@huanghaian
2020-08-11T04:01:56.000000Z
字数 6848
阅读 2169
进击的后浪yolov5深度可视化解析
目标检测
0 摘要
论文:暂无
github: https://github.com/ultralytics/yolov5
我注释版本github: https://github.com/hhaAndroid/yolov5-comment
关于yolov5是否应该赋予这个名称,网上众说纷纭,如何评价YOLOv5?讨论非常热烈,在最近的小麦检测比赛上也有讨论。作为技术人员,我对此不进行评论,但是由于其在各个数据集上体现出收敛速度快,模型可定制性强的特点,故还是非常有必要深入研究下源码。
本文从可视化角度结合源码进行分析,需要特别注意的是:yolov5还在快速迭代中,可能后续改动非常大,所以我仅仅以当前最新版本也就是2020.08.07时候clone的版本为例进行分析。我增加了很多注释,如果需要我新增注释以及可视化部分代码的人,可以点击注释版本github。
yolov5和前yolo系列在网络设计方面差别不大,如果要说差别的话,那就是在loss设计上面和前yolo系列存在较大差别,后面会细说。简单概述来说整个yolov5就是:通过应用类似EfficientNet的channel和layer控制因子来灵活配置不同复杂度的模型,并且在正负样本定义阶段采用了跨邻域网格的匹配策略,从而得到更多的正样本anchor,加速收敛。
网上也出现了一些yolov5的解析,但是我觉得要么写的太简单,要么没有分析到真正核心地方,故才有了这篇文章。通过对代码详细分析,并配合可视化gt和anchor分析,方便理解算法核心思想。由于本人水平有限,可能有理解错误的地方,烦请指正,谢谢。
1 整体设计
1.1 模型设计
yolov5的整体模型和yolov4差别很小,主要特点是灵活度比yolov4更高。yolov4典型结构是cspdarknet53+panet+spp+yolov3 head
- YOLOv4
- The model in YOLOv4 paper.
- Backbone - CSPDarknet53 with Mish activation
