@sambodhi
2018-08-16T02:53:00.000000Z
字数 6312
阅读 3114
借助摄像头和TensorFlow.js,让Alexa能够响应手语

作者 | Abhishek Singh
译者 | Sambodhi
编辑 | Debra
AI前线导读: 以Amazon Echo为代表的智能音箱开辟了人工智能的新领域,但是这些以语音交互的设备,对那些失聪者和失语者该怎么办呢?AI难道不应该是温暖的吗?很幸运的是,不止小编这样想,国外也有大佬如此想。这不,就有一个大佬实现了如何借助摄像头和TensorFlow.js让失聪者和失语者如何与Alexa进行交互,还提供了完整的项目代码。值得国内厂商借鉴!正如我们的AI前线迷你书(2018年1月)的卷首语说的那样,“AI就应该是温暖的。”
几个月前,有一天晚上,我躺在床上,突然有一个念头闪过我的脑海:如果说语音是人机交互界面的未来,那么,那些听不见的、或者无法言语的人该怎么办呢?我也不知道为什么会想到这个问题,因为我自己能听能说,身边也没有一个失聪者、失语者,而且我也没用什么语音助手。可能是因为最近有关语音助理的文章满天飞,或者大公司之间的竞争让你得以能够用语音激活家庭助理,也可能是因为我在越来越多的朋友家里看到这种设备。自那念头闪过之后,我就念念不忘,我知道,命中注定这个问题是需要我去解决了。
最后,这个项目诞生了,它证明了我那个想法确实是可行的:Amazon Echo能响应手语,美国手语(American Sign Language,ASL)更精确,因为它类似于口语,还有多种手语。
虽然我本来可以选择简单发布代码了事,但是我最终还是选择了发布演示系统的视频,因为我觉得,现在很多机器学习都缺乏可视元素,使人们很难理解。而且我还希望,我选择的发布方式,能够帮助公众将焦点从项目的技术元素转移到人文元素:我们不是讨论底层技术,而是讨论这些技术能够为人类带来什么样的能力。
现在,演示系统的视频已经发布了,我将在本文着重介绍底层技术,以及如何使用TensorFlow.js来构建这样的系统。你可以访问https://shekit.github.io/alexa-sign-language-translator/来体验一下Demo。我把它放在一起,这样你就可以用你自己的单词和手势组合来训练它。至于是不是要有能够响应你手势的Echo,这并不是必需的。
早期的研究
这个实验要如何整合成一个完整的系统,我深思熟虑,了若指掌。我知道我需要以下这些:
- 用于解释手语的神经网络(即将手语的视频转换为文本);
- 文本到语音系统,用于对Alexa说出解释的手语;
- 语音到文本系统,用于为用户转录Alexa的响应。
- 运行该系统的设备(笔记本/平板电脑)和与之交互的Echo;
- 将所有这些联系在一起的界面。
我在很早的时候,花了很多时间来决定哪一种神经网络架构最适合做这个系统。我提出了几个选择:
1)由于手语既有视觉方面的,也有时间方面的,因此我的想法是将CNN和RNN结合起来,其中最后一个卷积层(分类之前)的输出作为序列馈送到RNN中。后来我发现的技术术语叫“长期递归卷积网络”(Long-Term Recurrent Convolutional Networks,LRCN)。
2)使用3维卷积网络,其中卷积应用于3维,前两个维度为图像,第三个维度为时间。然而,这些网络都需要大量的内存,我希望在我那台服役7年的MacBook Pro上尽可能进行训练。
3)不是从视频流中训练单个帧上的CNN,而是仅在光流表示上训练CNN,这表示两个连续帧之间的表观运动的模式。我的想法是,它会对动作进行编码,会得到更为通用的手语模型。
4)使用双流CNN,其中空间流是单一帧(RGB),而时间流则使用光流表示。
