@qinyun
2018-08-01T08:31:10.000000Z
字数 4253
阅读 3899
去哪儿网前后端分离实践
未分类
前后端分离方案
去哪儿网主要有三种前后端的分离方案。
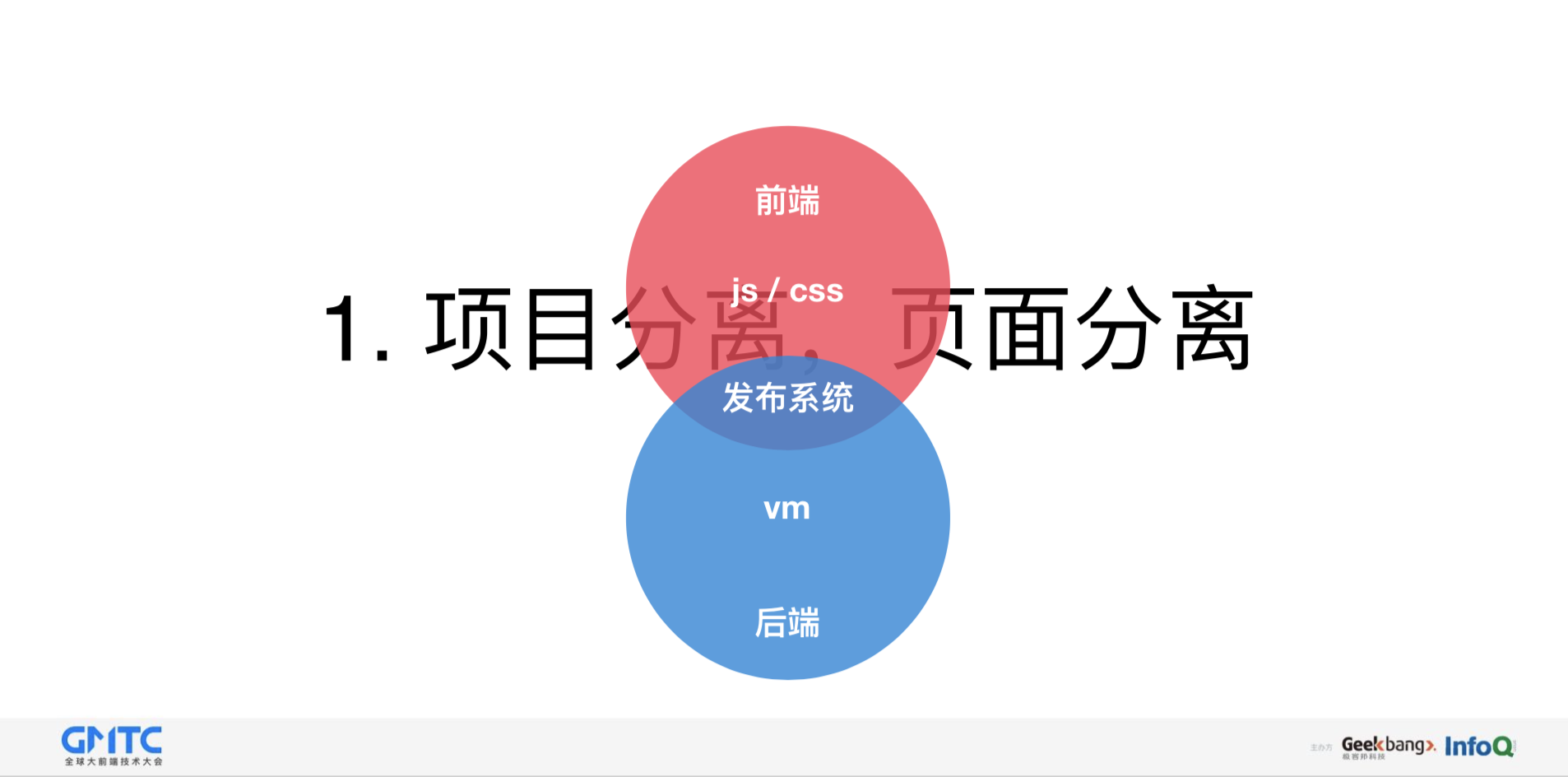
第一种方式是项目分离,页面分离,它的特点是简单快速,前端只需要关注浏览器方面,浏览器之外,全是由后端去负责,但沟通成本会非常高,因为在前期,前端需要使用NG,或使用代理工具进行调试,后期还要把一些页面给到后端,并且让后端新建一个所对应的一个路由,这样来来回回调试非常复杂,一旦前后端同学涉及到跨部门,跨楼层合路的时候,这些成本又会相应地增加。
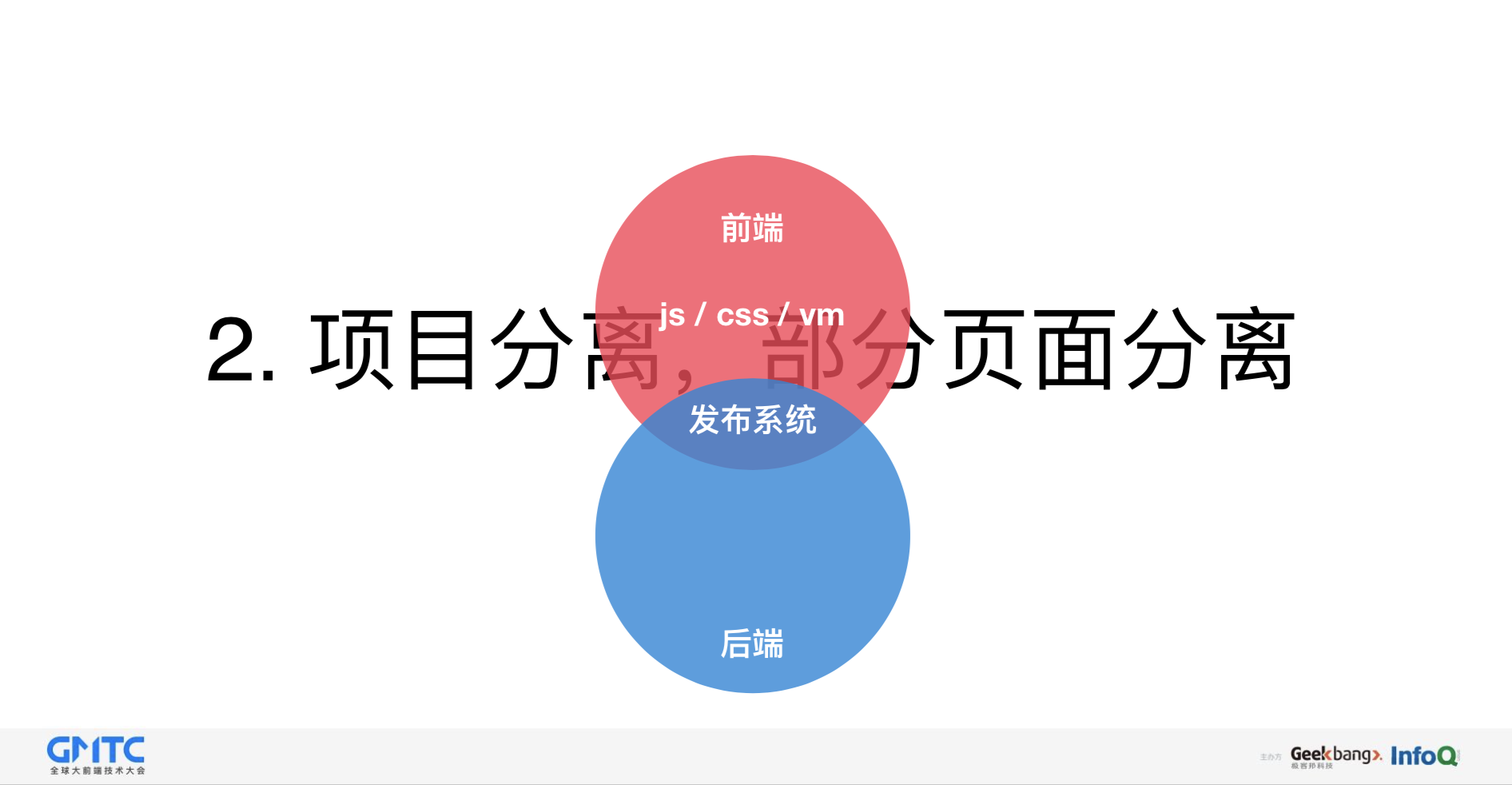
第二种方案还是项目分离,后端的页面放到了前端项目里,后端只需要配置路由就行了,最终上线的时候,由发布系统负责把前端中的页面自动同步到后端所相对应的目录文件里面。当然,在前期,前后端需要约定一下,要同步一个路径,不然在后端渲染页面的时候就会找不到相应的文件,相比第一种方案,稍微有点进步,沟通成本有一点降低。
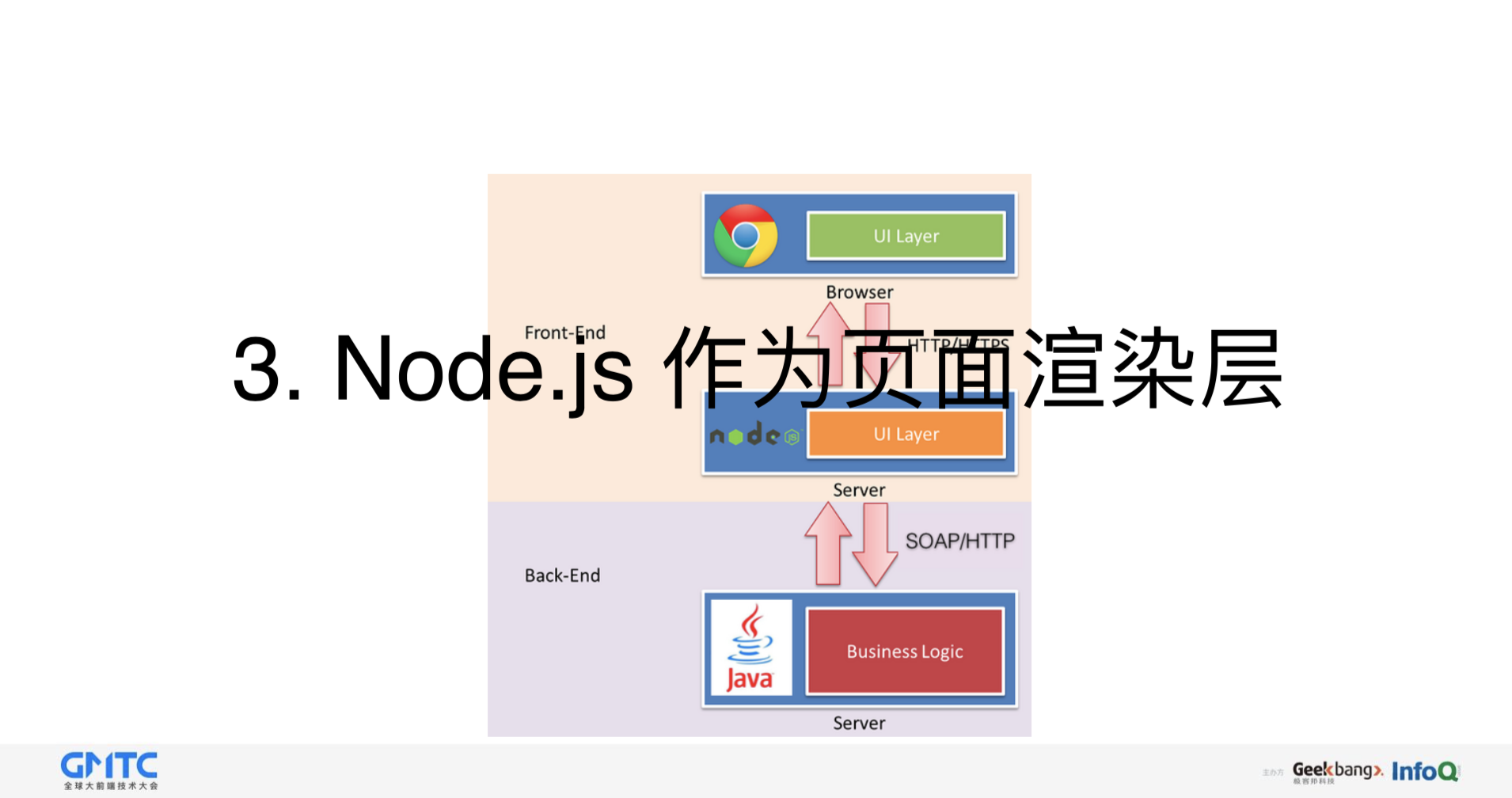
第三种方案,使用Node.js作为页面渲染层,后端只负责数据的生产工作,这也是在去哪儿网内部最主要的方式。它的优点是前端同学对于整个页面的生命周期有完全的控制权,包括开发调试,部署,上线,监控等,另外可做的事情也非常多,比如我们不能做React SSR,而使用Node.js很容易做这件事情。
静态资源离线包方案(qp)
在三种方案演变的过程中,为了让用户快速的看到页面,我们还设计了一个静态资源包的方案,这是它的整体的流程图:
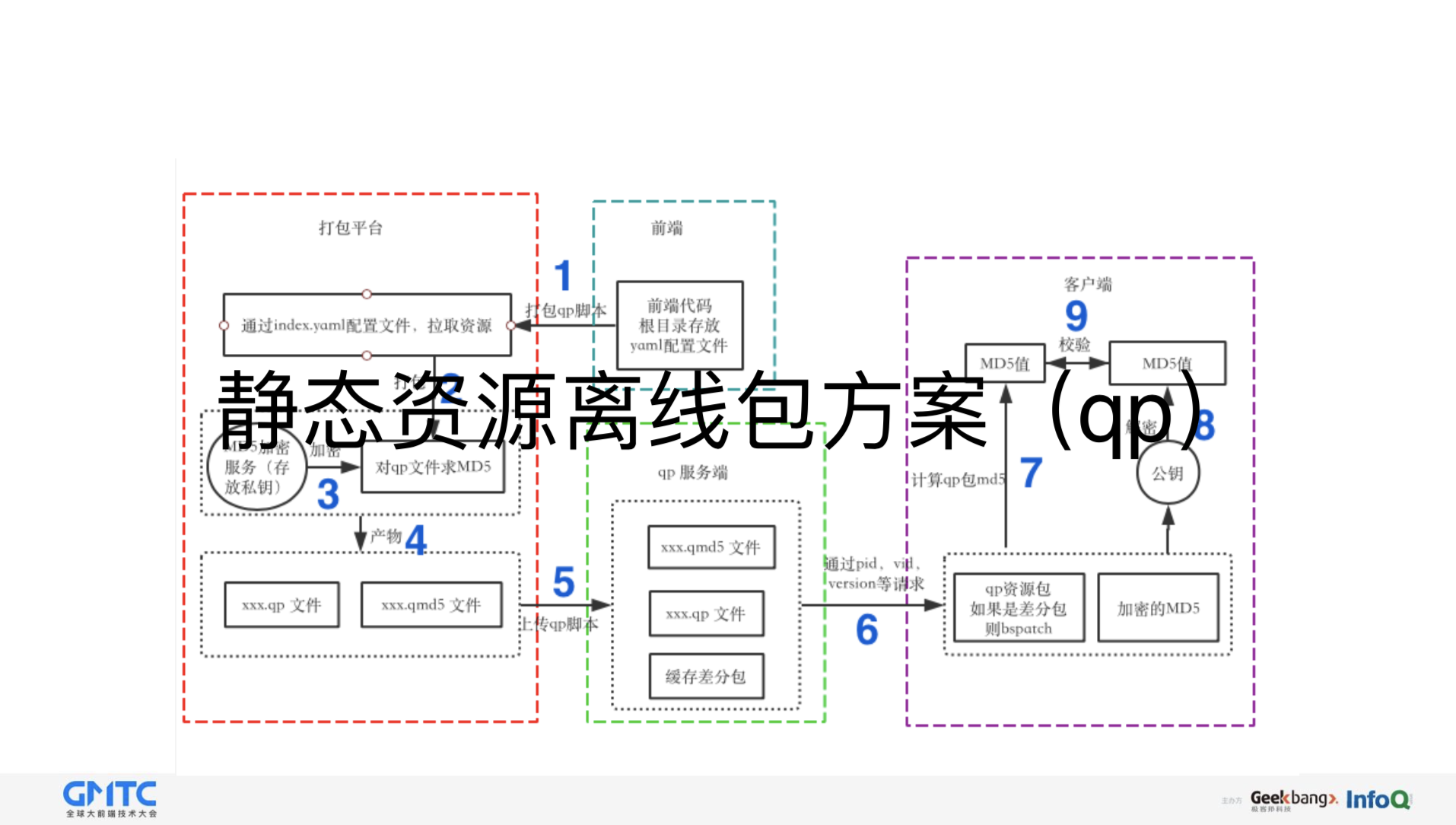
第一部分由前端同学负责,就是做一些配置文件;