- Neck - PANet with Leaky activation
- Plugin Modules - SPP
如果对yolov4网络结构不太清楚的,可以参考知乎文章(这位作者也出了yolov5的结构解析),为了方便分析,从里面截一张图,如有侵权,请联系我删除:
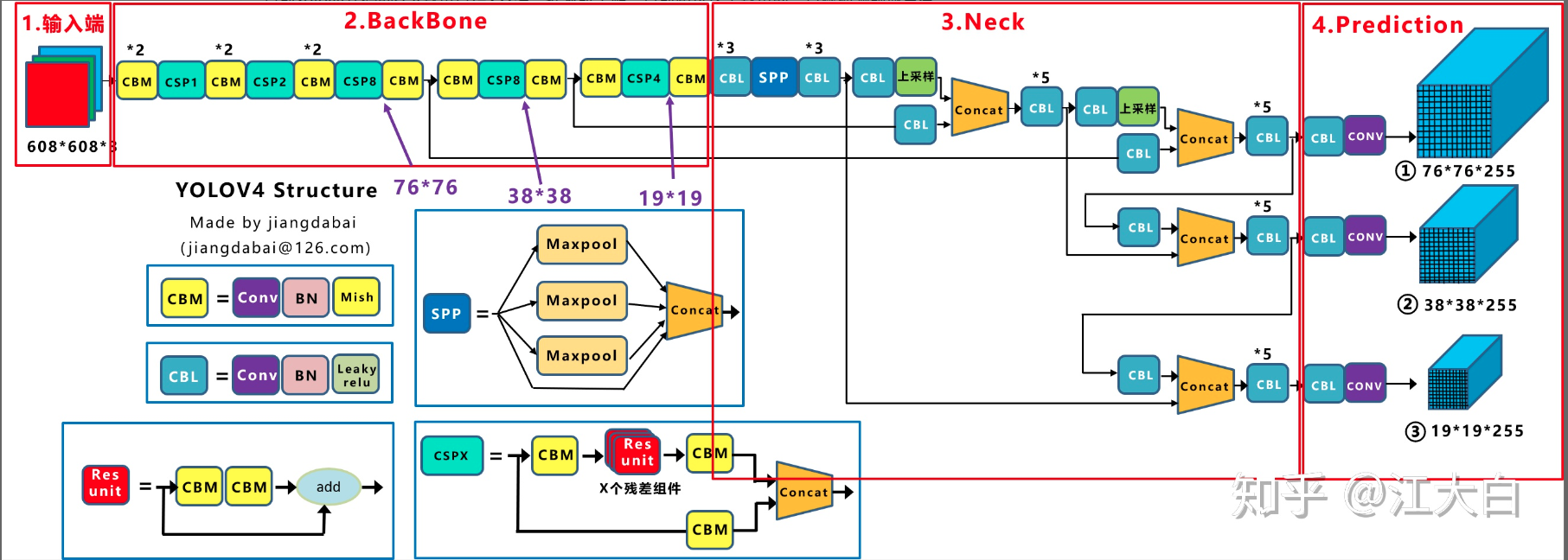
整个yolov4网络结构其实是非常清晰的,而yolov5基本没有啥变化,具体差别后面会写,先简单分析下yolov4结构:
(1) CSPDarknet53,CSP就是CSPNet论文里面跨阶段局部融合网络,仿照的是Densenet密集跨层挑层连接思想,但是考虑到内存消耗过大,故修改为部分局部跨层融合做法,图示如上所示
(2) neck模块采用的是PANet和增强模块SPP。SPP结构非常容易理解,就是不同kernel size的pool操作进行融合,在yolov3的改进版中也有应用,对整个运行速度影响很小,但是效果提升明显。而PANet是FPN结构的改进版本,目的是加快信息之间的流通,具体细节可以参考想读懂YOLOV4,你需要先了解下列技术(二)
(3) head部分没有任何改动,和yolov3和yolov4完全相同,也是三个输出头,stride分别是8,16,32,大输出特征图检测小物体,小输出特征图检测大物体
yolov5的模型构建仿照了darknet中采用的cfg模式,即通过配置文件来构建网络,但是考虑到darknet中的cfg文件细粒度过高,对于重新构建网络来说是很累人的,可读性比较差,本文作者借鉴了cfg思想,但是进行了适当改进即不再细分到conv+bn+act层,而最细粒度是模块,为后续模型构建、结构理解有很大好处,但是这种写法缺点是不再能直接采用第三方工具例如netron进行网络模型可视化了。以yolov5s.yaml为例进行分析。
骨架网络如下:
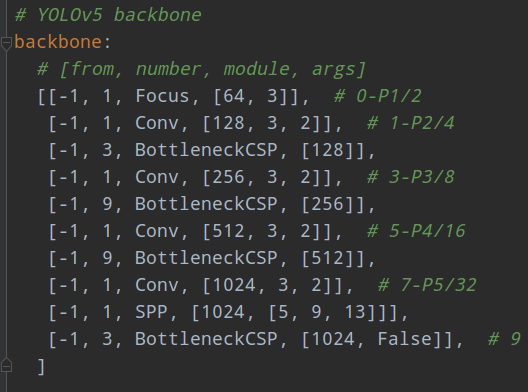
from意思是当前模块输入来自哪一层输出,和darknet里面一致,number是本模块重复次数,后面对应的是模块名称和输入参数。由于本份配置其实没有分neck模块,故spp也写在了backbone部分。
