@zhuanxu
2018-03-16T03:24:34.000000Z
字数 5289
阅读 2528
ZooKeeper 设计原理
分布式系统
第一步介绍下大数据相关的知识。
大数据技术体系
大数据必备技能
- 编程语言:Java/Python/Scala
- HDFS原理、MapReduce原理及编程、YARN原理、Hadoop集群搭建
- Hive原理、HQL、自定义函数、数据仓库设计
- Spark原理、SparkStreaming编程、SparkSQL
- Kafka原理、配置搭建、JavaAPI
- Flume原理、搭建
- Zookeeper原理、搭建
大数据就业方向


介绍完大数据的一些利好后,我们来看我们迈出的第一步:zookeeper。
zookeeper 概述
什么是zookeeper?
a service for coordinating(协调) processes of distributed applications,是一个重要的基础服务,目标是从更底层提供一个简单、高性能的服务,用来按需构建同步服务
zookeeper(动物管理员),为什么叫这个名字?
zookeeper是Hadoop和Hbase的重要组件,hadoop里面各种组件都是以动物命名的,而zookeeper相当于这动物园的管理员了
zookeeper特点是什么?
提供了一组通用(generic)的,无等待的(wait-free)api,同时提供了两个重要的特性:
- 保证每个客户端请求FIFO
- 每个客户端请求FIFO,所有事务请求线性有序
- 事务请求指能改变状态的写请求
zookeeper 介绍
我们先来回答为什么需要 zookeeper?
在传统的应用程序中,线程、进程的同步,都可以通过操作系统提供的机制来完成。但是在分布式系统中,多个进程之间的同步,操作系统层面就无能为力了。这时候就需要像ZooKeeper这样的分布式的协调(Coordination)服务来协助完成同步。
分布式系统中对于 Coordination 提出了各种各样的需求:
- Configuration:包括静态的操作参数和动态的配置参数
- Group membership:维护组中存活server的信息
- leader election:维护每个server都负责什么
解决上述coordination需求的一种方案是:为每种coordination需求都开发专门的服务。但是我们要知道一个道理:更powerful primitives的实现可以用于less powerful primitives,所以基于这个假设我们在设计coordination的服务上:我们不在实现具体的primitives,而是提供通用(generic)的API来实现满足个性化的primitives,一旦作出这种决策,带来的好处有两点:
coordination kernel帮助我们在不改变服务核心的情况下实现新的primitives
根据应用需求提供更多样化的primitives
在设计ZooKeeper的API的时候,我们移除了阻塞primitives,例如锁,基于的考虑有如下两点:
阻塞primitives会导致处理慢的客户端影响相对较快的客户端
由于请求在处理上依赖于其他客户端的响应和失败的检查,那ZooKeeper本身实现上也会更复杂【一个客户端锁了,必须等待他释放锁。或者由于掉线强制释放锁】
ZooKeeper由于实现了wait-free的数据对象,从而和其他基于阻塞语义(blocking primitives)有了显著的区别,ZooKeeper在组织wait-free的数据对象借鉴了文件系统的思路,将wait-free的数据对象按层级组织起来,不同只是移除了open和close这种阻塞方法。
ZooKeeper实现了pipelined architecture,提高了系统的吞吐。客户端可以同时发出多个请求,异步执行,同时保证请求的FIFO。
为了实现写请求linearizable,实现了Zab协议,一个leader-based atomic broadcast protocol,但是对于读请求,我们不适用Zab,只是本地读,这样能很方便的扩展系统。
在客户端缓存数据可以有效的提高系统性能,但是缓存的数据怎么更新呢?ZooKeeper使用watch机制,不直接操作客户端缓存,这是因为:由于Chubby直接管理客户端缓存,一旦某个客户端处理慢了(可能是挂了),会导致阻塞数据更新。针对这个问题,Chubby 使用租期来解决,一旦某个客户端有错误,不会影响更新操作太长时间,但这也只是确定了影响的上限,无法避免,而ZooKeeper的watches可以彻底解决改问题。
注:Chubby 是什么?
Google的三篇论文影响了很多很多人,也影响了很多很多系统。这三篇论文一直是分布式领域传阅的经典。根据MapReduce,于是我们有了Hadoop;根据GFS,于是我们有了HDFS;根据BigTable,于是我们有了HBase。而在这三篇论文里都提及Google的一个lock service—Chubby,于是我们有了Zookeeper。
总结起来,本文的主要内容是:
Coordination kernel:提出了wait-free的 Coordination service,能够保证 relaxed consistency,为其他同步技术提供基本原语。
Coordination recipes:通过 ZooKeeper 可以实现high level的同步原语,包括了强同步和强一致的同步(zookeeper本身提供的是wait-free的同步原语)
Experience with Coordination:心得,具体案例和评测
Zookeeper服务
ZooKeeper提供了client library来访问服务,client library主要做两件事:
管理client和ZooKeeper之间的网络连接
提供ZooKeeper的api
术语:
client:a user of the ZooKeeper service
server:a process providing the ZooKeeper service
znode:an in-memory data node in the ZooKeeper data
data tree:像文件系统一样按层级组织的命名空间
update,write:改变data tree状态的操作
session:client和ZooKeeper之间的网络连接
Service overview
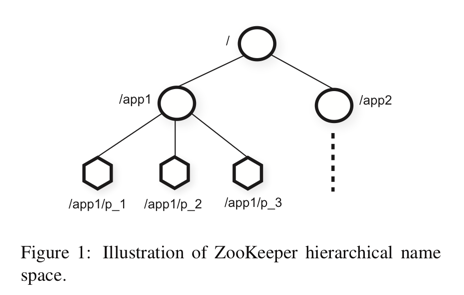
ZooKeeper给客户端提供了znode的抽象,客户端通过api来操作znode中存储的数据,znode的地址类似文件系统中的path,像上图中节点p_1就通过路径/app1/p_1来访问,客户端可以创建两种znode:
Regular: 需要客户端显式的创建和删除
ephemeral: 客户端创建,也可以删除,也可以当会话终止时候让系统自动删除
除此之外,创建的时候可以带sequential的flag,此时创建znode p,则会自动带上一个下标n,n是一个单调递增的数,并且满足seq(parent)>= max(children),意思是新建的node,其下标总是大于其父节点下面创建过的所有node的最大n。
watches怎么创建?
读请求上设置watch参数
watches作用?
客户端不必轮询服务器获取数据,当数据发生改变的时候,通知客户端
watches什么时候失效?
当数据发生改变通知客户端后
session关闭
watches通知了什么?
watches通知只是告知状态改变了,但是不提供改变的数据
数据模型
如图一所示:类似于文件系统,但是znodes不是用来做数据存储的,而是用来跟实际的应用映射的,像图1中,有两个应用app1,app2,app1下面实现了个简单的group membership protocol。
虽然znode设计之初不是为了存储数据,但是也可以存储一些meta-data或者configuration信息,同时znode本身会存储time stamps 和 version counters等元信息
会话(sessions)
代表client和ZooKeeper之间的网络连接,作用有:
server端可以通过sessions超时来判断客户端是否健在
客户端可以通过sessions观察其操作的一连串变化
sessions使得client的连接可以从一个server透明的转移到另一个server,因此可以持续的提供client服务
Client API
create(path, data, flags)delete(path, version) //if znode.version = version, then deleteexists(path, watch)getData(path, watch)setData(path, data, version) //if znode.version = version, then updategetChildren(path, watch)sync()
以上所有操作有syn和asyn两个版本。ZooKeeper的客户端保证所有写操作是完全有序的,写操作后其他client的写能看到。
在访问的znode的时候都是通过完整的path来访问的,而不是像文件系统那样通过open,close来操作文件句柄,大大简化了servers端的复杂度,不需要保存额外的信息了。
ZooKeeper guarantees
Linearizable writes:所有写请求有序
FIFO client order:每个客户端请求FIFO
考虑场景:leader election
当新的leader产生的时候,需要改变大量的配置后,通知其他processes,需要满足两个要求:
新leader改变配置的时候,其他processes不能读取不完整的配置
新leader在改变配置过程中挂了,其他processes不能使用这个不完整的配置
通过锁能满足第一个需求,zookeeper的实现:
新leader改变前删除 ready znode
改变配置(通过pipeline加速)
新建 ready znode
因为写顺序的保证,其他客户端能看到ready的时候,肯定新配置也生效了,如果在更改配置中leader挂了,就不会有ready。
上面仍然有一个问题:如果process先是看到了ready,此时在读取之前,leader删除了ready,开始更改配置,那process会读取到不完整的配置了,怎么解决呢?
