@sambodhi
2018-06-14T03:47:29.000000Z
字数 3102
阅读 2811

人工智能助力Faccebook实现产品规模化
作者|John Morris
译者|Liu Zhiyong
编辑|Chen Si
AI前线导读:还在把Facebook看作纯粹的社交媒体公司吗?不,这家公司一直不懈地追求人工智能,今天的Facebook,悄然成为世界上最先进的人工智能技术研究中心之一了。很奇怪吗?一点也不。因为Facebook是世界上最大的社交媒体,如果把Facebook视作一个国家的话,就是世界上人口第八多的国家,略多于日本、俄罗斯和尼日利亚。如此庞大的体量,如果没有人工智能的助力,它的运营压力简直不可想象。在全球的人工智能领域中,Facebook其实就是后起之秀,但它已经迅速在其产品中融入了人工智能技术。现在,让我们阅读John Morris的文章,人工智能是如何助力Facebook实现产品规模化的?
Facebook的产品和服务是由机器学习驱动的。强大的GPU已成为关键推动因素之一,但它需要更多的硬件和软件来为数十亿用户提供服务。
在Facebook的20亿用户中,大多数人都不知道这项服务在多大程度上依赖人工智能来实现如此大规模的运营。Facebook的产品,如新闻源、搜索和广告都使用机器学习,而在幕后,它为诸如面部识别和标签、语言翻译、语音识别、内容理解和异常检测等服务提供支持,以发现虚假账户和令人反感的内容。
数字是惊人的。总的来说,Facebook的机器学习系统每天要处理超过200万亿次的预测和50亿次的翻译。Facebook的算法每天都会自动删除数百万个虚假账户。
在今年的计算机架构国际研讨会(International Symposium on Computer Architecture,ISCA)上,Facebook人工智能基础架构部门负责人Kim Hazelwood博士在一个主题演讲中解释了他们的服务是如何设计硬件和软件来处理如此规模的机器学习的。她还敦促硬件和软件架构师们不要光顾炒作,要为机器学习开发“全栈解决方案”。Hazelwood表示:“重要的是,我们正在解决正确的问题,而不只是做其他人正在做的事情。”
Facebook的人工智能基础架构需要处理各种各样的工作负载。有些模型可能需要几分钟的训练,而有些模型可能需要几天甚至几周的训练。例如,新闻源和广告使用的计算资源比其他算法多100倍。因此,只要有可能,Facebook就会使用“传统的老式机器学习”,而且只有在绝对必要的时候才会采用深度学习——多层感知器(MLP)、卷积神经网络(CNN)和递归神经网络(RNN/LSTM)。
该公司的人工智能生态系统包括三个主要组成部分:基础架构、运行在顶层的工作流管理软件,以及PyTorch等核心机器学习框架。
自2010年以来,Facebook一直在设计自己的数据中心和服务器。如今,它运营着13个大型数据中心,其中10个在美国,3个在海外。并非所有这些数据中心都是相同的,因为它们是随着时间而建立起来的,并且它们不存储相同的数据,因为“最糟糕的事情是在每个数据中心中复制所有数据。”Hazelwood说,尽管如此,公司每个季度都要“拔掉整个Facebook数据中心的插头”,以确保数据的连续性。数据中心的设计是为了用于处理峰值负载,这使得大约50%的机群在一天中的某些时间处于空闲状态,作为“自由计算”,可以用于机器学习。
Facebook不使用单个服务器,而是在生产环境中,将数百个工作负载放入buckets中,并为每种类型设计定制服务器。数据存储在Bryce Canyon和Lighting存储服务器上,训练则在Big Basin服务器上,使用的是Nvidia Tesla GPU,这些模型在Twin Lakes单至强服务器和Tioga Pass双至强服务器上运行。Facebook继续对Google的TPU和微软的BrainWave FPGA等专用硬件进行评估,但Hazelwood认为,太多的投资集中在计算上,而对存储尤其是网络的投入不够,这与Amdahl定律相一致,可能会成为许多工作负载的瓶颈。她补充说,人工智能芯片初创公司没有把足够的精力放在软件上,这给机器学习工具和编译器留下了巨大的机遇。
