@zhuanxu
2018-02-14T06:59:19.000000Z
字数 1836
阅读 3137
卷积神经网络进阶
cnn
卷积基础
之前写的卷积神经网络一文中有对卷积核的讲解,下面补充下里面未曾讲到的卷积核计算的问题。
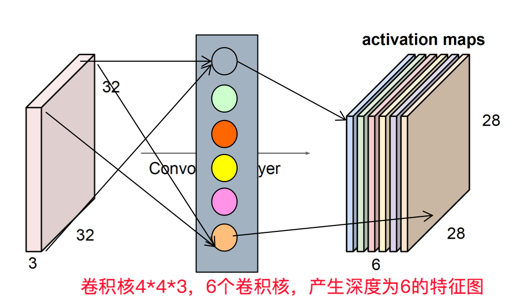
如上图所示,我们假设输入输入是 ,卷积核的4个超参数是:
- 卷积核个数K
- 卷积核大小F,F * F
- 卷积核每次移动距离S
- 左右填充大小P
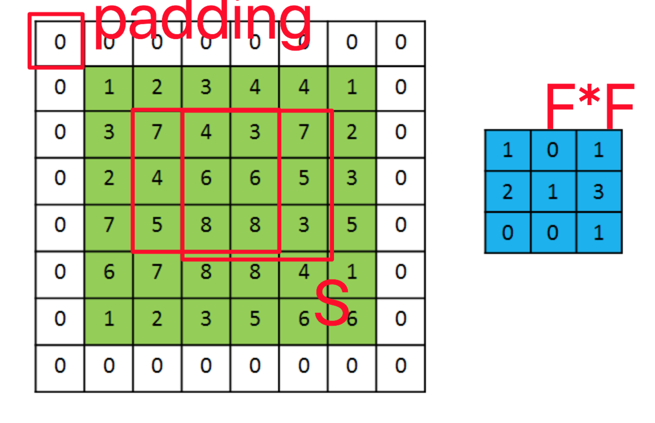
通过卷积后,输出为
下面计算引入的参数:
是单个卷积核参数的参数,一共有K个卷积核,即参数为
传统识别算法
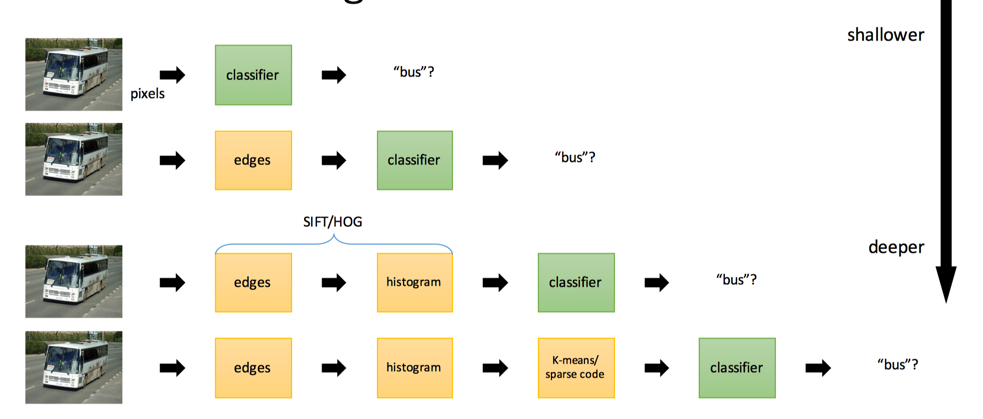
传统识别算法如上图所示,从浅到深,并且在变深的过程中,如下图所示,所需要的领域知识也越来越少,我们所需要只是不断去叠加通用模块-卷积层。

