@huanghaian
2020-12-02T06:22:07.000000Z
字数 12434
阅读 2180
Sparse R-CNN:简化版fast rcnn
transformer
0 摘要
论文名称:Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
论文地址:https://msc.berkeley.edu/research/autonomous-vehicle/sparse_rcnn.pdf
开源代码:https://github.com/PeizeSun/SparseR-CNN
原作者解读:https://zhuanlan.zhihu.com/p/310058362
知乎问答:https://www.zhihu.com/question/431890092/answer/1593944329
ss区域提取算法加上fast rcnn算法,是faster rcnn算法的前身,由于其巨大计算量以及无法端到端训练,故而提出区域提取网络RPN加上fast rcnn的faster rcnn算法。但是你是否想过去掉RPN,仅仅在fast rcnn算法基础上额外引入点新技术就可以实现更简洁、更高精度的替代算法? 本文借鉴了最新提出的detr算法核心思想,从而实现了上述想法。
Sparse R-CNN极其简单,不需要设置烦人的密集anchor,不需要RPN、不需要复杂后处理和nms,不需要小心的平衡RPN和fast rcnn训练过程,也没有难调的超参,和detr一样完美。如果说detr最大的缺点是收敛速度慢,推理内存占用多,那么Sparse R-CNN是不存在上述缺点的。
Sparse R-CNN之所以如此简洁高效,我觉得离不开前人relation network和detr的贡献,具体来说其创新点包括:
- 不需要RPN,该组件由可学习的proposal boxes代替
- 不需要复杂后处理和nms,因为其参考detr里面的点集预测做法
- 不需要设置anchor,是因为已经没有RPN模块了,自然不需要设置Anchor
- proposal boxes提供的仅仅是粗糙的roi信息,不足以表征物体属性例如姿态和形状等等,故额外引入了可学习的proposal feature,作用类似于detr里面的object query
- 为了更好的提取每个bbox实例的特征,对roi特征和proposal feature引入了交叉注意力模块(论文中叫做可交互模块)
- 引入了类似cascade rcnn的级联refine思想,提高整体性能
对上述做法的思想不了解的,不用着急,后面会一一详述,在阅读本文前最好先阅读下relation network和detr论文。
由于文章写的比较快,如果有不对的地方,请见谅!
1 前置基础
为了方便后续理解,这里先简要描述下前置算法。
1.1 fast rcnn
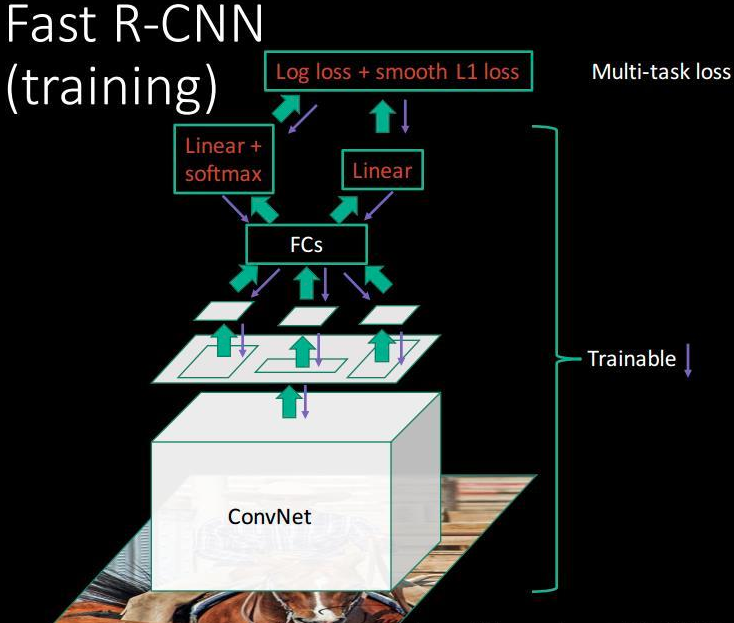
其简要流程为:
1. 对原始图片使用selective search算法得到约2k候选roi
2. 将任意大小的图片输入CNN,得到输出特征图
3. 在特征图中找到每一个roi对应的特征框,通过roipool将每个特征框池化到统一大小
4. 统一大小的特征框经过全连接层得到固定大小的特征向量,分别进行softmax分类和bbox回归
可以看出其是采用selective search启发式算法提前把roi提取出来了。
1.2 faster rcnn
