@huanghaian
2020-04-07T00:31:46.000000Z
字数 10117
阅读 2210
目标检测正负样本区分策略和平衡策略总结(一)
目标检测
0 简介
本文抛弃网络具体结构,仅仅从正负样本区分和正负样本平衡策略进行分析,大体可以分为正负样本定义、正负样本采样和平衡loss设计三个方面,主要是网络预测输出和loss核心设计即仅仅涉及网络的head部分。所有涉及到的代码均以mmdetection为主。本文是第一部分,主要包括faster rcnn、libra rcnn、retinanet、ssd和yolo一共5篇文章。下一篇会包括anchor-free的平衡策略,以及最新改进算法。
1 anchor-base
1.1 two-stage
1.1.1 faster rcnn
论文名称:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
(1) head结构
faster rcnn包括两个head:rpn head和rcnn head。其结构如下:
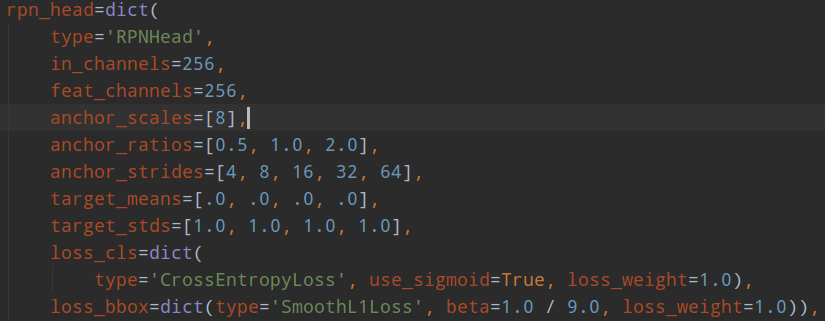
rpn head的输出是包括分类和回归,分类是二分类,只区分前景和背景;回归是仅仅对于前景样本(正样本)进行基于anchor的变换回归。rpn head的目的是提取roi,然后输入到rcnn head部分进行refine。
rcnn head的输出是包括分类和回归,分类输出是类别数+1(1是考虑背景),回归是仅仅对于前景样本不考虑分类类别进行基于roi的变换回归,rcnn head的目的是对rpn提取的roi特征进行refine,输出精准bbox。
(2) 正负样本定义
rpn和rcnn的正负样本定义都是基于MaxIoUAssigner,只不过定义阈值不一样而已。
rpn的assigner:
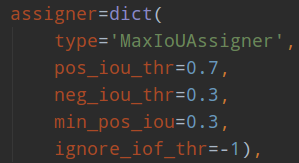
rcnn的assigner:

下面对MaxIoUAssigner进行详细分析。首先分析原理,然后分析细节。
正负样本定义非常关键。MaxIoUAssigner的操作包括4个步骤:
- 首先初始化时候假设每个anchor的mask都是-1,表示都是忽略anchor
- 将每个anchor和所有gt的iou的最大Iou小于neg_iou_thr的anchor的mask设置为0,表示是负样本(背景样本)
- 对于每个anchor,计算其和所有gt的iou,选取最大的iou对应的gt位置,如果其最大iou大于等于pos_iou_thr,则设置该anchor的mask设置为1,表示该anchor负责预测该gt bbox,是高质量anchor
- 3的设置可能会出现某些gt没有分配到对应的anchor(由于iou低于pos_iou_thr),故下一步对于每个gt还需要找出和最大iou的anchor位置,如果其iou大于min_pos_iou,将该anchor的mask设置为1,表示该anchor负责预测对应的gt。通过本步骤,可以最大程度保证每个gt都有anchor负责预测,如果还是小于min_pos_iou,那就没办法了,只能当做忽略样本了。从这一步可以看出,3和4有部分anchor重复分配了,即当某个gt和anchor的最大iou大于等于pos_iou_thr,那肯定大于min_pos_iou,此时3和4步骤分配的同一个anchor。
从上面4步分析,可以发现每个gt可能和多个anchor进行匹配,每个anchor不可能存在和多个gt匹配的场景。在第4步中,每个gt最多只会和某一个anchor匹配,但是实际操作时候为了多增加一些正样本,通过参数gt_max_assign_all可以实现某个gt和多个anchor匹配场景。通常第4步引入的都是低质量anchor,网络训练有时候还会带来噪声,可能还会起反作用。
简单总结来说就是:如果anchor和gt的iou低于neg_iou_thr的,那就是负样本,其应该包括大量数目;如果某个anchor和其中一个gt的最大iou大于pos_iou_thr,那么该anchor就负责对应的gt;如果某个gt和所有anchor的iou中最大的iou会小于pos_iou_thr,但是大于min_pos_iou,则依然将该anchor负责对应的gt;其余的anchor全部当做忽略区域,不计算梯度。该最大分配策略,可以尽最大程度的保证每个gt都有合适的高质量anchor进行负责预测,
下面结合代码进行分析:主要就是assign_wrt_overlaps函数,核心操作和注释如下:
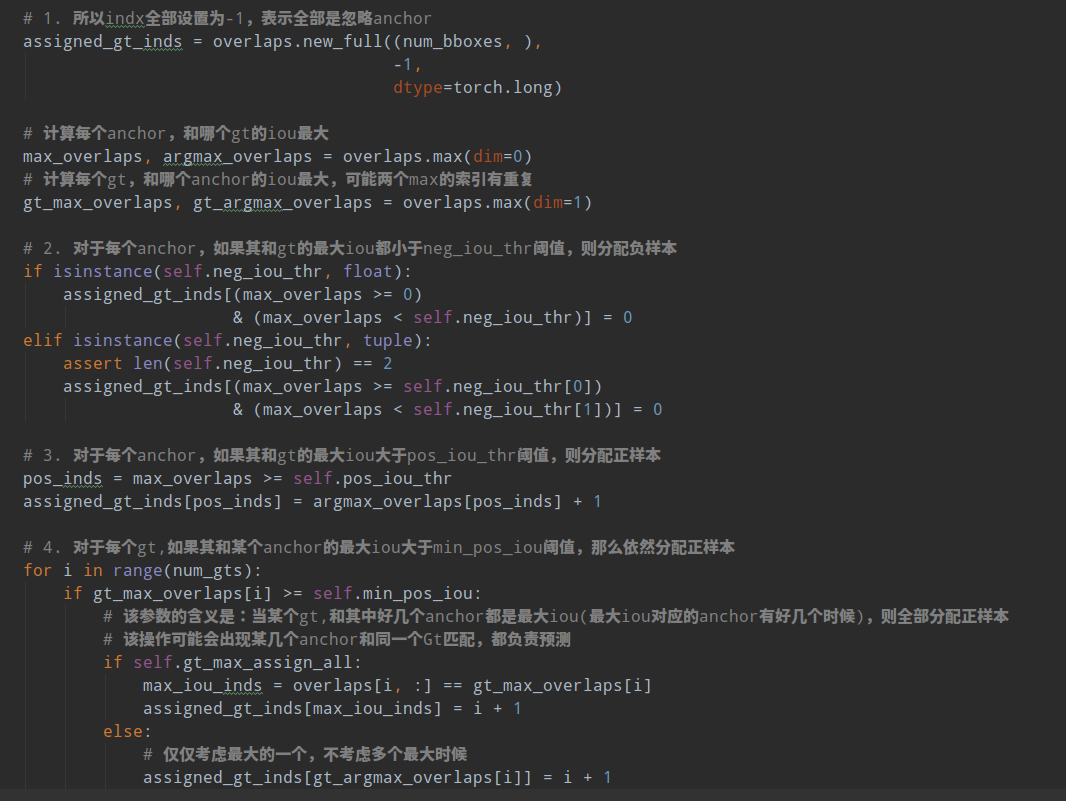
通过代码可以发现,当设置self.gt_max_assign_all=True时候是可能出现第4步的某个gt和多个anchor匹配场景,默认参数就是True。
由于rcnn head预测值是rpn head的refine,故rcnn head面对的anchor(其实就是rpn输出的roi)和gt的iou会高于rpn head部分,anchor质量更高,故min_pos_iou阈值设置的比较高,由于pos_iou_thr和neg_iou_thr设置都是0.5,那么忽略区域那就是没有了,因为rcnn head面对的都是高质量样本,不应该还存在忽略区域。
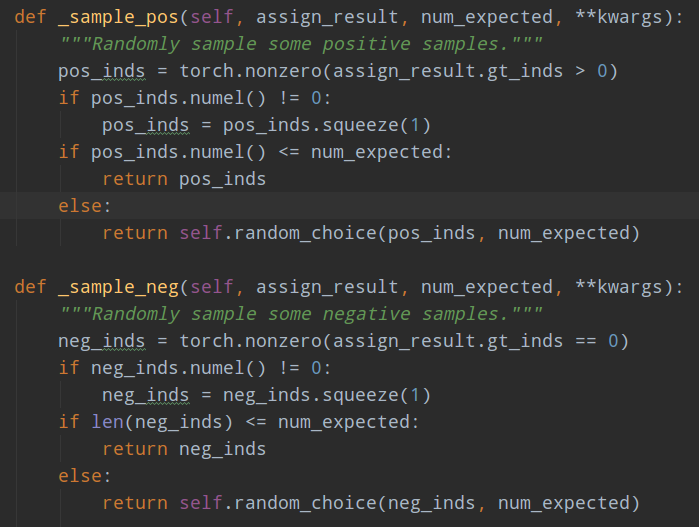
(3) 正负样本采样
步骤2可以区分正负和忽略样本,但是依然存在大量的正负样本不平衡问题,解决办法可以通过正负样本采样或者loss上面一定程度解决,faster rcnn默认是需要进行正负样本采样的。
rpn head和rcnn head的采样器都比较简单,就是随机采样,阈值不一样而已。
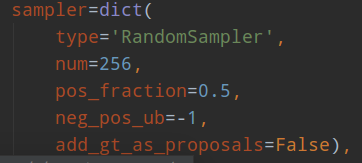
rpn head采样器:
rcnn head采样器:
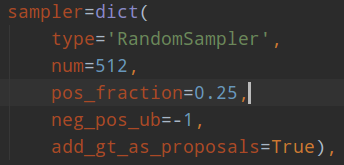
num表示采样后样本总数,包括正负和忽略样本,pos_fraction表示其中的正样本比例。add_gt_as_proposals是为了放在正样本太少而加入的,可以保证前期收敛更快、更稳定,属于技巧。neg_pos_ub表示正负样本比例,用于确定负样本采样个数上界,例如我打算采样1000个样本,正样本打算采样500个,但是可能实际正样本才200个,那么正样本实际上只能采样200个,如果设置neg_pos_ub=-1,那么就会对负样本采样800个,用于凑足1000个,但是如果设置为neg_pos_ub比例,例如1.5,那么负样本最多采样200x1.5=300个,最终返回的样本实际上不够1000个。默认情况neg_pos_ub=-1。
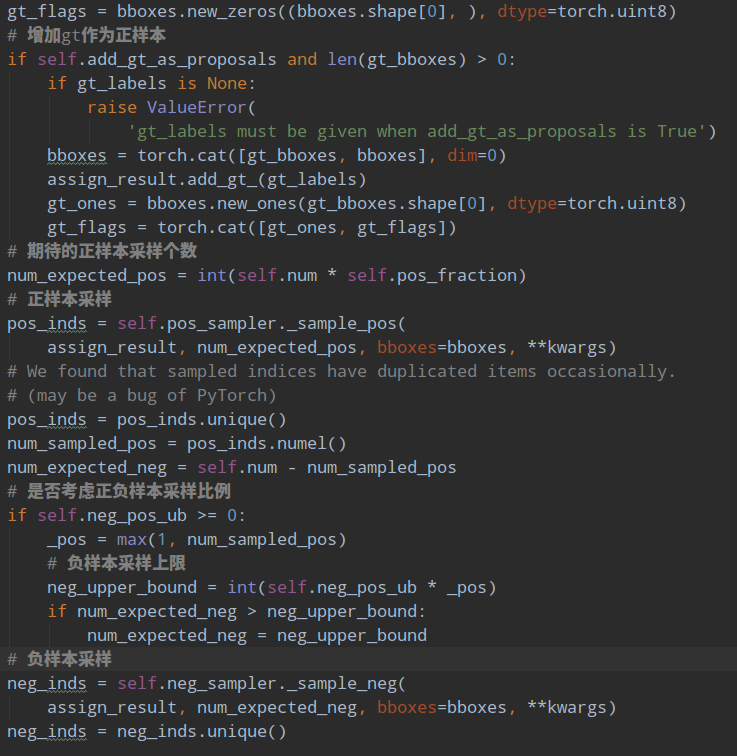
由于rcnn head的输入是rpn head的输出,在网络训练前期,rpn无法输出大量高质量样本,故为了平衡和稳定rcnn训练过程,通常会对rcnn head部分添加gt作为proposal。
其代码非常简单:
对正负样本单独进行随机采样就行,如果不够就全部保留。
由于原始faster rcnn采用的loss是ce和SmoothL1Loss,不存在loss层面解决正负样本不平衡问题,故不需要分析loss。
1.1.2 libra rcnn
论文名称:Libra R-CNN: Towards Balanced Learning for Object Detection
libra主要是分析训练过程中的不平衡问题,提出了对应的解决方案。由于libra rcnn的head部分和正负样本定义没有修改,故不再分析,仅仅分析正负样本采样和平衡loss设计部分。
(1) 正负样本采样
注意libra rcnn的正负样本采样规则修改仅仅是对于rcnn而言,对于rpn head没有任何修改,依然是随机采样器。原因是作者的主要目的是为了涨点mAP,作者认为rpn涨几个点对最终bbox 预测map没有多大帮助,因为主要是靠rcnn部分进行回归预测才能得到比较好的mAP。
其参数如下:
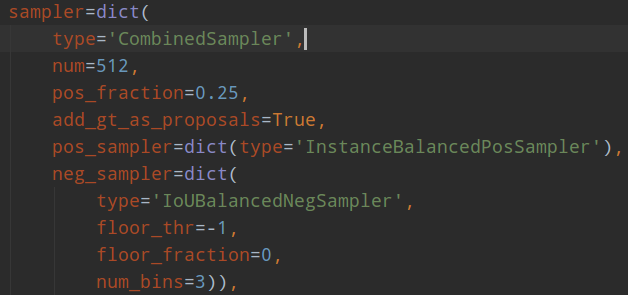
主要看IoUBalancedNegSampler部分即可。仅仅作用于负样本(iou=0~0.5之间)。作者认为样本级别的随机采样会带来样本不平衡,由于负样本本身iou的不平衡,当采用随机采样后,会出现难负(iou 0.5附近)和易负(iou接近0)样本不平衡采样,导致后面性能不好。作者发现了如果是随机采样的话,随机采样到的样本超过70%都是在IoU在0到0.05之间的,都是易学习负样本,作者觉得是不科学的,而实际统计得到的事实是60%的hard negative都落在IoU大于0.05的地方,但是随机采样只提供了30%,实在是太少了。最常用的解决难易样本不平衡问题的解决办法就是ohem,基于Loss排序来采样难负样本,但是作者分析,(1) 这种方法对噪音数据会比较敏感,因为错误样本loss高;(2) 参数比较难调。所以作者提出了IoU-balanced Sampling,如下所示:
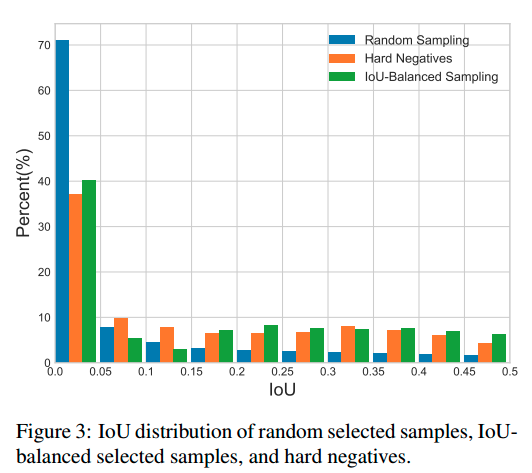
可以看出,随机采样效果最不好,而iou balanced sampling操作会尽量保证各个iou区间内都会采样到。
由于该操作比较简单,就不贴论文公式了。核心操作是对负样本按照iou划分k个区间,每个区间再进行随机采样,保证易学习负样本和难负样本比例尽量平衡,实验表明对K不敏感,作者设置的是3。