作者提出了一个新模块Focus(其余模块都是yolov4里面提到的),源码如下:

这个其实就是yolov2里面的ReOrg+Conv操作,也是亚像素卷积的反向操作版本,简单来说就是把数据切分为4份,每份数据都是相当于2倍下采样得到的,然后在channel维度进行拼接,最后进行卷积操作。
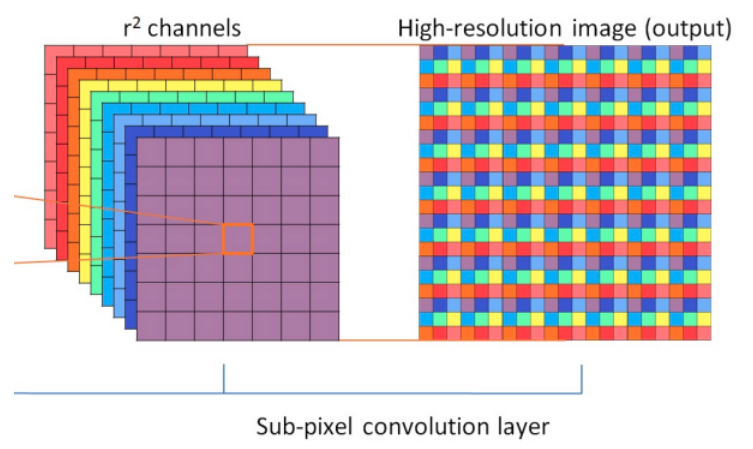
其最大好处是可以最大程度的减少信息损失而进行下采样操作。
head部分配置如下所示;
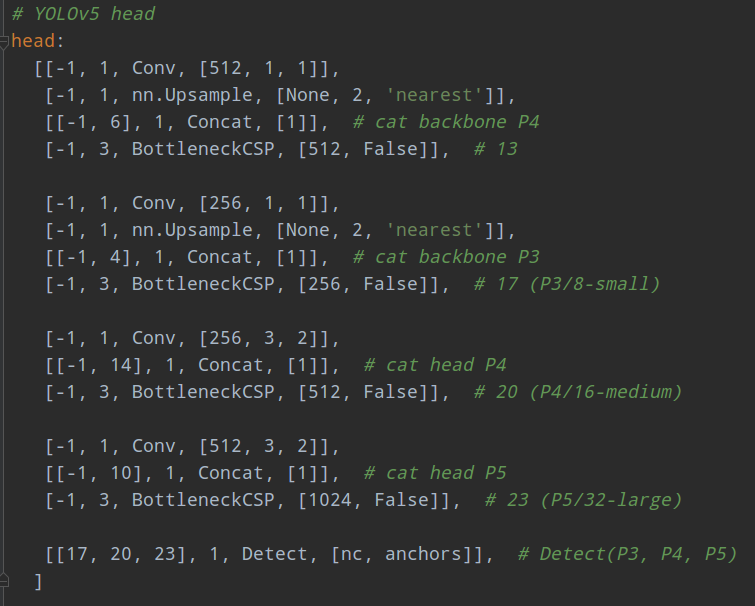
作者没有分neck模块,所以head部分包含了PANet+head(Detect)部分。
前面说过yolov5相比于yolov4,在模型方面最大特点是灵活,其引入了depth_multiple和width_multiple系数来得到不同大小模型:
yolov5s:
depth_multiple: 0.33
width_multiple: 0.50
yolov5m:
depth_multiple: 0.67
width_multiple: 0.75
yolov5l:
depth_multiple: 1.0
width_multiple: 1.0
depth_multiple表示channel的缩放系数,就是将配置里面的backbone和head部分有关通道的设置,全部乘以该系数即可。而width_multiple表示BottleneckCSP模块的层缩放系数,将所有的BottleneckCSP模块的number系数乘上该参数就可以最终的层个数。可以发现通过这两个参数就可以实现不同大小不同复杂度的模型设计。比yolov4更加灵活。
1.2 loss计算
yolov5的loss设计和前yolo系列差别比较大的地方就是正样本anchor区域计算,其余地方差距很小。分类分支采用的loss是BCE,conf分支也是BCE,当然可以通过h['fl_gamma']参数开启focal Loss,默认配置没有采用focal los,而bbox分支采用的是Giou loss。
