@zhuanxu
2018-03-28T10:18:02.000000Z
字数 1843
阅读 3659
实战:基于 docker 的 HA-hadoop 集群搭建
分布式系统
Hadoop的master和slave分别运行在不同的Docker容器中,其中hadoop-master容器中运行NameNode和ResourceManager,hadoop-slave容器中运行DataNode和NodeManager。NameNode和DataNode是Hadoop分布式文件系统HDFS的组件,负责储存输入以及输出数据,而ResourceManager和NodeManager是Hadoop集群资源管理系统YARN的组件,负责CPU和内存资源的调度。
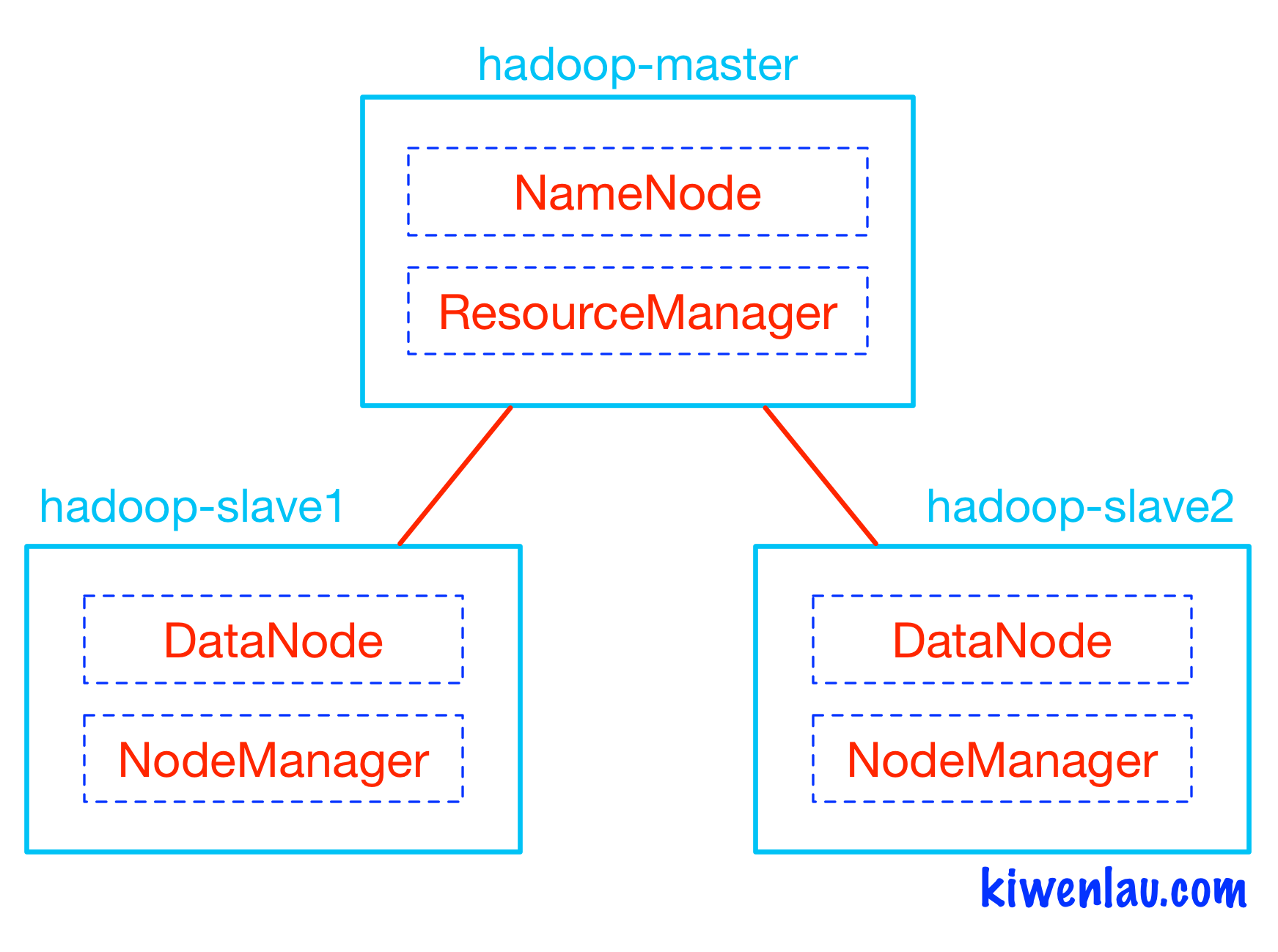
我们先来规划下集群:
| 主机名 | 安装软件 | 运行的进程 |
|---|---|---|
| node1 | JDK、Hadoop | NameNode(Active)、DFSZKFailoverController(zkfc)、ResourceManager(Standby) |
| node02 | JDK、Hadoop | NameNode(Standby)、DFSZKFailoverController(zkfc)、ResourceManager(Active)、Jobhistory |
| node03 | JDK、Hadoop | DataNode |
| jn01,jn02,jn03 | JDK、Hadoop | JournalNode |
| zk01,zk02,zk03 | JDK、zookeeper | zk,1主2备 |
我们来解释下上面的几个软件
其中 NameNode 是 hdfs 中的namenode,分为一主,一备,保证高可用:
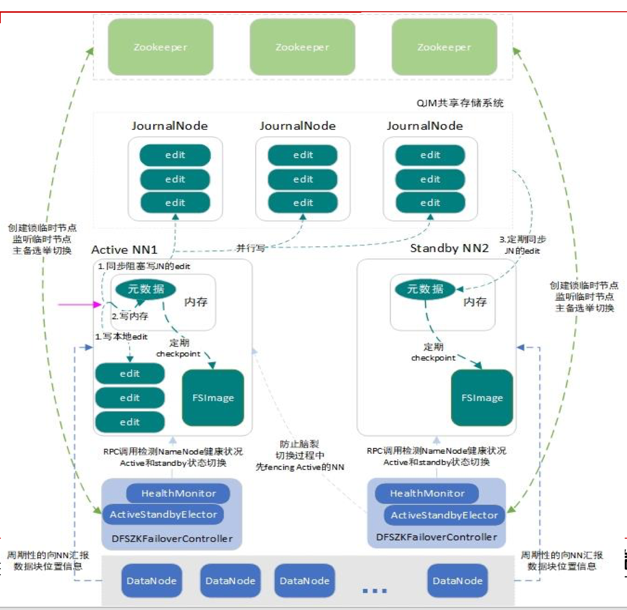
主处于active状态,备处于Standby,主备切换通过DFSZKFailoverController配合zookeeper完成。
另外为了保证master上edit日志的高可用,新建了3个JournalNode。
接着我们来看yarn,yarn是一种资源管理系统,负责集群的统一管理和调度
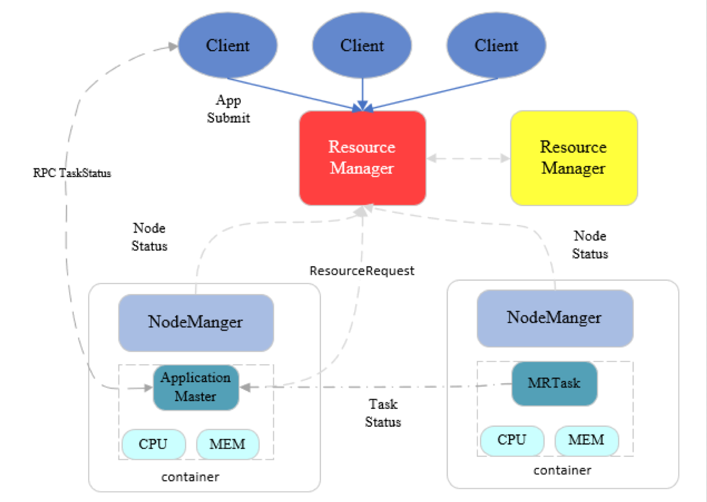
上面是介绍部分,下面我们来执行高可用集群的搭建
第一步到hadoop目录下,执行 docker-compose up -d
第二步执行 ./start-all.sh
完成上面步骤后,我们就可以根据控制台的输出查看数据了。

下面是一些集群验证操作:
1. 验证HDFS 是否正常工作及HA高可用
首先向hdfs上传一个文件
/usr/local/hadoop/bin/hadoop fs -put /usr/local/hadoop/README.txt /
在active节点手动关闭active的namenode
/usr/local/hadoop/sbin/hadoop-daemon.sh stop namenode
通过HTTP 50070端口查看standby namenode的状态是否转换为active
手动启动上一步关闭的namenode
/usr/local/hadoop/sbin/hadoop-daemon.sh start namenode
2.验证YARN是否正常工作及ResourceManager HA高可用
运行测试hadoop提供的demo中的WordCount程序:
/usr/local/hadoop/bin/hadoop fs -mkdir /wordcount
/usr/local/hadoop/bin/hadoop fs -mkdir /wordcount/input
/usr/local/hadoop/bin/hadoop fs -mv /README.txt /wordcount/input
/usr/local/hadoop/bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount /wordcount/input /wordcount/output
验证ResourceManager HA
手动关闭node02的ResourceManager
/usr/local/hadoop/sbin/yarn-daemon.sh stop resourcemanager
通过HTTP 8088端口访问node01的ResourceManager查看状态
手动启动node02 的ResourceManager
/usr/local/hadoop/sbin/yarn-daemon.sh start resourcemanager
代码的github地址:https://github.com/zhuanxuhit/distributed-system/issues/4 欢迎关注
你的鼓励是我继续写下去的动力,期待我们共同进步。

