@sambodhi
2018-07-16T06:59:41.000000Z
字数 2887
阅读 3655
对于未知物体,图像分类器可以做什么?
作者|Pete Warden
译者|5aM60dH1
编辑|Natalie

AI前线导读:以前,我们看到不认识的花花草草,要查阅半天资料才能知道是什么植物,可如今,我们可以通过各种识图软件对着花草拍照扫描一下就能知道是什么花草了,比如识花君、微软识花、形色等等,都是这类app的佼佼者。这就是深度神经网络技术在图像识别的应用。淘气如小编,在试用识花君的时候,曾对着同事拍照扫描看识别出的是什么结果,无一例外得到的全是错误的结果,为什么会这样呢?PlantVillage(一款智能植物识别App)也遇到了这个问题,让我们看看JetPac联合创始人Pete Warden是怎么说的。
前几天,我收到了来自我正与之合作的PlantVillage(https://plantvillage.psu.edu/)团队提出的一个问题,他们正在开发一款手机应用,遇到了问题。这款手机应用可以检测植物疾病,当手机摄像头对准叶子的时候,运行的效果非常好;但是如果你让它对准电脑键盘的话,就不行了:它会认为检测到的是一种受损的作物。
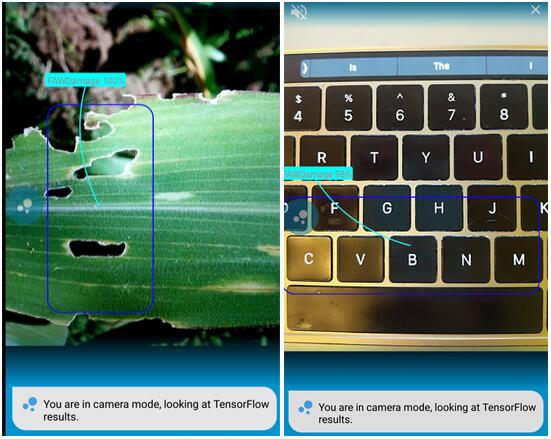
AI前线注: PlantVillage是来自美国宾夕法尼亚州立大学的一款智能植物识别App,能做的不仅仅是帮你识别你不认识的农作物,还能够帮助农户识别农作物的各种病虫害。
这样的结果对计算机视觉研究人员来说并不奇怪,但对大多数人来说,这是一个令人震惊的结果,所以我想解释为什么会发生这种情况,以及我们能做些什么。
作为人类,我们习惯于将我们所看到的事物进行分类,我们自然希望机器也能够拥有同样的能力。大多数模型的训练只用来识别一组非常有限的物体,例如原始ImageNet竞赛的1000个类别。关键是,训练过程假设模型看到的每个样本都是这些物体中的一个,而预测必须在那个数据集中。模型没有说“我不知道”的选择,也没有任何训练数据可以帮助它学习这类响应。这是一个在研究环境中有意义的简化,但是我们如果试图在现实世界中应用结果模型的话,就会出现问题。
AI前线注: ImageNet由李飞飞创建,可以说ImageNet开启了深度学习乃至人工智能新的篇章,对计算机视觉、机器学习、人工智能乃至人类进步的影响都更为巨大,ImageNet数据集让人们意识到构建优良数据集的工作是人工智能研究的核心,数据和算法一样至关重要。ImageNet竞赛目的是衡量哪些算法能够以最低的错误率识别数据集图像中的物体。李飞飞曾经说过:“ImageNet思维所带来的范式转变是,尽管很多人都在注意模型,但我们要关心数据,数据将重新定义我们对模型的看法。”
当我还在Jetpac工作时,我们就很难说服人们相信开创性的AlexNet模型是一个巨大的飞跃,因为我们每次将演示手机给他们看的时候,他们就将手机摄像头对准自己的脸,然后就会被预测成类似“氧气面罩”、“安全带”之类的东西。这是因为ImageNet竞赛的类别并没有包含任何人物标签,但大多数带有面罩和安全带标签的照片都包含了与物品一同出现的人脸。另一个尴尬的错误是,当他们将摄像头对准一个盘子时,它会预测为“马桶座圈”!之所以出现这情况,是因为在最初的类别中没有盘子,外观上最接近白色圆形物体的是厕所。
AI前线注: JetPac是一家图片分析创业公司,于2014年被Google收购。AlexNet是2012年的ImageNet竞赛的冠军,以第一作者Alex命名。其官方提供的数据模型,准确率达到57.1%,top1-5达到80.2%,对于传统的机器学习分类算法而言,已经相当出色。
我开始认为,这是“开放世界”与“封闭世界”的问题。模型经过训练和评估,假设给模型展现的世界是一个有限的物体。但是,它们一旦走出实验室,这种假设就会失败,并且用户会根据它们的表现来判断放在它们面前的任意物体,而不管是否在训练集中。
解决方案是什么?