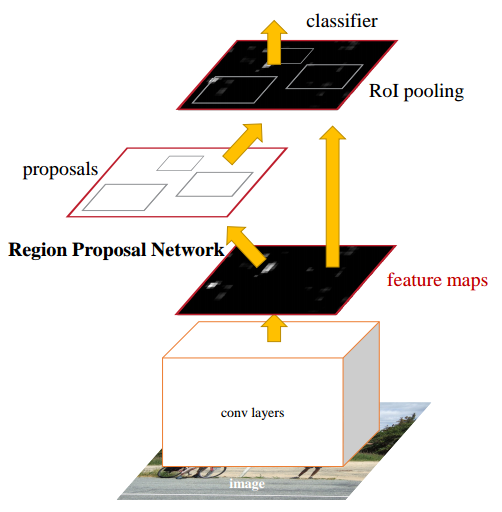
fastrcnn的做法不是一个完全端到端的做法,比较麻烦,性能也一般,故faster rcnn提出采用可学习的RPN网络代替SS算法,从而使得整个算法可以端到端训练、性能有大幅提高。faster rcnn虽好,但是其复杂度太高了,超参非常多。
1.3 relation
relation论文全名是Relation Networks for Object Detection,是微软将nlp里面的transformer思想引入到目标检测中从而加强物体和物体之间的关系,理论和实验表明确实有性能提升。
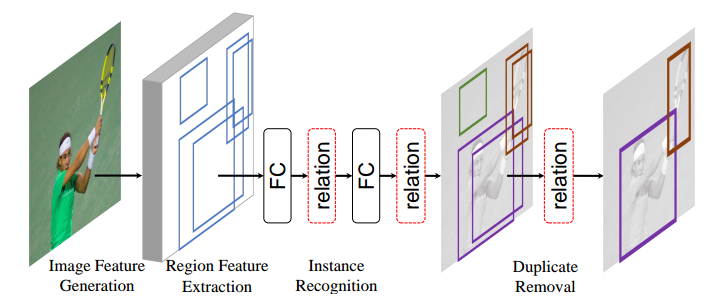
其所提relation模块应用于roipool提取特征然后经过fc层后,具体逻辑是:
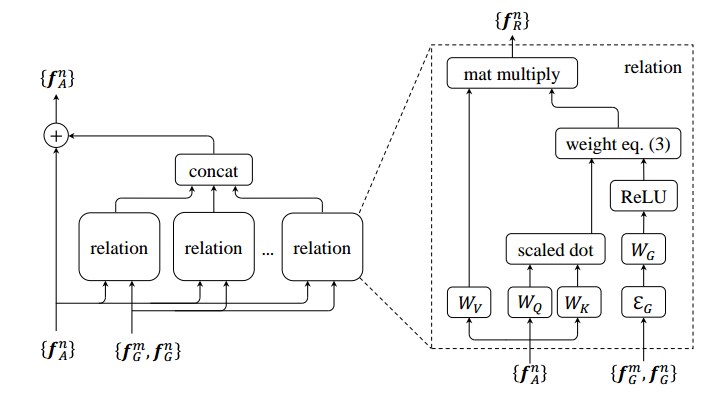
如果熟悉注意力attention的人可以发现如果把输入这条分支去掉,那就是标准的attention。f_A其实就是前一层fc的输出,论文中称为外观特征,而f_G是几何特征,具体是RPN阶段输出的roi坐标,其维度是4,然后先将第m个实例和第n个实例计算相关性,最后进行升维嵌入作为额外的注意力信息,和外观特征注意力加权平均,得到输出。
通过加入物体和物体的几何特征和外观的自注意力机制来建模物体和物体的关系。relation是即插即用模块,可以随意插入提升性能。
当然论文后面还将relation模块应用于代替nms,可以认为是可学习的nms模块,从而使得整个算法是真正的端到端了,没有任何后处理。
1.4 relation++
relation++论文全称是RelationNet++: Bridging Visual Representations for Object Detection via Transformer Decoder,其属于relation和reppointv2的改进版本,目的是通过transformer机制来桥接不同形式输出和主分支输出之间的联系,从而提升主分支性能。
relationv1版本中通过一个无监督的即插即用模块来自发学习物体和物体之间的关系,而reppointv2虽然没有引入注意力机制,但是其希望通过多个辅助验证任务来提升主分支性能,reppointv2图如下:
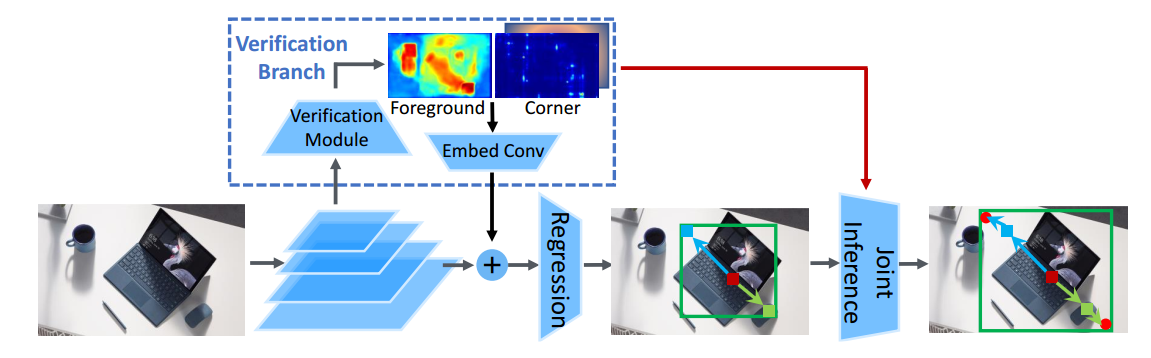
如果排除Verification分支,那就是标准的reppointv1算法,现在希望通过引入两个额外:1.左上右下角点检测任务;2.bbox前景分割任务,然后通过特征嵌入操作融合到主分支,从而提升整体性能,当然两个辅助验证分支也是有监督loss的。
测试时候是先进行reppointv1的回归操作,得到bbox坐标,由于cornernet算法检测的角点会比reppointv1直接回归的方式更准确,故在reppointv1得到的bbox左上右下坐标基础上,去cornernet分支的角点预测图上查找邻域内的角点,从而得到更加准确的预测结果。这个测试流程和centernet(object as center)用于人体姿态估计的做法完全相同,可以避免cornernet的角点分组错误。
而relation++更近一步,希望提出一个通用视觉注意力模块,可以融入任何输出形式和任何网络。
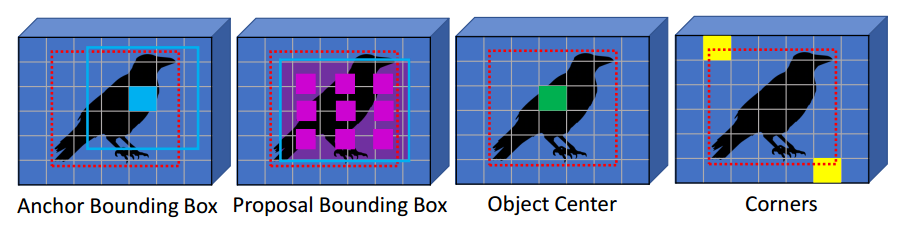
