@lancelot-vim
2016-05-30T08:10:09.000000Z
字数 4624
阅读 2306
概述,贝叶斯策略,最大似然估计
模式分类
@author lancelot-vim
绪论
宽度和数量直方图:
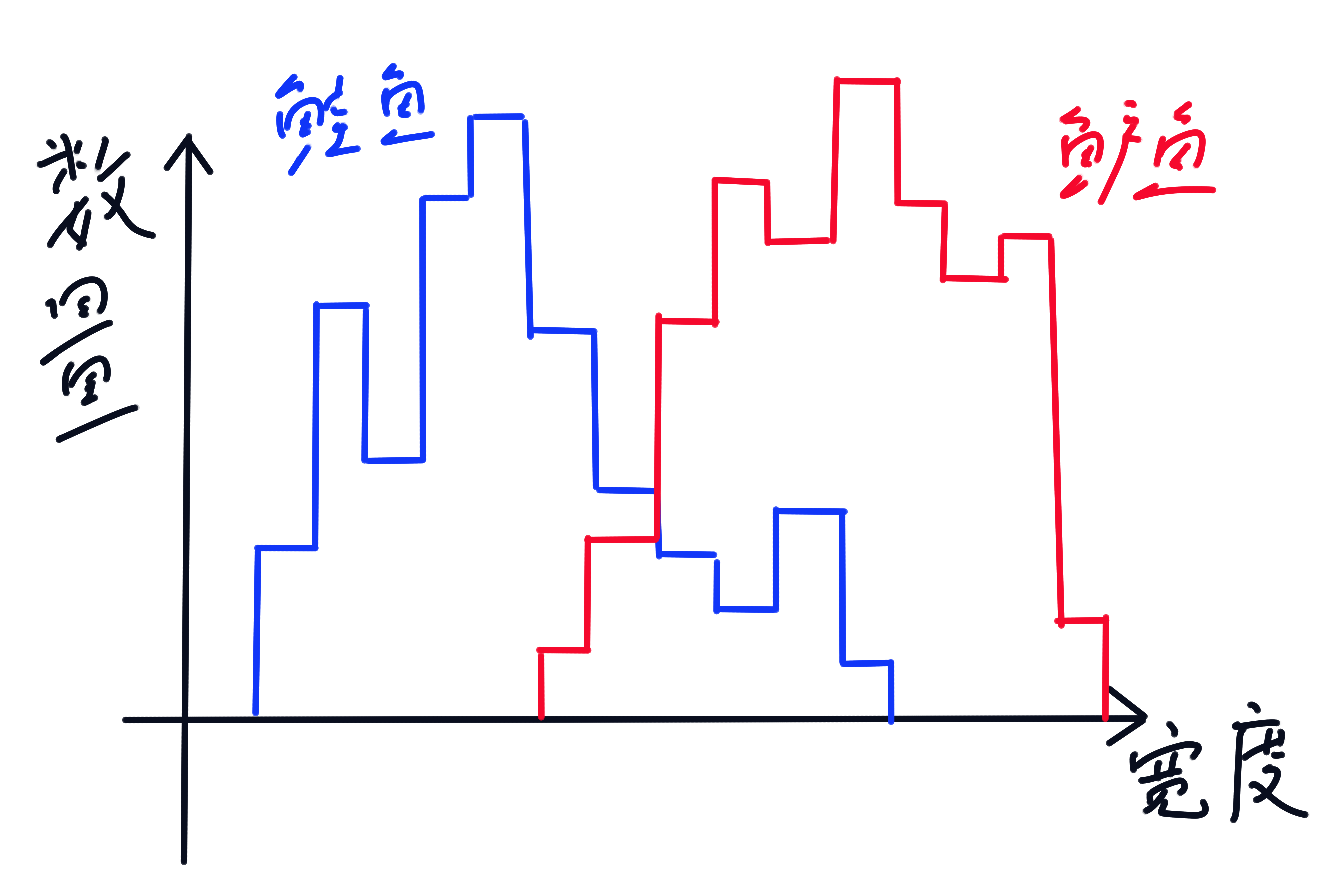
光泽度和数量直方图:
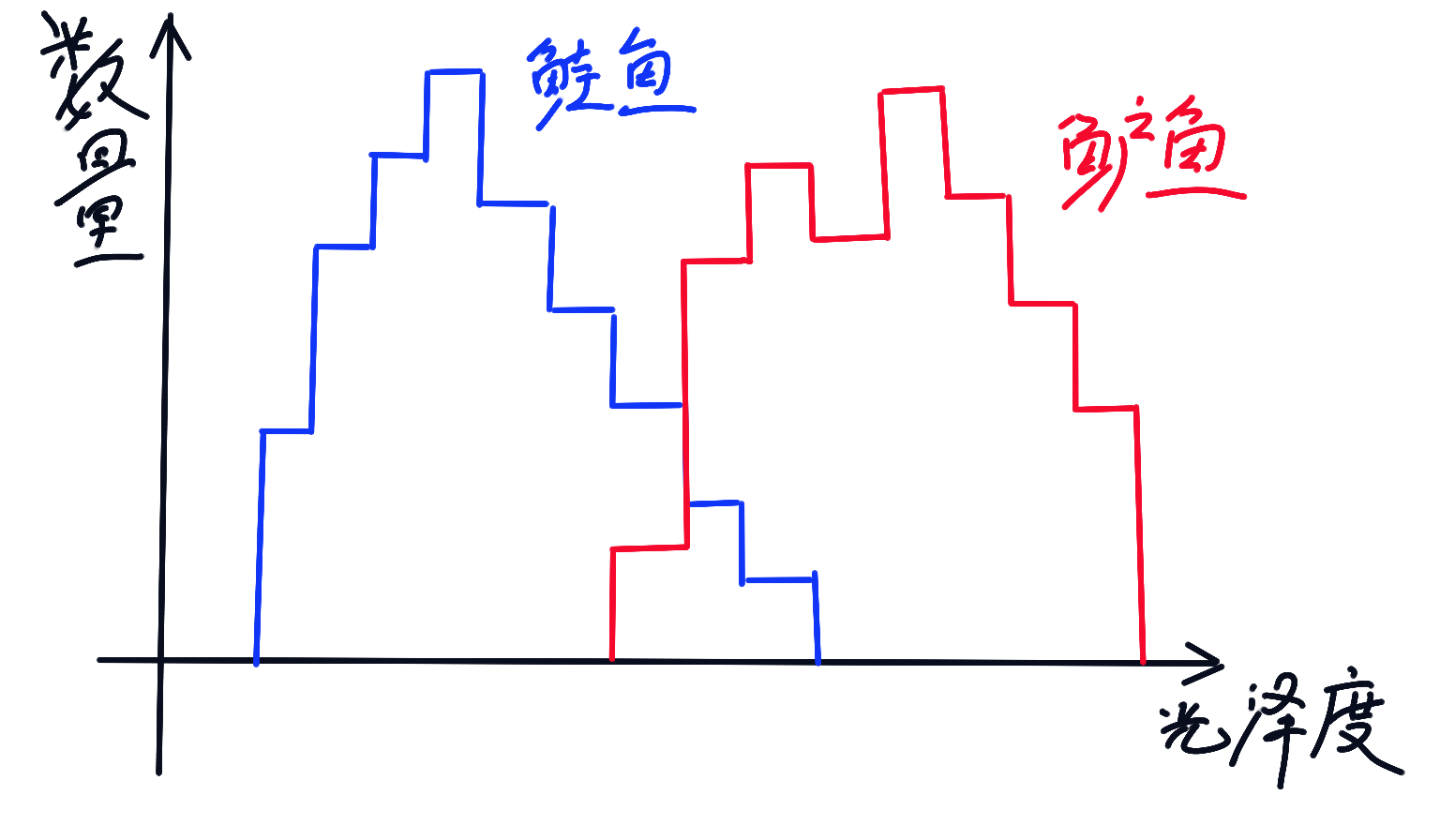
宽度-光泽度联合分类图:
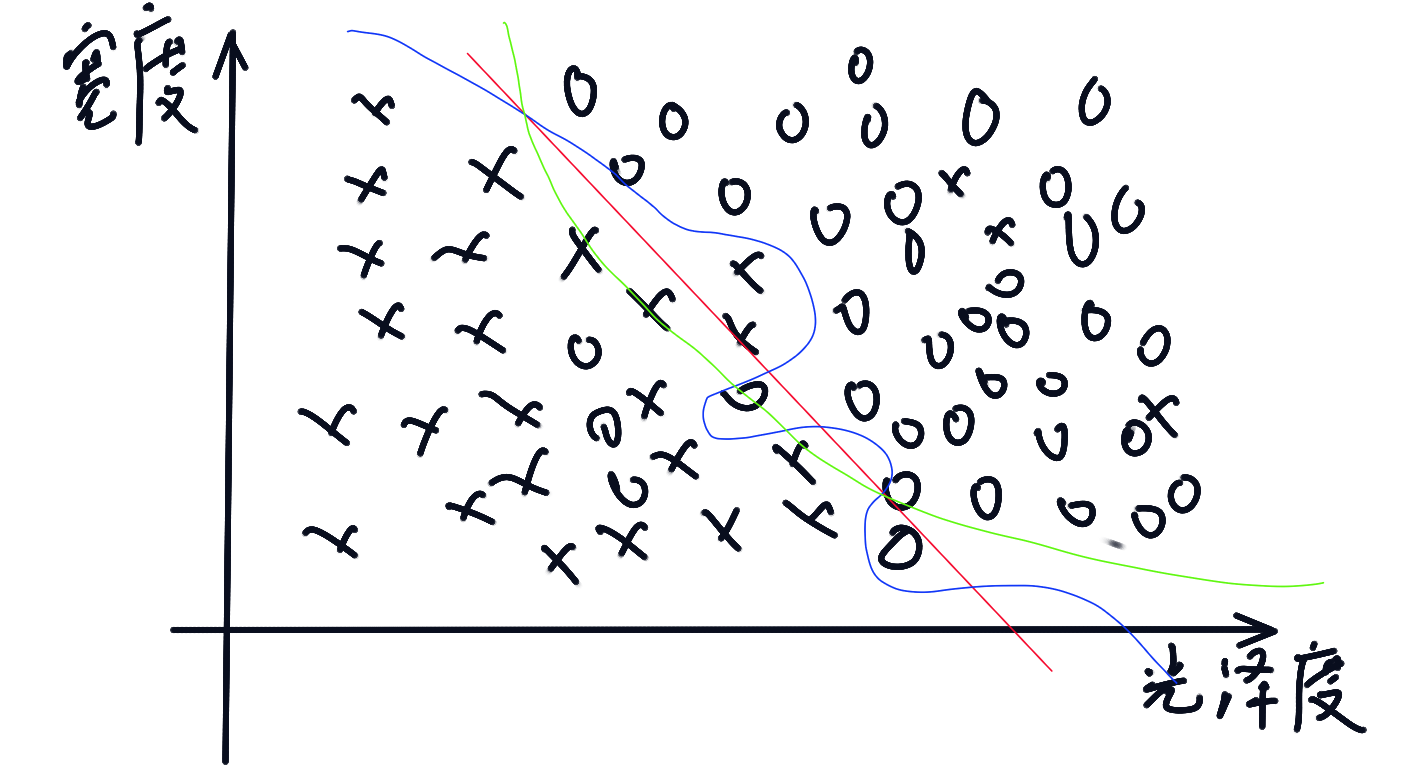