对于yolov3计算过程不熟悉的,可以参考目标检测正负样本区分策略和平衡策略总结(一),里面有详细分析yolov3的loss计算过程。loss的计算非常简单,核心是如何得到loss计算所需的target。yolov5的很大区别就是在于正样本区域的定义。在yolov3中,其正样本区域也就是anchor匹配策略非常粗暴:保证每个gt bbox一定有一个唯一的anchor进行对应,匹配规则就是IOU最大,并且某个gt一定不可能在三个预测层的某几层上同时进行匹配。,不考虑一个gt bbox对应多个anchor的场合,也不考虑anchor是否设置合理。不考虑一个gt bbox对应多个anchor的场合的设定会导致整体收敛比较慢,在诸多论文研究中表明,例如FCOS和ATSS:增加高质量正样本anchor可以显著加速收敛。
本文也采用了增加正样本anchor数目的做法来加速收敛,这其实也是yolov5在实践中表明收敛速度非常快的原因。其核心匹配规则为:
(1) 对于任何一个输出层,抛弃了基于max iou匹配的规则,而是直接采用shape规则匹配,也就是该bbox和当前层的anchor计算宽高比,如果宽高比例大于设定阈值,则说明该bbox和anchor匹配度不够,将该bbox过滤暂时丢掉,在该层预测中认为是背景
(2) 对于剩下的bbox,计算其落在哪个网格内,同时利用四舍五入规则,找出最近的两个网格,将这三个网格都认为是负责预测该bbox的,可以发现粗略估计正样本数相比前yolo系列,至少增加了三倍
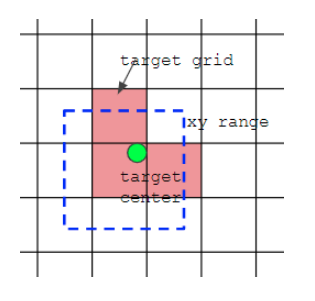
如上图所示,绿点表示该Bbox中心,现在需要额外考虑其2个最近的邻域网格也作为该bbox的正样本anchor。从这里就可以发现bbox的xy回归分支的取值范围不再是0~1,而是-0.5~1.5(0.5是网格中心偏移,请仔细思考为啥是这个范围),因为跨网格预测了。
为了方便理解,我对预测的正样本anchor进行了可视化(dataset应用了mosaic增强):

三张图排布顺序是:0-大输出特征图(stride=8),1-中等尺度特征图(stride=16),2-小尺度特征图(stride=32),分别检测小物体、中等尺寸和大尺度问题。其中红色bbox表示该预测层中的gt bbox,黄色bbox表示该层对应位置的正样本anchor。第一幅图是大输出特征图,只检测小物体,所以人那个bbox标注被当做背景了,并且有三个anchor进行匹配了,其中包括当前网格位置anchor和2个最近邻居anchor。从这幅图中可以看出很多东西(一定要仔细看这几幅图,loss设计的思想在图中一目了然):