第二部分是打包平台,需要把我们的配置文件读到,然后进行打包,打包期间,我们还要进行数据加密的操作,比如使用私钥,让qp包生成一个MD5文件,送到qp服务端,最后到客户端,客户端用私钥对QD再次求MD5,用一个QP服务端返回的一个MD5质量进行对比教验,如果通过说明是一个我们需要的包,而不是说被恶意篡改的包。
在客户端的时候,需要客户端同学做很多事情,为什么?因为这涉及到一个网络环境的问题,如果用户的环境是WiFi的情况下,我们会自动拉取所有的离线包,如果是非WiFi网络的环境,比如说4G、2G等之类的,我们是不会自动拉取离线包的。因为这样为了减少用户的流量,当用户进入到特定我们的页面的时候,会检查我们的本地是否存在有这样的离线包,如果有的话,就用我们离线包资源,如果没有的话直接走线上环境,它会静默在我们的后台,去静默下载,这是我们的客户端需要做的事情。
那么项目怎么去使用呢?很简单,只需要在项目的根目录中新建一个index.yaml的配置文件就可以了,其中包含几个主要内容:
唯一标识QP包的ID
针对IOS或安卓,特定的版本号去做一些限制
确定打包内容,因为并不是所有的资源都需要在QP文件的,因为体积会增加
最后是忽略内容,就是需要把我们的文件去忽略。
第二步就是相应的开发,或者QA去进入打包平台进行发布,也很简单,只要添置一些配置项就可以了,也不需要去人工干预。
用户对离线包是完全透明,并且无感知的,大家从整个流程上看相关的一些功能,可能觉得很简单,不复杂,但实际上考虑的事情非常多:
首先,保证资源的安全性,不被中间人恶意篡改,主要体现在传输安全和存储安全上。
第二,如何保证QP包快速回滚,因为不能保证QP发下去之后没有问题,有时候出现问题之后,怎么去保证快速回滚呢?起初我们用的是假回滚机制。假回滚就是每次有问题的时候,流程再走一遍,因为它的版本号是递增的,在实际的操作起来成本高。如果代码变动,那么打出的包的内容也会变,我们后期把它变成了一个真正的回滚机制。