不幸的是,我并不知道如何简单地解决这个问题。好消息是,有一些策略让我看到了希望的曙光。最明显的开始是在训练数据中添加“未知”类。坏消息是,这将带来一系列完全不同的问题,如下:
- 那个类应该包括哪些样本?潜在的自然图像几乎是无限的,所以你要如何选择包括哪些样本呢?
- 在未知类中,你需要多少种不同类型的物体?
- 对于看起来与你关心的类非常相似的位置物体,你应该如何处置?例如,添加一个不在ImageNet 1000中的犬种,但它看起来跟数据集中的犬种几乎相似,可能会强制许多正确的匹配进入“未知桶”中。
- 你的训练数据中,有多少比例应该是由未知类的样本组成?
上述最后一点实际上涉及到了一个更大的问题。从图像分类网络得到的预测值不是概率。它们假设看到的任何特定类的几率等于这个类在训练数据中出现的频率。如果你尝试使用包括亚马逊丛林的企鹅在内的动物分类器,你就会遇到这个问题,因为(可能)所有的企鹅的目击报告都是误报。即使是美国城市的犬种,在ImageNet训练数据中,稀有品种出现的频率也要高于出现在狗狗公园的品种,因此它们经常被误报。通常的解决方案是计算出在生产中遇到的情况下的先验概率是多少,然后使用它们将校准值应用于网络的输出,从而得到更接近实际概率的结果。
有助于解决实际应用中整体问题的主要策略是,将模型的使用限制在对将要出现的物体的假设与训练数据相匹配的情况下。一种简单的方法是通过产品设计来解决问题。你可以创建一个用户界面,指导人们在运行分类器之前,使设备关注你所感兴趣的物体,就像要求你拍摄支票或其他文档的应用一样。
更复杂一点的话,你可以编写一个单独的图像分类器,尝试识别主图像分类器没有为之设计的条件。这与添加一个“未知”类不同,因为它更像是一个级联,或者详细模型之前的一个过滤器。在作物发生病害的情况下,操作环境在视觉上足够清晰,因此,只需训练模型来区分叶片和随机选择的其他照片即可。由于有足够的相似之处,门控模型至少应该能够判断图像是否在不受支持的场景中拍摄。这个门控模型将在完整的图像分类器之前运行,如果它没有检测到看起来像是一个植物的东西,它将会提前显示出错误信息,表明没有发现任何作物。
要求你给信用卡拍照或者执行其他类型OCR的应用,通常会结合使用手机屏幕的方向和检测模糊度的模型,或拍照未对准时引导用户正确拍照可成功处理的照片,还有一种“是否存在叶片”的模型,是这个界面模式的简单版本。
这可能不是一组非常令人满意的答案,但是这正反映出了,当机器学习超出了一定的研究问题范围,用户所期望的结果是各不相同的。人们对物体的识别,有很多常识和外部知识,而在经典的图像分类任务中并没有这些知识。为了得到满足用户期望的结果,我们必须围绕我们的模型设计一个完整的系统,该系统能够理解将要部署到的世界,并且不仅仅是基于模型输出即可作出明智的决策。
原文链接: What Image Classifiers Can Do About Unknown Objects
https://petewarden.com/2018/07/06/what-image-classifiers-can-do-about-unknown-objects/