(1) 不同于yolov3和v4,其gt bbox可以跨层预测即有些bbox在多个预测层都算正样本
(2) 不同于yolov3和v4,其gt bbox的匹配数范围从3-9个,明显增加了很多正样本(**3是因为多引入了两个邻居)**
(3) 不同于yolov3和v4,有些gt bbox由于和anchor匹配度不高,而变成背景


我个人看法:作者这种特别暴力增加正样本做法还是存在很大弊端,虽然可以加速收敛,但是由于引入了很多低质量anchor,对最终结果还是有影响的。我相信这个部分作者应该还会优化的。
下面结合代码进行详细分析,具体就是compute_loss函数:
(1) build_targets
build_targets函数用于计算loss函数所需要的target。其大概流程为:
1.将targets 重复3遍(3=层anchor数目),也就是将每个gt bbox复制变成独立的3份,方便和每个位置的3个anchor单独匹配
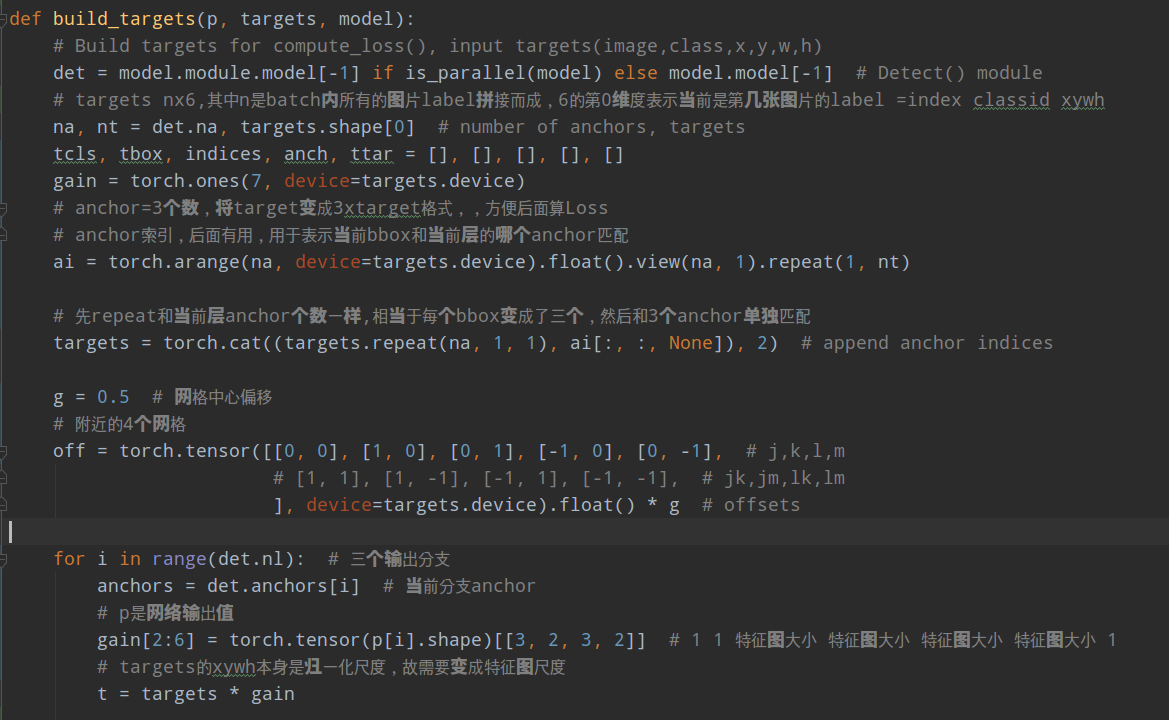
2.对每个输出层单独匹配。首先将targets变成anchor尺度,方便计算;然后将target wh shape和anchor的wh计算比例,如果比例过大,则说明匹配度不高,将该bbox过滤,在当前层认为是bg
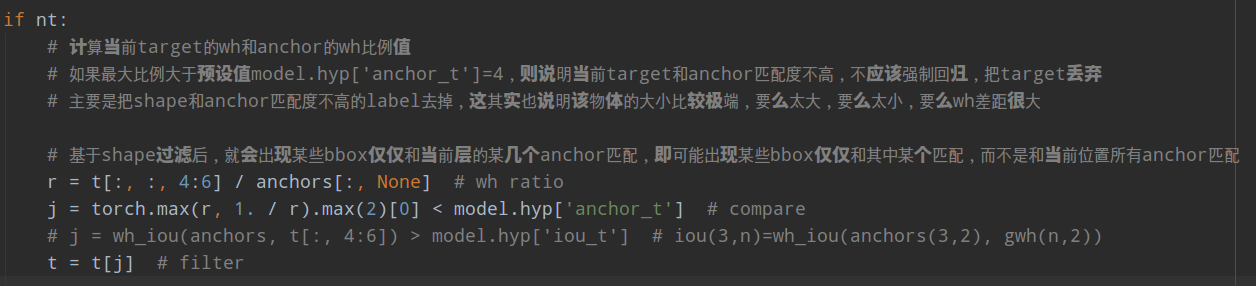
3.计算最近的2个邻居网格
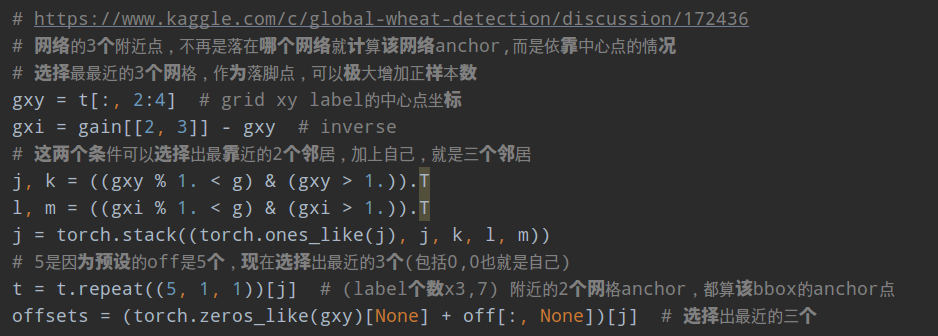
4.对每个bbox找出对应的正样本anchor,其中包括b表示当前bbox属于batch内部的第几张图片,a表示当前bbox和当前层的第几个anchor匹配上,gi,gj是对应的负责预测该bbox的网格坐标,gxy是不考虑offset或者说yolov3里面设定的该Bbox的负责预测网格,gwh是对应的归一化bbox wh,c是该Bbox类别
