@sambodhi
2018-07-16T07:08:03.000000Z
字数 7547
阅读 4114
浅谈训练神经网络的最快方法
更高、更快、更强 AI前线

作者|Sylvain Gugger/Jeremy Howard
译者|5aM60dh1
编辑|Natalie
AI前线导读:神经网络模型的每一类学习过程通常被归纳为一种训练算法。训练的算法有很多,它们的特点和性能也各不相同。为了高效训练深度神经网络,人们提出了一些实践方法,但学术界追求“更高、更快、更强”,于是,在研究人员的共同努力下,AdamW和超收敛已经成为目前训练神经网络的最快方法。前几天Sylvain Gugger和Jeremy Howard一起撰写了一篇文章,详细阐述了训练神经网络的最快方法,希望对从业者有所启示。
跌宕起伏的Adam
纵观Adam优化器的发展历程,就像过山车一样。它于2014年在论文 Adam: A Method for Stochastic Optimization (https://arxiv.org/abs/1412.6980)中首次提出,其核心是一个简单而直观的想法:既然我们明确地知道某些参数需要移动得更快、更远,那为什么每个参数还要遵循相同的学习率呢?因为最近梯度的平方告诉我们每增加一个权重可以得到多少个信号,所以我们可以除以它来确保即使是最缓慢的权重也能获得“发光”的机会。Adam接受了这个想法,在过程中增加了标准方法,Adam优化器就这样诞生了。它需要稍微调整来避免早期批出现偏差。
当论文首次发布时,原论文中的一些图表(如下图所示)让深度学习社区感到兴奋不已:
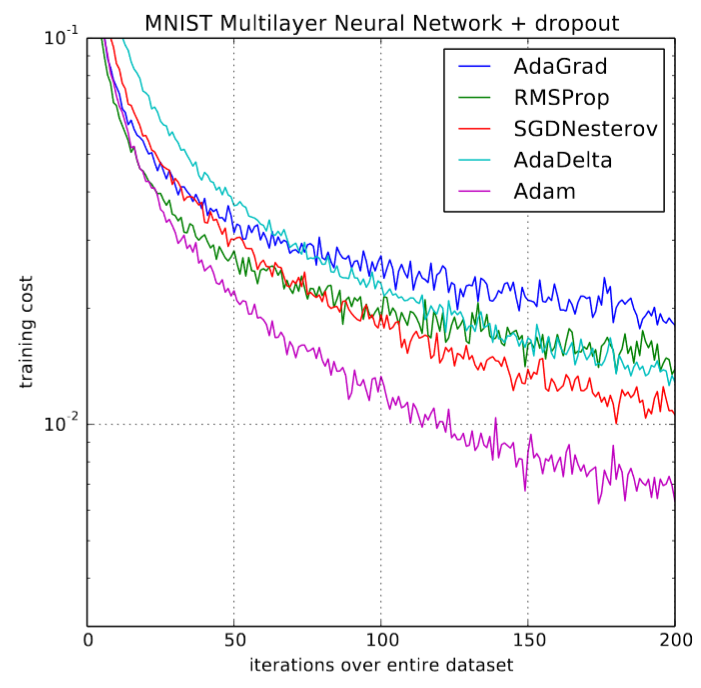
Adam和其他优化器的对比
训练速度加快了200%!“总体来看,我们发现Adam非常强大,非常适用于时下机器学习领域中的各种非凸优化问题。”论文如此总结道。那是三年前深度学习最辉煌的时候。但事情后来并没有像我们所期望的那样发展,很少见到有研究文章使用Adam来训练模型,新的研究也开始明显地不鼓励使用Adam(如论文 The Marginal Value of Adaptive Gradient Methods in Machine Learning,https://arxiv.org/abs/1705.08292),并通过几个实验结果表明,普通的SGD+Momentum可能比复杂的Adam表现更好。在2018年fast.ai的课程中,可怜的Adam就被从早期课程中剔除了。
但在2017年底,Adam似乎获得了重生。Ilya Loshchilov和Frank Hutter在他们的论文 Fixing Weight Decay Regularization in Adam (https://arxiv.org/abs/1711.05101)中指出,在每个库中在Adam上实施的权重衰减似乎都是错误的,并提出了一种简单的方法(他们称之为AdamW)来修复这个问题。虽然他们的结果略有不同,但是他们确实给出了一些令人鼓舞的图表,如下图所示:

Adam和AdamW对比
我们期待人们能够对Adam重燃热情,因为它的一些早期结果似乎已经可以重现。但事实并非如此。应用它的唯一一个深度学习框架是fastai,使用的是Sylvain编写的代码。但因为缺乏可用的通用框架,日常实践者就被又旧又难用的Adam所困。