简单归纳:
- 从单一特征得到的分类一般不强
- 将单一特征组合起来成多特征分类能得到更强的分类器
- 分类器模型简单(如图中红色线条)会比较弱,分类器太强(如图中蓝色线条)可能会过分类
- 以上问题,可能会存在如果鲈鱼分错,可能不会有太大的问题,但反之可能造成很大的影响
问题:
- 如何选择特征
- 如何选择分类器
- 分类之后如何采取行动
处理方案流程图:
贝叶斯决策论
引言
条件概率密度与贝叶斯公式
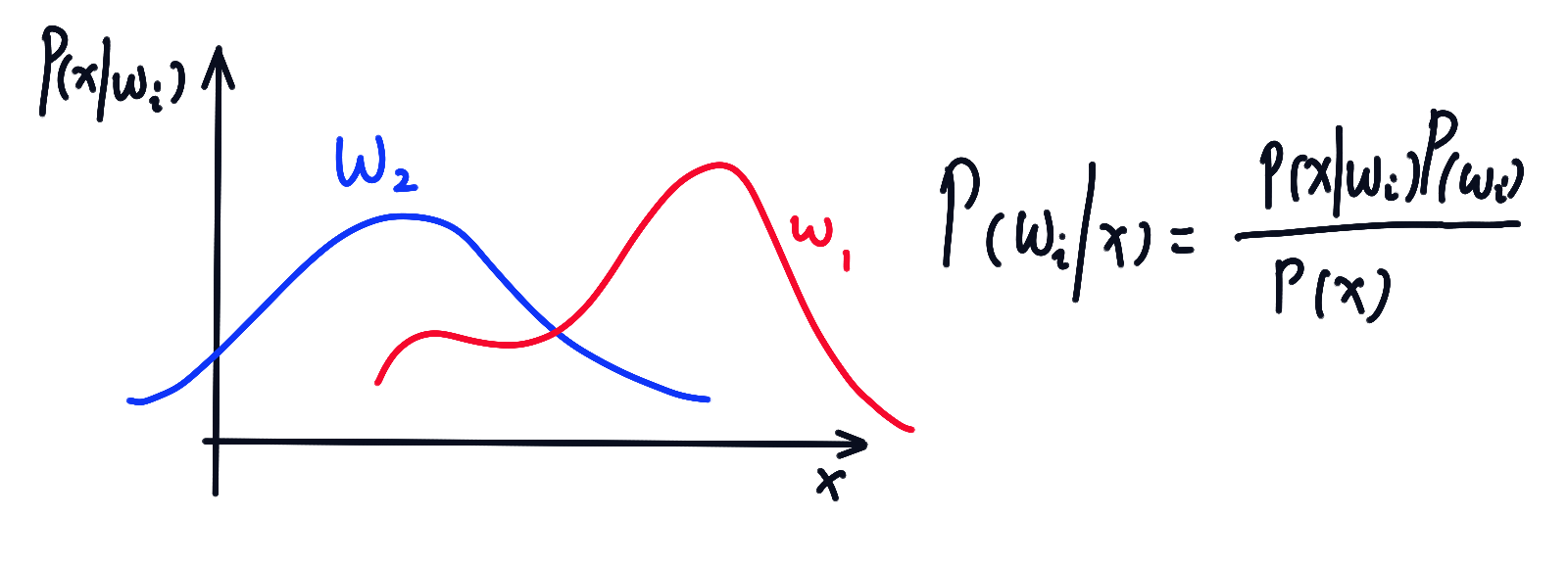
, 时的后验概率:
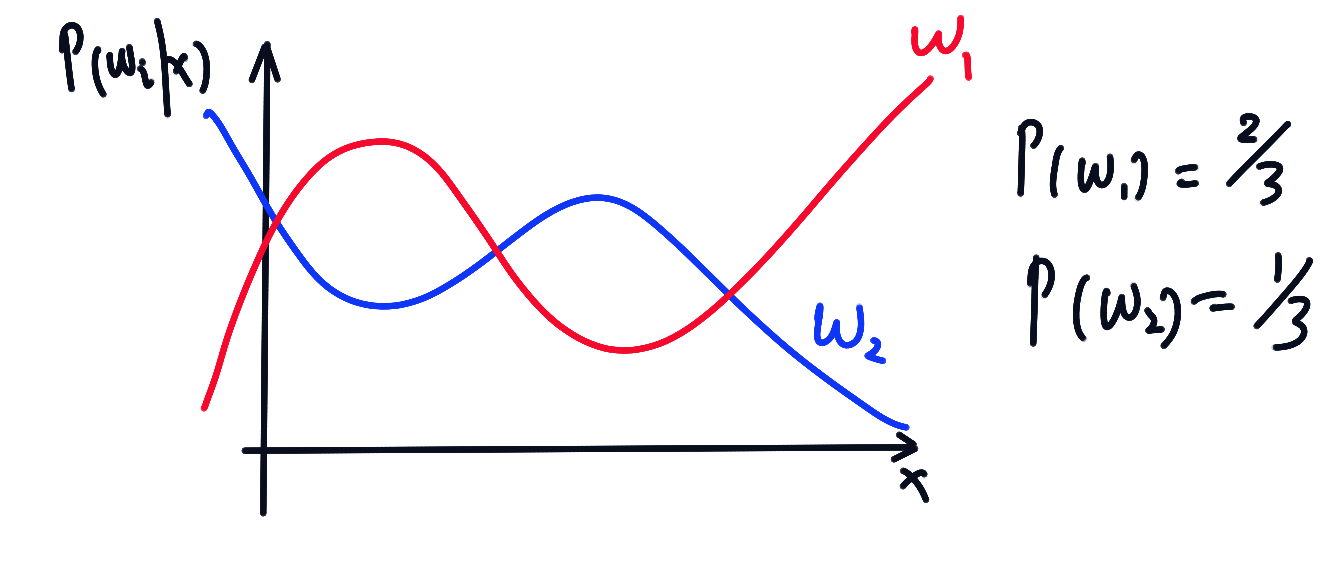
误差定义:
总误差为:
对 , 若 尽量小, 那么 就尽量小, 所以令
连续特征的贝叶斯决策论
- 允许使用多于一个的特征
- 允许使用两种类别以上的情形
- 允许有其他行为而不仅仅只是判定类别
- 通过引入一个更一般的损失函数来代替误差概率
以下4个约定:
1. 表示c个类别(class)
2. 表示a中行动(action)
3. 表示类别为,采取行为的损失
4. 表示d维的特征
根据贝叶斯公式:
若观测到,采取行为,则损失为:
总损失为:
若选择使得:对每个尽可能小,则风险函数最小化
对于二分类问题
约定:
1. 对应于
2. 对应于
3. 表示损失
则损失函数方程为:
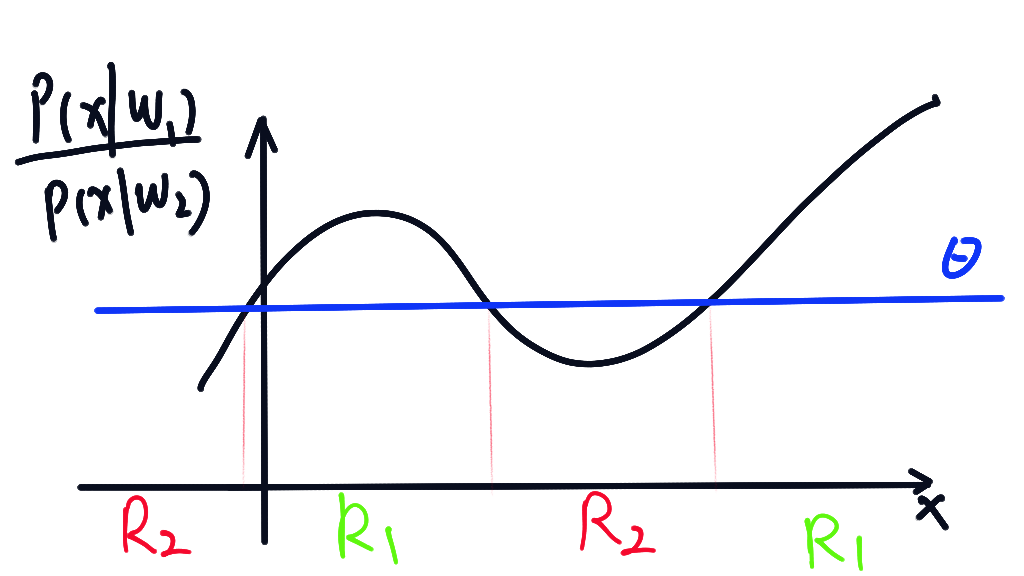
若, 即 ,将该类别判为
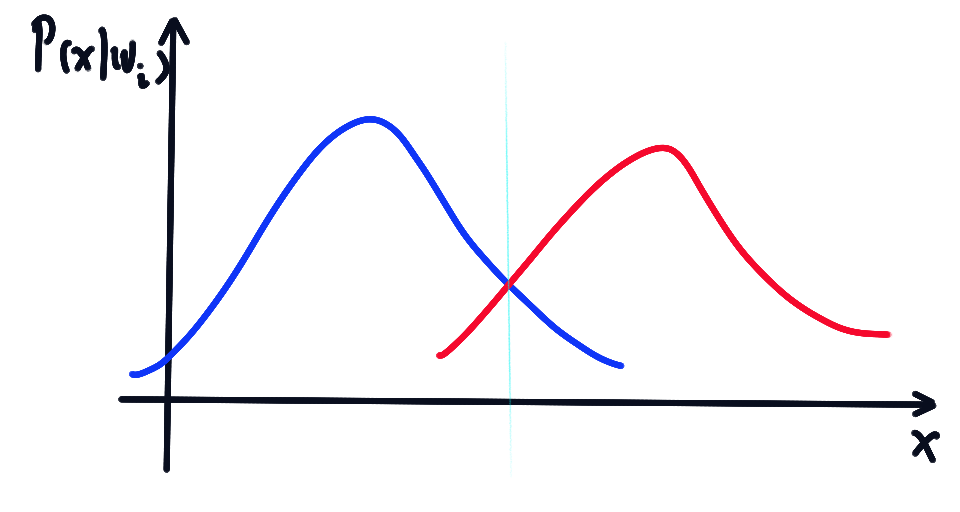
若且 , 将该类别判为, 如下图
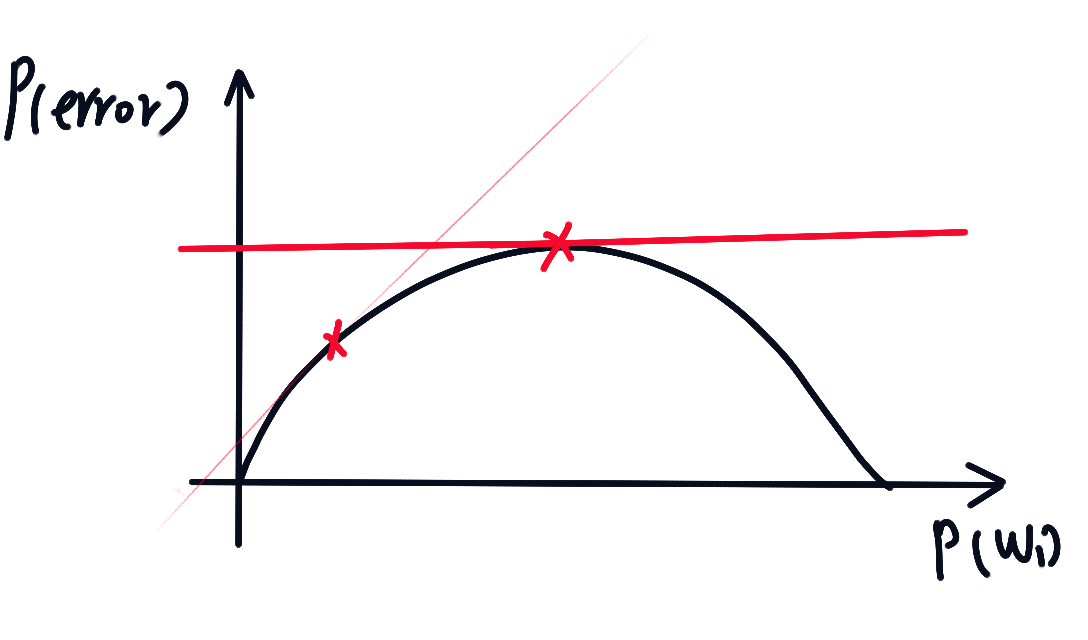