第三,下线和强制更新。下线就是当某个qp包有问题的时候,我们需要针对这个qp包进行下线的操作,不让用户访问到了,针对的是当前的这个离线包。那么强制更新呢?它的意思是说,当某个QP包希望用户或者某一批用户下载到时,我需要做一个强制更新的操作,那么它针对的要点是将要下载的包,这两个是不同的概念。
再者,就是提高更新率,主要有三个方法:第一,减少qp包大小,也就是体积;第二,使用HTTP2协议;第三,尽量使用差分包,而不使用全量包,因为全量包很大,我们只要不涉及到大更新,就不需要发全量包,尽量使用差分包的机制。
最后,关于更新率的效果:
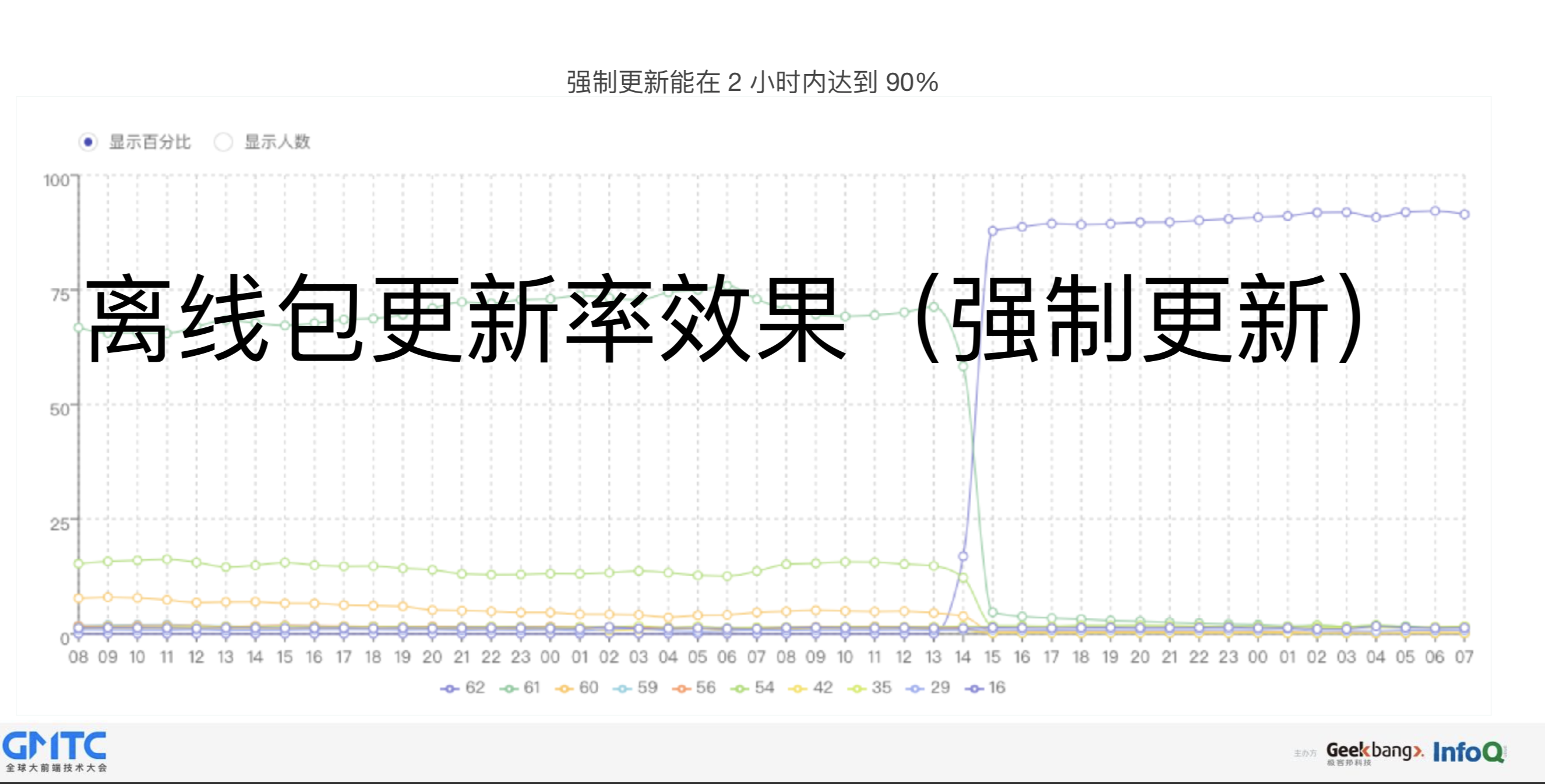
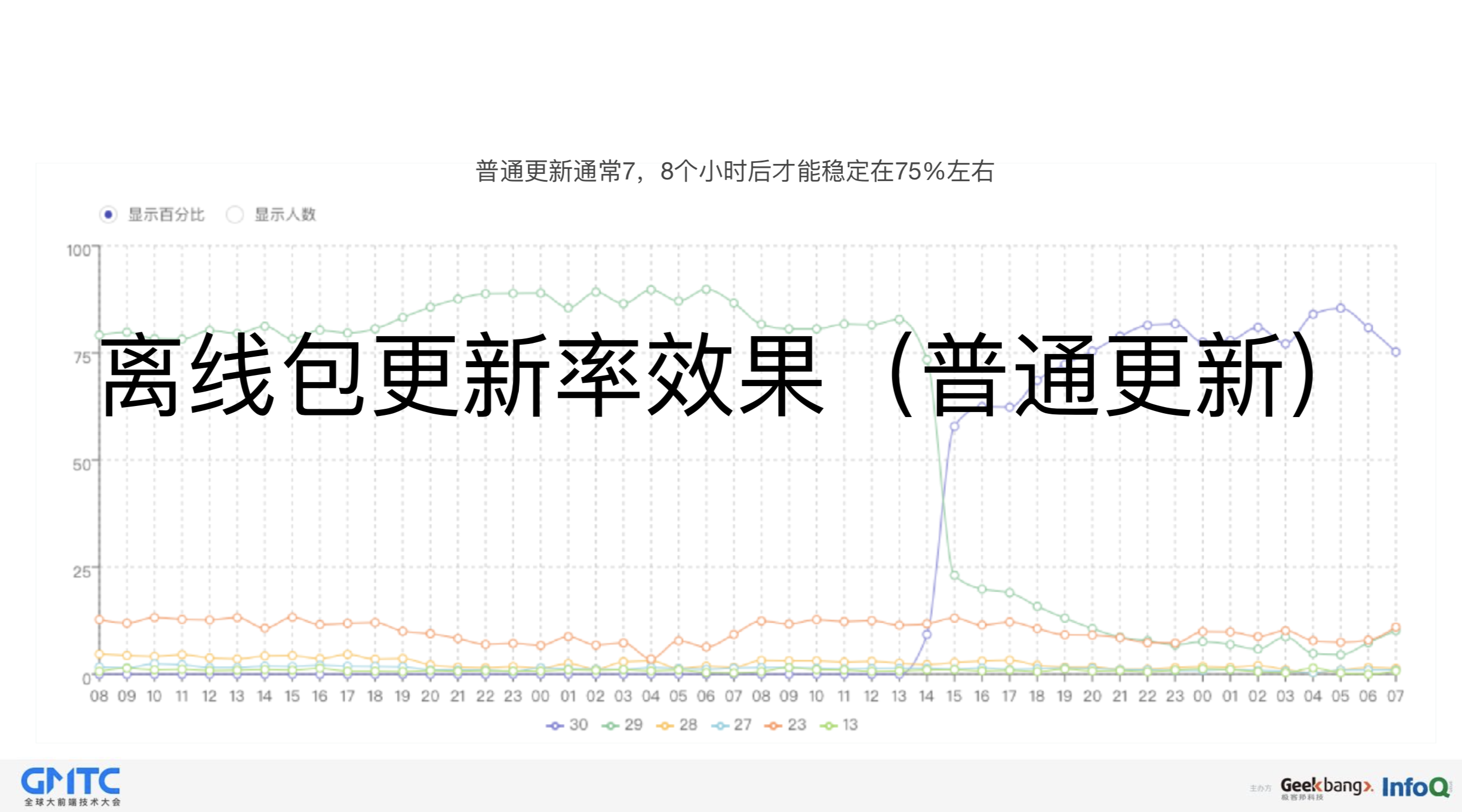
强制更新和普通更新这两个机制实现的方式不一样,所以它的更新效果也不一样,强制更新的效果最明显,它能在两个小时之内达到一个90%的水平,普通更新得七八个小时之后才能稳定到75%左右。
Node.js 实践
为什么Node没有大规模使用呢?我总结大概的原因:
一些前端开发者,只关注浏览器器端,服务器器端开发关注很少,或者根本就不关注;
认为 Node.js 只适合开发一些⼯工具类的功能,对于后端开发是个玩具;
Node生态不如其他后端语言生态健全;
涉及到后端开发的知识面比较广,在没有这些基础知识或者经验积累的基础上,考虑问题比较片面,最终做出的系统问题比较多,容易被后端鄙视;
对于Node开发后端,对项目负责人要求比较高(项目的目录规范,开发规范,系统的安全性,稳定
终做出的系统问题⽐比较多,容易易被后端鄙视性,可靠性,扩展性,维护成本等);以往前端不需要7 x 24保持待命状态,但是接触后端后,需要接受报警短信,有时出现问题还需要⻢马上随时随地解决;
Node.js到底能解决我们哪些的问题和痛点呢?
