0.95) # VaR和ESriskmeasures(m2,0.95)riskmeasures(m3,0.95)# P296m1gpd=gpd(xt,threshold=0.01) # gpd命令m1gpdnames(m1gpd)par(mfcol=c(2,2))plot(m1gpd) # 图7-13riskmeasures(m1gpd,0.95) # VaR和ES
- 平稳损失过程
考虑到严格平稳时间序列 可能存在的时间相关性,需要对基于极值理论的VaR计算公式进行调整,其中 为极值指数:
m1=exindex(xt,10) # 图7-10m1[which(m1[,2]==21),] # 子区间为21天,theta=0.7251.966-(1.029/.251)*(1-(-21*.72*log(.99))^(-.251)) # VaR
