@huanghaian
2020-11-17T09:31:59.000000Z
字数 7020
阅读 2064
mmdetection最小复刻版(十六):yolov1原理详解
mmdetection
0 摘要
yolov1全称是You Only Look Once,是相对于Look Twice而言,其是特指Faster rcnn系列。Faster rcnn系列做法是:
(1) 采用区域提取模块Region Proposal Network(RPN)预测出大量潜在候选bounding boxes(bbox)
(2) 然后采用Region-based Convolutional Network(rcnn)模块对候选bbox进行优化
示意图如下:
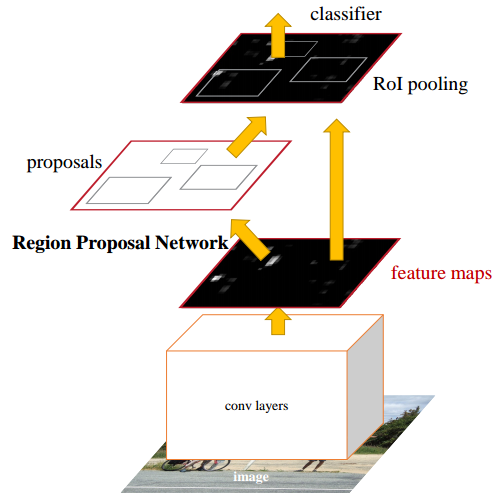
rcnn系列算法包括上述两步骤,其主要优点是性能优异,存在两阶段不断优化思想,但是其缺点也比较明显:速度慢、优化困难、代码比较复杂、非常不适合落地。
基于该痛点,作者提出了一个极度简单、通用、思路清晰、速度和精度平衡的目标检测算法YOLO。不需要复杂的两阶段refine思想,一次性即可学习出图片中所有目标类别和坐标信息(所以才叫做You Only Look Once),是入门目标检测的经典算法,算是one-stage目标检测的先行者。
其简要结构为:
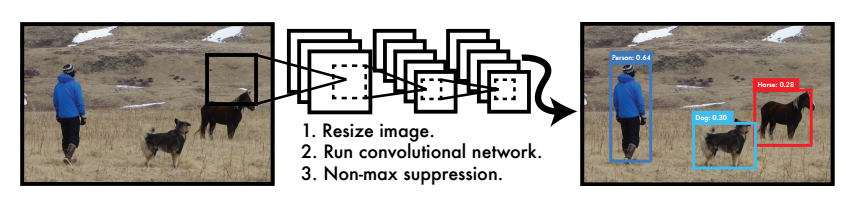
对图片进行缩放成指定大小,然后采用cnn进行特征提取,同时输出类别和目标位置,最后进行非极大值抑制nms即可,大道至简。
1 算法分析
1.1 grid cell网格
要想实现一次性学习出图片中所有目标类别和坐标信息,需要借助grid cell网格的概念,网格含义是对输入到网络中的图片均匀切割为SXS个网格(例如7x7),每个网格负责预测一个物体的类别和坐标即可,类似于滑动窗口思想,在每个窗口内部进行判断是否有物体、物体对应类别以及物体坐标,如下图所示。

假设输入到网络中的是上图,大小为448x448,此时可以均匀切割全图为7x7,每个格子所占大小为(448/7=64)x(448/7=64)像素,蓝色框为标注类别人和对应坐标,黄色是表示该人的gt bbox中心点坐标落在该网格内部,该网格负责预测该物体。
