@huanghaian
2020-03-19T06:51:33.000000Z
字数 2775
阅读 1770
ThunderNet
目标检测
论文题目:ThunderNet: Towards Real-time Generic Object Detection ICCV2019
论文地址:arxiv 1903.11752
官方开源代码还没有公开,网上有复现,但是效果还达不到论文指标,还在更新中
第三方复现:https://github.com/ouyanghuiyu/Thundernet_Pytorch
简介
为了进一步减小计算开销,使得两阶段的检测网络能够在移动嵌入式设备上实现实时运行。CNN可分为backbone和detect head两部分,从两个角度同时改进,提取更好的特征,更有效检测目标的同时轻量化网络。其主要基于Shufflenet v2和Lighthead r-cnn(Light-Head R-CNN: In Defense of Two-Stage Object Detector,也是旷视自己发表的论文,主要目的是提高two-stage速度)改进,本文主要是应用价值较大,论文创新点不多,都是为了提速且不降低性能而设计,涉及到大量细节。实时目标检测一般都是One-stage算法,例如yolo和ssd,作者认为two-stage的效果理论上会好于one-stage,但是目前还没有满足实时要求的two-stage算法,故本文从two-stage着手,基于轻量级骨架shufflenetv2和轻量级检测头lighthead rcnn进行改进。
主要有两部分创新:
- Backbone part,提出轻量级主干网络SNet