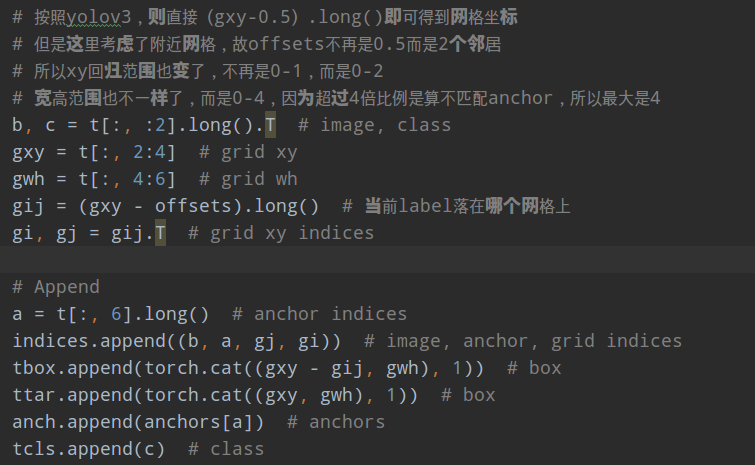
由于其采用了跨网格预测,故xy预测输出不再是0-1,而是-1~1,加上offset偏移,则为-0.5-1.5;并且由于shape过滤规则,wh预测输出也不再是任意范围,而是0-4。
整个build_targets代码虽然比较乱,但是计算效率是非常高的,没有常见的复现代码中的对batch进行for循环操作。
从上述可以发现:在任何一预测层,将每个bbox复制和anchor个数一样多的数目,然后将bbox和anchor一一对应计算,去除不匹配的bbox,然后对原始中心点网格坐标扩展两个邻居像素,增加正样本anchor。有个细节需要注意,前面shape过滤时候是不考虑bbox的xy坐标的,也就是说bbox的wh是和所有anchor匹配的,会导致找到的邻居也相当于进行了shape过滤规则,故对于任何一个输出层,如果该bbox保留,那么至少有3个anchor进行匹配,并且保留的3个anchor shape是一样大的。即保留的anchor在不考虑越界情况下是3或者6或者9。
(2) loss计算
有了上述数据,计算Loss就非常容易了。
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.Tensor([h['cls_pw']])).to(device)
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.Tensor([h['obj_pw']])).to(device)
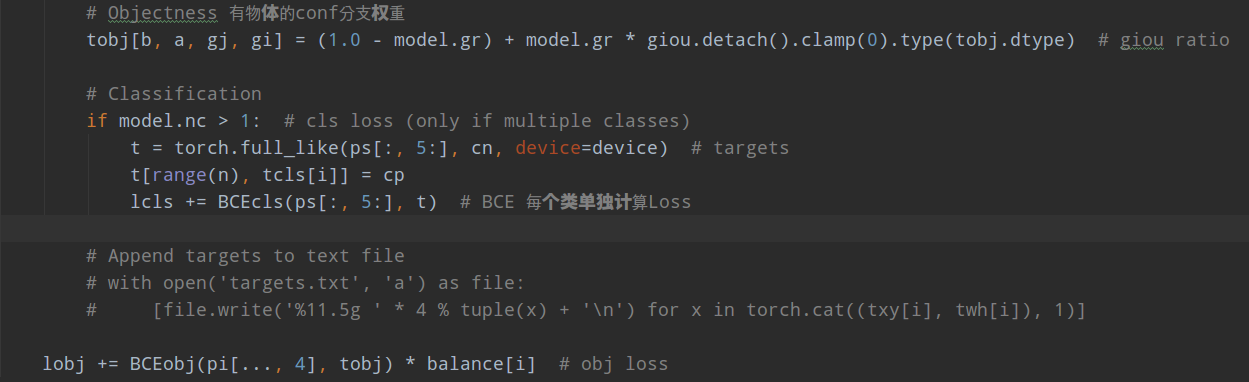
设置了正样本区域权重,cls和conf分支都是bce loss,xywh分支直接采用giou loss

注意:
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i] # wh
其没有采用exp操作,而是直接乘上anchors[i]。
类似fcos和yolov2,虽然我们引入了大量正样本anchor,但是不同anchor和gt bbox匹配度是不一样,预测框和gt bbox 的 匹配度也不一样,如果权重设置一样肯定不是最优的,故作者将预测框和bbox的giou作为权重乘到conf分支,用于表征预测质量。