首先,提高开发效率,因为有了Node之后就不需要配置Nginx了,也不需要配置一些代理工具了,所有的页面生命周期都是由前端统一去管理的,这时候不需要其他人进行合作。
第二,降低沟通成本,除了接口格式外,不需要和后端进行交互了;
第三,前后端职责也更为清晰,因为这时候,界限更为清晰了,后端只负责生产数据,它只提供数据就可以了,至于数据怎么消费,以及怎么用,都由前端去做;
第四,可以同时使用React SSR 技术,做到首屏渲染,提高用户体验,除了首屏之外,还可以做异步的加载、SEO等操作。
最后,Node.js可提供一些服务,不仅能让我们使用,还可以对外使用,如RESTful API,这样就不用有求于后端了。
去哪儿网在三年前用的是基于express的解决方案,包括日志收集,监控,模板,以及异常等。
在实际的开发使用过程中,或多或少有些问题,主要体现在以下方面:
1.如何确定项⽬目⽬目录划分的规范,命名规范(view or views);
2.确定规范后,如何保证⼤大家都认可,并且严格遵守;
3.如何保证系统的安全性、稳定性和扩展性,怎么保证和我们内部系统做很无缝的去对接,这就要求有很好的扩展性;
4.守护进程程序的选择(pm2 or supervisor);
