@qinyun
2018-12-18T10:29:36.000000Z
字数 3414
阅读 1922
标题
未分类
在这篇文章中,我们将分享Netflix在这些应用程序的前端架构中引入GraphQL所积累的经验。
在内部,我们把用于管理广告创建和组装的主要应用程序叫作Monet。它用于增强广告的创建以及自动管理外部广告平台上的营销广告活动。Monet有助于推动流量增量转换,增强用户与产品的互动,并向全世界的用户展示我们的内容和Netflix品牌。
首先,它有助于扩展和自动化广告创建以及管理数百万个广告素材组合。其次,我们利用各种信号和汇总数据(例如Netflix上的内容流行度)来实现高度相关的广告。我们的总体目标是使所有外部发布渠道上的广告都能够让用户产生共鸣,并且不断尝试提高有效性。
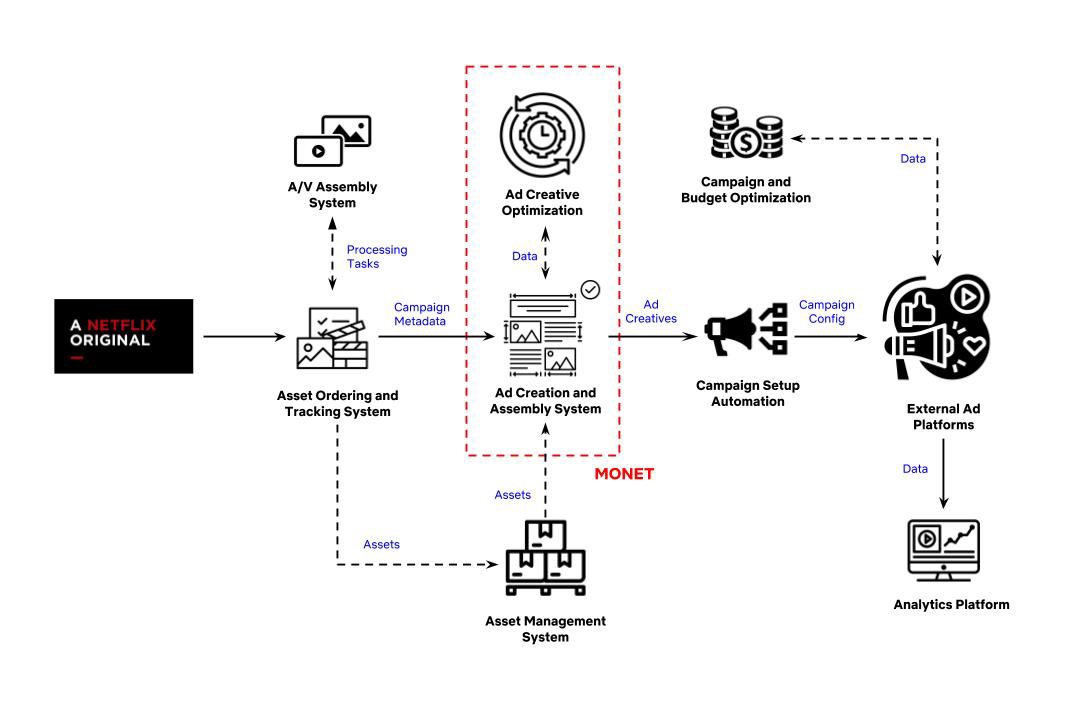
背景
在刚开始时,Monet的React UI层需要访问由Tomcat服务器提供的传统REST API。随着时间的推移,随着应用程序的发展,我们的用例变得越来越复杂,即使是一个简单页面也需要从各种来源提取数据。
为了更有效地将这些数据加载到客户端,我们首先尝试对后端的数据进行非规范化。但这种非规范化变得难以维护,因为并非所有页面都需要所有数据。我们很快遇到了网络带宽瓶颈。浏览器需要获取比以往更多的非规范化数据。
为了减少发送给客户端的字段数量,一种方法是为每个页面构建自定义端点,但这很明显不是一个好的解决方案。我们没有去构建自定义端点,而是选择GraphQL作为应用程序的中间层。
我们还将Falcor作为一种可能的解决方案,因为它在Netflix的很多核心用例中已经取得了很好的成果,并且得到了大量的采用,但因为GraphQL强大的生态系统和第三方工具,我们认为GraphQL对我们的用例来说会是更好的选择。此外,随着我们的数据结构越来越以图形为导向,GraphQL最终会变得更加合适我们的用例。引入GraphQL不仅解决了网络带宽瓶颈问题,而且还提供了很多其他优势,让我们能够更快地添加功能。
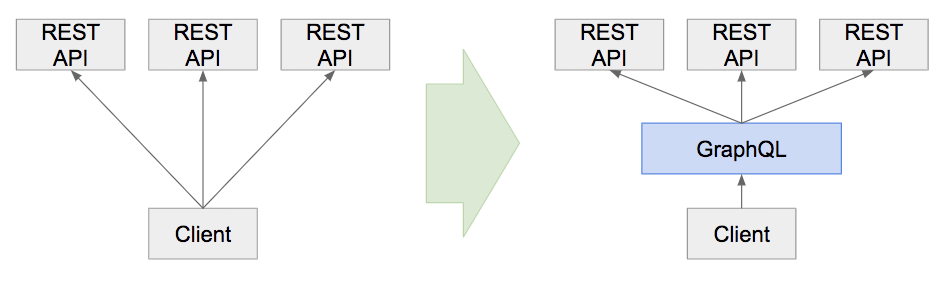
我们已经在NodeJS上运行GraphQL大约6个月,并且它已经被证明可以显著提高我们的开发速度和整体页面的加载性能。以下是从我们开始使用它以来给我们带来的一些好处。
GraphQL优点
重新分配负载和优化有效载荷
通常,某些机器比其他机器更适合用来完成某些任务。当我们引入GraphQL中间层后,GraphQL服务器仍然需要调用与客户端相同的服务和REST API。现在的区别在于,大多数数据是在同一数据中心内的服务器之间流动。这些服务器到服务器之间的调用具有非常低的延迟,而且带宽非常高,与来自浏览器的直接网络调用相比,性能提升了8倍。
