@zhuanxu
2018-01-24T03:41:15.000000Z
字数 2886
阅读 10721
贝叶斯统计:Gibbs sampling 原理到实践
贝叶斯 lda gibbs
经过前面两篇文章,我们终于来到了Gibbs samping,为什么我这么兴奋呢?因为我当初看贝叶斯推断就是因为LDA模型,里面用到了Gibbs sampling的方法来解参数问题。
好了下面开始介绍Gibbs 采样。
Gibbs采样
前面一篇文章我介绍了细致平稳条件,即:
Gibbs采样的算法如下:

我们来证明Gibbs采样算法也满足细致平稳条件。
假设x = x 1 , . . . , x D ,当我们采样第k个数据的时候,
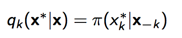
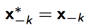
此时我们的接受率为:
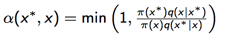
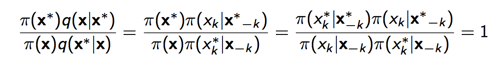
上面公式一个关键的部分是:
,
带入就可以得到1,即gibbs采样是一定接受的采样。
下面我们照惯例还是来一个例子。
例子
假设有我们有数据x1,x2...xN,其中1-n的数服从一个泊松分布,n+1-N的数服从另一个泊松分布。
而泊松分布的参数服从Gamma分布,我们总结下目前的先验假设:

此时后验概率是:
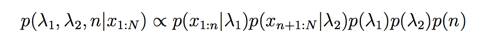
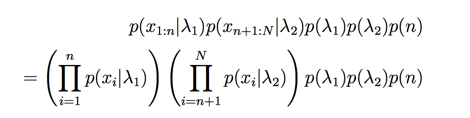
我们下一步开始我们的采样,先计算下logP:
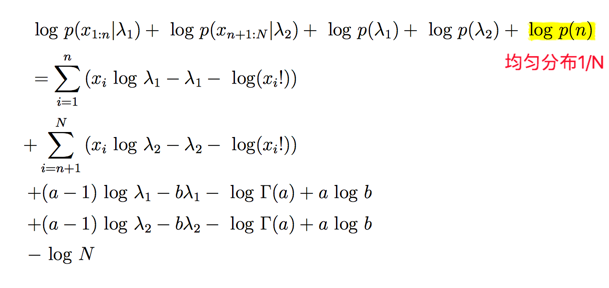
接着来采样

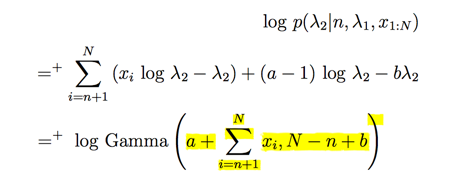
我们此处只取了跟当前采样参数有关的项,因为其他都是一些常数,作用只是将概率分布归一化,不影响采样。
此处都服从Gamma分布。
最后是n:
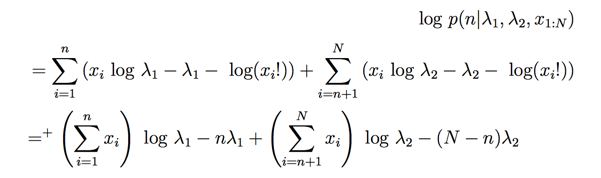
n没有显示的分布信息,但是我们简单将其认为是一个多项分布。
下面是关键Python代码:

完整代码见Gibbs
采样后输出如下图:
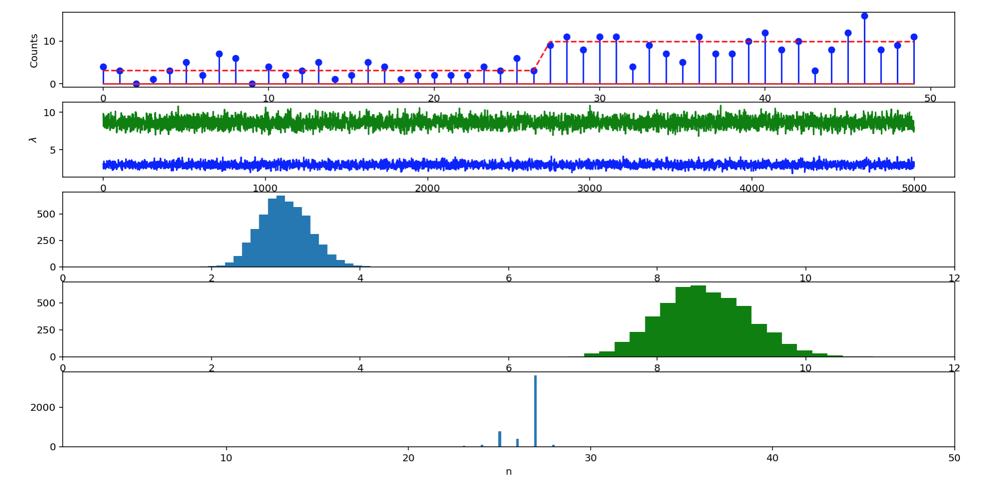
LDA
下面我们来最激动人心的LDA模型,看怎么用Gibbs 采样来解。
先看LDA的模型:
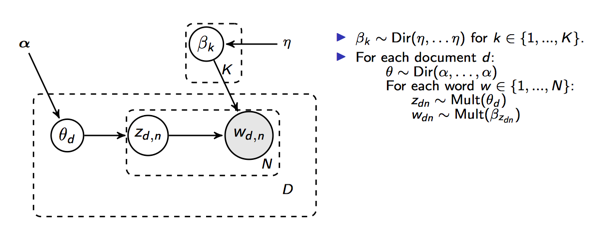
整个过程可以描述为
- 对于文档d,从分布中采样出,即文档d的主题分布
- 对于文档的每个词从多项分布中采样出主题k,即
- 对于主题k,从中采样出,即主题k的词分布
- 对于每个词,从主题分布中采样出具体的单词t
上面整个模型中,模型参数有:
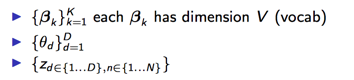
为了做Gibbs采样,我们先看这几个参数的联合分布。
上面公式中是多项分布,而是Dir分布,我们知道Dir分布和多项分布是共轭分布,因此后验分布比较容易写出来。
下面我们开始计算每个参数的概率,主要是计算下面3个概率:
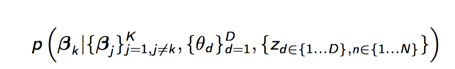
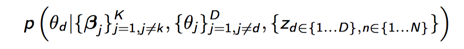

先来计算第一个主题的概率分布:
其中表示第m篇文档中,属于每个主题的词个数。
接着计算每个主题的词分布
其中第m篇文档中属于k个主题的,每个单词的数量,共(1-V)个单词。
最后来估算每个词的主题。
我们可以看到是一个多项分布,每一项的概率都是,而他们本身也是需要从Dir分布中采样出来的,一个自然的想法就是我们可以用估计值来代替,根据Dir分布我们能够很方便的计算出概率来。
此处需要的数学基础可以看主题模型:LDA 数学基础。
里面一个点是Dir分布和其数学期望
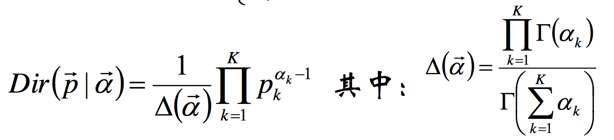
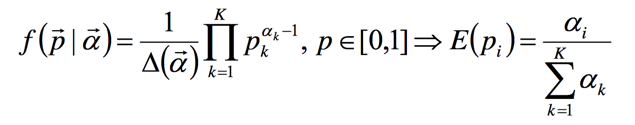
我们上面在Gibbs采样中计算分别采样都可以用Dir分布的的期望来作为新的参数值。
编码
介绍完数学基础后,我么就能来看如何实现了,下面是一个伪代码。
for m in range(D): // 遍历每篇文档for n in range(W[m]): // 遍历每篇文档的单词w = W[m][n] // 单词 wk = z[m][n] // 主题 knd[m,k] -= 1 // 第m篇文档第k个主题的词数目ndsum[m, 0] -= 1 // 第m篇文档总的主题词数目sum(nd[m])nw[k, w] -= 1 // 第k个topic中产生w的数目nwsum[k, 0] -= 1 // 第k个topic总共产生的w数目# 计算theta值,Dir分布的期望theta_p = (nd[m] + alpha) / (ndsum[m, 0] + sum_alpha)# 计算beta的期望值beta_p = (nw[:, w] + beta[w]) / (nwsum[:, 0] + sum_beta)# multi_p为多项式分布的参数multi_p = theta_p * beta_p# 多项式采样新的kk = mul_sample(multi_p)nd[m,k] += 1 // 第m篇文档第k个主题的词数目ndsum[m, 0] += 1 // 第m篇文档总的主题词数目sum(nd[m])nw[k, w] += 1 // 第k个topic中产生w的数目nwsum[k, 0] += 1 // 第k个topic总共产生的w数目z[m][n] = k// 更新主题
完整的代码可以见玩点高级的 -- 带你入门 Topic 模型 LDA(小改进 + 附源码)
pymc3 实现
下面我们再来用pymc3来实现下。

可以说pymc3写出来的代码真是简洁。but。就是太慢了,完整的代码可以看gibbs-lda。
总结
本文介绍了mh算法的特例Gibbs采样,并且给出了证明为什么Gibbs采样work,最后我们用Gibbs采样来解决了LDA的参数估计问题。
你的鼓励是我继续写下去的动力,期待我们共同进步。

