@huanghaian
2020-07-20T09:39:00.000000Z
字数 5957
阅读 4093
从代码角度分析高效优雅检测模型CenterNet
目标检测
0 摘要
论文题目:Objects as Points
arxiv: 1904.07850
github: https://github.com/xingyizhou/CenterNet
从目前来看,centernet是一个速度和精度平衡的不错,且是anchor-free的算法。由于其简单的设计思想、超参少的特点,在很多对速度有要求的场合或者比赛中都有采用,应用还是非常广泛的。另一个精度蛮好的anchor-free经典算法是FCOS,学术界研究比较多,但是由于其速度较慢,超参蛮多,在应用案例中我很少看到其身影。
centernet非常简单,对于目标检测而言,只需要学中心点和相对的宽高属性即可。

如果说他还有其他牛逼之处的话,那就是:其将很多任务都归纳到整个框架中,例如可以直接用于2d目标检测、3d目标检测、深度估计、关键点检测等等任务中,属于通用做法,而其他anchor-free论文仅仅可用于2d目标检测。 对于目标检测任务,可以将bbox回归问题建模成学习bbox中心点+bbox宽高问题;而对于3d目标检测,也是基于中心点处学习出3d size(长宽高)、深度(距离)和方向(朝向);对于人体关键点任务,则是学习基于中心点的偏移属性。
单就目标检测而言,其仅仅需要单分支输出,不需要nms操作,超参少,速度快,精度也不错,这些特性足够吸引应用开发人员了。
1 算法分析
对于目标检测而言,其输出主要包括两条分支,一个是中心点回归分支;一条是基于中心点的宽高属性预测分支,如上图所示,为了提高中心点的预测精度,还引入了额外的reg分支,回归用于量化误差导致的中心点偏移,这个操作其实是采用cornernet算法的做法。
1.1 网络设计
(1) 骨架部分
骨架网络采用了4种,分别是ResNet-18, ResNet-101, DLA-34和Hourglass-104, ResNet-101和Hourglass-104都是超大模型,主要是拼精度,而ResNet-18和DLA-34是折中模型,整体来说DLA-34是速度和精度平衡最合适的模型。