在进一步的研究中,我还发现了一些论文,其中有些论文至少使用了上述一些视频活动识别的方法(最常用于UFC101数据集)。然而,这不仅仅是我的计算能力有限,而且我从头开始研读和实现这些论文的能力也有限。经过几个月断断续续的研究,我定期放弃项目去做其他项目,对此我并不抱很大希望。
我最终确定的方法完全不同。
输入TensorFlow.js:
TensorFlow.js团队一直在进行基于浏览器有趣的小实验,以使人们熟悉机器学习的概念,并鼓励他们将其作为构建自己项目的模块。TensorFlow.js是一个开源库,允许你使用JavaScript直接在浏览器中定义、训练和运行机器学习模型。我要特别介绍一下,网上有两个很有趣的演示,可作为起点:Pacman Webcam Controller和Teachable Machine。
- Pacman Webcam Controller:http://u6.gg/enxTv
- Teachable Machine:http://u6.gg/enxVm
虽然这两个演示都是从摄像头中获取输入图像并根据训练数据输出预测,但它们内部的操作方式并不相同:
1)Pacman Webcam:它使用卷积神经网络(Convolutional Neural Network,CNN)来获取输入图像(来自摄像头),并将其传递给一系列卷积和最大池化层。利用这一点,它可以提取图像的主要特征,并根据已训练过的样本来预测其标签。由于训练是一个费时费力的过程,因此它使用一个名为MobileNet的预训练模型进行迁移学习。该模型在1000个ImageNet类上进行训练,但经过优化后,可以在浏览器和移动应用中运行。
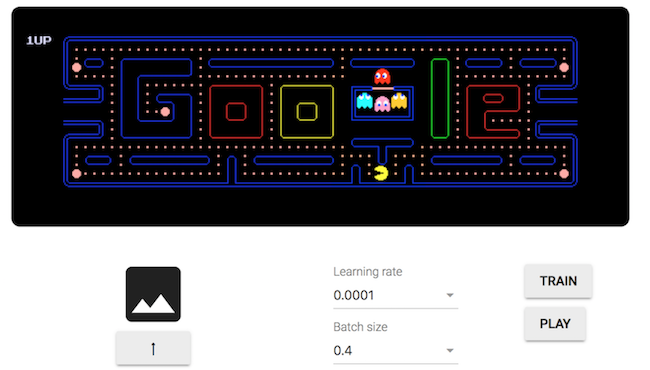
AI前线注:Pacman是一款由南梦宫公司制作的街机游戏。游戏最初于1980年5月22日在日本发行。本游戏由南梦宫公司的岩谷彻设计。游戏于1980年10月由Midway Games公司在美国发行。缺了一角的薄饼是岩谷彻创作此游戏的灵感来源。Pacman在80年代风靡全球,被认为是最经典的街机游戏之一,游戏的主角小精灵的形象甚至被作为一种大众文化符号,或是电子游戏产业的代表形象。它的开发商Namco也把这个形象作为其吉祥物和公司的标志,一直沿用至今。
2)Teachable Machine:它使用k最近邻算法(k-Nearest-Neighbours,kNN),这种算法非常简单,从技术上来说,它根本就没有执行任何“学习”。它是获取一个输入图像(来自摄像头),并通过使用相似度函数或距离度量找到最接近该输入图像的训练样本的标签来对其进行分类。然而,在馈入kNN之前,图像要先通过称为“SqueezeNet”的小型神经网络。然后将该网络倒数第二层的输出馈入kNN,这样你就可以训练自己的类。这样做的好处是,我们可以使用SqueenzeNet已经学会的高级抽象,从而训练出更好的分类器。
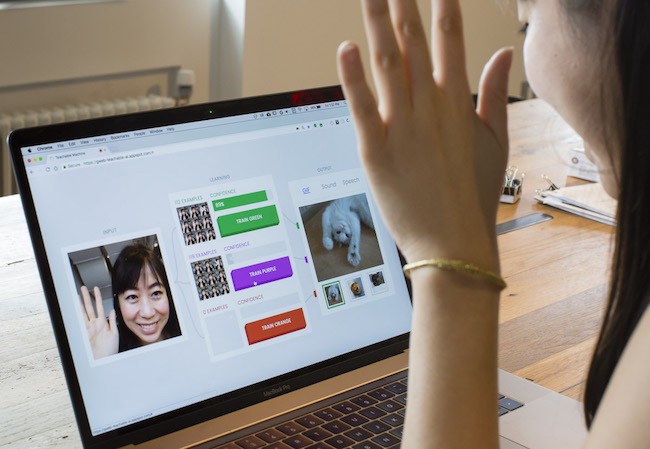
现在你可能想知道,这些手语的时间性质是什么。这两个系统在每一帧上都有一个输入图像,并对之前的帧进行零考虑的预测。这难道不是早期研究RNN的全部观点吗?难道不是真正理解一个手势的必要条件吗?嗯,在从在线资源为这个项目学习美国手语的过程中,我发现在做手势的时候,手势的开始和结束以及手的位置,在不同的手势语之间差异非常大。虽然在这两者之间发生的一切可能是与另一人交流必需的,但对仅使用手势开始和结束的机器来说,应该足够了。
我最终决定使用TensorFlow.js,还有其他原因:
- 我可以使用这些演示进行原型设计,无需编写任何代码。我通过简单地在浏览器中运行原始示例开始了早期的原型设计,我打算用手势来训练它们,并观察系统的执行情况:即时输出意味着Pacman Webcam里的小精灵在屏幕上移动。
- 我可以使用TensorFlow.js直接在浏览器中运行模型。从可移植性、开发速度和与Web界面轻松交互的能力来看,价值非常大,而且模型完全在浏览器中运行,无需向服务器发送数据。