核心内容就上面这些了。
1.3 可视化部分代码
对于上述我新增运行的可视化代码,代码比较长,如下所示:
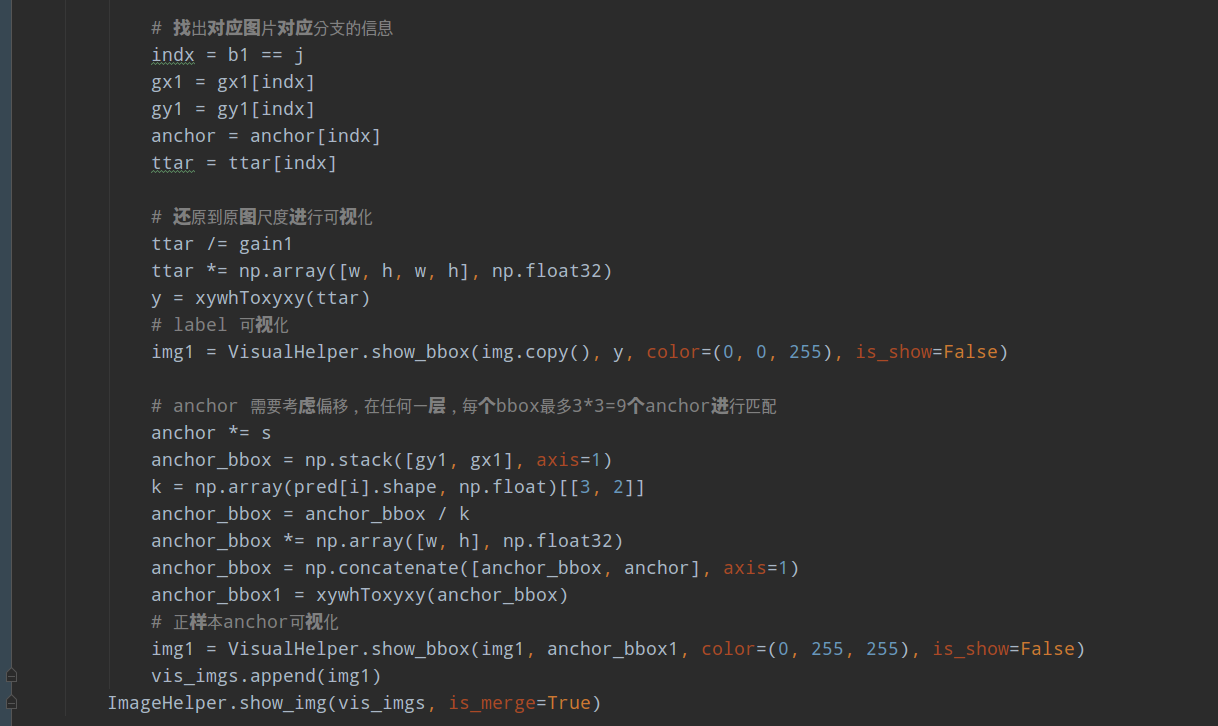
代码比较长,如果需要的直接联系我。
以上就是yolov5的所有核心内容了,至于推理逻辑和前yolo系列没有本质区别,就不分析了。
2 附加介绍
通过以上结束,yolov5的trick相比yolov4是少一些的,要说trick的话,主要包括:loss的平衡参数设计;模型ema;mosaic增强。但是如果考虑自动anchor重计算和最佳超参查找策略,那么trick就比较多了,这也是很多人吐槽说yolov5结构没有大改,全靠trick堆起来的原因。
我个人觉得不能这么说,首先自动anchor重计算策略,影响应该不是很大,除非是刚开始设置的anchor是随意设置的,一般我们都会基于实际项目数据重新运用kmean算法计算anchor,这一步本身就不能少;至于最佳超参查找策略,由于本身就非常耗时,应该只能在小数据上实验,而且这种trick本身就是通用做法,任何算法都可以直接用。
1.自动anchor重计算
对应函数是:check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
其原理是:
(1) 考虑到数据有进行随机增强,对dataset的所有bbox进行随机变换,
(2) 利用预设值anchor基于shape规则对bbox计算best possible recall。具体细节是:先利用n个bbox,shape=nx2,和9个anchor计算wh比例值;取wh中的最小值;取9个anchor中最大的比例值;比例值大于阈值,则认为匹配,计算匹配比例即可。由于其计算过程是max(min()),故是最大可能召回率
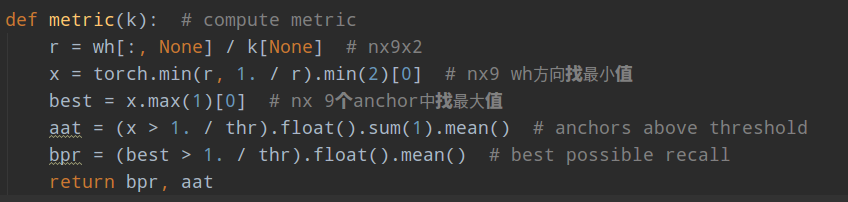
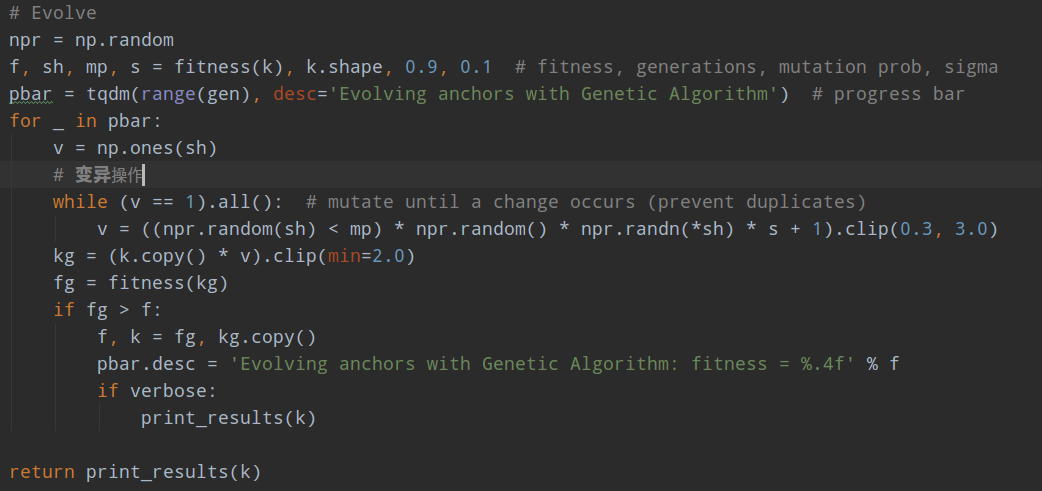