5.怎么保证多环境运⾏行行规则(local / beta / prod),因为在我们实际项目中,可能对我们的Local或者对Bata或者对PID都有不同的规则,如果这时候没有去做这件事,就有可能对我们的实际应用有可能造成一定的障碍;
6.如何利利⽤用系统 cpu 多核,以及多进程之间的通信。
针对这些问题,去哪儿网也进行了一些改进,开始Revial和调研,最终,在文档说明、框架扩展、插件数量、部署流畅性以及开发体验上,我们选择的是 Egg.js。
插件开发
同时,为了对接我们的内部系统,我们还开发了不同功能的一些插件,比如egg-qversion,它能关联我们前后端版本号,因为不管你是原来那种Java和Java合作的模式,还是现在Node.js,都需要版本号的关联。
由于,我们用webpack进行打包,webpack打包出来是一个MD5一个串,那保证这些串关联起来呢?我们做了一个egg-qversion的插件;
第二个是egg-qconfig,这个是对接内部的q系统;
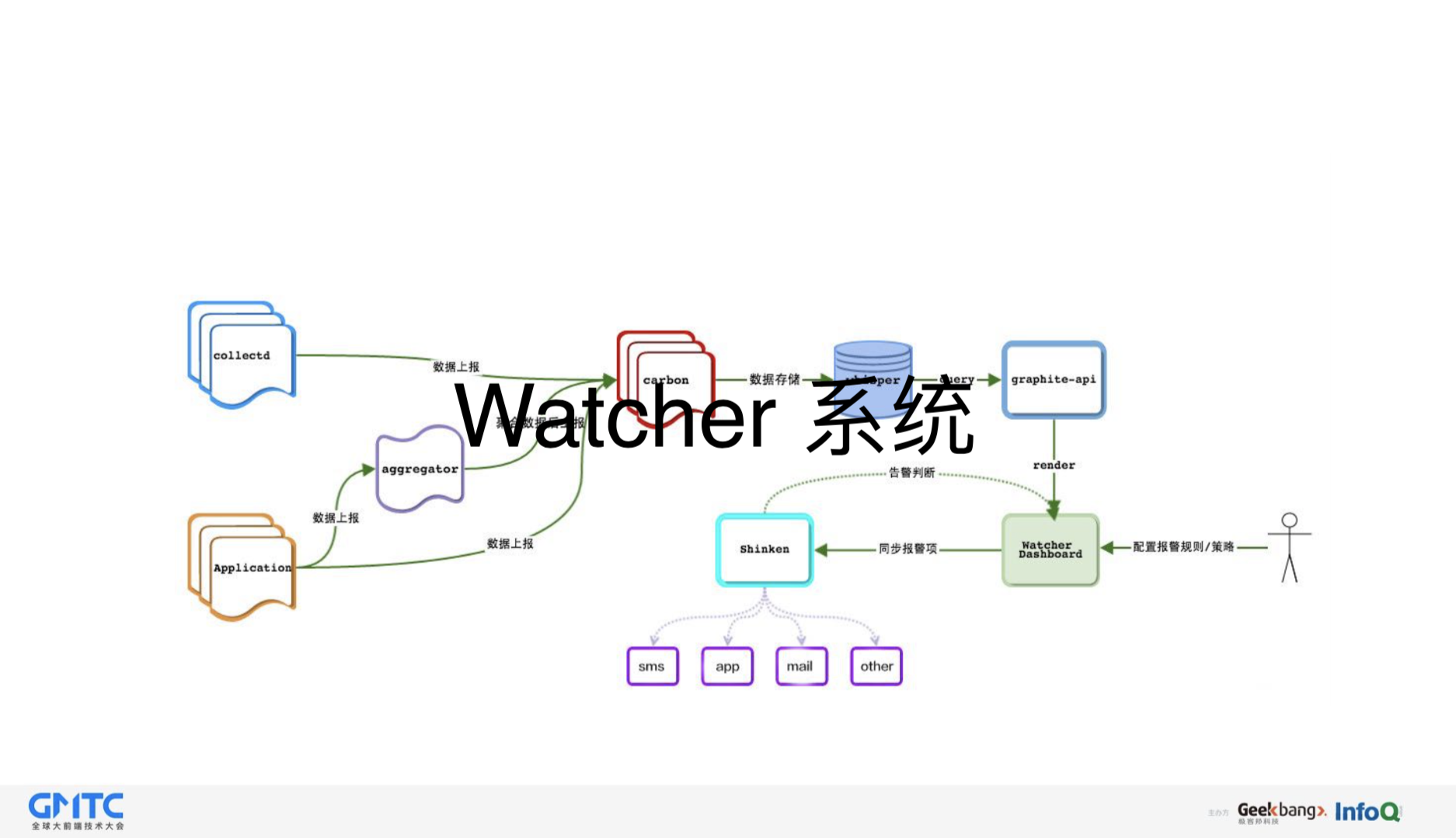
第三个就是对接我们的qwatcher系统的egg-qwatcher。