Resnet骨架网络,我想大家都知道,但是DLA就不一定了,其网络图如下所示:
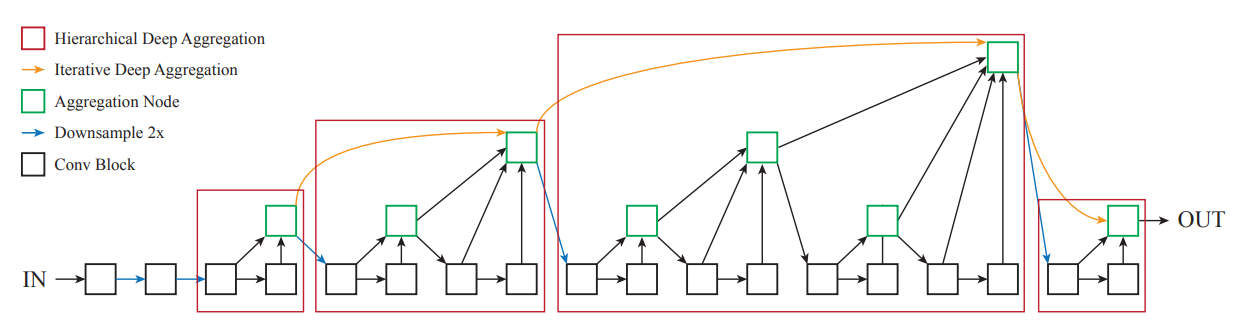
DLA引入了非常多的内部跳层连接和特征聚合操作。
(2) 上采样部分
为了保证中心点坐标回归的精度,高输出分辨率图是必需的,论文设置输出是输入的1/4倍,
对于Resnet而言,其参考人体姿态估计里面的经典算法Simple Baselines for Human Pose Estimation and Tracking,简单通过反卷积进行上采样到指定倍数,如下所示:
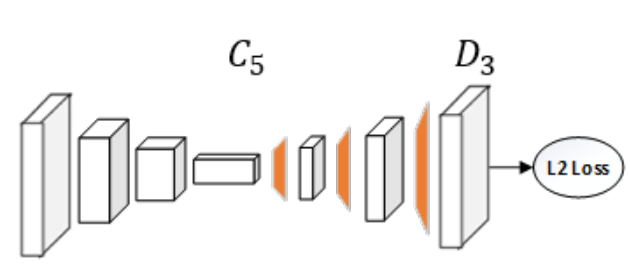
具体来说就是对resnet骨架输出的最后一层特征,采用三次反卷积操作,卷积核是4x4,得到相比原图输入小4倍的特征图。
具体代码在src/lib/models/networks/resnet_dcn.py
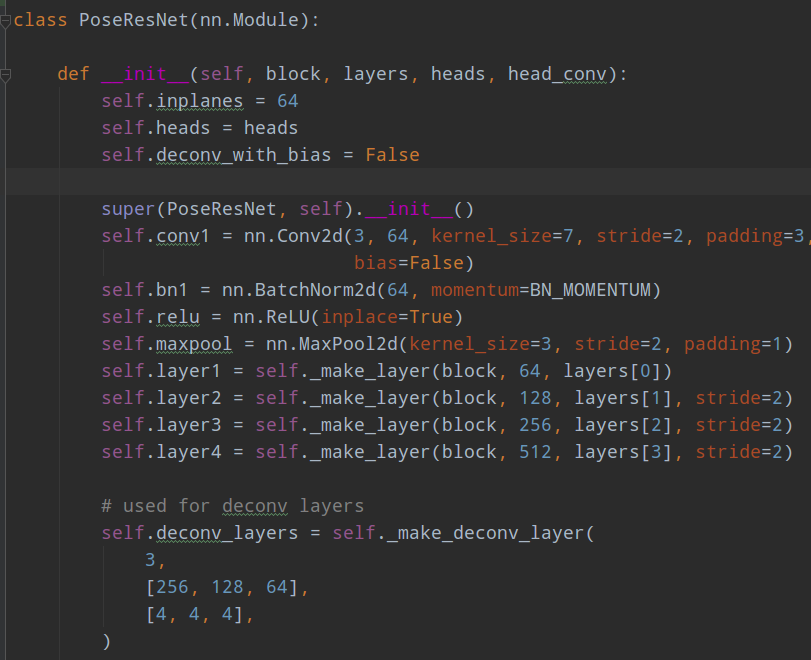
前面是标准的resnet特征提取结构,后面的deconv_layers就是反卷积层。同时为了增强特征提取能力,但是不会严重影响速度的情况下,对反卷积前面部分引入了变形卷积DCNV2。如果不想用变形卷积,则可以采用src/lib/models/networks/msra_resnet.py,由于这个算法是微软提出的,故命名是msra_resnet。
对于DLA也是差不多,在附录里面提供了结构图:
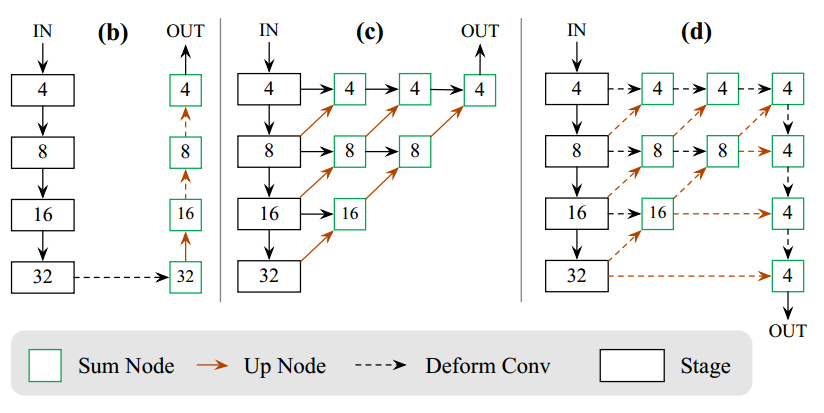
b是resnet带反卷积结构,虚线是引入了额外的DCNV2,c是原版dla带反卷积结构,对应的是src/lib/models/networks/dlav0.py,而d是本文稍微修改了下的结构src/lib/models/networks/pose_dla_dcn.py,看起来还是比较复杂。
(3) head部分
对于目标检测而言,输出三个特征图,分别是高斯热图(h/4,w/4,cls_nums),每个通道代表一个类别;宽高输出图(h/4,w/4,2),代表中心点距离左上边距值;中心点量化偏移图(h/4,w/4,2),这个分支对于目标检测而言可能作用不会很大,因为我们最终要的是bbox,而不是中心点,但是对于姿态估计而言就非常重要了。