具体做法是对所有负样本计算和gt的iou,并且划分K个区间后,在每个区间内均匀采样就可以了。假设分成三个区间,我想总共取9个,第一个区间有20个候选框,第二个区间有10个,第三个区间有5个,那这三个区间的采样概率就是9/(3x20),9/(3x10),9/(3x5),这样的概率就能在三个区间分别都取3个,因为区间内候选框多,它被选中的概率小,最终体现各个区间都选这么多框。
实际代码做法是:首先按照iou分成k个区间,先尝试在不同区间进行随机采样采相同多数目的样本,如果不够就全部采样;进行一轮后,如果样本数不够,再剩下的样本中均匀随机采样。例如假设总共有1000个候选负样本(区间1:800个,区间2:120个,区间3:80个),分为3个区间,总共想取333个,那么理论上每个区间是111个,首先第一次在不同区间均匀采样,此时区间1可以采样得到111个,区间2也可以得到111个,区间3不够,所以全部保留;然后不够的样本数,在剩下的(800-111)+(120-111)+0个里面随机取31个,最终补齐333个。
核心代码如下:
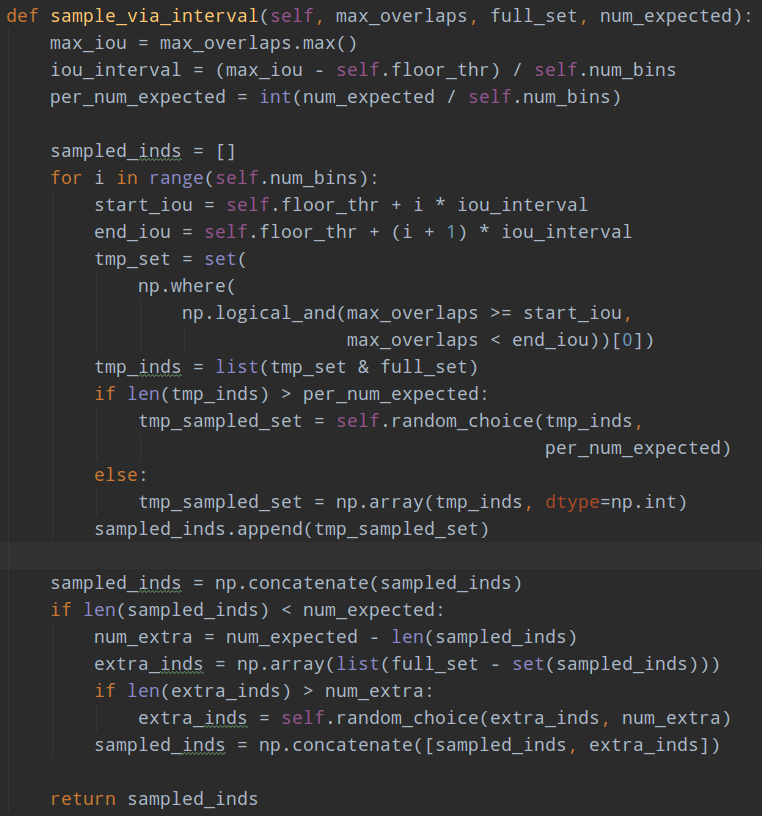
意思是在各个区间内,如果够数目就随机采样,如果不够那就剩下的负样本里面全部采样。
(2) 平衡回归loss
原始的faster rcnn的rcnn head,使用的回归loss是smooth l1,作者认为这个依然存在不平衡。作者分析是:loss解决Classification和Localization的问题,属于多任务loss,那么就存在一个平衡权重,一般来说回归权重会大一些,但一味的提高regression的loss其实会让outlier的影响变大(类似于OHEM中的noise label),outlier外点样本这里作者认为是样本损失大于等于1.0,这些样本会产生巨大的梯度不利于训练过程,小于的叫做inliers。平衡回归loss的目的是既不希望放大外点对梯度的影响,又要突出内点中难负样本的梯度,从而实现对外点容忍,对内点区分难负样本的作用。为此作者在smooth l1的基础上进行重新设计,得到Balanced L1 Loss。核心操作就是想要得到一个当样本在 附近产生稍微大点的梯度的函数。
首先smooth l1的定义如下:
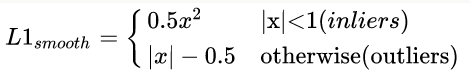
其梯度如下:
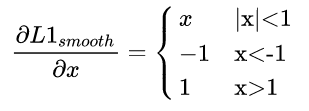
为了突出难样本梯度,需要重新设计梯度函数,作者想到了如下函数:

梯度公式可以实现上述任务。然后反向计算就可以得到Loss函数了。为了保证连续,还需要增加(9)的限制。
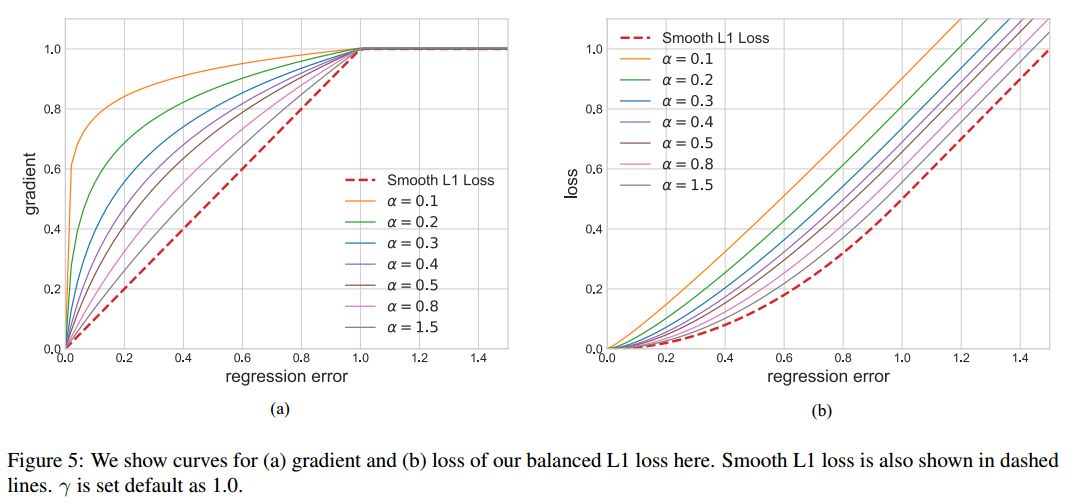
左边是梯度曲线,右边是loss曲线,可以看出非常巧妙。
1.2 one-stage
1.2.1 focal loss
论文名称:Feature Pyramid Networks for Object Detection
该论文也叫做retinanet,是目前非常主流的FPN目标检测one-stage网络结构,本文主要是提出了一个focal loss来对难易样本进行平衡,属于平衡loss范畴。
(1) 网络结构
由于该网络结构非常流行,故这里仅仅简要说明下,不做具体分析。
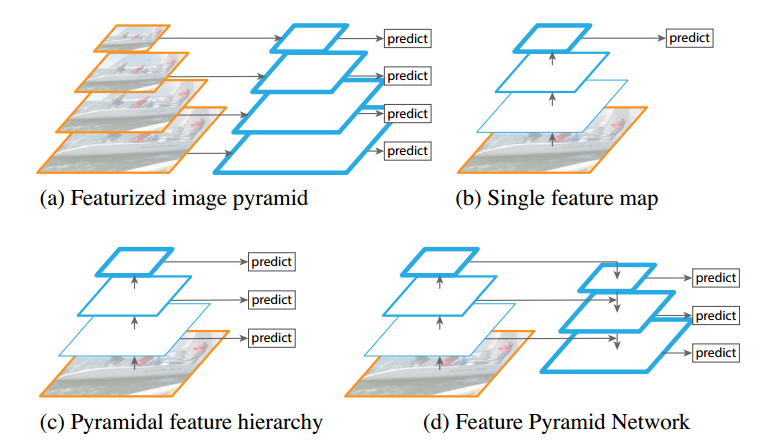
图(d)即为retinanet的网络结构。主要特点是:(1) 多尺度预测输出;(2) 采用FPN结构进行多层特征图融合。
网络进行多尺度预测,尺度一共是5个,每个尺度共享同一个head结构,但是分类和回归分支是不共享权重的。
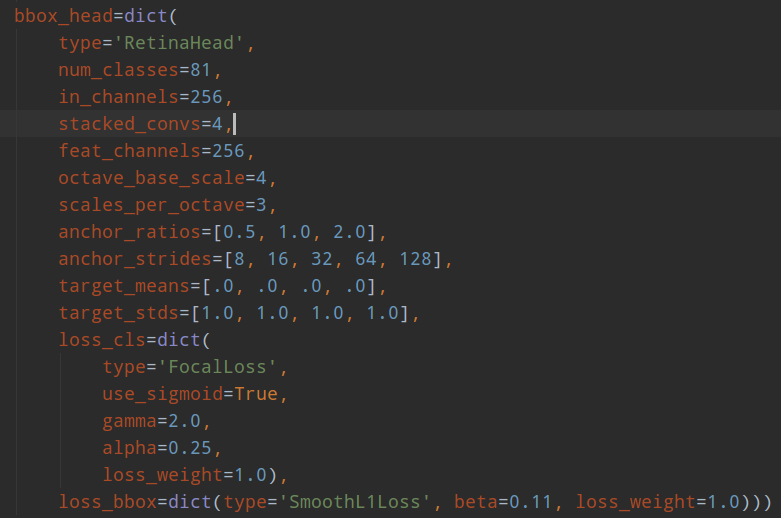
为了方便和faster rcnn进行对比,下面再次贴出rpn结构,并解释参数含义。
1. 共同部分
anchor_strides表示对应的特征图下采样次数,由于retinanet是从stage1开始进行多尺度预测,故其stride比rpn大一倍; anchor_ratios表示anchor比例,一般是1:1,1:2和2:1三种;
2. 不同部分
rpn中的anchor_scales表示每个特征尺度上anchor的base尺度,例如这里是8,表示设定的anchor大小是8*[4,8,16,32,64],可以看出每个预测层是1个size * 3个比例,也就是每个预测层是3个anchor;而retianet是不同的,scales_pre_octave=3表示每个尺度上有3个scale size,分别是,而octave_base_scale=4,意思其实和rpn的anchor_scales意思一样,但是这里换个名字是因为retinanet的scale值是固定的,就一个值,而rpn可能是多个值;通过上面的设置,retinanet的每个预测层都有scale_pre_octivate*len(anchor_ratios)个anchor,这里是9个,是非常多的,anchor的大小是octave_base_scale * [8,16,32,64,128]。可以明显发现retinanet正负样本不平衡问题比faster rcnn更加严重。
(2) 正负样本定义
retinanet是one-stage算法,其采用的正负样本定义操作是MaxIoUAssigner,阈值定义和rpn不一样,更加严格。如下所示:

min_pos_iou=0,可以保证每个GT一定有对应的anchor负责预测。0.4以下是负样本,0.5以上且是最大Iou的anchor是正样本0.4~0.5之间的anchor是忽略样本。其不需要正负样本采样器,因为其是通过平衡分类loss来解决的。
(3) 平衡分类loss
FocalLoss是本文重点,是用于处理分类分支中大量正负样本不平衡问题,或者说大量难易样本不平衡问题。
作者首先也深入分析了OHEM的不足:它通过对loss排序,选出loss最大的example来进行训练,这样就能保证训练的区域都是hard example,这个方法的缺陷,是把所有的easy example(包括easy positive和easy negitive)都去除掉了,造成easy positive example无法进一步提升训练的精度(表现的可能现象是预测出来了,但是bbox不是特别准确),而且复杂度高影响检测效率。故作者提出一个简单且高效的方法:Focal Loss焦点损失函数,用于替代OHEM,功能是一样的,需要强调的是:FL本质上解决的是将大量易学习样本的loss权重降低,但是不丢弃样本,突出难学习样本的loss权重,但是因为大部分易学习样本都是负样本,所以顺便解决了正负样本不平衡问题。
其是根据交叉熵改进而来,本质是dynamically scaled cross entropy loss,直接按照loss decay掉那些easy example的权重,这样使训练更加bias到更有意义的样本中去,说通俗点就是一个解决分类问题中类别不平衡、分类难度差异的一个 loss。
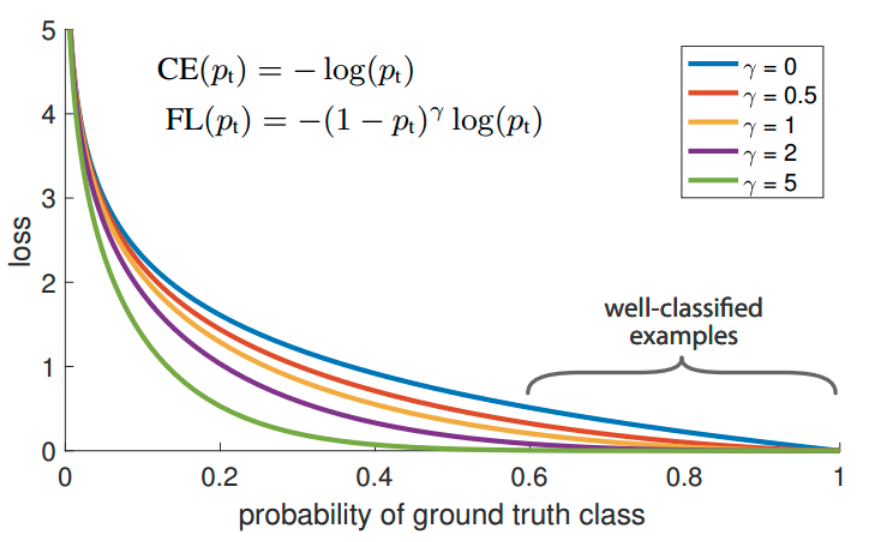
上面的公式表示label必须是one-hot形式。只看图示就很好理解了,对于任何一个类别的样本,本质上是希望学习的概率为1,当预测输出接近1时候,该样本loss权重是很低的,当预测的结果越接近0,该样本loss权重就越高。而且相比于原始的CE,这种差距会进一步拉开。由于大量样本都是属于well-classified examples,故这部分样本的loss全部都需要往下拉。其简单思想版本如下:
1.2.2 yolov2 or yolov3
论文名称:YOLOv3: An Incremental Improvement
yolov2和yolov3差不多,主要是网络有差异,不是我们分析的重点,下面以yolov3为例。
(1) head结构
yolov3也是多尺度输出,每个尺度有3个anchor。对于任何一个分支都是输出[anchor数×(x,y,w,h,confidence,class类别数)h',w']。需要注意的是,其和faster rcnn或者ssd不一样,其类别预测是不考虑背景的,所以才多引入了一个confidence的概念,该分支用于区分前景和背景。,所以最复杂的设计就在condidence上面了。
(2) 正负样本定义
yolo系列的正负样本定义比较简单,原则和MaxIoUAssigner(固定anchor和gt值计算)非常类似,但是更加简单粗暴:保证每个gt bbox一定有一个唯一的anchor进行对应,匹配规则就是IOU最大,而没有考虑其他乱七八糟的。具体就是:对于某个ground truth,首先要确定其中心点要落在哪个cell上,然后计算这个cell的每个anchor与ground truth的IOU值,计算IOU值时不考虑坐标,只考虑形状(因为anchor没有坐标xy信息),所以先将anchor与ground truth的中心点都移动到同一位置(原点),然后计算出对应的IOU值,IOU值最大的那个先验框anchor与ground truth匹配,对应的预测框用来预测这个ground truth。这个匹配规则和ssd和faster rcnn相比,简单很多,其没有啥阈值的概念。
对于分类分支和bbox回归分支,采用上述MaxIoU分配原则,可以保证每个gt bbox一定有唯一的anchor进行负责预测,而不考虑阈值,即使某些anchor与gt的匹配度不高也负责,而faster rcnn里面的MaxIoUAssigner是可能由于anchor设置不合理导致某个gt没有anchor进行对应,而变成忽略区域的。可以看出这种分配制度会导致正样本比较少。
对于confidence分支,其在上述MaxIoU分配原则下,还需要从负样本中划分出额外的忽略区域。因为有些anchor虽然没有和gt有最大iou,但是其iou依然很高,如果作为正样本来对待,由于质量不是很高以及为了和分类、回归分支的正样本定义一致,所以不适合作为正样本,但是如果作为负样本那也不合适,毕竟iou很大,这部分位置的anchor就应该设置为忽略区域,一般忽略iou阈值是0.7即将负样本中的iou大于0.7中的anchor设置为忽略区域(需要特别注意一个细节:此处的iou是每个位置的anchor预测值和所有gt计算iou,而不是固定的anchor和所有gt计算iou,因为此处需要考虑位置信息,faster rcnn系列不需要这么算的原因是faster rcnn是每个位置都会预测xywh,而yolo系列是基于grid网格预测,xy和wh预测是分开来的,所以会更复杂一些)。总结就是:
1 基于max iou分配准则,区分正负样本
2 在负样本范围内,将iou(基于anchor预测值和gt计算)大于忽略阈值的anchor定义为忽略区域,实时改变
3 此时就区分出了正、负和忽略anchor样本,正anchor用于分类、回归分支学习,正负anchor用于confidence分支学习,忽略区域不考虑。
对于yolov3,由于是多尺度预测,故还有一个细节需要注意:首先需要将gt利用 max iou原则分配到不同的预测层上去,然后在每个层上单独计算正负样本和忽略样本,也就是和faster rcnn不一样的地方是yolov3不存在某个gt会分配到多个层进行预测的可能性,而是一定是某一层负责的。但是不同的具体代码实现时候可能会有些许差别。
(3) loss
由于其采用的是普通的bce分类Loss和smooth l1 回归loss,故不再进行分析。
1.2.3 ssd
论文地址:SSD: Single Shot MultiBox Detector
(1) head结构
ssd是最典型的多尺度预测结构,是非常早期的网络。
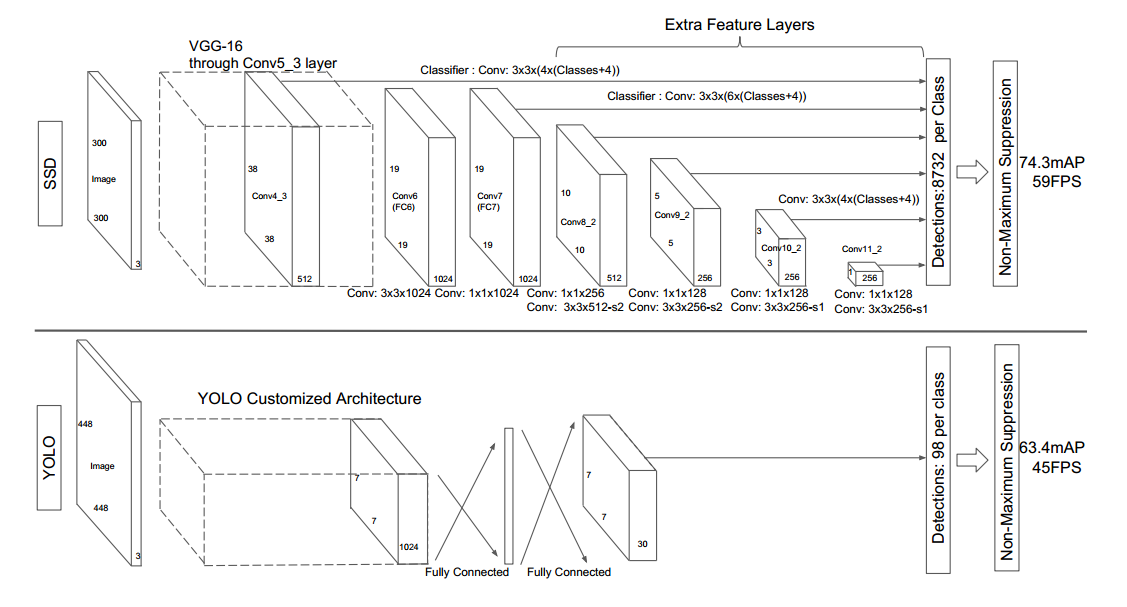
其ssd300的head结构如下:
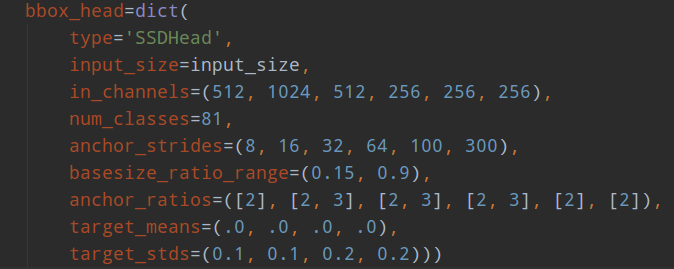
可以看出,ssd一共包括6个尺度输出,每个尺度的strides可以从anchor_strides中看出来,basesize_ratio_range表示正方形anchor的min_size和max_size,anchor_ratios表示每个预测层的anchor个数,以及比例。有点绕,下面具体分析。
为了方便设置anchor,作者设计了一个公式来生成anchor,具体为:
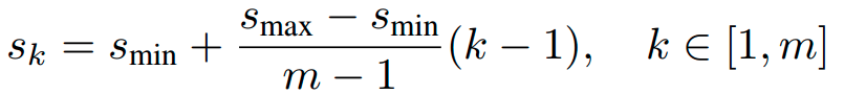
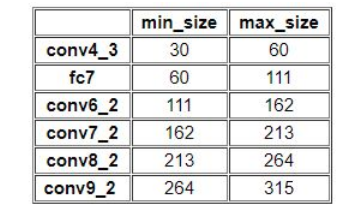
k为特征图索引,m为5,而不是6,因为第一层输出特征图Conv4_3比较特殊,是单独设置的,表示anchor大小相对于图片的比例,和是比例的最小和最大值,论文中设置min=0.2(ssd300中,coco数据集设置为0.15,voc数据集设置为0.2),max=0.9,但是实际上代码不是这样写的。实际上是:对于第一个特征图Conv4_3,其先验框的尺度比例一般设置为,故第一层的=0.1,输入是300,故conv4_3的min_size=30。对于从第二层开始的特征图,则利用上述公式进行线性增加,然后再乘以图片大小,可以得到各个特征图的尺度为60,111,162,213,264。最后一个特征图conv9_2的size是直接计算的,300*105/100=315。
以上计算可得每个特征的min_size和max_size,如下:
计算得到min_size和max_size后,需要再使用宽高比例因子来生成更多比例的anchor,一般选取,但是对于比例为1的先验框,作者又单独多设置了一种比例为1,的尺度,所以一共是6种尺度。但是在实现时,Conv4_3,Conv8_2和Conv9_2层仅使用4个先验框,它们不使用长宽比为3,1/3的先验框,每个单元的先验框的中心点分布在各个单元的中心。
具体细节如下:
- 以feature map上每个点的中点为中心(offset=0.5),生成一些列同心的prior box(然后中心点的坐标会乘以step,相当于从feature map位置映射回原图位置)。
- 正方形prior box最小边长为和最大边长为:min_size和
根据aspect ratio,会生成2个长方形,长宽为
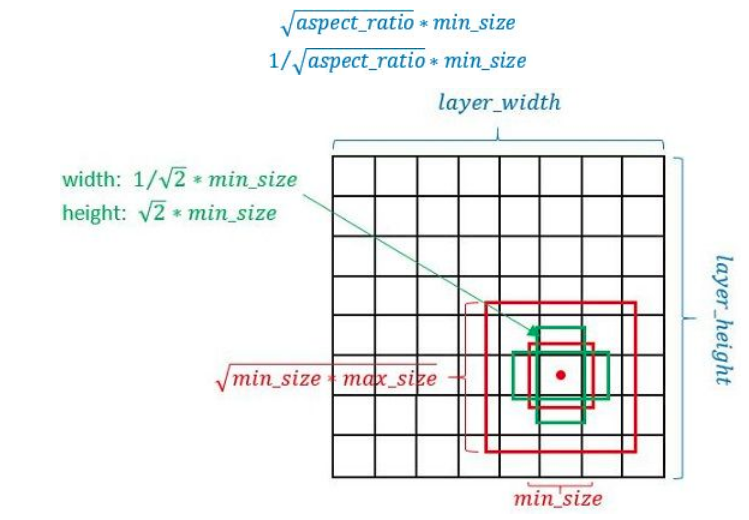
目的是保存在该比例下,面积不变。
以fc7为例,前面知道其min_size=60,max_size=111,由于其需要6种比例,故生成过程是:第一种比例,(min_size,min_size)=(60,60)
第二种比例, ,
第三种比例,,
第四种比例,
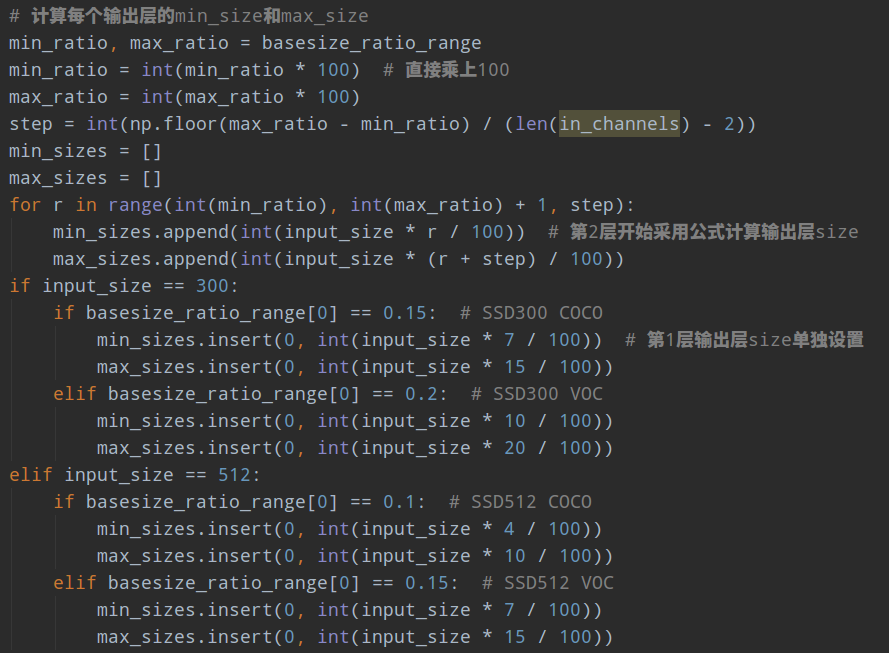
不管哪个框架实现,核心思想都是一样,但是可能某些数据的设置不一样。下面以mmdetection为例:
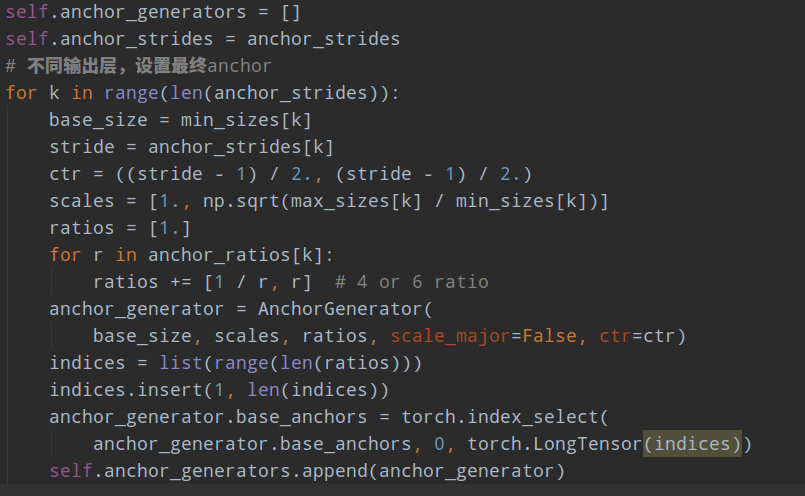
(2) 正负样本定义
ssd采用的正负样本定义器依然是MaxIoUAssigner,但是由于参数设置不一样,故有了不同的解释。
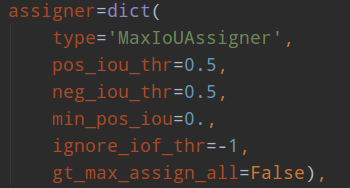
其定义anchor与gt的iou小于0.5的就全部认为是负样本,大于0.5的最大iou样本认为是正样本anchor,同时由于min_pos_iou=0以及gt_max_assign_all=False,可以发现该设置的结果是每个gt可能和多个anchor匹配上,匹配阈值比较低,且每个gt一定会和某个anchor匹配上,不可能存在gt没有anchor匹配的情况,且没有忽略样本。
总结下意思就是:
- anchor和所有gt的iou都小于0.5,则认为是负样本
- anchor和某个gt的最大iou大于0.5,则认为是正样本
- gt和所有anchor的最大iou值,如果大于0.0,则认为该最大iou anchor是正样本
- 没有忽略样本
(3) 平衡分类loss
由于正负样本差距较大,如果直接采用ce和smooth l1训练,效果可能不太好,比较样本不平衡严重。故作者的ce loss其实采用了ohem+ce的策略,通过train_cfg.neg_pos_ratio=3来配置负样本是正样本的3倍。
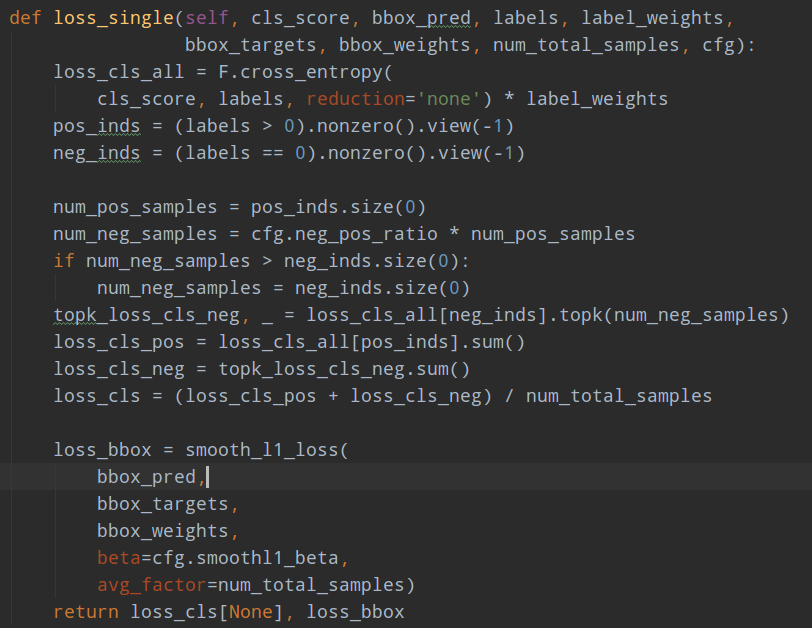
核心就是按照分类loss进行topk,得到3倍的负样本进行反向传播。