上图是常见的4种bbox输出形式,第一个是anchor-base的one-stage类算法,例如retinanet,第二个anchor-base的two-stage算法,例如faster rcnn,第三个是centernet和fcos,第四个是cornernet。relation++希望对于任何一种主输出形式,都可以利用其余输出形式来增强主分支输出,思想不可谓不超前。
以retinanet为例,如下所示:
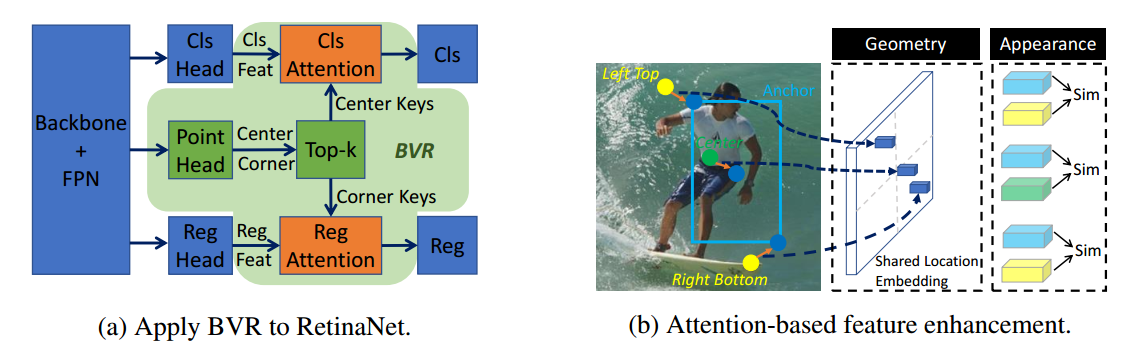
BVR是Bridging Visual Representations模块,也就是本文所提出的通用组件。中间的point head包括中心点高斯热图输出和cornernet中的两个角点输出,为了减轻attention的压力,会对两个辅助分支的输出进行topk操作,然后再采用某种通用attention手段融入到主分支中。具体细节见后续解读。
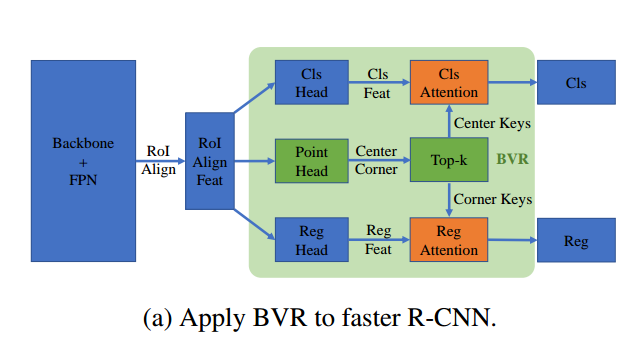
当然faster rcnn也可以应用:
1.5 detr
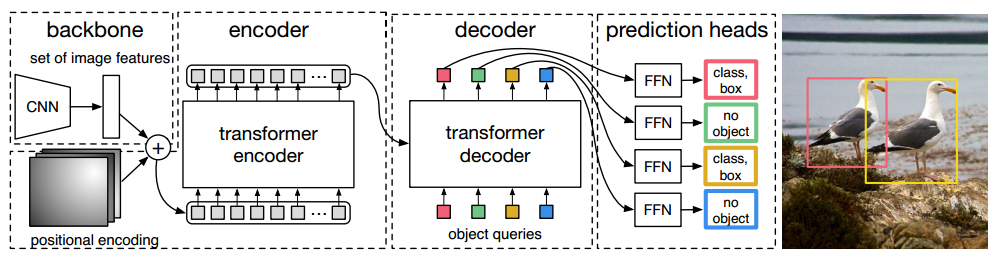
detr做法非常简单:给定一张图片,经过CNN进行特征提取,然后变成特征序列输入到transformer的编解码器中,直接输出指定长度为N的无序集合,集合中每个元素包含物体类别和坐标。其中N表示整个数据集中图片上最多物体的数目。其包括两个主要组件:
- 无序集合输出的loss计算
- 针对目标检测的transformer改进
无序集合输出的loss计算第一步是先采用匈牙利算法进行双边匹配,得到无序输出和无序gt bbox的有序索引对,然后对有序的一对一预测和gt计算相应loss即可。由于其训练时候每个gt bbox只有一个匹配,故detr测试阶段不需要nms。
为了加强transformer在目标检测算法上的性能,提出了核心的Object queries可学习向量,其作用主要是在学习过程中提供目标对象和全局图像之间的关系,相当于全局注意力,必不可少非常关键。
object queries通俗理解:假设其维度是(100,256),在训练过程中每个格子(共N个)的向量都会包括整个训练集相关的位置和类别信息,例如第0个格子里面存储的一定是某个空间位置的大象类别的嵌入向量,注意该大象类别嵌入向量和某一张图片的大象特征无关,而是通过训练考虑了所有图片的某个位置附近的大象编码特征,属于和位置有关的全局大象统计信息。训练完成后每个格子里面都会压缩入所有类别的图片位置相关的统计信息。现在开始测试:假设图片中有大象、狗和猫三种物体,该图片会输入到编码器中进行特征编码,假设特征没有丢失,该编码器输出的编码向量就是KV,而object queries是Q,现在通过注意力模块将Q和K计算,然后加权V得到解码器输出。对于第0个格子的q会和K中的所有向量进行计算,目的是查找某个位置附近有没有大象,如果有那么该特征就会加权输出,整个过程计算完成后就可以把编码向量中的大象、狗和猫的编码嵌入信息提取出来,然后后面接fc进行分类和回归就比较容易,因为特征已经对齐了。
在整个分析过程中可以总结下:object queries在训练过程中对于N个格子会压缩入对应的和位置和类别相关的统计信息,在测试阶段就可以利用该Q去和编码特征KV计算加权计算,从而提出想要的对齐的特征,最后进行分类和回归。所以前面才会说object queries作用非常类似faster rcnn中的anchor,这个anchor是可学习的,由于维度比较高,故可以表征的东西丰富,当然维度越高,训练时长就会越长。
其他的transformer改进主要是输入输出引入了更多的信息而已。整个思想看起来非常简单,相比faster rcnn或者yolo算法那就简单太多了,因为其不需要设置先验anchor,超参几乎没有,也不需要nms(因为输出的无序集合没有重复情况),并且在代码程度相比faster rcnn那就不知道简单多少倍了,通过简单修改就可以应用于全景分割任务。detr虽然说看起来不错,但是其需要非常长的训练时长,收敛比较慢,消耗的内存也比较多。具体解读见:https://zhuanlan.zhihu.com/p/308301901
上述的简要说明写的比较简单,后续会有详细解读。
2 算法分析
2.1 核心思想
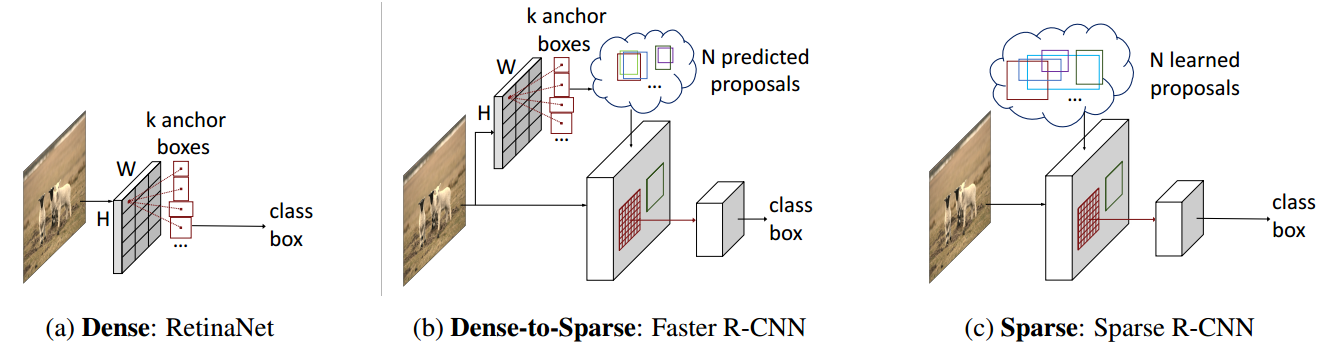
首先需要理解论文所说的sparse,该含义是最后的分类和回归分支面对的候选roi是密集还是稀疏的。retinanet属于one-stage算法,可以将密集anchor认为是候选roi,故其属于dense做法,而faster rcnn由于有RPN来提取稀疏的roi,故属于dense-to-sparse类算法,而本文直接定义N个稀疏的可学习的roi,然后直接通过fast rcnn进行端到端训练即可,故称为sparse rcnn。
由于本文roi是通过网络联合直接学出来的,不需要专门的RPN网络,使得整个sparse rcnn简化为fast rcnn,所以本文才如此简单,并且在计算loss时候也采用了detr的点集预测做法,故最终输出也不需要nms了,进一步简化了算法。
总结下本文优点:不需要RPN、不需要复杂后处理和nms、不需要设置anchor、效果还比faster rcnn好和收敛速度远远快于detr。
2.2 sparse rcnn算法
可以先忽略roi如何获取,先复习下fast rcnn整体测试流程:
- 对原始图片使用SS或者RPN算法得到约2k候选roi
- 将任意大小的图片输入CNN,得到输出特征图
- 在特征图中找到每一个roi对应的特征框,通过roipool将每个特征框池化到统一大小
- 统一大小的特征框经过全连接层得到固定大小的特征向量,分别进行softmax分类和bbox回归
可以看出其包括:backbone+fpn+rcnn head、roipool(或者roialign)、正负样本定义、正负样本采样、bbox编解码和loss计算一共6个核心部件,测试阶段还需要复杂后处理+nms算法,而对比sparse rcnn其主要包括:backbone+fpn+rcnn head、roipool(或者roialign)、可学习的Proposal Boxes与Proposal Features和loss计算一共4个部件,不需要后处理和nms,并且少了最麻烦的正负样本定义+正负样本采样两个步骤,如果再考虑faster rcnn中的RPN模块(其也包括正负样本定义、正负样本采样、bbox编解码和loss计算),那就简单太多了。其最简结构图如下所示:
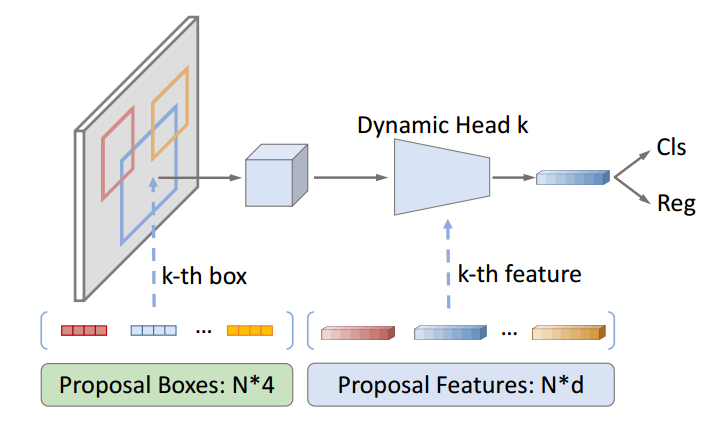
sparse rcnn的大概训练流程是:
- 通过嵌入指定的N个可学习候选框Proposal Boxes来提供roi坐标
- 通过嵌入指定的N个可学习实例级别特征Proposal Features来提供更多的物体相关信息,例如姿态和形状等等
- 将任意大小的图片输入CNN,得到输出特征图