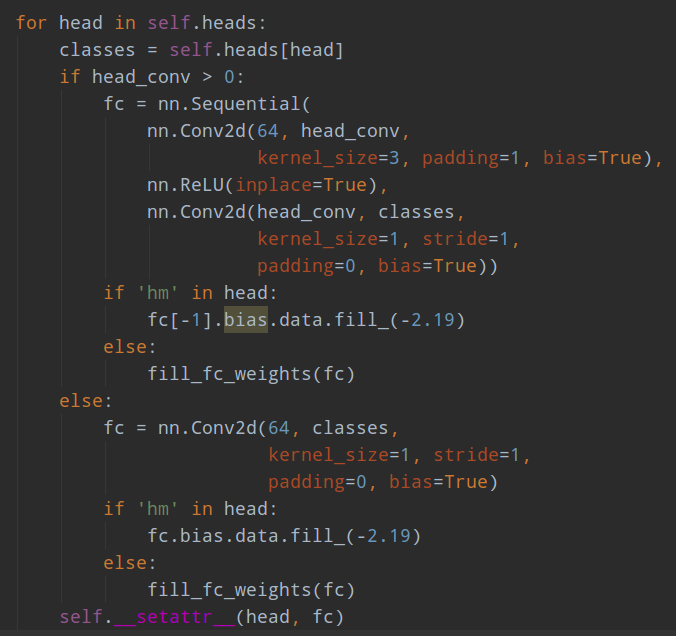
不得不说作者代码写的质量确实不咋地,各种参数到处是,而且写死了,要换个数据集要改几个地方。特别是命名,感觉就是凭心情乱写的,要弄明白这些简称要花费不少时间。
1.2 label生成过程
只有先弄懂label生成过程,才能对loss计算过程有个非常清晰的认识。整个label生成过程代码在src/lib/datasets/sample/ctdet.py,其外部采用的是多继承的方式实现dataset,
def get_dataset(dataset, task):
class Dataset(dataset_factory[dataset], _sample_factory[task]):
pass
return Dataset
其中dataset_factory[dataset]是COCO数据解析类,_sample_factory[task]是目标检测的datalayer即CTDetDataset,这两个类都是继承至pytorch的Dataset类。
对于python多继承而言,是按照先后顺序继承的,COCO类实现仅仅解析coco格式数据以及评估等等,而CTDetDataset才是真正实现了getitem方法,两个类的全部方法和属性合并才得到最终的datalayer层。这样写的好处很明显就是解耦,如果数据格式变了或是说是coco格式,但是内部变量数据值变了,此时就可以仅仅额外提供一个和COCO类一样的py文件即可,而不需要重写CTDetDataset类。但是这样写的缺点也很明显:代码可阅读性降低了很多,而且在CTDetDataset里面强制读取COCO类的属性,是没有代码提示的,因为如果不是多继承的写法,实际运行时候肯定是会报错了,加入了多继承后,子类就可以读取到父类里面的任何一个方法和属性。虽然看起来很优雅,但是这种实现方式不推荐,严重违背迪米特法则。
COCO这个类仅仅是为后面的CTDetDataset提供一些数据和属性。
(1) 图片和bbox前处理和数据增强
主要是利用一些随机得到中心点坐标、缩放尺度,利用这些参数可以得到仿射变换矩阵,然后应用于图片和bbox上得到新的指定大小为6512x512的图片和对应的bbox。期间还利用了颜色相关的增强。