这是通过对通知的顺序性保证解决的,具体来说就是:如果客户端在watch一个Ready改变事件,那只有当配置改变后,才会通知client Ready有变化的事件(不是Ready删除就通知事件),这就保证了客户端收到通知,肯定是配置变化了。
另一个可能的问题是:客户端之间除了ZooKeeper之外,还有别的通信通道,场景是:
A和B在ZooKeeper上有共享数据,A改变数据后,通过其他通信手段告诉B数据改变了,此时B去读取数据,可能会读取不到改变的数据,因为ZooKeeper集群可能存在的主从延迟,解决方案是:B读之前先发个sync请求,类似于文件系统中的flush操作,让pending的写请求真正执行。
除此之外,ZooKeeper还有两个保证:
高可用,只要大多数机器还存活,就能提供服务
数据可靠:只要ZooKeeper回复写成功,则数据最终一定会存在在服务器上
ZooKeeper 实现
作为一个 coordination,非常重要的就是高可用和数据可靠性,我们来看下如何实现的。
先来看数据的写入过程:
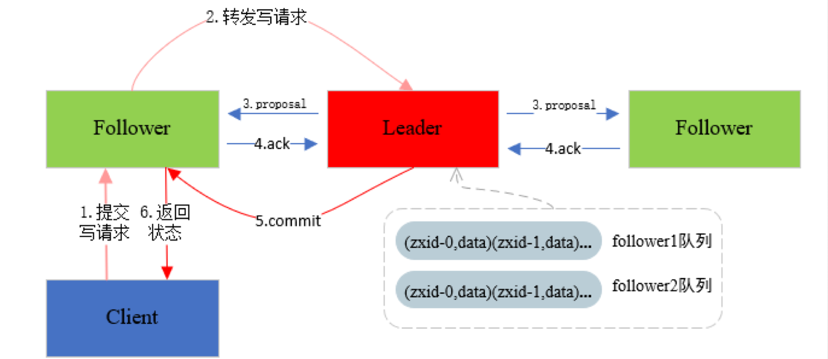
- 客户端提交写请求
- follower写请求交给leader,由leader作为整个事务的协调者,负责整个写入过程
- leader在整个事务中是通过ZAB算法保证了数据的最终一致,由leader发起事务提议(重点是一个zxid,全局递增的一个id生成器,通过zxid来达到全局时钟的效果)
- follower接收到leader发起的事务提议,返回收到(所有请求都是在一个FIFO的队列中)
- leader在收到follower的回复后,提交本次事务
- 客户端收到回复
此处ZAB算法是保证数据一致性的关键,我们在raft那再讲。
总结
本文主要是介绍了zookeeper是什么:一个开源的针对大型分布式系统的可靠协调系统;设计目标是:将复杂且容易出错的分布式式一致性服务封装起来,构成一个高效可靠的原语集,并以简单易用的接口提供给用户使用,其特性有:
- 最终一致性
- 顺序性:从同一个客户端发起的事务请求,最终会严格地按照其发送顺序被应用到Zookeeper中。
- 可靠性:一旦服务器成功的应用一个事务,并完成了客户端的响应,那么该事务所引起的服务端状态变更将会被一直保留下去。
- 实时性:Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
- 原子性:一次数据更新要么成功,要么失败。
- 单一视图:无论客户端连接到哪个服务器,看到的数据模型都是一致的。
其中一致性算法将会在raft中讲解。
你的鼓励是我继续写下去的动力,期待我们共同进步。