从GraphQL服务器到客户端浏览器的最后一英里数据传输现在减少到了单个网络调用。由于GraphQL允许客户端选择它需要的数据,所以我们只需要获取更小的有效载荷。
在我们的应用程序中,之前需要获取10MB数据的页面现在只需要获取200KB。页面加载速度变得更快,特别是在数据受限的移动网络上,我们的应用程序使用的内存也更少了。这些变更是以提高服务器利用率为代价的,服务器需要进行数据的获取和聚合,不过虽然牺牲了这额外的几毫秒服务器时间,却换来了较小的客户端有效载荷。
可重用的抽象
软件开发人员通常希望使用可重用的抽象而不是单一用途的方法。在使用GraphQL时,我们定义了数据以及与数据之间的关系。当消费者应用程序从多个源获取数据时,不需要操心与数据连接操作相关联的复杂业务逻辑。
例如,我们只在GraphQL中定义一次实体:catalog、creative和comment。我们现在可以基于这些定义构建多个页面视图。客户端应用程序(catalogView)的一个页面想要获得catalog中所有creative的所有comment,而另一个客户端页面(creativeView)想要知道creative和相关comment所属的catalog。

链接类型系统
很多人专注于单一服务中的类型系统,但很少关注跨服务。在GraphQL服务中定义了实体之后,我们就会使用自动生成工具为客户端应用程序生成TypeScript类型。React组件的prop接收类型以匹配组件查询。由于这些类型和查询也需要通过服务器schema的验证,因此服务器的任何重大更改都将被使用数据的客户端捕获到。
使用GraphQL将多个服务链接在一起,并将这些检查过程集成到构建过程中,可以在部署错误代码之前捕获更多问题。理想情况下,我们可以实现从数据库层一直到客户端浏览器的类型安全性。

DI/DX——简化开发
创建客户端应用程序时人们比较关心的是UI/UX,但开发者接口和开发者体验对于构建可维护应用程序来说同样重要。在使用GraphQL之前,编写一个新的React容器组件需要维护复杂的逻辑。
开发人员需要考虑数据之间的相关性、如何缓存数据、是否进行并行调用还是串行调用以及在Redux的什么地方保存数据。在使用GraphQL查询包装器后,每个React组件只需要描述它需要的数据,包装器会处理所有其他问题。这样样板代码更少了,数据和UI之间的关注点也更清晰了。这种声明性数据提取模型让React组件变得更容易理解。
其他好处
我们也注意到了其他的一些较小的好处。首先,如果GraphQL查询的某些解析器失败,成功的解析器仍然会将数据返回到客户端,并尽可能多地渲染页面。其次,后端数据模型得到大大的简化,因为我们不需要关心客户端的模型,并且在大多数情况下可以只提供原始实体的CRUD接口。最后,测试组件也变得更容易,因为GraphQL查询被自动转换为测试存根,我们可以独立于React组件测试解析器。