(3) 如果召回率大于0.98,则不用优化了,直接返回;如果小于0.98,则利用遗传算法+kmean重新计算anchor;一直迭代保存召回率最高的anchor即可。
可以看出,由于计算Loss时候匹配规则是shape,而不是iou,所以kmeans算法的聚类结果也是采用shape下召回率作为评估指标。
至于遗传算法+kmean计算anchor,也比较简单,遗传算法是最经典的智能优化算法,主要包括选择、交叉和变异三个步骤,先选择一些种子即初始值,然后经过适应度函数(评估函数)得到评估指标,对不错的解进行交叉和变异操作,进行下一次迭代。采用优胜劣汰准则不断进化,得到最优解。但是本文仅仅是模拟了遗传算法思想,因为其只有变异这一个步骤即对第一次运行得到的anchor进行随机变异操作,然后再次计算适应度函数值,选择最好的。
2. 最佳超参查找策略
这个就更加简单暴力了,直接设定一组要优化的超参,设定优化范围;然后随机初始化参数,进行train,保存结果;在下一代训练时候,对前述topk最佳超参进行随机选择一组参数,然后进行变异,然后再重新train,重复100遍;最后对搜索结果进行可视化挑选最佳参数。
3 总结
纵观整个yolov5代码,和前yolo系列相比,特点应该是
(1) 考虑了邻域的正样本anchor匹配策略,增加了正样本
(2) 通过灵活的配置参数,可以得到不同复杂度的模型
(3) 通过一些内置的超参优化策略,提升整体性能
(4) 和yolov4一样,都用了mosaic增强,提升小物体检测性能
其他一些操作包括:
(1) 采用了最新版本的pytorch进行混合精度以及分布式训练
(2) warmup+cos lr学习率策略,对bias不进行权重衰减
(3) 采用了yolo系列中常用的梯度累积策略,增加batch size,并对输出head部分的bias进行特殊初始化;采用了类平衡采样策略
(4) 多尺度训练,但是写的非常粗暴,直接对dataloader输出的batch图片进行双线性插值
(5) 支持onnx格式导出
(6) 采用了模型权重指数滑动平均的ema策略(比赛常用策略)
但是本仓库缺点是代码质量比较糟糕,类和类之间耦合非常严重,存在大量的直接修改类属性的方法,并且很多参数都是自己写死在代码里面,对于理解代码结构非常不利。
作者提供模型运行结果:

