@lancelot-vim
2016-05-10T09:39:46.000000Z
字数 3997
阅读 1977
主成分分析和判别函数
模式分类
@author lancelot-vim
主成分分析
考虑n个d维的样本,如何使用一个d维的向量,来代表这n个样本,确切说,我们希望这n个样本和它的代表之间的距离的和越小越好,特别的,使用欧几里得距离来定义误差函数:
我们的目标是寻找,使得最小,很容易可以得到:
实际上,样本均值是样本数据集的零维表达,它表达了样本之间的相似,但不能表达样本的差异性。过样本均值做一条直线,并将所有的样本向这条直线上做投影,那么我们能得到代表所有样本的一维向量,若表示这条直线的单位向量,那么直线方程为,其中代表样本均值
其中是一个实数,表示某点离开的距离,我们用来表示,可得:
由于,通过对求偏导,令结果为0有:,直观上表示为点到直线的距离
这就引出一个问题,什么方向的直线才是最好的直线,对此定义"散布矩阵"(scatter matrix)
将上式代入,有:
因此,我们需要找单位向量,让最大,根据拉格朗日乘数法可得:,最终我们可以得到新的平方判决函数:
其中:为散布矩阵的d'个的最大特征值所对应的特征向量
判别方法
PCA(主成分分析)对于代表或者说表达数据样本特别有效,但是可能对分类并没有什么作用,比如对于字母Q和O,很可能PCA会Q的尾巴丢掉,总的来说PCA方法是用来寻找有效主轴方向的方法,而判别分类方法(discriminant analysis)使用来寻找有效分类方向的方法。
Fisher 线性判别分析
考虑把d维空间的数据投影到一条直线上去,希望不同类别之间的距离尽量远,相同类别尽量紧凑,我们希望找到这样一条直线。假设我们有一组d维的样本,它们分别属于两个不同的类别,其中大小为的样本子集属于类别,大小为的样本子集属于类别,如果对中的各个成分做线性组合,就能的到一个內积,结果为标量 ,这样,n个样本就能的到n个结果,相应属于。
从几何上来说,假设,那么每个就是把向方向为的直线作投影,本身的范数仅仅只是乘以了一个倍数,并不重要,但方向很重要。假如在d维空间上形成两个显著分开的聚类,那么我们希望数据在直线的投影是分来的。
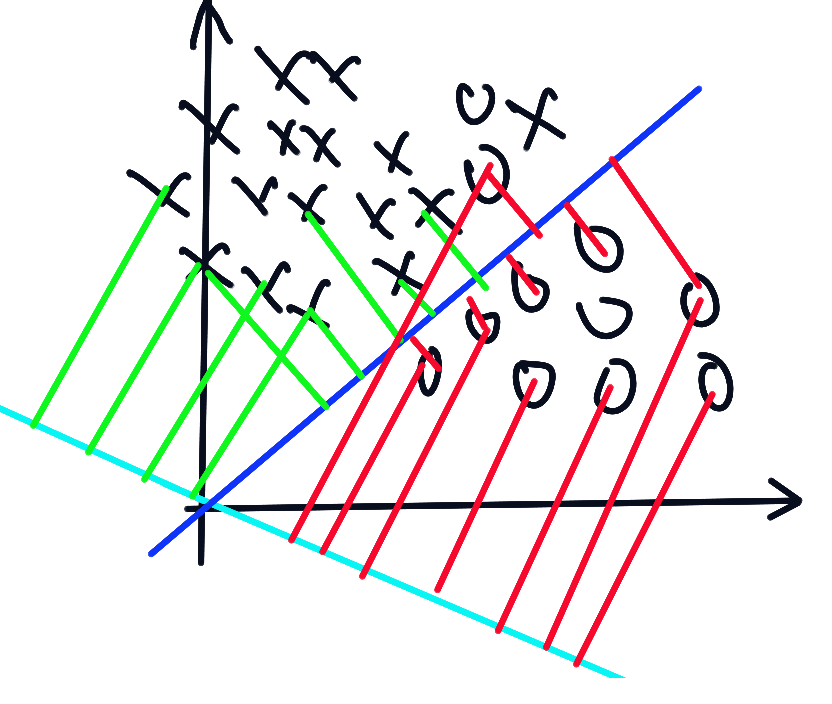
一个很好的用来确定最佳分类方向的方法是度量两个类别样本均值的差,加入为d为样本的均值,那么投影后的点为:
因此投影之后的样本差为:
由于可以增加的幅值,使得距离超级大,但是投影样本均值的差却是相对的,所以我们需要定义类别的类内散布:,于是就是全部数据总体方差的估计,而称作投影样本的总类内散布
由此Fisher线性可分性准则要求在投影下,准测函数尽可能大
要使最大化的能够使投影后的两类最大程度的分开,我们还需要一个阈值准则来确定最终的分类器。
为了把写成的表达式,定义类内散布矩阵,和总散布矩阵
可得:
- 各散度的和:
- 各散度的差:
我们把称为总类内散度矩阵。它与全部样本的样本写方差矩阵成正比,并且是对称且半正定的。当时,通常非奇异。类似的,被称为总类间散步矩阵,也是对称半正定的,但由于是两个向量的外积,所以秩至多等于1.特别的,对于任意的,的方向沿着。
若使用来表达,准则函数可以写为:
这个表达式在数学物理中经常被使用,同城被称为广义瑞利商,容易证明,使得准则函数最大化的满足
这是一个广义特征值问题,可以理解成在的极值处,发生微小扰动,并不会使得的分子分母比例发生太大变化。假如是非奇异的,我们就能把该问题化为通常的特征值问题:
多重判别分析
对于c-类问题,把Fisher线性判别准则作推广,就需要c-1个判别函数,也就是说投影问题实际上是从d维空间向c-1维空间作投影, 并且假设,类内散布矩阵推广是明显的:,其中
对的推广不是那么容易,假设我们定义总体均值为,总体散布矩阵,有:
由于,总散布矩阵就是类内散布矩阵和内间散布矩阵的和,即,所以自然而然定义类间散布矩阵为:
从d维空间向c-1维空间的投影是通过c-1个分类方程进行的:,如果我们吧看作一个c-1维的方程组,可以表达为简单的矩阵方程
对原始样本进行投影后,的到新的样本,这些新得到的样本本身又具有它们自己的均值向量和散步矩阵,由此:
易证:
最终,我们的到了判别函数:
要使得最大化,需使矩阵的列向量为特征值所对应的特征向量
下一篇: 隐马尔可夫模型