不带Q的的插件,就是对外的,比如说egg-accesslog,对于Java来说,egg-accesslog不需要大家去关心,因为他们在NG上做了处理,或者在Java本身做了处理,但是Node没有做处理,这个需要我们自己去做。
还有egg-healthcheck,这是心跳检测的一个功能,就是检测我们的应用,或者检测我们服务器是否在下线或者上线的过程;
egg-checkurl是检查我们的应用是否存活;
最后一个是对接egg-swift的系统,就是存储的系统,后四个都是公开的。
去哪儿网原来的部署流程(service 方式)问题
1.不能利⽤发布系统中相应的端口和⽬录字段,只能在 qunar_xx 服务中写死, 不友好
2.不能区分多环境策略如beta环境和prod环境配置规则不一样
3.启动过程中出现错误,不方便定位问题,需要到机器上排查
4.写系统服务需要了解shell命令和系统服务格式,对于前端开发同学,成本稍高
5.除了端口、项目路径、运行环境,node.js启动方式外,处理逻辑相似
改进过的部署方式
在项目中建立 deploy_scripts 目录,新增 start.sh (名称可以随便命名)
在 start.sh 中填⼊Node.js 启动逻辑,比如 node index.js (之前是 N 行,
如今最多两⾏)在发布系统选择 node 发布方式,填⼊端⼝号,发布路径,以及启动脚本名称(start.sh),停止脚本填入发布系统内置的stop.sh(按照端口杀掉进程)
这是start.sh的一个样例:
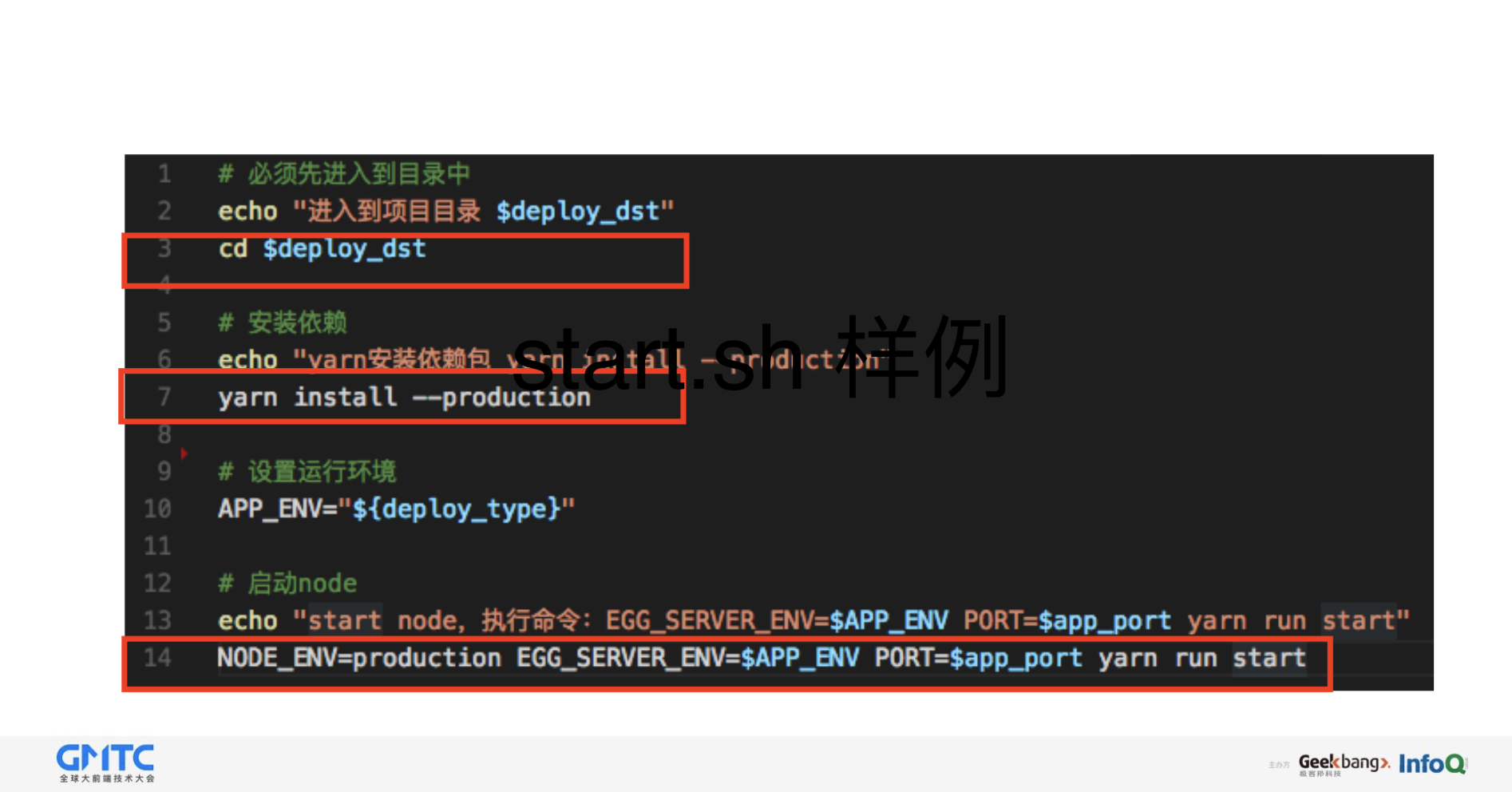
第二,我们可以安装一些依赖。
第三,启动Node.js,因为我们用的是egg.js,启动的逻辑是参照Node.js的起动方式发布的。
React SSR实践:
这是大致的结构:
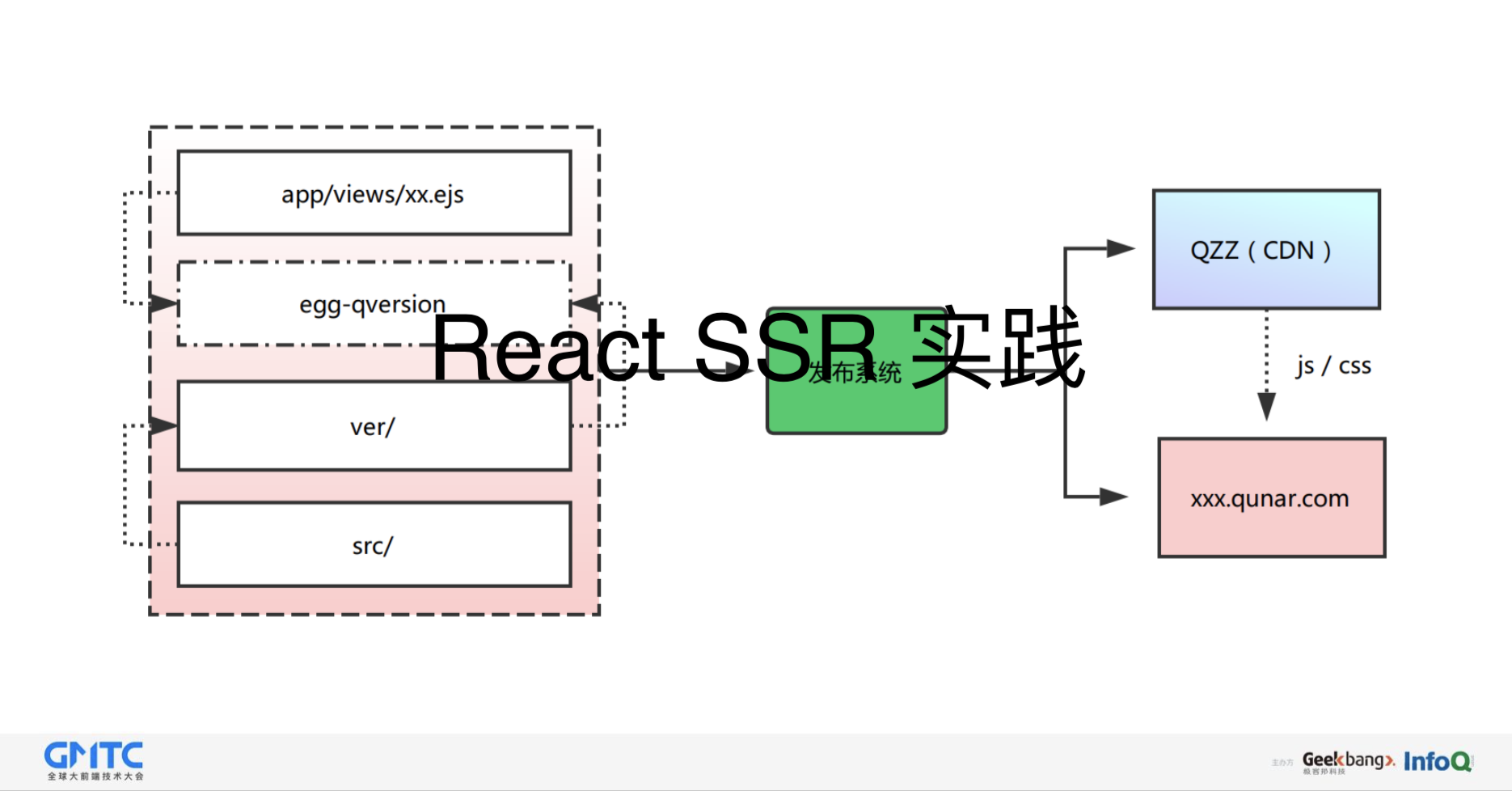
这是React SSR实现的结构。

即使不使用React SSR,我们这个项目同样能跑,基于这两点,我们使用React进行一些操作,红圈就是引用我们前端一个JS代码,然后最后就是做一些那个异步,同步加载的过程。
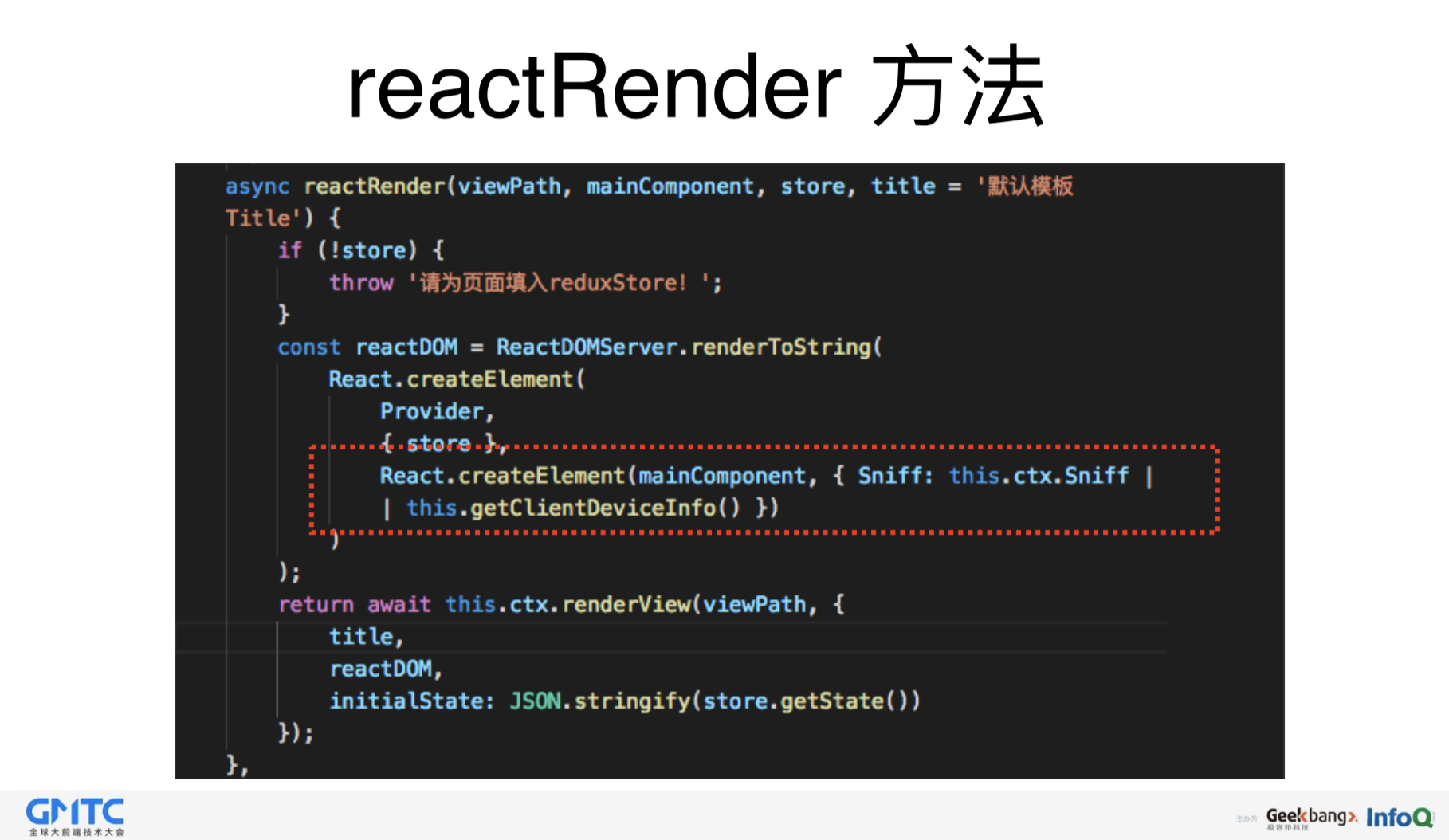
这是reactRender的写法。
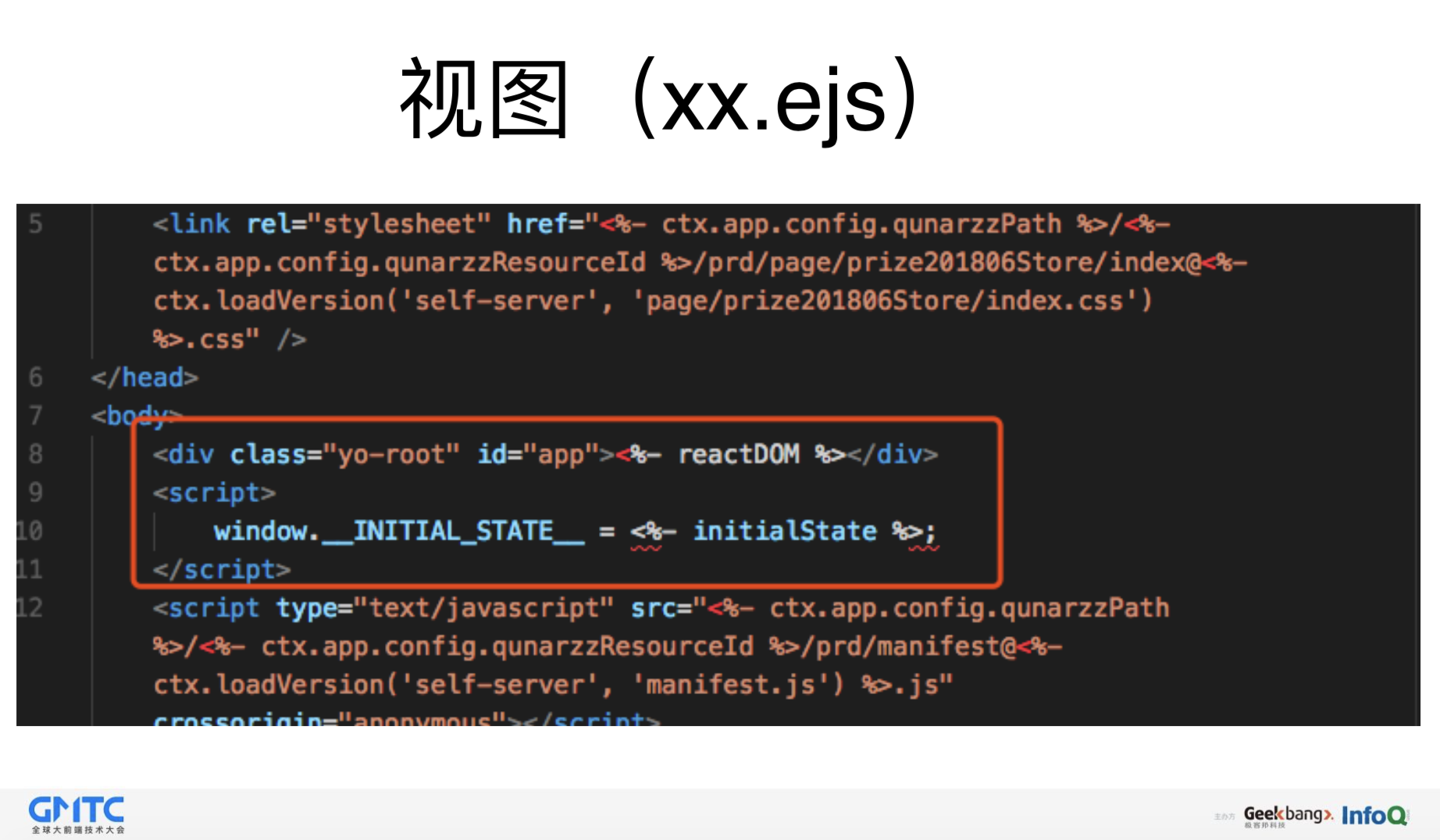