但这并不是唯一问题,前方还有更多的障碍。有两篇论文分别指出了Adam在收敛性证明方面存在明显的问题。尽管其中一篇论文提出了解决方案(并在久负盛名的ICLR大会上获得了“最佳论文”奖),他们称之为AMSGrad。但是,如果要说我们从这段充满戏剧化的生活(至少按照优化器的标准而言是戏剧化的)中学到了什么,那就是,没有什么是表面看到的那样。事实上,博士生Jeremy Bernstein在博文 On the Convergence of Adam and Beyond (https://openreview.net/forum?id=ryQu7f-RZ¬eId=B1PDZUChG) 中指出,所谓的收敛问题实际上只是超参数选择不当,也许AMSGrad并不能解决问题。另一名博士生Filip Korzeniowski在论文 Experiments with AMSGrad(https://fdlm.github.io/post/amsgrad/) 中展示了一些早期研究成果,似乎也证明了这个令人沮丧的观点。
Adam到底怎么样?
对于那些只想快速训练精确模型的人,我们该做些什么呢?让我们用数百年来解决科学辩论的方式来解决这一争议:做实验!我们将在本文稍后阐述所有的细节,但先让我们看一下大致结果:
- 适当调参之后,Adam真的是能用的!我们在各种任务上获得了训练时间方面的最新结果如下:
- 在含有测试时间增加的18个epoch或30个epoch训练CIFAR10,使其准确率超过94%,如DAWNBech竞赛;
- 只需60个epoch即可对Resnet50进行调参,使其在斯坦福汽车数据集的准确率达到90%,据报告称,之前要达到相同的准确率需600个epoch;
- 从零开始训练AWD LSTM或QRNN(见论文 Regularizing and Optimizing LSTM Language Models(https://arxiv.org/abs/1708.02182)),需90个epoch(或在单个GPU上训练一个半小时),其困惑度在Wikitext-2达到当前最优水平,据之前报告称,LSTM需要750个epoch,QRNN需要500个epoch。
- 这意味着我们已经看到了使用Adam的超收敛!(参见论文Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates(https://arxiv.org/abs/1708.07120))超收敛是训练学习率高的神经网络时出现的一种现象,表示节约了一半的训练时间。在人们了解AdamW之前,人们训练CIFAR10使其准确率达到94%需要大约100个epoch。
- 与之前的工作相比,我们发现只要调整得当,Adam在尝试过的每一个CNN图像问题上都能获得与SGD+Momentum一样的准确率,而且,几乎总是快一点。
- 至于有人认为AMSGrad是一个槽糕的“解决方案”,这种看法是正确的。我们一直发现,AMSGrad的准确率(或其他相关指标)并没有获得比普通的Adam/AdamW更高的增益。
如果你听到人们说Adam的泛化性能不如SGD+Momentum时,你基本就会发现他们为自己的模型选择的超参数其实蛮糟糕的。通常情况下,Adam需要比SGD更多的正则化,因此,当从SGD转向到Adam时,一定要确保调整正则化超参数。
AdamW
理解AdamW:权重衰减与L2正则化
L2正则化是减少过拟合的经典方法,它向损失函数添加模型的所有权重的平方和组成的惩罚项,乘以特定的超参数来控制惩罚力度(在本文中,所有的方程式均使用Python、NumPy和PyTorch表示法):
final_loss = loss + wd * all_weights.pow(2).sum() / 2
其中,wd是我们设置的超参数,也可称为权重衰减,因为运用vanilla SGD时,它相当于使用如下方程式更新权重:
w = w - lr * w.grad - lr * wd * w
其中,lr表示学习率,w²表示损失函数对w的导数,wd*w表示惩罚项对w的求导结果。在这个方程式中,我们可以看到每一次更新都会减去一小部分权重,因此这就是命名为“衰减”的原因。