1.2 核心思想
在了解网格概念后,构建整个算法就水到渠成了,我们可以自己猜想下如何进行训练和测试?训练流程可以是:
(1) 将多张图片通过前处理操作统一size,设置为(H,W),然后组成batch输入到CNN中进行特征提取
(2) 为了实现SXS输出网格效果,我们可以故意设置网络下采样率为(H/S,W/S),实现特征图上面任意一点都对应原图的(H/S,W/S)个像素区域,举例原图是448x448,S=7,那么可以设置下采样倍数为64,特征图输出就是7x7了,7x7的特征图上面任何一点都等效对应原图的64x64像素区域。由于卷积kernel一般都是正方形,为了好处理输入一般设置H=W
(3) 此时就将全图划分为SXS个块了,对于标注的任何一个gt bbox,先下采样(H/S,W/S)倍映射到特征图尺度上,然后计算该gt bbox中心坐标落在哪个网格上面,落在哪个网格上那么哪个网格就负责预测该物体。预测输出形式可以是分类输出和bbox坐标预测回归输出
(4) 计算出每个网格处的label,然后和预测值算loss,迭代sgd优化就可以
测试流程可以是:
(1) 将多张图片通过前处理操作统一size,设置为(H,W),然后组成batch输入到CNN中进行特征提取
(2) 特征提取后输出为SXS的网格大小,对每个网格的分类分支判断是否有物体,如果有物体则读取对应网格的bbox坐标预测值
(3) 考虑到多个网格会预测同一个bbox,故还需要进行最后的nms,得到最终目标检测结果
上面的训练和测试流程是我们基于网格的作用猜想出来的,是一个比较自然的想法,而实际上YOLO确实就是这样做的,只不过为了达到比较高的性能,会进行优化而已。
1.3 yolo分析
在前面文章中我们说过任何一个目标检测算法核心部分都可以归纳为以下6个部分:
- 网络backbone设计
- 网络neck设计
- 网络head设计
- 正负样本定义
- bbox编解码设计
- loss设计
网络backbone和head设计是必不可少的,neck模块最典型的是FPN进行特征融合,并不是必须的模块。由于目标检测是一个同时包括分类和bbox回归预测的问题,既然是分类问题那么就需要确定哪些是正样本(前景样本),哪些是背景样本,不然如何训练呢?在这里其实特指对于SXS个网格输出,哪些网格算正样本哪些网格算负样本的定义规则。而bbox编解码是为了方便loss收敛而设计的一种预测bbox和gt bbox的转换关系。最后的loss设计也至关重要。下面按照上面顺序分析。
(1) 整体思想
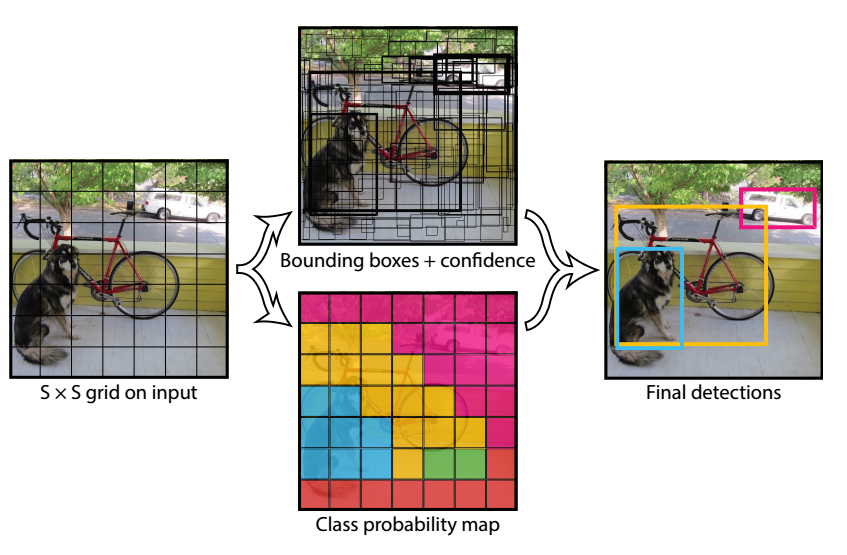
YOLO将输入图像划分为S*S的网格,每个网格负责检测中心落在该网格中的物体,每一个网格预测B(论文设置为2)个bbox,以及这些bbox的置信度confidence分值和对应类别。
置信度分值反映了模型对于这个网格的预测,包括两个信息:该网格是否含有物体,以及这个bbox的坐标预测有多准。值越大表示越可能有前景物体,且该网格的预测bbox越准确。是否可以舍弃置信度预测值,只预测类别和位置?答案是:如果仅仅考虑该网格是否含有物体的作用,那么完全可以舍弃,把这个功能并入分类分支即可(cls_num+1,1是背景类别),但是如果还要同时考虑预测bbox准确度,那么就不能舍弃,否则无法实现这个功能。
在强行施加了网格限制以后,每个网格最多只能输出一个预测结果(不管B设置为多少都一样,需要知道正样本定义规则才能理解),所以该算法最大不足是理论召回率比较低,特别是在物体和物体靠的比较近且物体比较小的时候,很大几率多个物体中心坐标会落在同一个网格中,导致漏检。
(2) 网络bockbone及其head定义
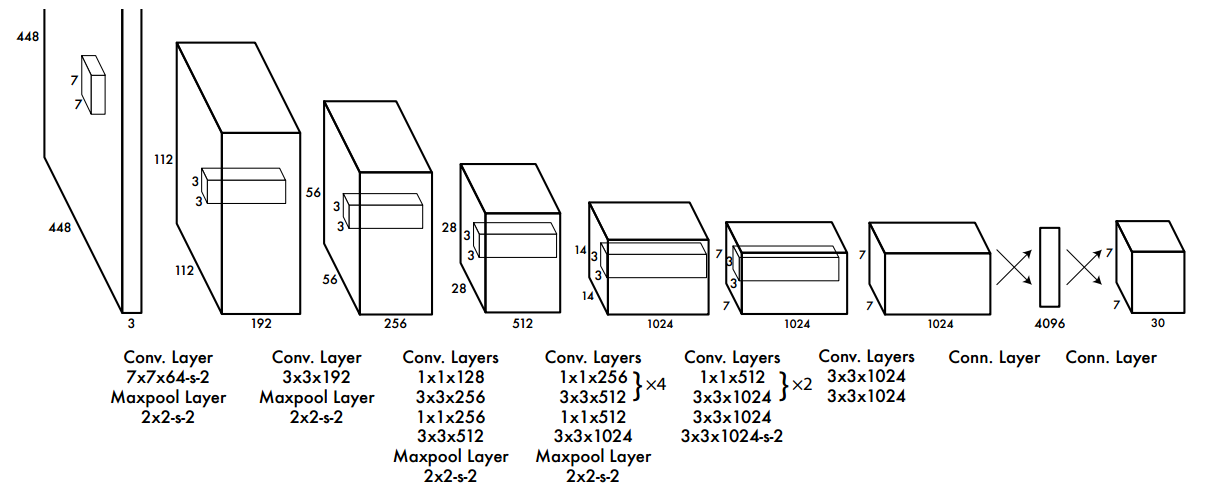
由于YOLOV1发表时间比较早,那时网络设计还没有现在这么多花样,所以其设计的骨架比较简单,就是标准卷积+池化的直筒结构,没啥好细说的,如上图所示。
每个卷积层后面的激活函数是Leaky ReLU,算是ReLU简单改进,在x < 0时候也有梯度:
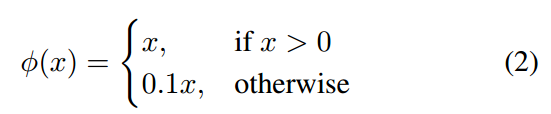
最后一层是采用fc形式输出,没有激活函数,shape为(batch,S×S×(B * 5 + C),S是网格参数,B是每个网格输出的bbox个数,C是类别数,5是表示bbox的xywh预测值加上一个置信度预测值。对于PASCAL VOC数据且输入是448x448,S=7,B=2,则输出是(batch,7x7x(2*(4+1)+20))=(batch,7x7x30)