React SSR 遇到的问题
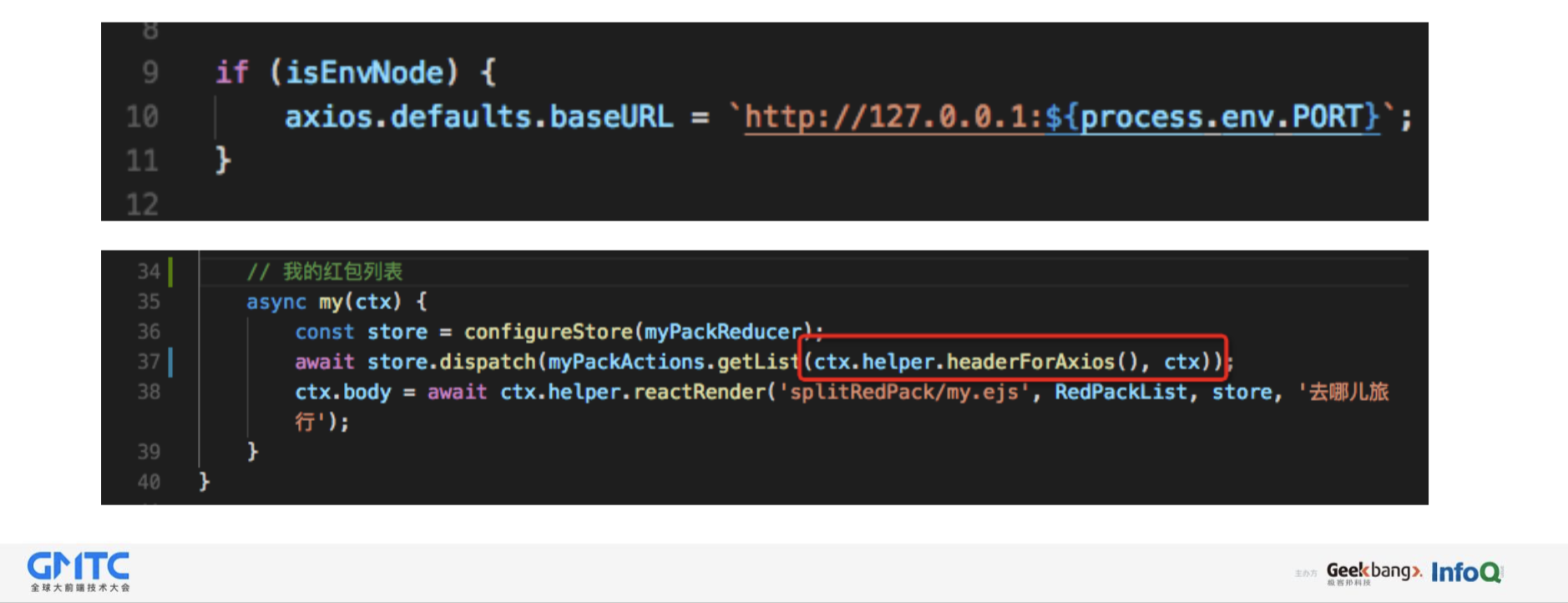
共享代码如何处理请求
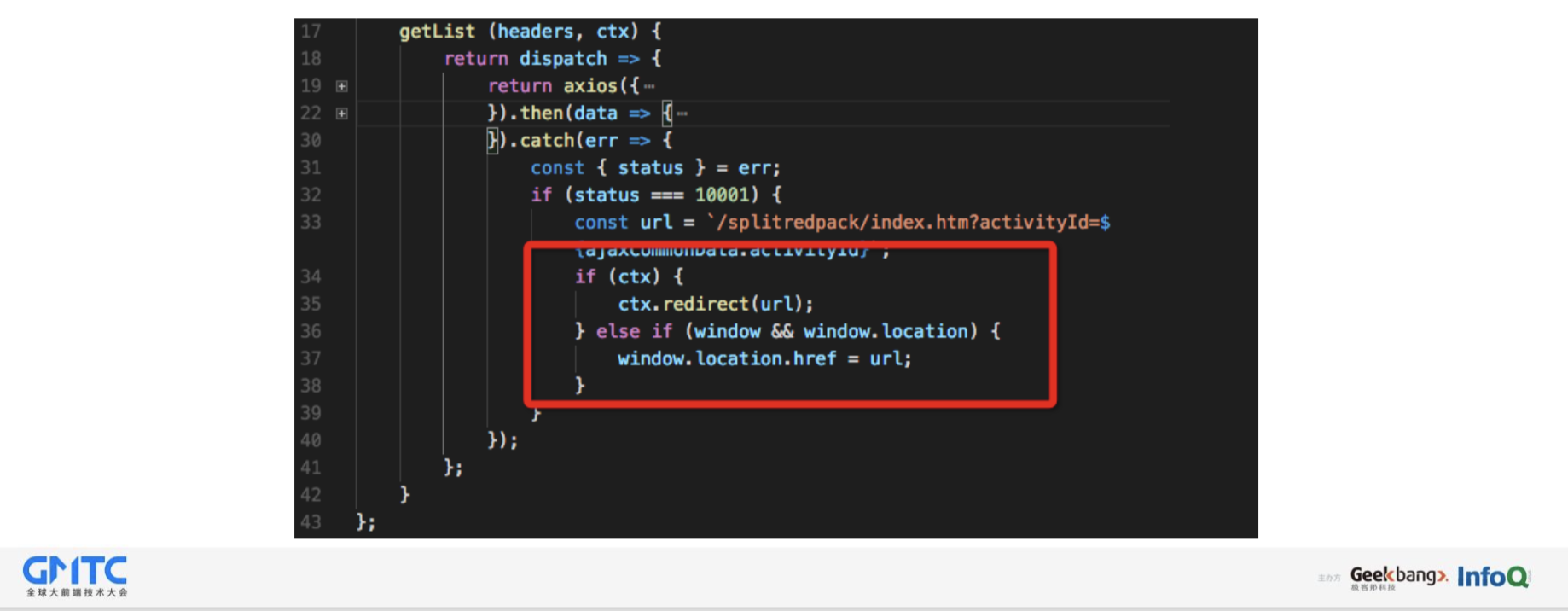
共享代码如何处理错误
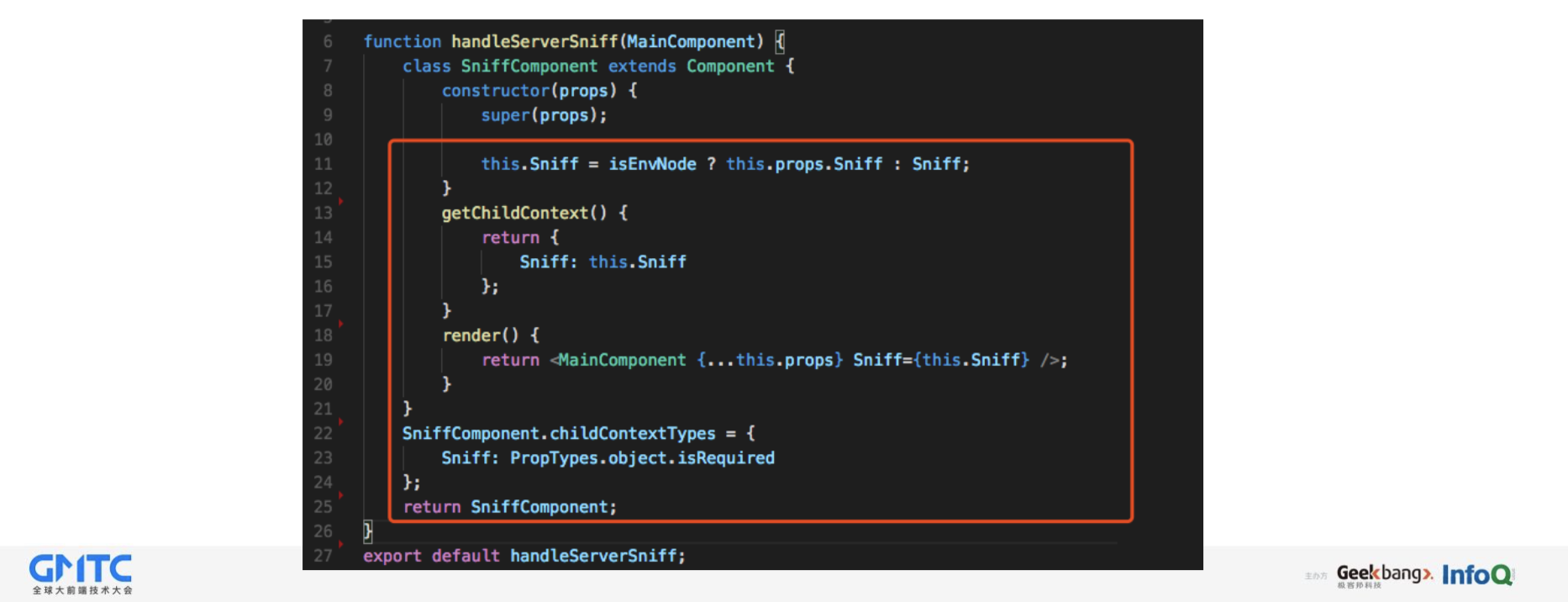
后端代码获得设备信息
性能监控
对于性能方面,我们做得不是太多,因为 eggjs 本身已经经历过淘宝双十一的洗礼, 相信在阿⾥内部对这块已经做了不少优化,所以简单使用的是公司级别的机器监控。
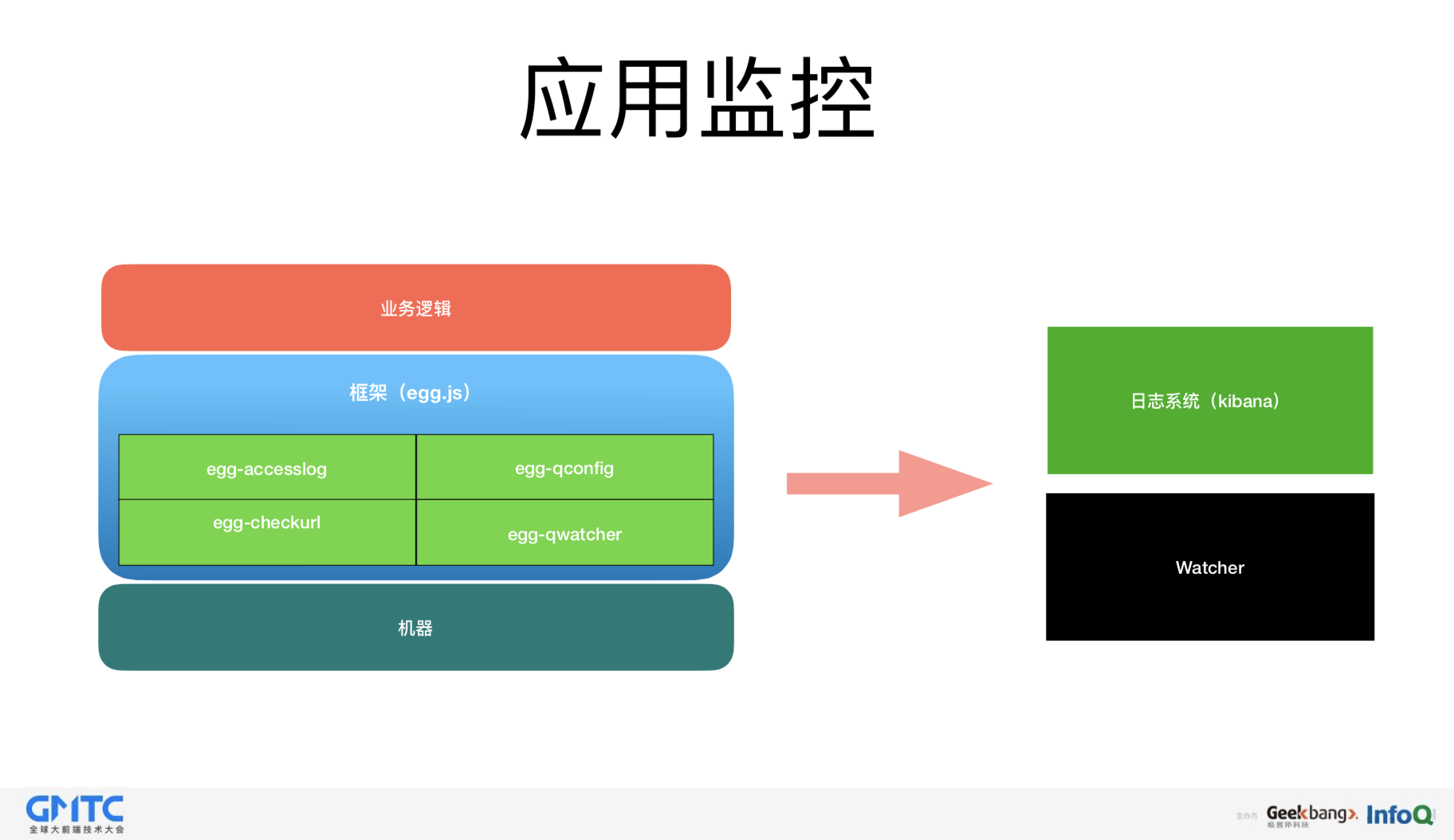
在应用方面,我们做的比较多,应用分成两个方面,一个是应用级别的错误,还有一个是前端页面级别的错误。
应用级别的错误,就是记录应用用户数,使用后端接口消耗时长,以及它所对应的接口异常等。
前端页面级别错误,如脚本错误,还有静态资源文件夹的错误、异步错误。
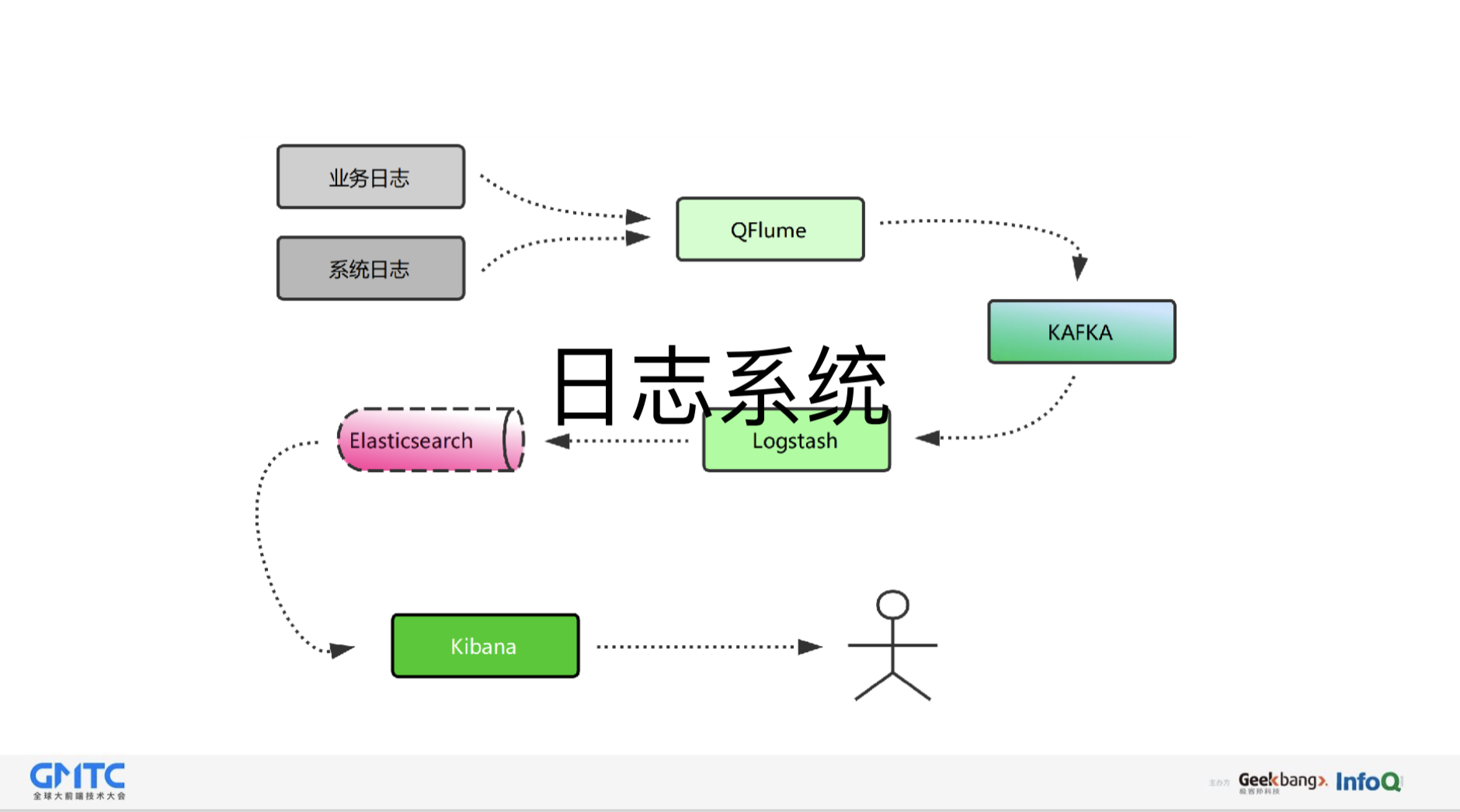
针对这两方面的错误,我们有了两个系统,一个是日志系统,一个是Watcher系统,这两个系统是搭配合作的。