- Detection part,参考Light-Head R-CNN的设计,对RPN和R-CNN子网进一步压缩。对于小主干和小特征图产生的性能退化问题,提出两个高效的block:Context Enhancement Module(CEM),组合多尺寸的特征图来整合本地和全局上下文信息;Spatial Attention Module(SAM),使用RPN中的上下文信息来优化RoI warping的特征分布
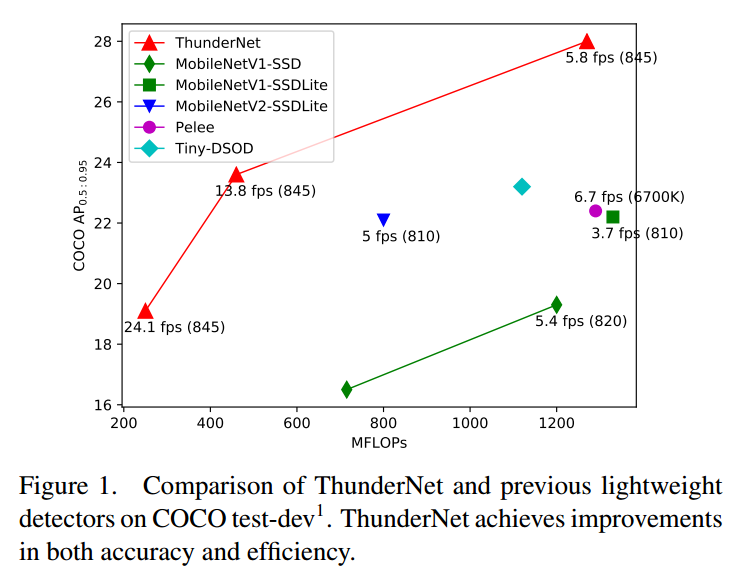
模型
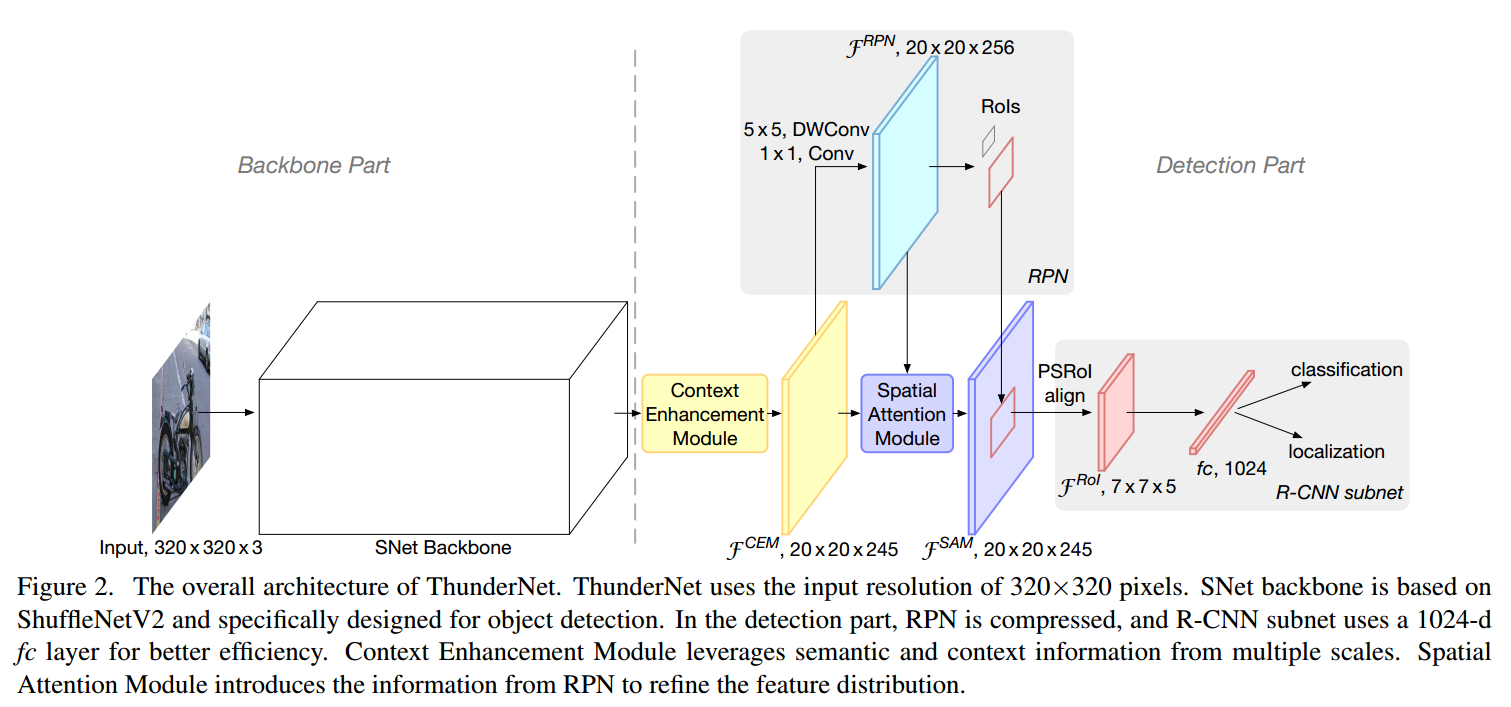
骨架网络
(1) 输入分辨率
通常而言two-stage目标检测网络,都是输入800x的图,而ThunderNet采用的输入分辨率为320 *320, 主要是为了加快速度。同时作者通过实验分析,得出输入分辨率和主干网络应该相符( the input resolution should match the capability of the backbone ),大分辨率小主干网络和小分辨率大主干网络都是不可取的。小的输入图片产生更小的feature maps 但是会导致严重的细节丢失,而且很难通过增大主干网络来修复;另一方面,小的主干网络很难编码大的输入图片所包含的富裕信息

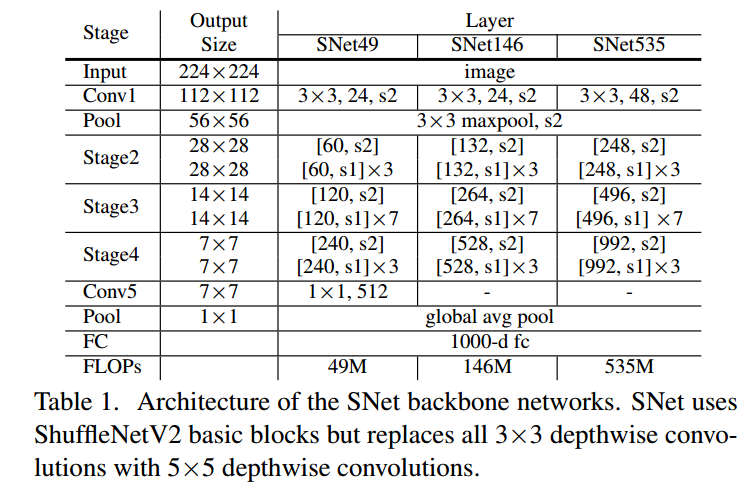
(2) 骨架网络
作者认为骨干网络需要具有两大特点,第一:较大的感受野。第二:浅层特征位置信息丰富,深层特征区分度更大,因此Backbone Networks需要同时兼顾这两种特征。ShuffleNetV1/V2限制了感受野,ShuffleNetV2 和MobileNetV2 缺乏浅层特征,而Xception 在计算预算低下的情况下缺乏深层特征。
基于此,作者对ShufflenetV2提出下列改进:
- 使用5×5 depthwise convolutions替换原来ShufflenetV2中所有的3×3 depthwise convolutions来增大感受野(从121 到 193 )