AI前线注:Amdahl定律,是计算机系统设计的重要定量原理之一,于1967年由IBM360系列机的主要设计者Amdahl首先提出。该定律是指:系统中对某一部件采用更快执行方式所能获得的系统性能改进程度,取决于这种执行方式被使用的频率,或所占总执行时间的比例。Amdahl定律实际上定义了采取增强(加速)某部分功能处理的措施后可获得的性能改进或执行时间的加速比。简单来说是通过更快的处理器来获得加速是由慢的系统组件所限制。
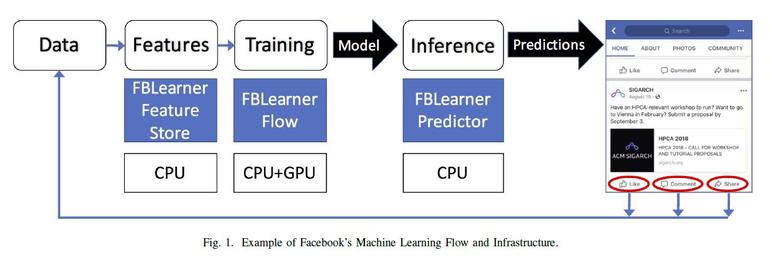
Facebook自己的软件栈包括FBLearn,这是一套针对机器学习管道不同部分的三种管理和部署工具。FBLearner Store用于数据处理和特征提取,FBLearning Flow用于管理训练中涉及的步骤,FBLearner Prediction用于在生产中部署模型。我们的目标是解放Facebook的工程师,让他们更有效率,专注于算法设计。
Facebook以前使用过两种机器学习框架:用于研究的PyTorch和用于生产的Caffe。基于Python的PyTorch更容易使用,但Caffe2的性能更好。问题是,将模型从PyTorch移植到用于生产的Caffe2是一个耗时且麻烦的过程。Hazelwood说,上个月,在F8开发者大会上,Facebook宣布,现在使用PyTorch 1.0,由于“在内部合并了它们”,这样你就能享受到PyTorch的外观,Caffe2的性能。
这对于ONNX(Open Neural Network Exchange)来说是合乎逻辑的第一步,这是由Facebook、Microsoft共同努力开发的一种开放格式,用于优化构建在不同框架中的深度学习模型,并在各种硬件上运行。我们面临的挑战是,目前市面上已经有很多框架了:Google TensorFlow、Microsoft Cognitive Toolkit、Apache MXNet(深受Amazon青睐)……这些模型需要在各种不同的平台上运行,如Apple ML、Nvidia、Intel/Nervana和Qualcomm的Snapdragon Neural Engine等。
在边缘设备上运行模型有很多很好的理由,但手机尤其具有挑战性。世界上许多地区仍然几乎没有移动网络,全球超过一半的地区使用的是2012年或更早的手机,他们使用各种硬件和软件。Hazelwood说,目前的旗舰手机和中档手机的性能差异约为10倍。她说:“你不能假设你为之设计移动神经网络的每个人都在使用iPhone X。”“在美国,这种情况非常反常。”Facebook的Caffe2 Go框架旨在压缩模型以解决其中的一些问题。
深度学习时代已经到来,Hazelwood说,有很多硬件和软件问题亟须解决。行业花费大量的时间和金钱建设更快的硅片,但她说,我们需要在应用Proebsting定律的软件上进行平等的投资,编译器的计算性能每18年只能翻一番,“请记住这一点,以便我们不会再遇到安腾的另一种情况,”Hazelwood开玩笑地说,安腾是Intel未失效的IA-64架构。Hazelwood说,真正的机遇是解决人们尚未致力构建具有平衡硬件和更好的软件、工具和编译器的端到端解决方案的问题。
原文链接: How Facebook scales AI
https://www.zdnet.com/article/how-facebook-scales-ai/