成长的烦恼
基于我们为网络请求和转换数据构建的大多数基础设施,可以轻松地将React应用程序转到NodeJS服务器上,无需更改任何代码。我们删除的代码比我们添加的还要多。但是,在迁移过程中,我们难免要克服一些障碍。
自私的解析器
GraphQL中的解析器作为独立单元运行,不需要关心其他解析器,因此我们发现它们对相同或类似的数据进行了很多重复的网络请求。我们通过为数据提供者提供一个简单的缓存层来解决这种重复问题,这个缓存层将网络响应保存在内存中,直到所有解析器处理完毕。缓存层还允许我们将对单个服务的多个请求聚合成一次性请求。解析器现在可以请求它们需要的任何数据,无需操心如何进行优化数据的获取过程。
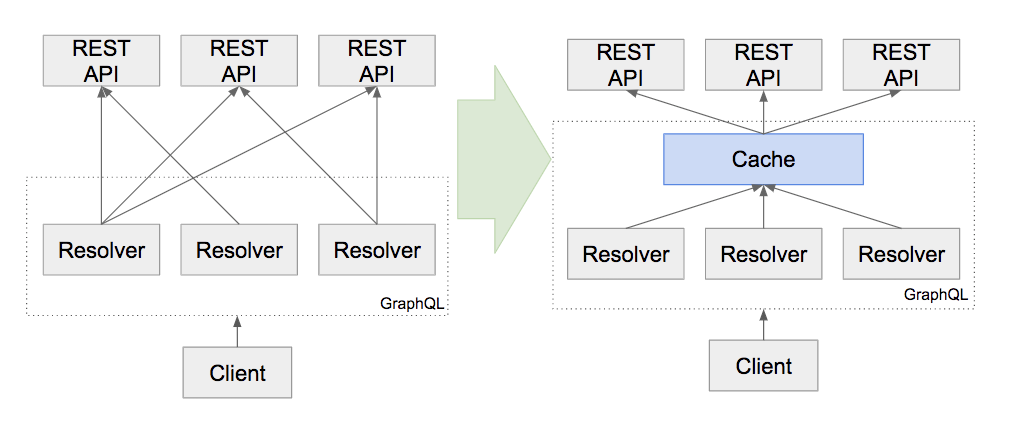
我们编织的糟糕的Web
抽象是提高开发人员效率的好办法......直到出现问题。毫无疑问,我们的代码中存在bug,我们不希望中间层将bug的根源隐藏掉。GraphQL会自动编排对其他服务的网络调用,从而隐藏用户的复杂性。服务器日志可以作为一种调试方法,但仍然不能使用浏览器实现这一步的调试。为了使调试更容易,我们将日志直接添加到GraphQL响应有效载荷中,显示了服务器正在处理的所有网络请求。在启用调试标志后,你将在浏览器中获得与使用浏览器进行网络调用时相同的数据。
被破坏的类型
GraphQL破坏了OOP的范式,当我们获取部分对象时,这些数据不能用于需要完整对象的方法和组件。当然,你可以手动转换这些对象,但是你会失去类型系统的很多好处。所幸的是,TypeScript支持动态类型,因此我们可以调整方法,让它们只需要获得真正需要的对象属性即可。定义这些更精确的类型需要更多的工作量,但总体上能够提供更大的类型安全性。
接下来
我们仍然处于探索GraphQL的早期阶段,到目前为止,这是一次积极的体验,我们很高兴能够采用它。我们的关键目标之一是在系统变得日益复杂的同时帮助我们提高开发效率。
我们希望在图数据模型上进行投入,以便随着更多边和节点的增加,我们的团队将变得更加高效,而不是陷入复杂数据结构的泥潭中。在过去的几个月,我们已经发现现有的图模型已经变得足够强大,我们不需要修改图就可以构建出一些功能。GraphQL确实使我们更有成效。
随着GraphQL继续发展和不断成熟,我们期待从社区学习到更多东西。在实现层面,我们期待使用一些很酷的概念,如模式拼接,这让与其他服务的集成变得更加简单,并节省大量的开发时间。最重要的是,让公司的更多团队看到GraphQL的潜力并开始采用它是一件非常令人兴奋的事情。
英文原文
https://medium.com/netflix-techblog/our-learnings-from-adopting-graphql-f099de39ae5f