- 在SNet146 和 SNet535, 去除 Conv5 ,同时在浅层特征提取阶段加入更多通道以增加底层特征
- 在SNet49中,压缩Conv5 的通道为 512, 同时在浅层特征提取阶段加入更多通道,以便实现浅层和深层特征间更好的平衡。作者同时认为去掉Conv5,骨干网络就无法提取足够的信息,而且要是保留1024维度的Conv5层,骨干网络就会受到有限的浅层特征的影响。
基于上述设置,提出了三种不同形式的SNet网络,SNet49用于更快的推理,SNet535用于更好的精度,SNet146用于更好的速度/精度权衡。
(3) 检测部分
(3-1) 压缩RPN
将RPN的256通道3 * 3卷积压缩为5 * 5深度可分离卷积和1 * 1卷积,使用了5尺度5比例25个anchor;
与light-head类似,沿用R-FCN的结构,进一步位置敏感特征图通道数压缩到5; 减少了测试阶段的RoI数目。5个尺度是{32,64,128,256,512},5个比例是{1:2, 3:4, 1:1, 4:3, 2:1}。
(3-2) 压缩检测头
- 在 RoI warping前面的α × p × p channels的feature map 中使用α = 5 (p = 7)替换原来的α = 10 (p = 7)
- 使用PSRoI align代替RoI warping
- R-CNN子网络使用1024维的全连接层,提高速度
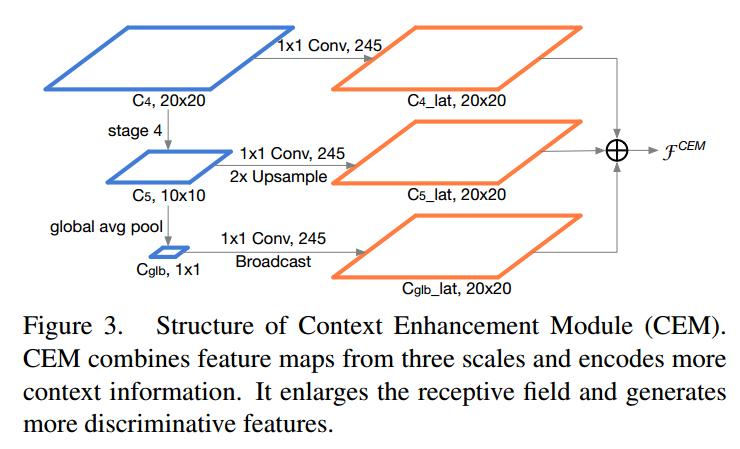
(3-3) 上下文增强模块
Context Enhancement Module整合局部和全局特征增强网络特征表达能力。CEM融合来自三个尺度的特征图:C4,C5和Cglb(在C5上应用global average pooling得到的全局特征信息)