本来这些操作都是常规操作,但是作者写的实在是太复杂了,我觉得没有这个必要。由于比较复杂,我暂时就不分析这个数据增强部分了。
(2) 对每个bbox进行遍历,计算label
首先是准备数据:
上述绘制高斯的函数,默认采用的loss不是mse,故实际上高斯生成函数是draw_umich_gaussian,而draw_msra_gaussian是姿态估计领域常用的高斯热图生成策略。至于这两个函数区别在哪里?我觉得作者自己都不清楚,我看到issue里面作者回复是umich是从cornernet库里面copy过来的,msra是从simplebase库里面copy过来的。我仔细看了下,其实没啥区别,要说区别的话,在相同的输入参数下,那就是:draw_msra_gaussian半径就是默认的sigma参数,所以绘制出来的热图显示会比较大;而draw_umich_gaussian的半径参数其实和sigma之间有个除以(2r+1)/6的转化关系,导致其热图显示比较小。如果在采用draw_msra_gaussian函数前把半径先转化为sigma,那么两个高斯图是完全相同的。
draw_umich_gaussian(hm[cls_id], ct_int, radius)
draw_msra_gaussian(hm1[cls_id], ct_int, radius)
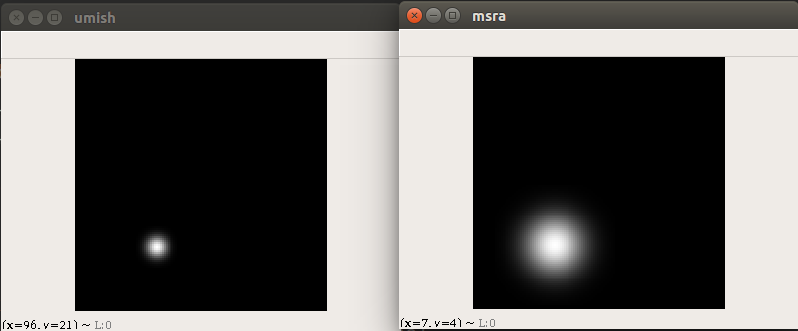
draw_umich_gaussian(hm[cls_id], ct_int, radius)
draw_msra_gaussian(hm1[cls_id], ct_int, (2*radius+1)/6)
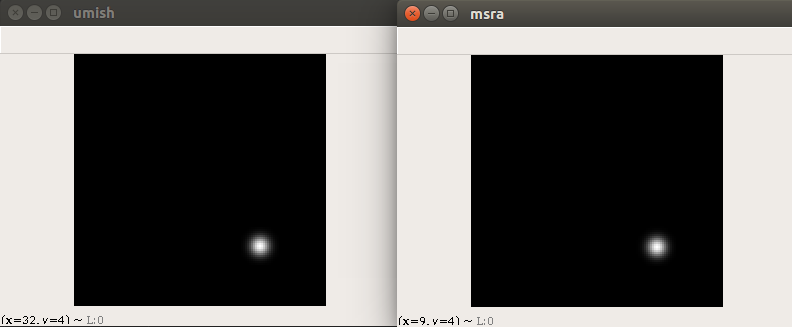
可以看出是一样的。
整个label生成过程非常简单:首先针对每个bbox的宽高计算出最合适的半径,然后对bbox中心生成高斯热图,同时把wh属性和offset保存起来即可。

wh分支和reg offset分支输出都是图,但是保存label时候是一维向量,原因是计算wh和ref offset分支时候都是只在某几个中心点才计算loss,或者说只有bbox中心点对应的位置才是正样本,其余位置不算loss,为了后续代码简单,在生成label时候就提前把这些位置按照bbox顺序存储起来了,reg存储的是offset,reg_mask是用来标记一共有多少个bbox,为了后续方便,还保存了bbox和类别信息到gt_det里面。后面结合Loss分析就能够看出这样设计label存储的好处了。
关于如何实现自适应计算高斯半径的代码,原论文没有公式说明,只有代码,比较难以理解,在issue里面有人进行了分析,有兴趣的可以自行查看 https://github.com/princeton-vl/CornerNet/issues/110
在后续论文里面有指出虽然你是自适应半径,但是你生成的高斯图还是圆形的,最make sense的做法应该是椭圆形的高斯图。
1.3 loss计算
(1) 中心点回归Loss
对于中心点回归分支和中心点量化偏移分支的Loss计算和cornernet完全相同。中心点热图回归分支是focal loss的变种:
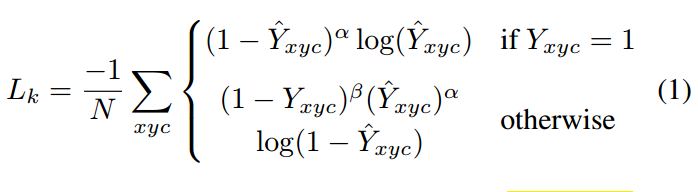
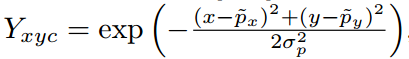
Y是高斯热图,其中对应的bbox中心坐标位置是1,其余都是小于0的,呈现高斯分布。p是整数量化后的关键点,例如如果中心坐标是321x200,下采样4倍后,得到量化后中心点坐标为80x50。是高斯分布标准差,基于bbox的形状来自适应计算得到。是focal loss的两个参数。
按照分类正负样本角度来看,只有当Y=1的位置可以认为是正样本,其余位置都是负样本,但是由于非常靠近1的地方也是近似正样本,故虽然其当做负样本,但是其权重比较小,随着越来越远离中心点,其loss权重越来越小。为了对比,贴下focal loss公式:
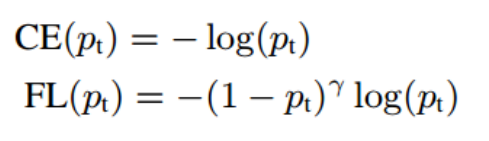
仔细观察可以发现,如果把去掉其实就是标准的focal loss。为啥要这样设计的原因是我们希望预测输出图不是非0即1的,而是呈现高斯分布的。其实这个设计比较复杂,按照姿态估计里面的做法,直接采用mse监督就行了。在作者的代码里面其实提供了这个选项来切换focal loss和mse loss。
mse loss就没啥好说的了,对于修改版本的focal loss代码在models/losses.py的Focal loss类里面,具体是函数_neg_loss,非常简单。

(2) 宽高和偏移回归分支
宽高回归分支采用的是l1 loss,具体来说是RegL1Loss。本来这个Loss非常简单,没有啥好说的,但是由于该分支仅仅在bbox中心点位置才计算loss,其余地方全部忽略,所以还是要说一下。其实这样训练很不好,这个分支是密集预测输出,但是只有几个点位置才计算loss,会导致网络整体收敛很慢。后面有论文进行了改进,在下一篇文章中详细说明。
要实现仅仅几个点位置计算loss,则需要先利用索引把位置挑选出来,核心函数就是_transpose_and_gather_feat,输入特征图和对应的位置。

总体的loss为:
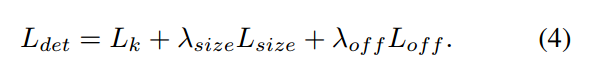
有个细节需要注意: 宽高回归分支的label是原图尺度的值,而没有进行任何归一化。为了平衡三个loss,size分支的权重设置为0.1,off分支权重设置为1。
1.4 网络推理
网络推理流程如下:
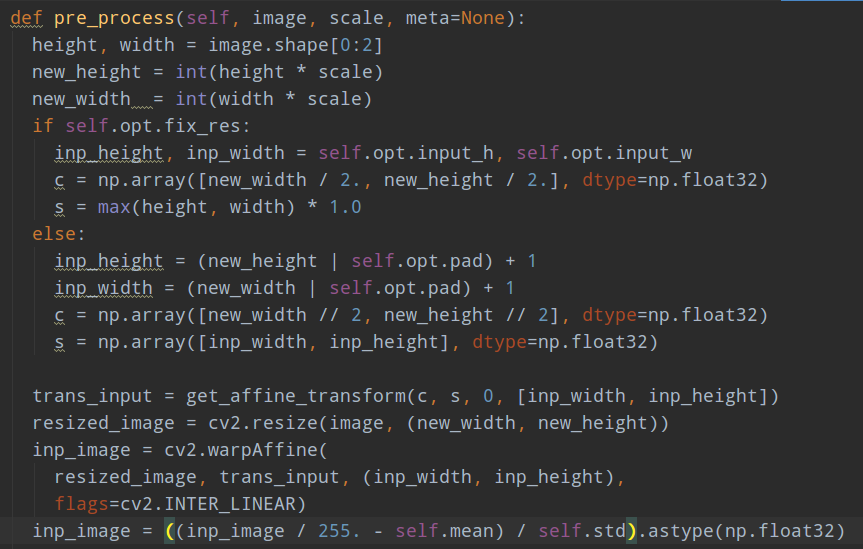
(1) 对图片预处理
和训练label生成类似,将图片采用仿射变换转化为512x512的大小,同时存储下后续还原需要的参数;然后减均值除方差即可
(2) 网络推理
with torch.no_grad():
output = self.model(images)[-1]
hm = output['hm'].sigmoid_()
wh = output['wh']
reg = output['reg'] if self.opt.reg_offset else None
if self.opt.flip_test:
hm = (hm[0:1] + flip_tensor(hm[1:2])) / 2
wh = (wh[0:1] + flip_tensor(wh[1:2])) / 2
reg = reg[0:1] if reg is not None else None
高斯热图输出是0-1,所以对输出进行sigmoid操作即可,宽高回归分支没有进行scale操作