- 在特征图中找到每一个roi对应的特征框,通过roipool将每个特征框池化到统一大小
- roi所提特征和Proposal Features计算交叉注意力,增强前景特征
- 统一大小的特征框经过全连接层得到固定大小的特征向量,输出N个无序集合,每个集合元素包括分类和bbox坐标信息
- 采用casecase rcnn极联实现,对6步骤输出的bbox进行refine,得到refine后的bbox坐标
- 每个级联阶段的输出信息都利用匈牙利双边匹配+分类回归loss进行训练
而测试流程非常简单:1-7步后就已经得到了没有重复的bbox框。
2.2.1 Proposal Boxes
可学习Proposal Boxes维度是(N,4)用于代替RPN层,N是每张图片中最多的物体总数(coco数据集中最多大概是63个物体),N的取值对性能有一定影响,faster rcnn中一般RPN输出给rcnn的roi个数是2000,但是本文考虑计算效率设置的是300,实验结果如下所示:
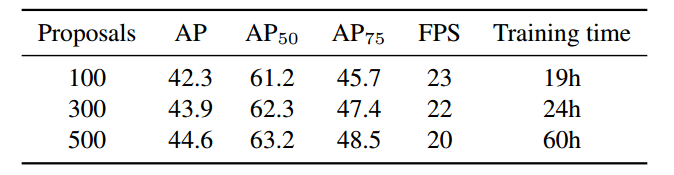
N越大效果越好,但是对应的训练时间会增加很多不可取。
其中4维含义表示roi框,表示方式有很多种,作者采用了和detr中相同的表示方式即图片尺度的归一化cxcywh值,范围是0-1。具体实现上通过Embedding层实现:
#self.num_proposals为超参,默认是300,内部权重是(300,4)self.init_proposal_boxes = nn.Embedding(self.num_proposals, 4)nn.init.constant_(self.init_proposal_boxes.weight[:, :2], 0.5)nn.init.constant_(self.init_proposal_boxes.weight[:, 2:], 1.0)# 为啥用nn.Embedding,在本文中其实和以下语句是同一个意思self.init_proposal_boxes = nn.Parameter(torch.Tensor(self.num_proposals, 4))
注意:self.init_proposal_boxes不包括batch信息,也就是说这个(N,4)矩阵存储的不是当前一张图片信息,而是整个数据集相关的统计roi信息(非常类似注意力机制中的Keys作用,不是Query),然后通过后续可学习层能够提取出本图片中真正的N个roi区域。
为啥需要可学习Proposal Boxes?其主要用于提供粗糙roi表征,否则RCNN算法无法切割出roi特征图(two-stage算法必须要提供roi给rcnn部分进行refine)。
RPN输出的roi主要目的是提供丰富的候选框,保证召回率即可,roi不需要 很准确,故作者觉得采用一个合理的和数据集相关的统计信息就可以提供足够的候选框了,从而采用可学习的proposal boxes代替RPN是完全合理的。
至于proposal boxes初始化设置为啥,对最终结果影响很小,作者实验结果如下:

- center初始化表示都定位到图片中心,wh全部设置为0.1,也就是全部初始化为(0.5,0.5,0.1,0.1)
- Image初始化表示所有roi都初始化为图像大小即(0.5,0.5,1,1)
- Grid表示roi按照类似anchor一样密集排列在原图上,例如[(0,0,0.1,0.1),(32/图片w,32/图片h,0.1,0.1)...]
- Random表示采用高斯分布随机初始化。最终效果看起来都差不多,也就是说采用何种初始化方式对结果没有很大关系。
2.2.2 Proposal Features
可学习Proposal Features维度是(N,256),N含义和上节一致,256是超参表示每个roi实例独有的嵌入信息,其实现和Proposal Boxes一致。
#(300,256)self.init_proposal_features = nn.Embedding(self.num_proposals, self.hidden_dim)
注意其也不包括batch信息,故和Proposal Boxes内部的N是一一对应的关系,也是表征实例的统计信息。
为啥需要proposal feature?作者意思是:仅仅靠4d的proposal boxes提供的roi太过粗糙,无法表征例如物体姿态和形状,为了提高精度很有必要额外输入一个高维度的proposal feature,其目的是希望通过可学习维度嵌入提供N个实例的独特统计信息。

联系detr论文,可以发现具体实现上面Proposal Features和Object query都是一样的,但是由于设计原则上的区别,Object query需要和空间位置编码一起使用,否则性能会有大幅下降,但是sparse rcnn中Proposal Features的主要设计原则是用于特征过滤,其不需要空间位置编码。要理解上述语句,你需要继续看后面的可交互模块设计。
总结下上述两个核心组件:联系relation或者v2论文可以发现,proposal boxes就是论文所说的几何特征,而proposal feature就是外观特征。相对于detr,proposal feature非常类似object query作用,这个是本文成功的关键,而proposal boxes作业仅仅是为了提取roi,使其可以应用于two-stage算法。简单来说就是proposal feature重要性远远大于proposal boxes。
2.2.3 动态实例级可交互模块
该模块属于rcnn head针对性改进,主流程和rcnn一样,利用输入的proposal boxes在特征图上切割,然后采用roialign层统一输出大小,最后通过2个fc层进行分类和bbox回归。
在roialign后面,由于和原始rcnn head输入不一样,本文除了输入FPN输出特征图和proposal boxes,还包括额外的proposal feature,故作者插入了一个新的模块:动态实例级可交互模块。该模块主要作用是进行实例级别roi特征和proposal feature之间的交互,具体分析是:暂时不考虑batch,假设roialign输出shape是(300,7,7,256),300是proposal个数,7x7是切割后统一输出特征图大小,256是表示每个特征空间位置的表征向量,而proposal feature的shape是(300,256),假设我采用如下计算:(300,7x7,256)的roi特征和(300,256,1)的proposal feature进行矩阵乘法,输出是(300,7x7,1)其表示将256维度的proposal feature向量和空间7x7的每个roi特征256维度向量计算相似性,得到相似性权重,该权重可以表征空间7x7个位置中哪些位置才是应该关心的,如果将该权重作用到原始的(300,7x7,256)上,那不就是CV领域常说的空间注意力机制吗?并且由于roi特征的300维度和proposal feature的300维度没有进行交叉计算,而是一对一计算,从而论文中称为实例级可交互模块即N个实例roi特征和N个实例proposal feature一一对应计算,而没有交叉计算。
故动态实例级可交互模块的主要作用是:将roi特征和Proposal Features进行实例级的可交互计算,从而突出对前景贡献最大的bin(7x7个)的输出值,从而最终影响物体的位置和分类预测,如果确实是背景,则相当于7x7个bin都没有高输出值。
示意图如下:
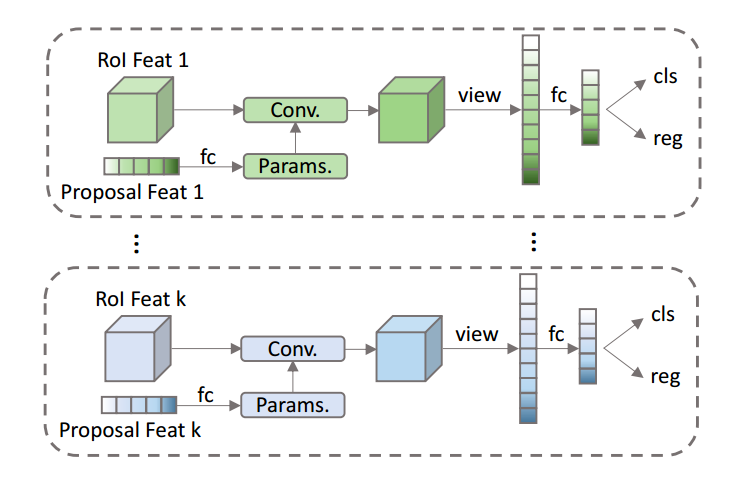
下面对动态实例级可交互模块进行代码分析,其输入rcnn head内部的一个组件,调用过程是:
# 步骤1:FPN特征和proposal boxes作为roialign输入,进行特征切割并统一大小为(49,bxN,256),和rcnn过程完全相同,也需要对roi映射到具体的FPN层上进行切割# 步骤2:对Proposal Features额外加上自注意力模块,输出大小不变,(N, b, 256)# N=300,b=batch,256是嵌入向量长度# 步骤3:动态卷积交互过程(1,bxN,256),(49,bxN,256)--> (bxN,256)pro_features2 = self.inst_interact(pro_features, roi_features)# 步骤4:简单输出head# 步骤5: 分类和回归预测输出
上述5个步骤就是整个动态rcnn head的完整forward过程,其中步骤3是最核心的部分,理解步骤3也就理解了本文细节,其核心代码如下:
def forward(self, pro_features, roi_features):'''pro_features: (1, N * nr_boxes, self.d_model)roi_features: (49, N * nr_boxes, self.d_model)'''features = roi_features.permute(1, 0, 2) # (bxN,49,256)# self.dynamic_layer就是fc层# (1, b * N, 256)-->(1, bxN, 2x64x256)-->(bxN,1,2x64x512)parameters = self.dynamic_layer(pro_features).permute(1, 0, 2)# 切分数据# (bxN,1,2x64x512)-->(bxN,1,64x512)-->(bxN,256,64)param1 = parameters[:, :, :self.num_params].view(-1, self.hidden_dim, self.dim_dynamic)# (bxN,1,2x64x512)-->(bxN,1,64x512)-->(bxN,64,256)param2 = parameters[:, :, self.num_params:].view(-1, self.dim_dynamic, self.hidden_dim)# 实例级别(bxN)交叉注意力计算,计算roi特征和Proposal Features的空间注意力# (bxN,49,256) x (bxN,256,64)-->(bxN,49,64) # 每个位置输出都是64维度features = torch.bmm(features, param1)...# 实例级别交互,再算一遍,从而保存维度不变# (bxN,49,64) x (bxN,64,256)-->(bxN,49,256)# 得到49个格子上不同的空间权重features = torch.bmm(features, param2)...# (bxN,49x256)features = features.flatten(1)# fc层变成(bxN,256)输出features = self.out_layer(features)...
核心就是上图所示:实例级别计算+交叉注意力。论文中指出具体如何设计交互模块并不关键,只要支持并行操作以提高效率即可也就是说上面设置方式是作者设计的,可以不需要如此设置,只要能达到目的就行。作者设计的交互手段采用了attention思想,并且结合了动态卷积做法进行设计。
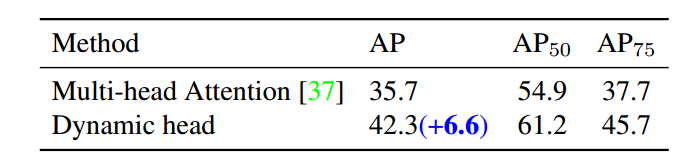
虽然可以直接采用transformer中的Multi-head Attention 机制实现交互效果,但是实验结果表明本文设计的Dynamic head效果有显著改善。
(4) 级联refine做法
为了进一步提高性能,作者还提出了cascade rcnn类似的refine回归思想,就是迭代运行n个stage,每个stage都是一个rcnn模块,参数是不共享的,下一个stage接受的是上一个stage输出的refine后的roi
def forward(self, features, init_bboxes, init_features):inter_class_logits = []inter_pred_bboxes = []# 多尺度输出特征图bs = len(features[0])# 可学习roi (b,N,4) 其中所有batch维度初始化时候都是相同的bboxes = init_bboxes # 可学习的proposal boxes# 可学习特征(N,256)-->(N,b,256)init_features = init_features[None].repeat(1, bs, 1)proposal_features = init_features.clone()# 迭代n次rcnn headfor rcnn_head in self.head_series:# features是FPN输出特征,bboxes初始化时候是可学习的bbox,后面是预测的bbox# proposal_features每次都会同一个输入,self.box_pooler是roialign层class_logits, pred_bboxes, proposal_features = rcnn_head(features, bboxes,proposal_features,self.box_pooler)# 中继监督if self.return_intermediate:inter_class_logits.append(class_logits)inter_pred_bboxes.append(pred_bboxes)# 不断更新roi,类似cascade rcnn思想# 需要截断,和cascade rcnn一样bboxes = pred_bboxes.detach()if self.return_intermediate:return torch.stack(inter_class_logits), torch.stack(inter_pred_bboxes)
效果如下所示:
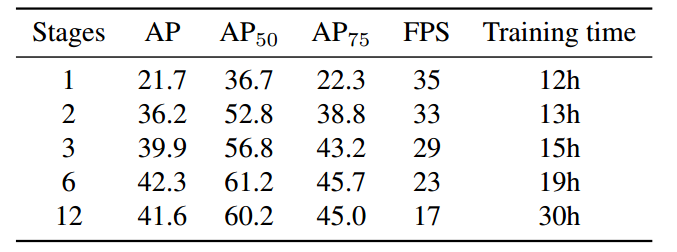
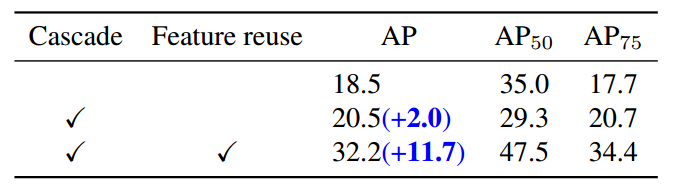
级联stage越多,效果并不是更好,因为可能stage太多了需要特别长的训练时间,如果不够性能会下降。可视化如下:

fature reuse表示在级联多个rcnn head时候,会重用Proposal Features特征,可以看出可以带来巨大增益。
2.2.5 总体算法核心流程
(1) 训练流程
# 图片前处理images, images_whwh = self.preprocess_image(batched_inputs)# resnet+fpn前向,和FPN一样,输出5个输出特征图src = self.backbone(images.tensor)# 多尺度输出特征for f in self.in_features:feature = src[f]features.append(feature)# 准备proposal_boxesproposal_boxes = self.init_proposal_boxes.weight.clone()proposal_boxes = box_cxcywh_to_xyxy(proposal_boxes)# (1,N,4)*(b,1,4)=(b,N,4) 引入batch维度,方便后面计算,已经还原到原图尺度proposal_boxes = proposal_boxes[None] * images_whwh[:, None, :]# 动态交互迭代headoutputs_class, outputs_coord = self.head(features, proposal_boxes, self.init_proposal_features.weight)#输出outputs_class存储了多个阶段的输出output = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}# 计算lossgt_instances = [x["instances"].to(self.device) for x in batched_inputs]targets = self.prepare_targets(gt_instances)if self.deep_supervision:output['aux_outputs'] = [{'pred_logits': a, 'pred_boxes': b}for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
而self.head的流程是不断的迭代n个stage的rcnn head而已。
(2) 测试流程
测试流程和detr几乎相同,由于其loss计算过程和detr完全相同,故也没有复杂后处理和nms。
2.2.6 总体效果
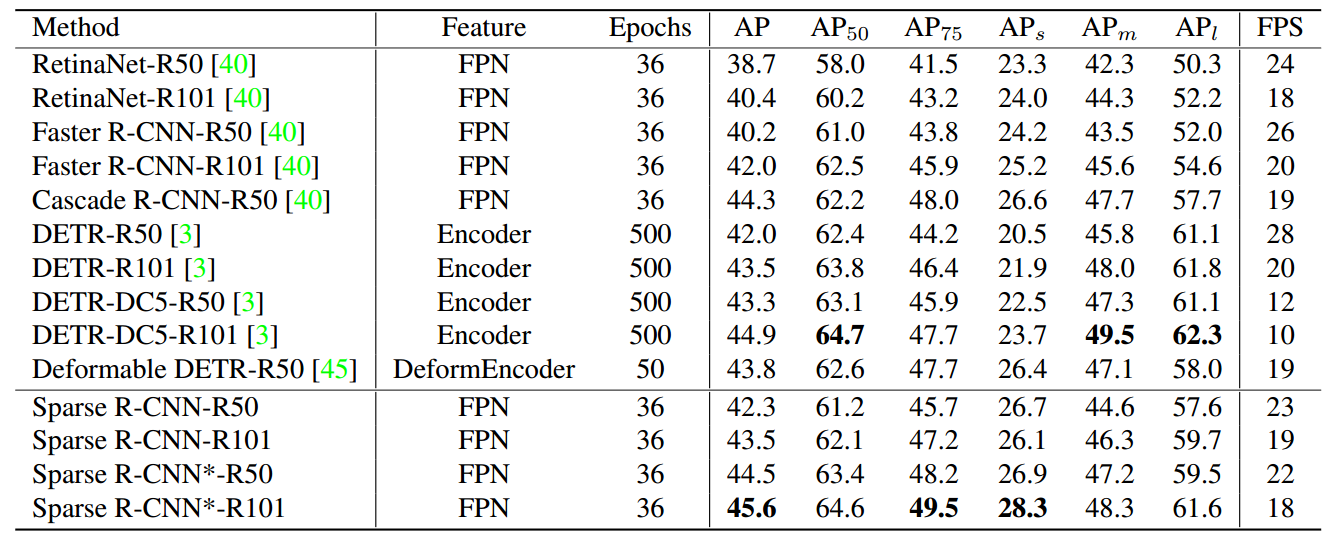
可以看出在同等epoch情况下,可以比retinanet和faster rcnn更好,速度上慢了一点点而已。为啥会更慢?相比detr训练速度上优势就比较大了,当然看起来比可变性detr差一点点。*号是指可学习的Proposal Boxes总共训练了300epoch,并且训练时候用了随机裁剪数据增强。

Sparse指的可学习的bbox和feature,可以看出动态交互和迭代策略提升非常多。
3 总结
借鉴detr思想,引入了核心的可学习的Proposal bboxes和Proposal Features,从而取消RPN层,把整个faster rcnn简化为仅仅需要fast rcnn即可,不需要nms,不需要先验anchor设置,不需要RPN,几乎没有超参,收敛速度远远快于detr,期待未来更多这方面的改进。