- C4:C4特征图上应用1×1卷积将通道数量压缩为α×p×p = 245
- C5:C5进行2X上采样,C5特征图上应用1×1卷积将通道数量压缩为α×p×p = 245
- Cglb:Cglb进行Broadcast ,Cglb特征图上应用1×1卷积将通道数量压缩为α×p×p = 245
CEM增大感受野的同时,增强feature map的表达能力。因为CEM只有两个1*1卷积和一个全连接层,因此计算也很高效。
(3-4) 空间注意力模块
Spatial Attention Module空间注意模块,通过引入来自RPN的前后景信息用以优化feature map的特征分布(前景信息多,背景信息少), SAM融合分别来自于CEM的 thin feature map和来自RPN的intermediate feature map 信息。

使用来自RPN的intermediate feature map 信息对CEM的 thin feature map信息加权编码(增强前景特征,抑制背景特征)。
实验
训练细节:


作者指出由于网络比较简单,故数据增强非常重要,作者采用了ssd论文中提到的大量数据增强技巧,并且使用多尺度训练,和同步BN。分别在voc和coco上面进行训练和测试
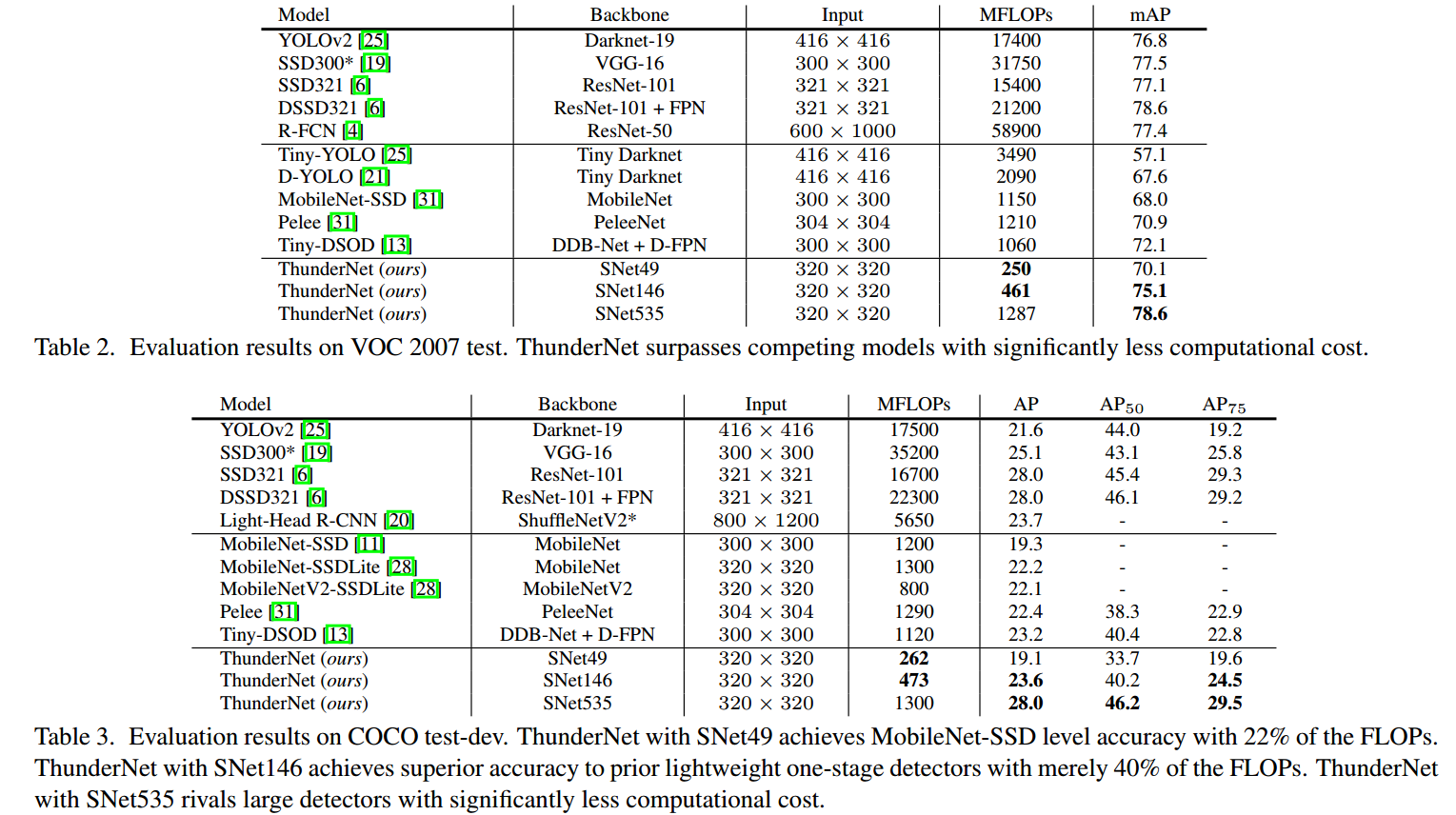


总结
(1) 输入分辨率应该match模型的大小,两者不匹配效果都不好
(2) backbone和head的大小也要match
(3) SAM模块利用RPN的二分类信息训练前景监督器,使模型更加集中关注前景
总的来说,在输入图片320x320情况下,性能是非常好的。但是要训练到这么好的效果应该存在很多训练技巧,光改改模型应该是提升不了这么多,从第三方复现可以看下,自己重头训练很难达到这么好的效果,具体效果要等官方开源核心代码才能知道。