对于任何一个网格的B * 5 + C长度向量,其每个向量位置含义只需要提前确定就好了,作者设置为如下形式:
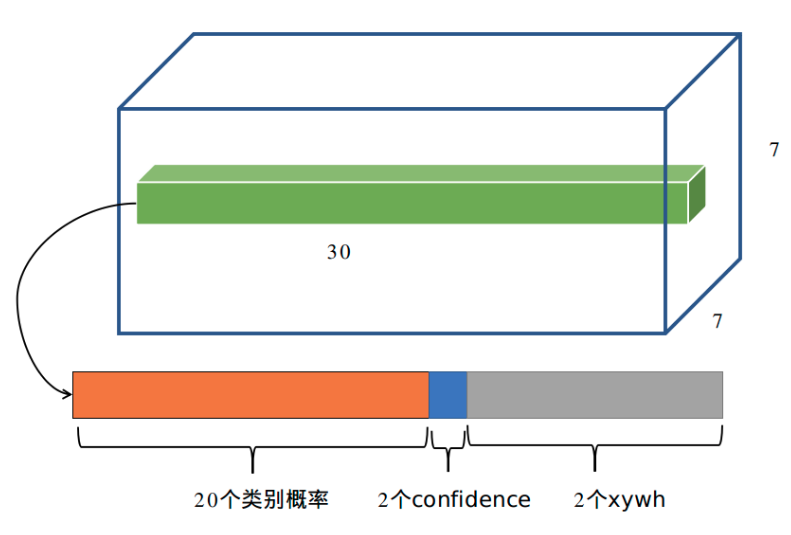
以上述设置为例,前20个数是不包括背景的类别信息,值最大的索引就是对应类别;由于B=2,所以前2个数是置信度分支;后面2x4个数是按照xywhxywh...的格式存储的。有了这个规则就可以进行后续操作了。
(3) 正负样本定义
任何一个目标检测算法都需要定义正负样本,否则分类分支无法训练。其正负样本定义超级简单(很多目标检测算法复杂就体现在这个部分):对于任何一个gt bbox,如果其中心坐标落在某个网格内部,那么该网格就负责预测该物体。 但是有一个细节需要注意:如果B=1,则比较好理解,但是作者设置B=2,也就是每个网格还要预测两个bbox,此时对于gt bbox中心落在该网格时候到底哪部分xywh输出向量负责预测该gt bbox,具体做法是将B个xywh预测值都进行解码还原为预测bbox格式(在1.5 推理逻辑小结有讲到,此处暂时不需要知道解码细节),然后计算B个预测bbox和对应gt bbox的iou,哪个iou大就哪个xywh预测框负责预测该gt bbox,另一个当做负样本。那么如果某个网格有m(m>=2)个gt bbox中心落在里面匹配规则是啥呢?其实也是一样的,将B个预测bbox和所有gt bbox计算iou,然后取最大iou就可以找到哪个预测框和哪个gt bbox最匹配,此时该预测框就是正样本,其余全部算负样本,其余gt bbox被忽略当做背景处理。
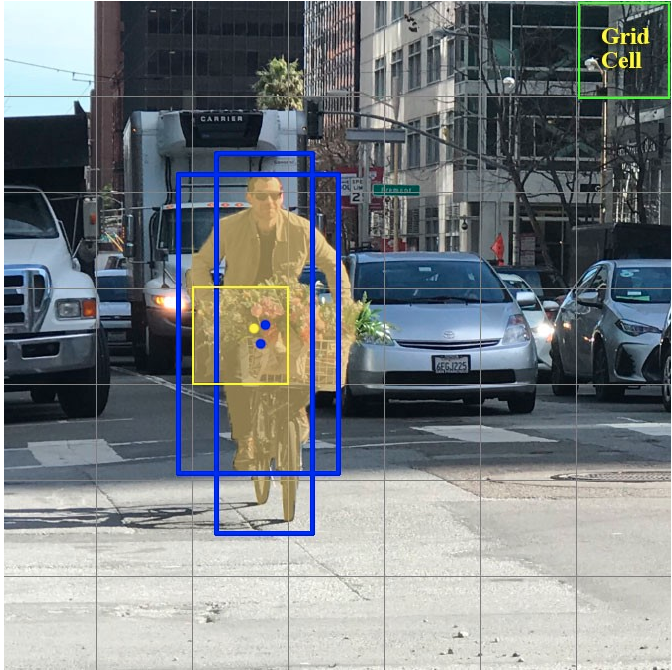
两个蓝色框表示黄色网格实时预测出的bbox值,其中有一个蓝色框和gt bbox的iou几乎为1,此时iou最高的蓝色框才是真正的正样本,另一个算负样本。
之所以设置B=2是想提高召回率且不影响推理速度,理论上B越大召回率越高(相当于B个人做同一件事情,并且进行竞争,谁做的更好就采用谁的方案,只要我安排的人越多,那么可能方案越出色),但是速度肯定越慢。作者实验发现一个网格的两个xywh预测在尺寸、长宽比、或者某些类别上逐渐有所分工,总体的召回率有所提升。
(4) bbox编解码设计
理论上每个网格的xywh预测值可以是gt bbox的真实值,但是这样做不太好,因为xy和wh的预测范围不一样,并且分类和bbox预测分支取值范围也不一样,如果不做任何设计会出现某个分支训练的好而其余分支训练的不好现象,效果可能不太好,所以对bbox进行编解码是非常关键的。
对于xy预测值的target,其表示gt bbox中心相当于所负责网格左上角的偏移,范围是0~1。假设该gt bbox的中心坐标为(200,300),图片大小是448x448,S=7,那么其xy label计算过程是:
- 将gt bbox中心坐标值映射到特征图上,其实就是除以stride=448/7=64,得到(200/64=3.125,300/64=4.69)
- 然后向下取整得到所负责该gt的网格坐标(3,4)
- 计算xy值label=(0.125,0.69)
可以看出由于取整操作使得xy预测值始终是相当于网格左上角坐标相对偏移值。
对于wh预测就直接将gt bbox的宽高除以图片宽高归一化即可,其范围也是0~1。这个操作本身没有问题,但是其忽略了大小bbox属性,会出现小物体梯度比较小的问题出现漏检。假设某个gt bbox是大物体shape=200x300,还有一个小物体20x30,在后续计算l2像素误差都是10像素时候,对于大物体而言其实iou还是蛮高的,但是对于小物体就偏差太多了。可以发现在loss相同情况下,小物体的bbox误差其实更大。为了突出小物体的重要性,可以采用各种做法,作者做法是采用平方根变换,此时大物体变成14.1x17.3,小物体变成4.47x5.4,此时可以发现由原始的10倍差距变成了3.5倍。当然你也可以采用自适应加权来实现上述效果。将gt bbox的wh预测值进行归一化分析结果也是一样的,其本质是压缩大小物体回归差距,使得大小不同尺度物体在loss层面相同时候更加重视小物体。
(5) loss设计
在确定了正负样本以及bbox的编码格式,就可以计算Loss了。
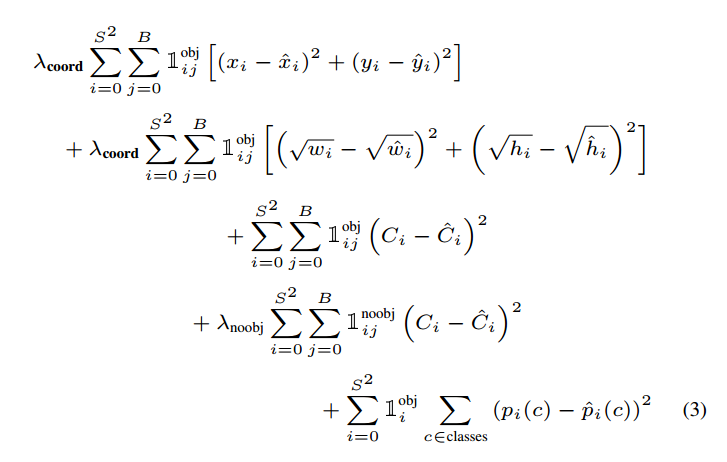
表示哪些网格(一共SXS个)的哪些框(一共B个)负责预测对应gt bbox,也就是我们说的正样本位置,其计算规则在(3) 正负样本定义已经分析了,相反的表示负样本。
可以发现所有loss都是l2 loss即都是回归问题,如此设置的原因可能是想把整个框架都认为是回归问题吧。并且因为是回归问题,所以即使xywh预测范围是0~1也没有采用sigmoid进行强制压缩范围(原因是sigmoid有饱和区)。
- 对于xywh向量,其仅仅计算正样本loss,其余位置是忽略的
- 对于类别向量,其也是仅仅计算正样本loss,其余位置是忽略的,label向量是One-hot编码
- 对于置信度值,其需要考虑正负样本,并且正负样本权重不一样。特别的为了实现置信度值的功能:该网格是否含有物体,以及这个box的坐标预测的有多准,对于正样本,其置信度的label不是1,而是预测bbox和gt bbox的iou值,对于负样本,其置信度label=0。当然如果你希望置信度值仅仅具有该网格是否含有物体功能,那么只需要正样本label设置为1即可,代码实现上通过变量rescore控制。
因为正样本非常少,故其设置了参数来平衡正负样本梯度。
1.4 训练逻辑
为了提高目标检测性能,首先利用ImageNet数据集在224x224输入大小上面预训练卷积层,具体是使用backone网络中的前20 个卷积层,加上一个全局平均池化层和一个全连接层进行分类训练,训练大约一周时间,在ImageNet 2012的验证数据集Top-5的精度达到88%,这个结果跟GoogleNet的效果相当。采用预训练的好处是目的是让CNN层具有更好的特征提取能力,同时加快收敛。
将预训练结果的前20层卷积层应用到YOLO中,并加入剩下的4个卷积层及2个全连接,同时为了获取更精细化的结果,将输入图像分辨率由224 * 224 提升到448 * 448,然后进行目标检测YOLO训练,并且配合一些常规的数据增强提高模型泛化能力。
1.5 推理逻辑

(1) 遍历每个网格,将B个置信度预测值和预测类别向量分值相乘,得到每个bbox的类相关置信度值,可以发现这个乘积即表示了预测的bbox属于某一类的概率和该bbox准确度的信息,此时一共有SXSXB个预测框
(2) 设置阈值,滤掉类相关置信度值低的boxes,同时将剩下的bbox还原到原图尺度,xy中心坐标还原是首先加上当前网格左上角坐标,然后乘上stride即可,而wh值就直接乘上图片wh即可