我们注意到所有的库都使用了第一种形式。在实践中,几乎总是通过向梯度增加wd*d来实现算法,而不是真正改变损失函数。因为我们不希望还有其他更简单的方法的情况下,增加额外的计算量来修正损失。
如果这两个概念是一样的话,那为什么还要区分这两种概念呢?答案就是,它们对于vanilla SGD来说是等价的,一旦我们添加动量,或者使用像Adam那样复杂的最优化器,那么L2正则化(第一个方程式)和权重衰减(第二个方程式)就会变得不同。在本文其余部分中,我们讨论的权重衰减都是指第二个方程式(权重将会衰减一点),而我们讨论经典方法时就会讨论L2正则化。
让我们来看看带动量的SGD。使用L2正则化会在梯度上添加wd*d(正如我们前面所述),但梯度并不是直接从权重中减去。首先我们要计算一个移动均值:
moving_avg = alpha * moving_avg + (1-alpha) * (w.grad + wd*w)
这个移动均值乘以学习率,再减去w得到权重的更新,因此w与正则化相关的部分是lr*(1-alpha)*wd*d加上已经在moving_avg中前面权重的结合。
因此,权重衰减的更新方式可以如下表示:
moving_avg = alpha * moving_avg + (1-alpha) * w.gradw = w - lr * moving_avg - lr * wd * w
我们可以看到,从w连接到正则化的部分在两种方法是不一样的。在使用Adam优化器时,权重衰减的部分可能相差很大:在L2正则化的情况下,我们将这个wd*d添加到梯度中,然后分别计算梯度机器平方的移动均值,然后再更新权重。然而权重衰减方法只是简单地更新权重,然后每次从权重中减去一点。
显然这是两种不同的方法。在进行实验之后,Ilya Loshchilov和Frank Hutter在论文中建议我们应该使用Adam的权重衰减方法,而不是像经典深度学习库中实现的L2正则化方法。
实现AdamW
那我们要怎么做才能实现AdamW呢?如果你在使用fastai库,那么在使用fit函数时只需添加参数use_wd_sched=True就能简单地实现了:
learn.fit(lr, 1, wds=1e-4, use_wd_sched=True)
如果你更青睐新的训练API,那你可以在每个训练阶段中使用参数wd_loss=False(用于在衰减过程中没有计算的权重衰减):
phases = [TrainingPhase(1, optim.Adam, lr, wds=1-e4, wd_loss=False)]learn.fit_opt_sched(phases)
以下是我们在fastai中如何实现AdamW的简要总结。在优化器中的阶跃函数(step function)中,只需使用梯度修正参数,根本不使用参数本身的值(除了权重衰减,我们将在外部处理)。我们可以在最优化器步骤之前通过简单的实现权重衰减,但这仍然需要在计算梯度之后才能完成,否则会影响梯度值。因此在训练循环中,我们必须确定计算权重衰减的位置。
loss.backward()#Do the weight decay here!optimizer.step()
当然,最优化器应该设定为wd=0,否则它还会做一些L2正则化,这也是我们不希望看到的。现在在权重衰减的位置中,我们可以在所有参数上进行循环,并依次采用权重衰减的更新。我们的参数应该存储在优化器的字典param_groups中,因此这个循环应该如下段代码所示那样的:
loss.backward()for group in optimizer.param_groups():for param in group['params']:param.data = param.data.add(-wd * group['lr'], param.data)optimizer.step()
AdamW实验结果:是否有效?
我们先在计算机视觉问题上进行了测试,结果令人鼓舞。具体来说,我们使用Adam和L2正则化在30个epoch(这是SGD在1cycle策略(详见https://sgugger.github.io/the-1cycle-policy.html)中达到94%准确率的必要时间)获得的准确率平均为93.36%,在两次中有一次超过了94%。当使用Adam和权重衰减方法时,我们始终得到的是94%~94.25%的准确率。为此,我们发现使用1cycle策略时,beta2的最优值为0.99。我们将beta1参数作为SGD的动量,也就是说,随着学习率的增长,它从0.95降到0.85,然后随着学习率的降低又升到0.95。
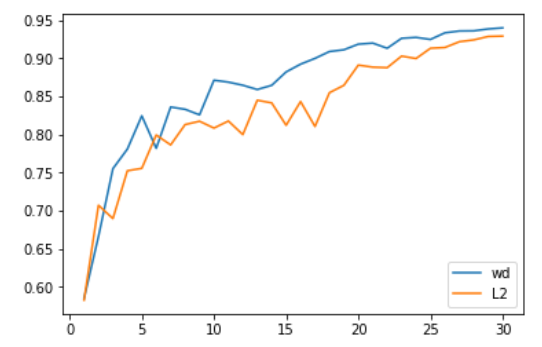
L2正则化或权重衰减准确率
更令人印象深刻的是,使用测试时间增加(即对测试集的一个图像和它的四个数据增强版本进行预测的平均值),我们可以在仅仅18个epoch内达到94%的准确率(平均93.98%)!使用简单的Adam和L2正则化的话,每尝试20个epoch就会出现一次超过94%的情况。
在这些比较中需要考虑的一件事是,改变正则化的方式会改变权重衰减或学习率的最佳值。在我们进行的测试中,L2正则化的最佳学习率为1e-6(最大学习率为1e-3),而0.3是权重衰减的最佳值(学习率为3e-3)。在我们的测试中,数量级的差异都是非常一致的,主要是因为L2正则化被梯度的平均范数(相当低)有效地划分,并且Adam的学习率相当小(所以权重衰减的更新需要更强的系数)。
那么,权重衰减是不是总比Adam的L2正则化更好呢?我们还没发现明显更糟的情况,但无论是迁移学习问题(例如斯坦福汽车数据集上的Resnet50的微调)还是RNN,它都没有给出更好的结果。
AMSGrad
理解AMSGrad
AMSGrad是由Sashank J. Reddi、Satyen Kale和Sanjiv Kumar在最近的一篇文章 On the Convergence of Adam and Beyond (https://openreview.net/forum?id=ryQu7f-RZ)中介绍的。通过分析Adam优化器的收敛性证明,他们发现了更新规则中的一个错误,该错误可能导致算法收敛到次优点。他们设计了理论实验,展示了Adam失败的情形,并提出了一个简单的解决方案。
为了更好地理解错误和解决方案,让我们看一下Adam的更新规则:
avg_grads = beta1 * avg_grads + (1-beta1) * w.gradavg_squared = beta2 * (avg_squared) + (1-beta2) * (w.grad ** 2)w = w - lr * avg_grads / sqrt(avg_squared)
我们刚刚跳过了偏差修正(这对训练的开始很有用)来关注重点。作者发现的Adam收敛性证明中的错误之处在于它需要数量。
lr / sqrt(avg_squared)
这是我们朝着平均梯度方向迈出的一步,在训练中逐渐减少。由于学习率通常是常量或递减的(除了像我们这样疯狂的人试图获得超收敛之外),作者提出的解决方案是通过添加另一个变量来跟踪它们的最大值来迫使avg_square量增加。
实现AMSGrad
相关文章在ICLR 2018中获得了一项大奖,并已经在两个主要的深度学习库——PyTorch和Keras中实现了。所以我们只要传入参数amsgrad=True就万事大吉了。
前一节中的权重更新代码更改为如下内容:
avg_grads = beta1 * avg_grads + (1-beta1) * w.gradavg_squared = beta2 * (avg_squared) + (1-beta2) * (w.grad ** 2)max_squared = max(avg_squared, max_squared)w = w - lr * avg_grads / sqrt(max_squared)
AMSGrad实验结果:大量毫无意义的噪音
AMSGrad的表现令人失望。我们发现,在所有的实验中,它一点用都没有。即使AMSGrad发现的最小值确实有时比Adam达到的最小值略低(在损失方面),其度量(准确率、f1分数等)最终总是更槽糕(请访问此网址参阅更多表格和示例:https://fdlm.github.io/post/amsgrad/)
Adam优化器在深度学习中收敛的证明(因为它是针对凸问题的)和他们在其中发现的错误对于与现实问题无关的合成实验很重要。实际的测试表明,当那些avg_squared梯度想要减少时,这样做能得到最好的结果。
这表明,即使对理论的关注对获得一些新想法很有用,也没有什么能代替实验(以及大量的实验),以确保这些想法能够帮助实践者训练更好的模型。
附录:全部结果
从零开始训练CIFAR10(模型是一个WideResnet 22,如下表所示为五个模型的测试集中平均误差结果):
| Method | Without AMSGrad | With AMSGrad |
|---|---|---|
| AdamW | 5.66% | 6.31% |
| Adam | 6.06% | 6.64% |
使用fastai库引入的标准头对斯坦福汽车数据集上的Resnet50进行微调(在解冻前对头进行20个epoch的训练,并用不同的学习率训练40个epoch):
| Method | Without AMSGrad | With AMSGrad |
|---|---|---|
| AdamW | 10.8%/9.5% | 10.1%/9.5% |
| Adam | 10.4%/9% | 10.1%/9% |
使用github repo中的超参数(https://github.com/salesforce/awd-lstm-lm)对AWD LSTM进行训练(结果显示在有无缓存指针的情况下验证/测试集的困惑度):
| Method | Raw model | With cache pointer |
|---|---|---|
| Adam | 68.7/65.5 | 52.9/50.9 |
| Adam + AMSGrad | 69.4/66.5 | 53.1/51.3 |
| AdamW | 69.3/66 | 54.1/51.9 |
| AdamW + AMSGrad | 72.7/69 | 57/54.7 |
QRNNs代替LSTMs也一样:
| Method | Raw model | With cache pointer |
|---|---|---|
| Adam | 69.6/66.7 | 53.6/51.7 |
| Adam + AMSGrad | 71.5/68.4 | 54.2/52.2 |
| AdamW | 70.5/67.3 | 55.5/53.3 |
| AdamW + AMSGrad | 74.3/70.9 | 57.8/55.6 |
对于这个特定的任务,我们使用了一个改进版本的1cycle策略,加快了学习速度,之后长时间保持较高的恒定学习速度,然后再次下降。
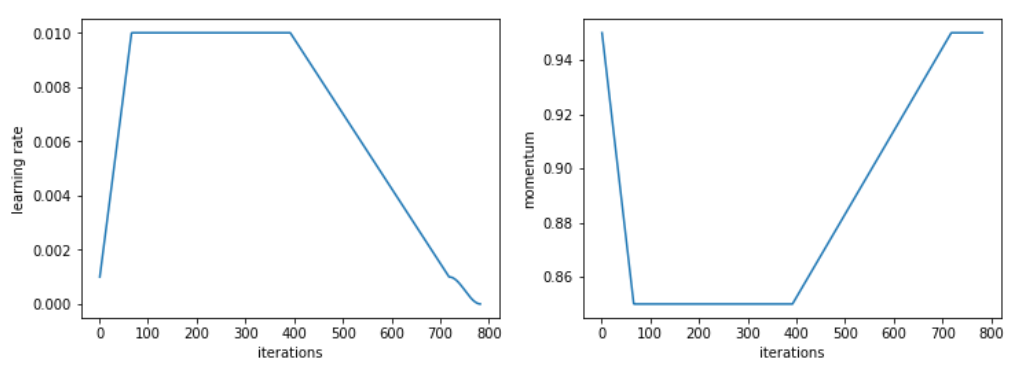
Adam和其他优化器之间的对比
所有相关超参数的值以及用于生成这些结果的代码可访问此网址来获得:https://github.com/sgugger/Adam-experiments
原文链接: AdamW and Super-convergence is now the fastest way to train neural nets
http://www.fast.ai/2018/07/02/adam-weight-decay/