卷积神经网络回顾
LeNet, AlexNet, VGG, GoogleNet;Batch Norm,…

整个卷积网络的发展。
LeNet

卷积网络中最重要的可能是权重共享了,有效的减少了参数个数,可以查看之前的文章卷积神经网络里面有对卷积核的理解。
AlexNet

12年的时候AlexNet,其激活函数使用Relu,通过dropout和数据增强来防止过拟合。

上面是模型结构的细节。
VGGNet

14年的VggNet基本结构是3*3卷积,通过简单的堆叠达到了当时的最佳效果,训练这么深的网络,一个关键就在于如何初始化模型参数。
特点有:
- 通过加深网络来获取更多的非线性表达能力
- 3*3卷积核,可以参考知乎的回答为什么一个 5 * 5 的卷积核可以用两个 3*3 的卷积核代替,一个 7*7 的卷积核可以用三个的 3*3 卷积核代替?
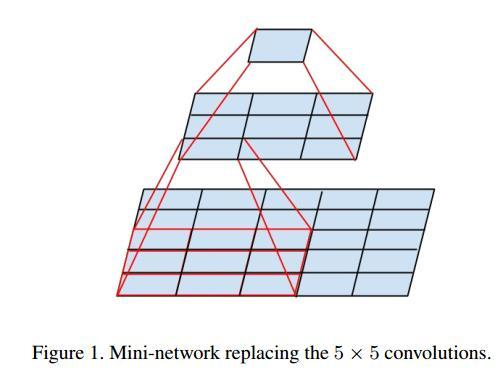
我们可以看到2个3*3的卷积核视野是和一个5*5的卷积核一样的,但是5*5 的 kernel 是 2 个 3*3kernel 的参数量的 25/18=1.39 倍,而且2个3*3的卷积核通过两个激活层,能引入更多的非线性。
下面是vggnet的具体结构,可以看到内存前面层占用的多,参数则是后面层多。

模型参数初始化
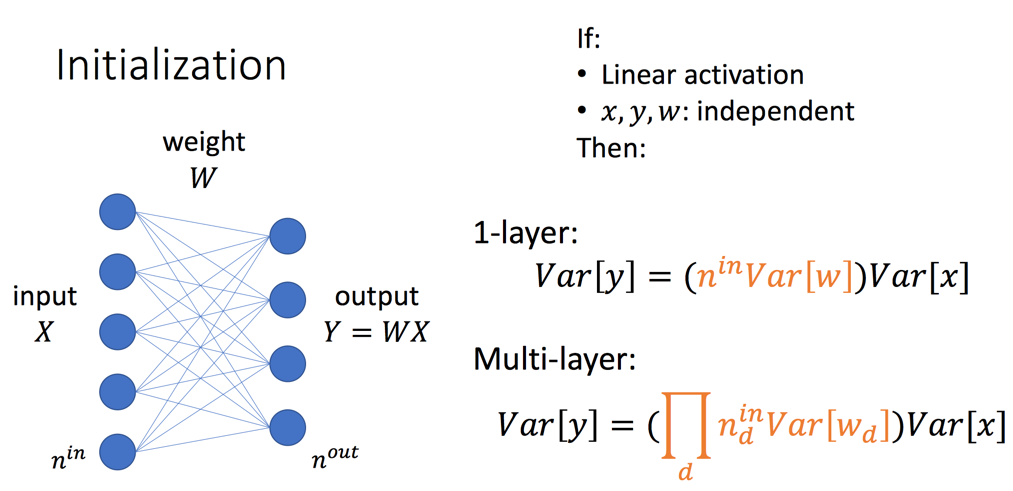
如上图所示,如果y=wx,则我们可以计算出输出和输入之间的方差关系,差的参数就是一个

通过方差之间的关系,我们再来看"梯度爆炸"和"梯度消失"问题,要想解决我们就希望
下面介绍两种初始化方法:Xavier 和 MSRA。


具体的初始化方法可以看吴恩达第二课-权重初始化
GoogleNet
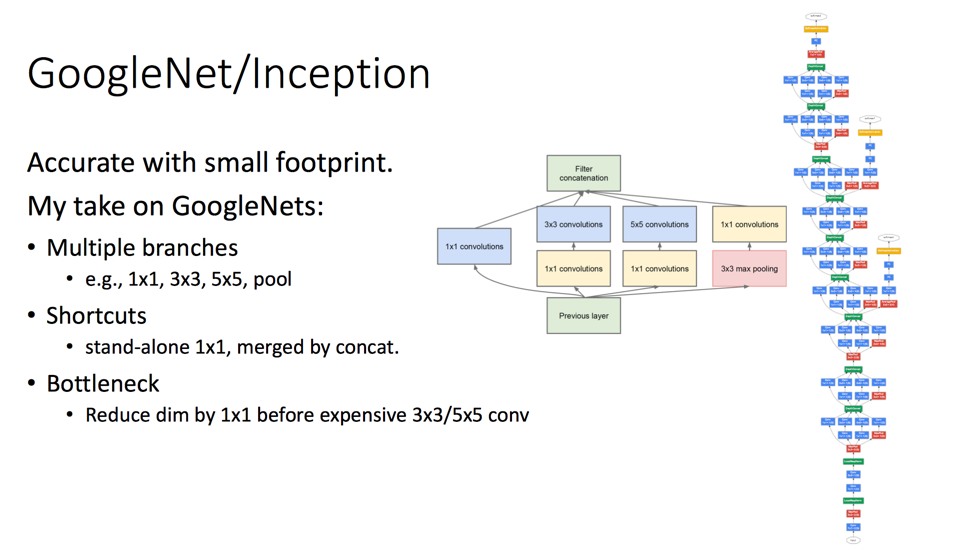
GoogleNet特点有3:
- 多分支
- 捷径:通过1*1的卷积核直接将输出和输出连接
- 瓶颈设计:在进行3*3或者5*5卷积操作前,先通过1*1的卷积降维,有效减少参数
解释下上面1*1的卷积怎么能有效降维,先看一张图:

下面对比下googleNet中的inception:
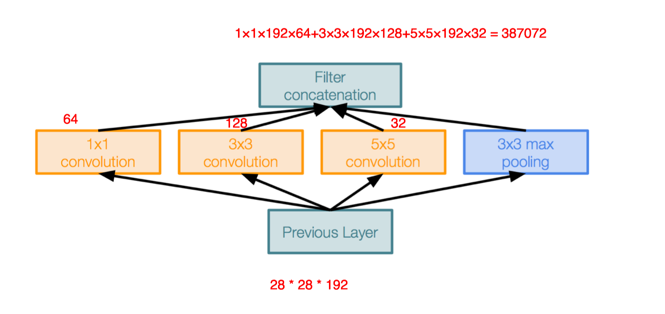

参数大约减少到原来的三分之一。
更具体的可以看知乎问答卷积神经网络中用 1*1 卷积有什么作用或者好处呢?
在上面的GoogleNet中,由于多分枝的特性,Xavier 和 MSRA 方法不能很好的起作用,于是有了Batch Normalization方法。


BN带来的效果非常显著:

BN的使用需要特别注意在test阶段的取值:

ResNet
最后我们来介绍 ResNet。
那我们为什么要追求网络越来越深呢?
- 特征的“等级”随着网络深度的加深而变高
- 极其深的深度使该网络拥有极其强大的表达能力
那是否是深度越深越好呢?答案显然是否定的,我们先来先看一个现象,我们通过简单的叠加3*3的网络,随着网络变深,误差反而变大了。

这个原因就是熟知的梯度弥散/梯度爆炸问题

一个可行的增加网络深度的方法如下:
- 拷贝已经训练好的网络
- 附加上恒等层

上面方法的问题是:随着网络变深时,要使得 W=I,即学习恒等网络 f(x,W)= x 就不那么容易了,于是一个想法就是不去学习恒等,而是去学习W=0,去拟合 f(x,W)+x=x :

那怎么理解拟合残差会比拟合恒等简单呢?
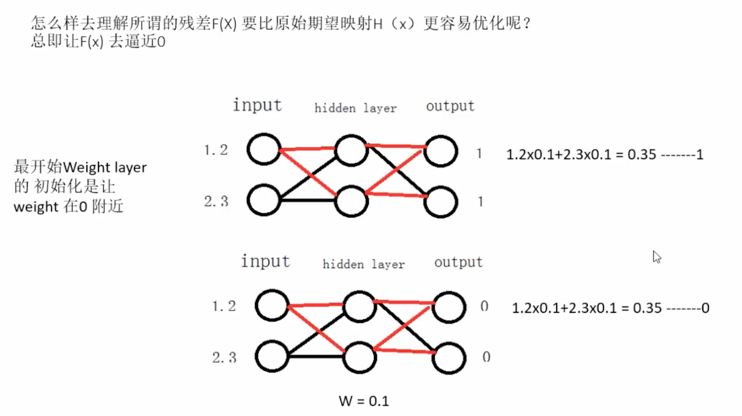
因为网络初始化权重为0附近,这样计算出来的值本身就会接近于0,另外一个是Relu的特性,当小于0的输入,输出都是0:

通过直连的x,能够将梯度回流到任意浅层。
 。
。
总结
本文介绍了LeNet, AlexNet, VGG, GoogleNet;Batch Norm。。只是一个粗浅的介绍,下面一篇将结合斯坦福的CS231n课继续介绍卷积网络。
你的鼓励是我继续写下去的动力,期待我们共同进步。

参考
深度学习入门教学 --Resnet 残差网络介绍
一种新的 ResNet 思路:Learning Identity Mapping with Residual Gates 论文笔记
ResNet 的理解及其 Keras 实现