- 由于它可以在浏览器中运行,因此我可以很好地与现代浏览器支持的语音到文本和文本到语音的API进行交互,我需要用到这些。
- 它使测试、训练和调整变得快速,而这些在机器学习中通常是一个挑战。
- 由于我没有手语数据集,而训练用的样本基本就是我重复做的手势,因此使用摄像头来收集训练数据还是很方便的。
在彻底测试了这两种方法之后,我意识到这两种系统在我的测试中都表现得相当好,我决定使用Teachable Machine作为我的基础,这是因为:
- 在较小的数据集上,kNN实际上可以比CNN执行得更快、更好。当使用很多样本进行训练时,它们会占用更多的内存,导致性能下降。但是,我清楚我的数据集很小,因此这不是问题。
- 由于kNN并未真正从样本中学习,所以它们在泛化方面很差。因此,对完全由一个人构成的样本训练的模型,用在另一个人身上并不会很好地预测。这对我来说也没有什么问题,因为我会通过自己反复做手势来训练和测试模型。
- 该团队已经公开了项目的样本:https://github.com/googlecreativelab/teachable-machine-boilerplate 这对我来说是一个很好的起点。
它是如何工作的

下面是系统工作原理:
- 在浏览器中启动站点时,第一步是提供训练样本。这意味着使用摄像头捕捉自己反复执行的每一个手势。这一步相对来说比较快,因为按住特定的捕获按钮就可以连续捕获帧,直到释放这个按钮,并用适当的标签来标记所捕获的图像。我训练的系统包含了14个单词,通过各种组合,我可以为Alexa创建各种请求。
- 训练完成后就进入预测模式。它现在使用来自摄像头的输入图像,并通过分类器运行它,根据上一步提供的训练样本和标签找到其最近的邻居。
- 如果超过某个预测阈值,它会将标签附加到屏幕的左侧。
- 然后,我使用Web Speech API进行语音合成,“说”出检测到的标签。
- 如果说出的单词是“Alexa”,那么附近的Echo就会被唤醒,并开始收听、查询。另外值得注意的是,我创建了一个任意的手势(右拳举在空中)来表示单词Alexa,因为在美国手语中没有Alexa这个单词,而且,翻来覆去用手势拼写A-L-E-X-A会很烦人。
- 当整个手语短语完成之后,我再次使用Web Speech API来转录Echo的响应,该响应对查询进行响应,完全不知道这个响应实际上是来自另一台机器。转录的响应显示在屏幕的右侧,供用户阅读。
- 再次做出唤醒词的手势,清除屏幕并重新开始重复查询的过程。
我已经将所有代码和在线演示都上传到GitHub了:
- 代码:https://github.com/shekit/alexa-sign-language-translator
- 在线演示:https://shekit.github.io/alexa-sign-language-translator/
你可以随意使用和修改。
虽然该系统运行得相对较好,但它确实需要一些技巧来帮助获得理想的结果并提高准确性,例如:
- 确保没有检测到任何手势,除非已经说出唤醒词Alexa。
- 添加一个完整的、包含所有类别的训练样本,我将其归类为“其他”的空间状态(如空白背景、垂着两只手无所事事地站着等等)。这么做是为了防止错误地检测到单词。
- 在接受输出之前,设置一个高阈值以减少预测错误。
- 降低预测率。而不是以最大帧速率进行预测,控制每秒预测的数量有助于减少错误的预测。
- 确保已经在该短语中检测到的单词不在被考虑用于预测。
- 由于手语通常会忽略署名文章,而是依赖于上下文来传达相同的内容,因此我使用某些单词来训练模型,其中包括适当的文章或介词,如天气、列表等等。
另一个挑战就是,如何准确预测用户何时完成对查询的手势。这对与准确的转录是必要的。如果转录被提前触发(在用户完成手势之前),系统就会开始转录自己的语音。另一方面,如果转录触发晚了,可能会导致它错过Alexa响应的转录部分。为了克服这个问题,我实施了两种独立的技术,每种技术都有各自的优缺点:
- 第一种选项是在将某些单词添加到训练时,将它们标记为终端词。我所说的终端词是指用户只会在短语结尾做手势的词。例如,如果查询内容是“Alexa, what's the weather?”,那么,通过将“the weather”作为终端词,当检测到这个词时,就可以正确地触发转录。虽然这很有效,但这意味着用户必须记住在训练期间将单词标记为终端词,并且还依赖于这个词只出现在查询末尾的假设。这意味着你要重新调整你的查询,而不是问“Alexa,what's the weather in New York?”这将是个问题。演示使用的是这种方法。
- 第二种选项是让用户用手势做出一个停用词,以便让系统知道他们已经完成查询。一旦识别出这个停用词时,系统就会触发转录。因此用户将会用手势做出唤醒词→查询→停用词。不过这种选项存在这样的风险:用户忘记用手势做出停用词,导致转录根本没有被触发。我已在一个单独的gitub分支(https://github.com/shekit/alexa-sign-language-translator/tree/stopword)实现了这种方法,你可以用唤醒词Alexa作为查询的书签,即“Alexa, what’s the weather in New York (Alexa)?”
当然,如果有一种方法可以区分来自内部(笔记本电脑)的语音和来自外部(附近的Echo)的语音,那么整个问题就可以解决,但这完全就是另外一个挑战。

接下来,我认为还有很多其他的方法可以处理这个问题,对于为自己的项目创建更为健壮、更为通用的模型来说,这些都是很好的起点:
- TensorFlow.js还发布了PoseNet(参阅http://u6.gg/eny5R),使用这个或许是一种有趣的方法。从机器的角度来看,跟踪手腕、肘部和肩部在帧中的位置,应该足以预测大多数单词。在书写时,手指的位置很重要。
- 使用基于CNN的方法(如Pacman示例)可以提高准确性,并使模型更能抵抗平移不变性。它还有助于更好地概括不同的人。还可以包括保存模型或加载预训练Keras模型的能力,这些都有详细的文档记录。这将消除每次重新启动浏览器时训练系统的需要。
- 考虑时间特征的CNN+RNN或PoseNet+RNN的某种组合,可能会提高准确率。
- 使用TensorFlow.js中包含的较新的可重用kNN分类器(https://github.com/tensorflow/tfjs-models/tree/master/knn-classifier)。
自我第一次发布这个项目以来,它在社交媒体上被广泛分享,被媒体广泛报道,甚至连Amazon在Echo Show上为那些言语障碍人士实现了这个辅助功能(Tap to Alexa)。虽然没有证据表明我这个项目是不是促使Amazon实现了这个功能(但时间上看非常巧合),但如果确实如此,那真是太酷了!我希望将来Amazon Show或者其他基于摄像头和屏幕的语音助手,也集成这种功能。对我来说,这可能就是这个原型所展示的最终用例,并且能够向数百万新用户开放这些设备的能力。
降低网络的复杂性,并构建一个简单的架构来创建我的原型,这无疑有助于快速完成这个项目。我的目标不是解决整个手语到文本的问题。相反,它是为了发起一场围绕包容性设计的对话,以平易近人的方式展示机器学习,并激励人们探索这个问题领域——我希望这个项目能够实现。
原文链接: Getting Alexa to Respond to Sign Language Using Your Webcam and TensorFlow.js
https://medium.com/tensorflow/getting-alexa-to-respond-to-sign-language-using-your-webcam-and-tensorflow-js-735ccc1e6d3f