(3) 后处理
首先对中心点回归热图分支进行基于关键点的nms操作,其实就是采用3x3的maxpool操作,然后把不是最大值的位置设置为0,就可以把最大值附近的值抑制掉。
def _nms(heat, kernel=3):
pad = (kernel - 1) // 2
hmax = nn.functional.max_pool2d(
heat, (kernel, kernel), stride=1, padding=pad)
keep = (hmax == heat).float() # 抑制掉不是最大值位置的值
return heat * keep
然后对中心坐标进行topk算法,k默认取100,返回对应索引,
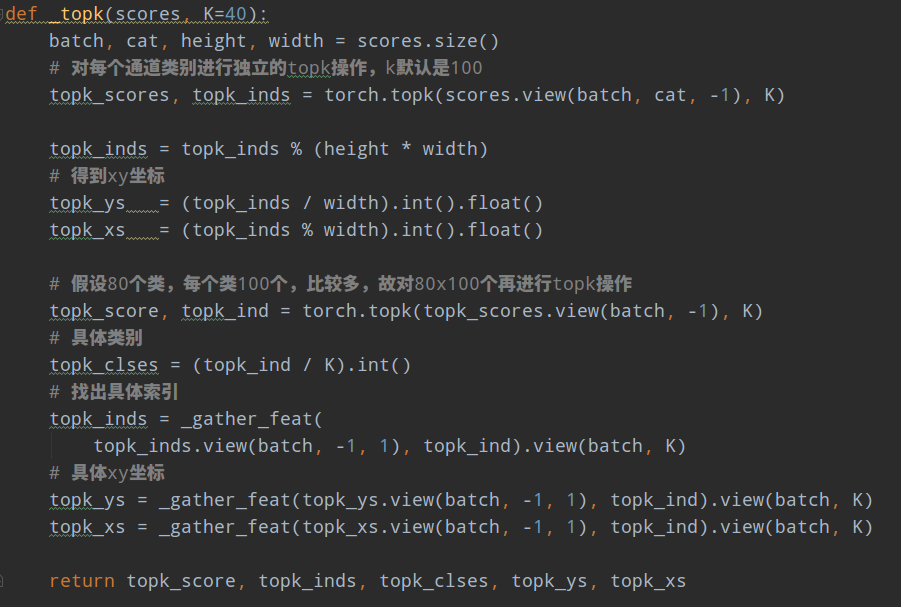
对宽高回归分支和量化误差offset分支采用同样处理。
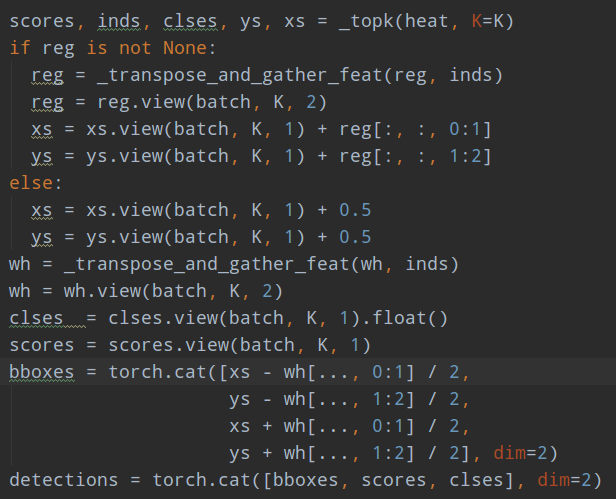
此时就可以得到检测结果了。可以看出是没有采用标准的nms操作。
采用作者提供模型,运行demo代码,可以得到如下结果(有可视化阈值0.3从100个bbox里面挑选出大于阈值的):

如果应用了多尺度测试,那么还是需要nms的。
附加一句: 这个工程项目基于pyotrch0.4.1开发的,但是对于现在来说这个太老了,所以如果想迁移到pytorch1.0以上,那么只需要将变形卷积部分代码换成最新版即可,我的环境是pytorch1.3.0,只需要将src/lib/models/networks/DCNv2整个文件夹替换为https://github.com/CharlesShang/DCNv2里面的代码,然后编译下就可以用了,可以直接运行作者训练好的权重。
2 实验结果分析

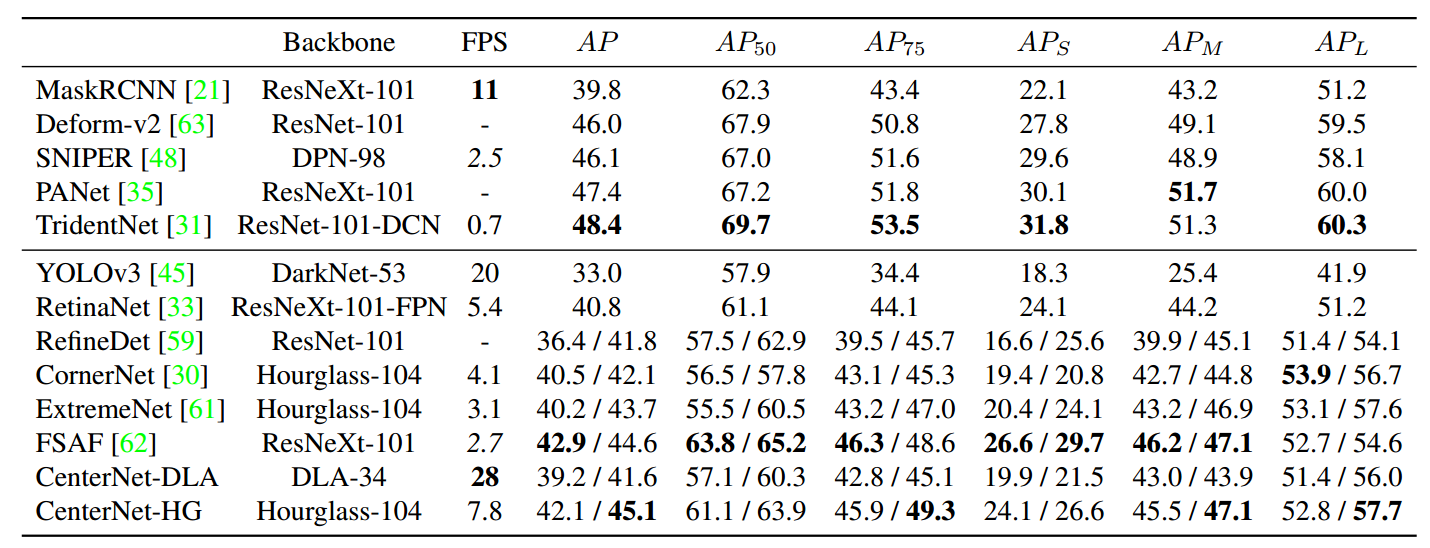
可以看出,Hourglass-104和Resnet-101模型非常大,精度蛮高,速度太慢了,而DLA34速度和精度都不错。

注意epoch,可以发现这个网络需要的训练时间非常长,居然要这么多epoch,这也是这个算法最大的缺点,后续在论文TTFNet里面有专门解决,下一篇文章再进行分析。