(3) 对剩下的boxes进行NMS处理,就得到最终检测结果
可视化图如下:
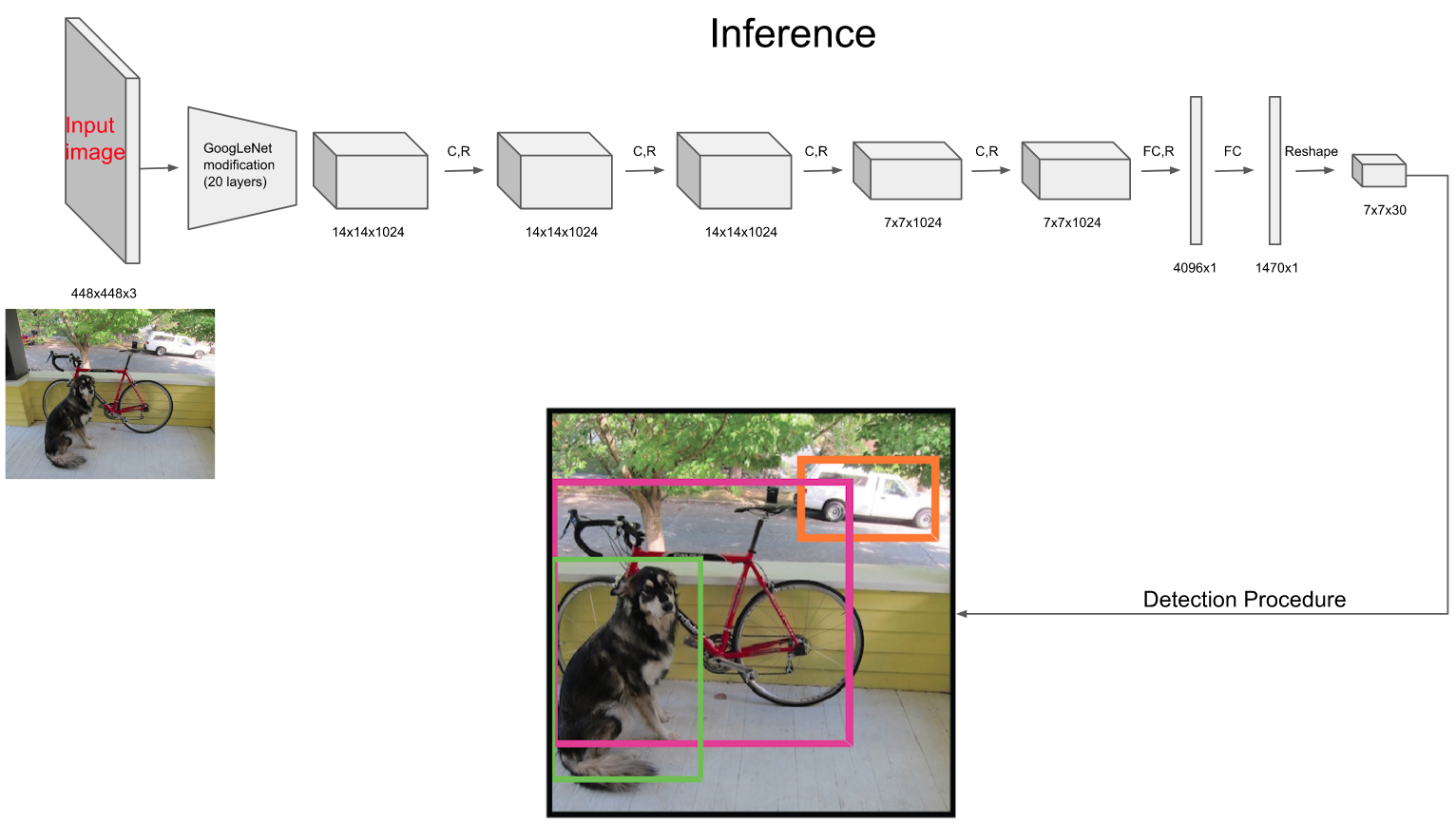
2 结果分析
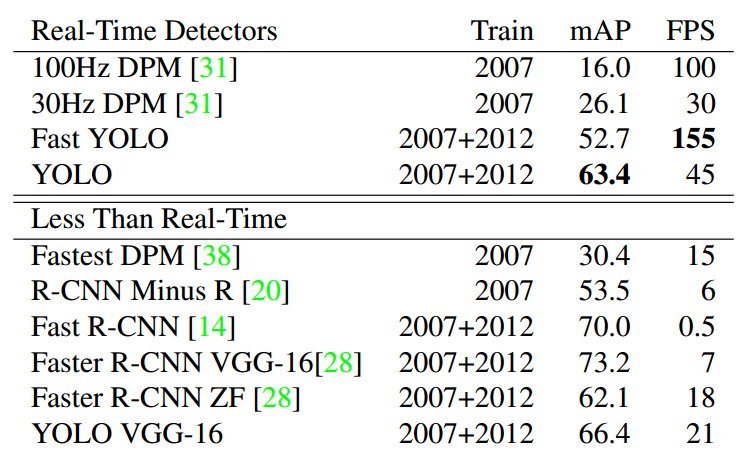
可以看出其最大特点是速度极快。
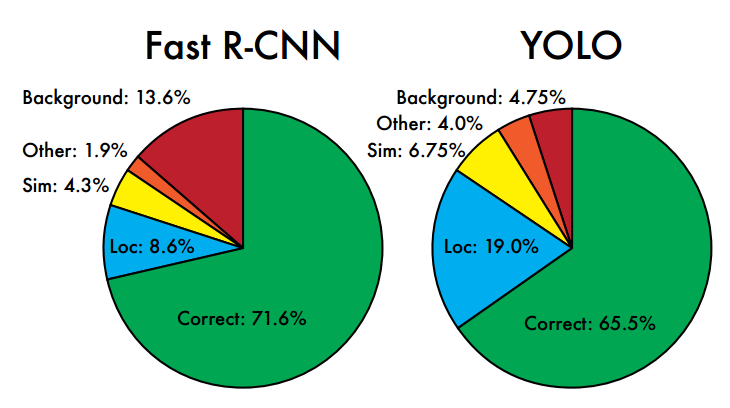
相比Fast RCNN,其背景误检率很低,作者分析原因是在训练和推理过程中能‘看到’整张图像的整体信息。但是YOLO的定位准确率较差,主要原因是物体尺度变化很大,强行回归做法都有这个问题。
3 总结
YOLO可以说是第一个简洁优美的one-stage目标检测算法,设计思路非常简洁清晰,最大优点是速度极快、背景误检率低,缺点是由于网格特点召回率会低一些,回归精度也不是很高,特别是小物体,这些缺点在后续的YOLOV2-V3中都有极大改善。
4 思考
4.1 为何不设置每个网格同时预测B个物体
在YOLOV1设置中输出shape是(batch,S×S×(B * 5 + C),不管你如何设计算法,都是无法做到每个网格预测B个物体的,原因是B个bbox预测框都是对应1个类别信息的,这个类别信息只能表示一个物体,无法表达B个bbox。
那作者为啥不设置shape为(batch,S×S×(B * 5 + B * C)?这样理论上就可以实现每个网格预测B个物体了。关于原因我暂时不知道,大概可以归结为历史局限或者说速度方面考虑吧。我们可以试图分析下如果是这种场景要如何训练? 会不会有问题?
假设B=2
(1) 假设某个网格就1个gt bbox
由于B=2,那么可以沿用目前设计思想:将B个xywh预测值都进行解码还原为预测bbox格式,然后计算B个预测bbox和对应gt bbox的iou,哪个iou大就哪个xywh预测值负责预测该gt bbox,另一个当做负样本。
(2) 假设某个网格有n(n>=2)个gt bbox
此时需要确定网格中的2个框应该负责哪个gt bbox?基于目前理解可以有两种设计方法:
1) 2个框必须负责不同的gt bbox,其分配原则是对每个框的预测解码bbox和所有网格内gt bbox计算iou,此时可以得到2xn的iou矩阵,对n方向求max,变成(2,)向量代表每个框和gt bbox的最大Iou,最后哪个iou更大,谁就优先选择,剩下的就只能选择其他的gt bbox。举个例子,假设b=2,且仅有两个gt bbox,将这两个框的预测bbox解码和gt bbox分别算Iou,
| IOU | GT A | GT B |
|---|---|---|
| 预测框A | 0.6 | 0.45 |
| 预测框B | 0.7 | 0.5 |
由于最大值是预测框B对应GT A,所以B预测框负责GT A,而A预测框只能负责GT B
2) 2个框可以负责同一个gt bbox,其分配原则是max iou准则,对每个框的预测解码bbox和所有网格内gt bbox计算iou,然后找出每个框各自和gt bbox的最大Ious索引,就代表其负责的gt bbox。依然以上面例子举例,由于两个预测框都是和GT A 的iou较大,故这两个预测框都是负责预测GT A。
按照上面的分析,看起来改成(batch,S×S×(B * 5 + B * C)是没有问题的,但是1)设定规则应该是不太好的,因为你训练时候强制不同预测框负责不同的gt bbox,而这个强制规则会导致不同的训练阶段出现label冲突,并且测试时候也无法保证多个物体中心落在同一个网格情况下能够全部检出,训练不知道能不能work还不清楚。2)的规则应该更符合常理。
欢迎讨论!
参考文献
1 You Only Look Once: Unified, Real-Time Object Detection
2 https://jonathan-hui.medium.com/real-time-object-detection-with-yolo-yolov2-28b1b93e2088
3 https://pjreddie.com/darknet/yolo/
4 https://docs.google.com/presentation/d/1aeRvtKG21KHdD5lg6Hgyhx5rPq_ZOsGjG5rJ1HP7BbA/pub?start=false&loop=false&delayms=3000&slide=id.g137784ab86_4_2287