极小化极大原则
总损失:
由于, 得:
令
可得,, 以及极小化极大误差:
极小化极大描述图:
分类器、判别函数和判定面
定义:
一般我们认为对于所有的,有,则认为该特征向量的类型为
一般流程如下图:
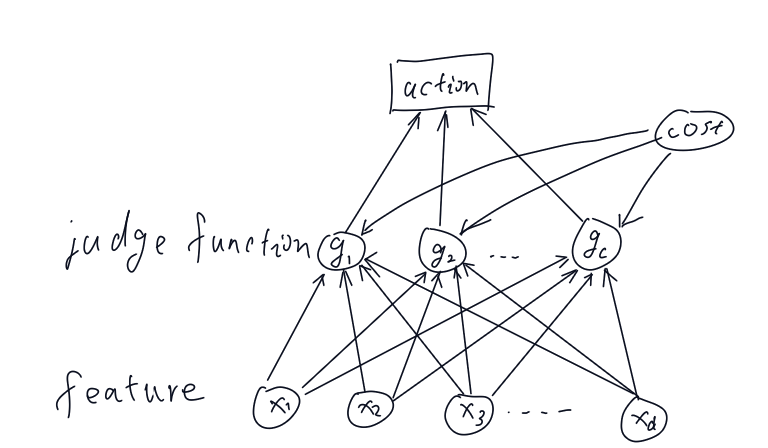
一般判决函数选择:
正态判别函数
对于正态分布,通常我们取判别函数为,根据正态分布密度函数可得:
情况1 :
对此情况,, ,由此简化判别函数为:
显然对所有的i是相等的,所以可以简化为线性判别函数:
其中,
对于,令,得:,其中
由可见,判别面为数据的法平面,当时,正好是中垂面
情况2 :
判别函数可重写为:
由同样的方法可得:
由可见,判别面为数据马氏距离的法平面,当时,正好是马氏距离中垂面
最大似然估计
假设每个分类有数据集的样本分别都是根据独立同分布的抽取的,概率分布形式已知,但参数未定,约定未知参数符号为,那么可以写出最大似然函数:
我们认为发生的事情为是概率最大的事,所以目标为求得使得最大的, 一般情况,为了计算方便,我们使用似然函数的对数函数即
高斯解
- 未知:
- 未知:
