@huanghaian
2020-03-19T12:04:14.000000Z
字数 26793
阅读 3116
检测相关
黄海安
改变检测
- DASNet: Dual attentive fully convolutional siamesenetworks for change detection of high resolution satellite images https://arxiv.org/pdf/2003.03608.pdf
目标检测
https://zhuanlan.zhihu.com/p/110205719
目前的先目标检测+关键点检测的方案,速度太慢了,特别是在物体很多场景下。优化方案应该是:第一级别目标检测的同时预测关键点,例如centerpose;然后左右图片先进行极限误差挑选出topk对的图片数目裁剪下来,并且将第一级别的预测结果和图片concat作为输入,输入到cpn中,进行加速训练和推理。
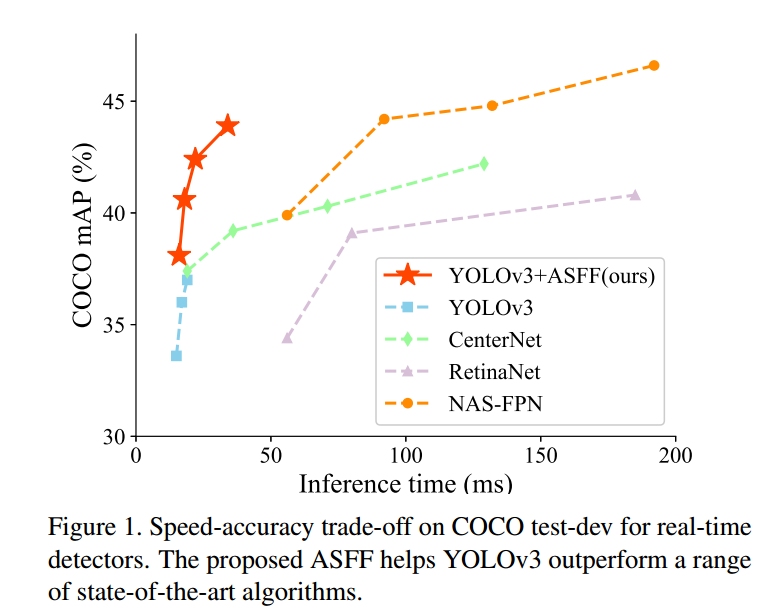
ASFF-yolov3
论文:Learning Spatial Fusion for Single-Shot Object Detection
arxiv: 1911.09516
github地址:https://github.com/ruinmessi/ASFF
本文和BIFPN一样,也是探讨FPN的融合方式存在特征的不一致性,故而提出adaptively spatial feature fusion (ASFF)模块来提升FPN性能,在时间增加不大的情况下,显著提高yolov3的性能。更重要的是作者将目前常用的有效的训练技巧应用于yolov3模型中,显著提升了yolov3的baseline性能。故本文的贡献可以归纳为:
(1) 引入了新的训练技巧以及最新论文中提到的一些操作,训练出了一个非常强大的yolov3 baseline
(2) 在强baseline基础上改进了FPN融合策略,提出了ASFF模块,进一步提高精度,速度牺牲很小
1 强baseline模型
YOLOv3包括darknet53骨架网络和3层特征金字塔网络构成的3个尺度输出。
首先采用基于Bag of freebies for training object detection neural networks里面提出的训练策略来改进性能,主要包括 the mixup algorithm , the cosinelearning rate schedule和 the synchronized batch normalization。
其次,由于最新论文表示iou loss对于边界框回归效果好,故作者也额外引入了一个iou loss来优化bbox。
最后,由于GA论文(Region proposal by guided anchoring )指出采用语义向导式的anchor策略可以得到更好的结果,故作者也引入了GA操作来提升性能。
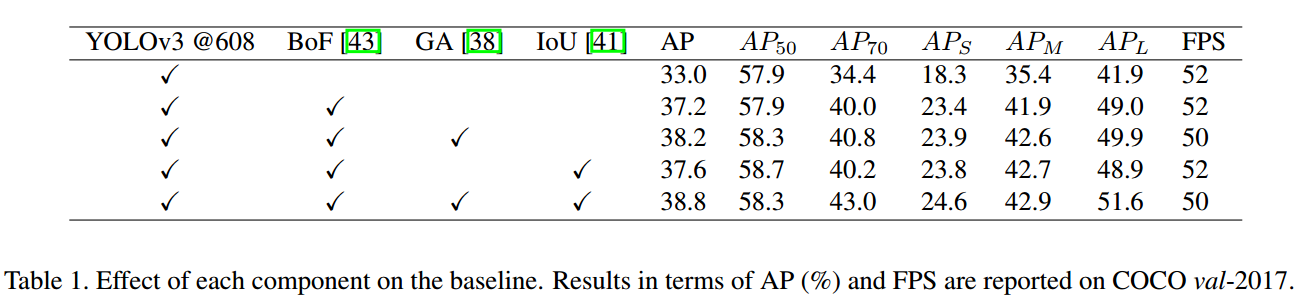
可以看出,结合这些策略后,在coco上面可以得到38.8的mAP,速度仅仅慢了一点点(多了GA操作),可谓是非常强大,这也反应出训练策略对最终性能的影响非常大。
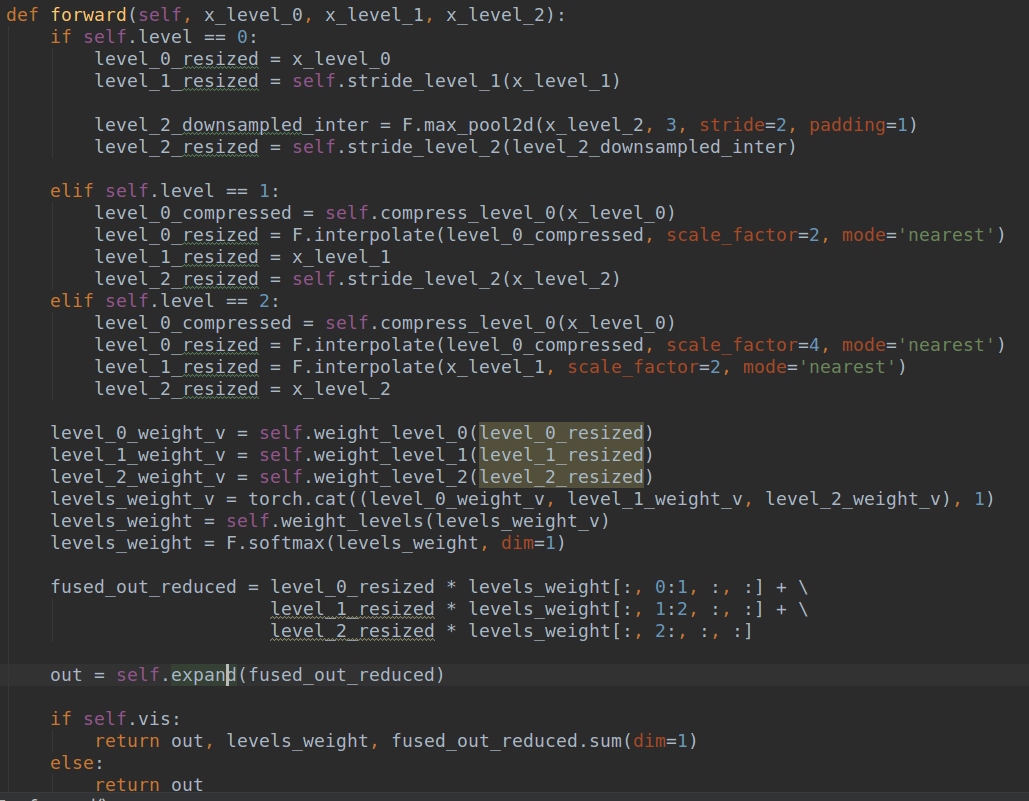
2 Adaptively Spatial Feature Fusion
FPN操作是一个非常常用的用于对付大小尺寸物体检测的办法,作者指出FPN的缺点是不同尺度之间存在语义gap,举例来说基于iou准则,某个gt bbox只会分配到某一个特定层,而其余层级对应区域会认为是背景,如果图像中包含大小对象,则不同级别的特征之间的冲突往往会占据要素金字塔的主要部分,这种不一致会干扰训练期间的梯度计算,并降低特征金字塔的有效性。一句话就是:目前这种concat或者add的融合方式不够科学。本文觉得应该自适应融合,自动找出最合适的融合特征,如下所示:

简要思想就是:原来的FPN add方式现在变成了add基础上多了一个可学习系数,该参数是自动学习的,可以实现自适应融合效果,类似于全连接参数。
ASFF具体操作包括 identically rescaling和adaptively fusing。
定义FPN层级为l,为了进行融合,对于不同层级的特征都要进行上采样或者下采样操作,用于得到同等空间大小的特征图,上采样操作是1x1卷积进行通道压缩,然后双线性插值得到;下采样操作是对于1/2特征图是采样3 × 3 convolution layer with a stride of 2,对于1/4特征图是add a 2-stride max pooling layer然后引用stride 卷积。
Adaptive Fusion

下面讲解具体操作:
(1) 首先对于第l级特征图输出cxhxw,对其余特征图进行上下采样操作,得到同样大小和channel的特征图,方便后续融合
(2) 对处理后的3个层级特征图输出,输入到1x1xn的卷积中(n是预先设定的),得到3个空间权重向量,每个大小是nxhxw
(3) 然后通道方向拼接得到3nxhxw的权重融合图
(4) 为了得到通道为3的权重图,对上述特征图采用1x1x3的卷积,得到3xhxw的权重向量
(5) 在通道方向softmax操作,进行归一化,将3个向量乘加到3个特征图上面,得到融合后的cxhxw特征图
(6) 采用3x3卷积得到输出通道为256的预测输出层
为了提高性能,训练时候采用了多尺度训练,尺度是randomly picked in 320; 352; 384; 416; 448; 480; 512; 544; 576; 608。作者首先采用mixup策略在darknet53分类网络上面进行预训练,得到一个比较好的darknet53权重,然后再进行目标检测训练。训练详情: The entire network is trained with stochastic gradient descent (SGD) on 4 GPUs
(NVDIA Tesla V100) with 16 images per GPU. All models are trained for 300 epochs with the first 4 epochs of warmup and the cosine learning rate schedule 26 from 0.001 to
0.00001. The weight decay is 0.0005 and the momentum is
0.9 . We turn off mixup augmentation for the last 30 epochs
3 实验分析
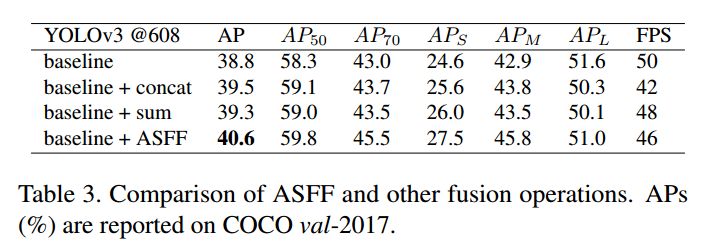


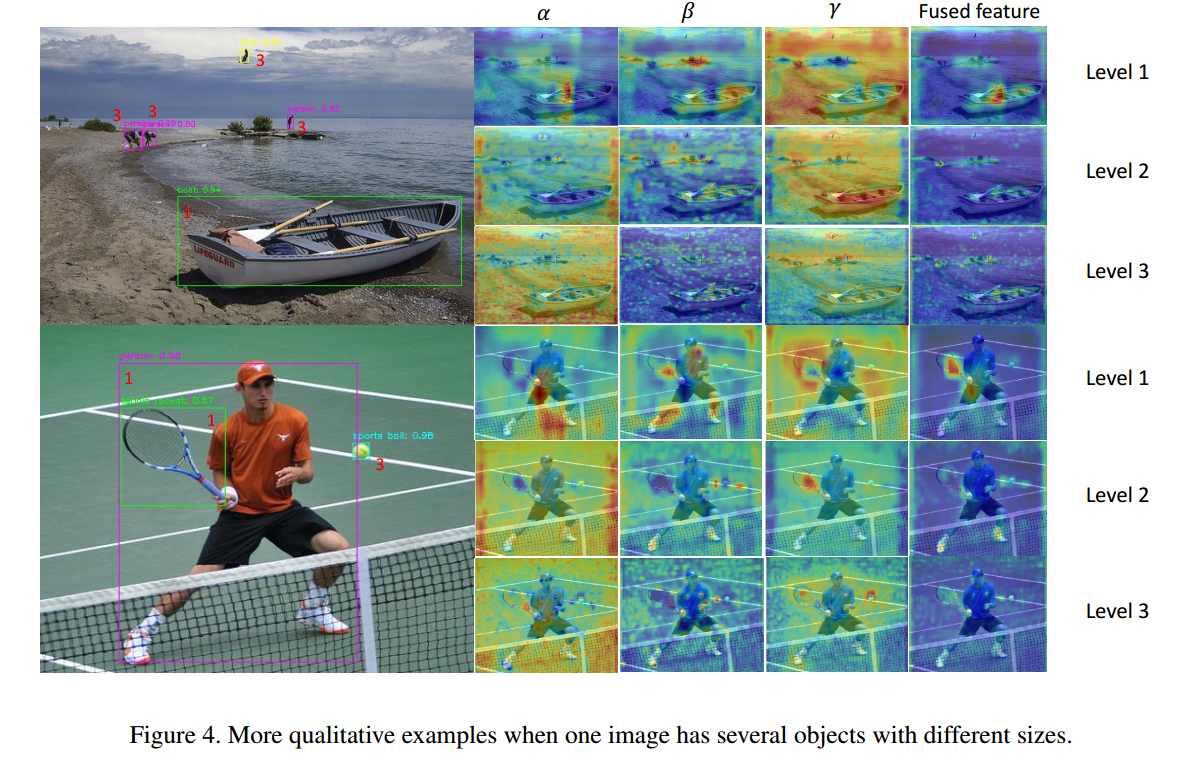
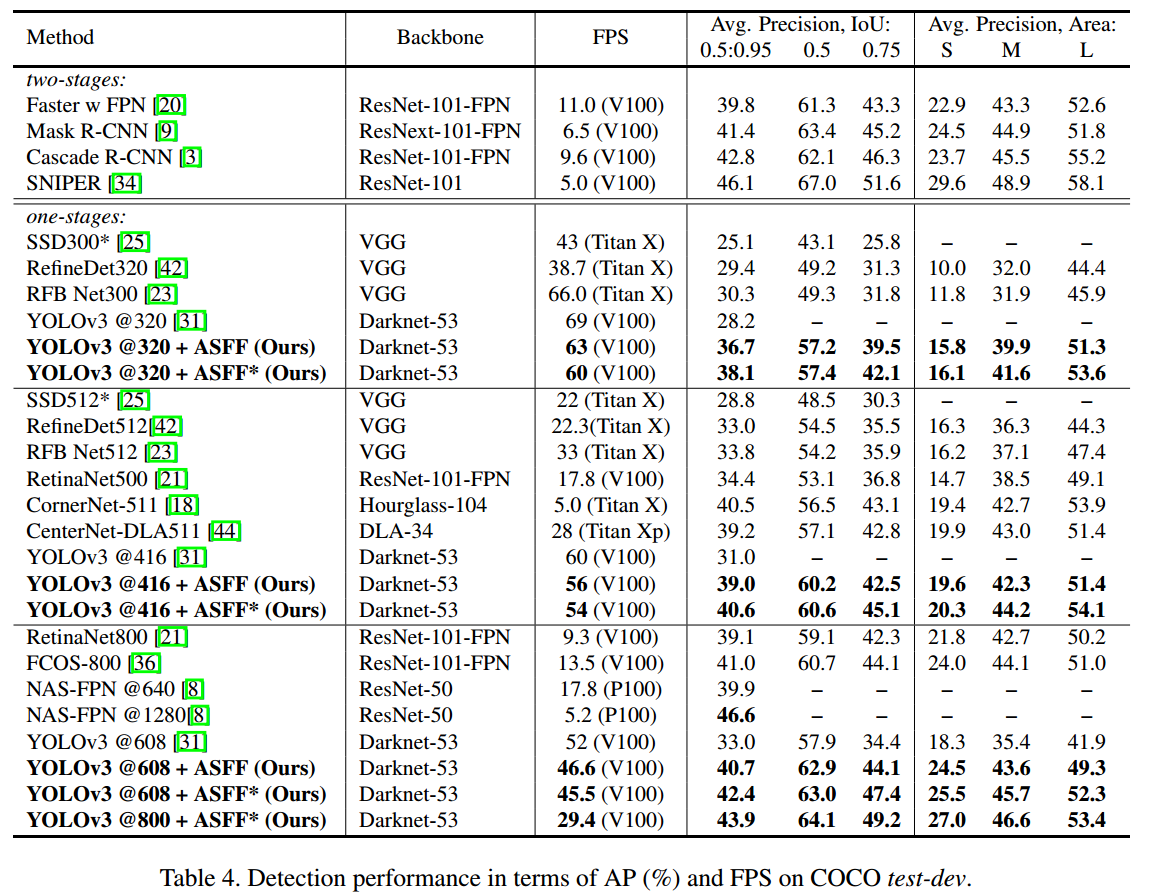
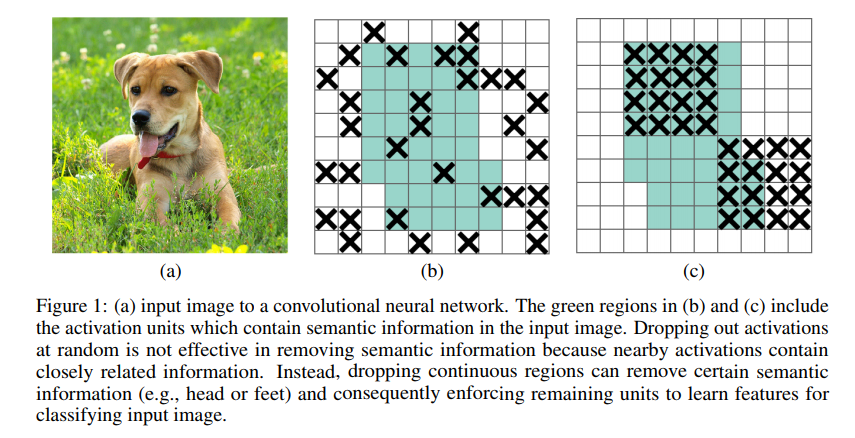
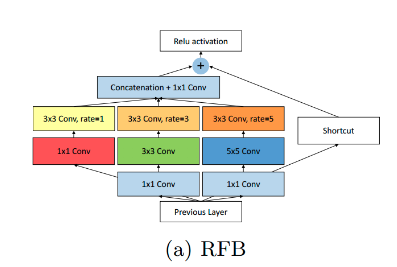
ASFF×是指ASFF增强版,主要是新增了Lightweight modules (i.e.DropBlock and RFB ) 并且 1.5× longer training time得到的结果。其中DropBlock是论文DropBlock: A regularization method for convolutional networks,其核心示意图如下:
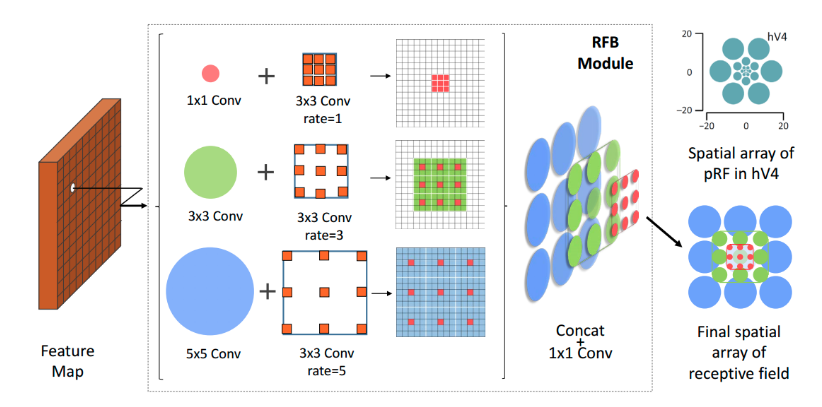
RFB模块是RFBNet目标检测算法提出的结构:
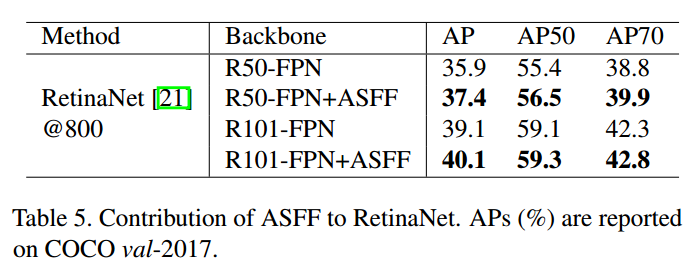
应用于其他模型也可以实现精度提升
4 总结
本文提出的强baseline,精度非常高,但是需要用多卡才能训练出来这么高的精度,单卡不知道能否训练出来。并且提出一直FPN的改进融合方式,可以应用于其他类似FPN结构中。作者开源代码写的比较乱,不太好修改。
文本检测
待阅读论文:ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network-cvpr2020
Efficient Scene Text Detection with Textual Attention Tower
https://arxiv.org/pdf/2002.03741.pdf 没开源
本文属于轻量级文本检测模型,核心是提出一个新的网络而已,骨架是MobileNetV2,比east精度高,预测的其实是旋转bbox格式,而不是east的8点法。
说到底就是各种注意力而已,本文没啥看的,稍微有点点实践意义,如果后续需要非常轻量级网络,可以考虑
SA-Text: Simple but Accurate Detector for Text of Arbitrary Shapes
https://arxiv.org/pdf/1911.07046v2.pdf
采用分割做法进行文本检测
DGST : Discriminator Guided Scene Text detector
arxiv: 2002.12509 优秀
本文采用分割做法来进行文本检测,并且将分割做法变成gan生成问题,效果非常好,并且思想非常简单,应该可以应用于其他一些分割做法的文本检测算法中。F值非常高,效果可以说非常好,速度应该也很快。
本文指出常见的分割做法不好地方:考虑到噪声,通常都会对label进行shrink,但是一个刚性收缩不能精确地调整每个框的标签,并且不能很好地区分文本边缘和背景像素,这使得最终的文本框位置偏离了期望的结果。作者认为bbox的中心重要性应该高于4周,故作者采用宁一种建模方式,类似高斯图形式。
soft-text-score map。

其实就是在shrink的基础上,还要考虑4周距离。为了后处理方便,作者采用了不同的缩放因子,得到两个通道的score map。
网络:
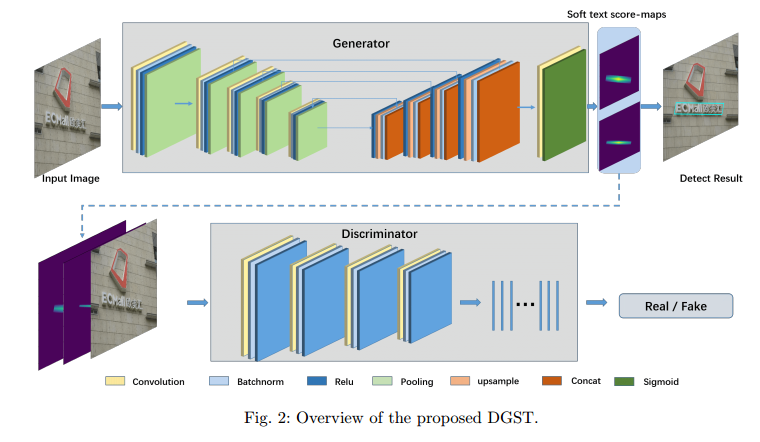
看到网络图就很容易理解了。
可以看到,gan其实是带条件的判别器,因为输入到判别器的输入不仅有预测,还有原图。
网站网络图:
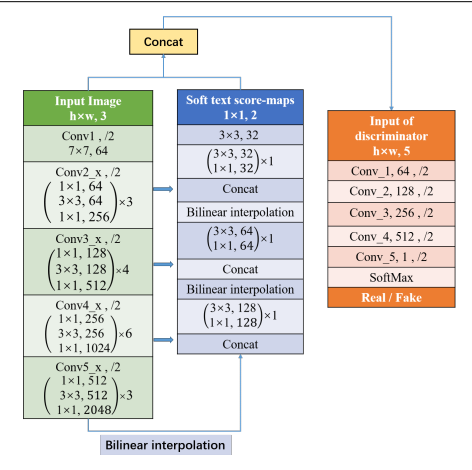
骨架是resnet50.

loss包括GAN本身的2个loss,然后在生成器的输出地方加上L2 loss监督。
后处理:
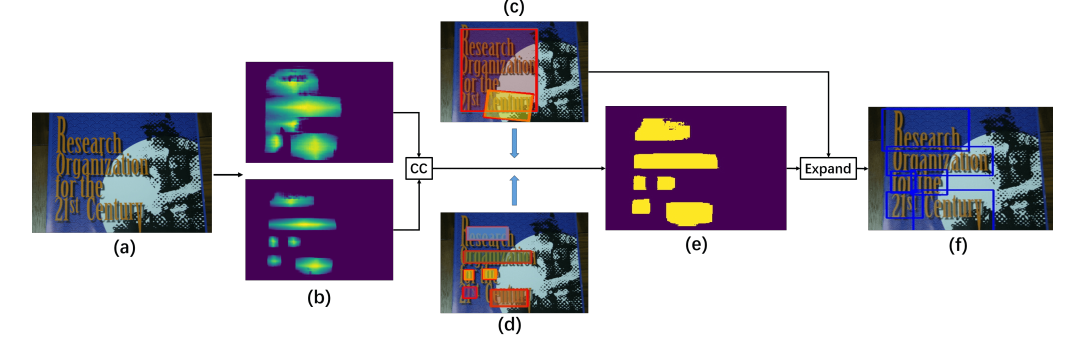
后处理采用opencv,利用阈值法和连通集处理得当:

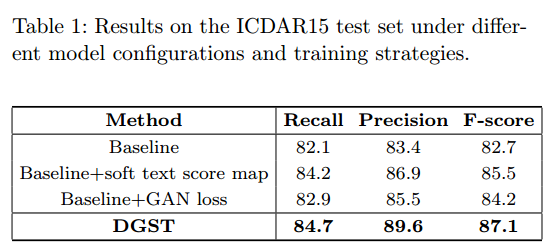
baseline是生成器,然后采样二值分割图进行训练的结果。可以看出效果确实提升很多。

在不同数据集上,F值都提升很多。这是本文最大的亮点。
6d姿态估计
cvpr2020: G2L-Net: Global to Local Network for Real-time 6D Pose Estimation with Embedding Vector Features 论文暂时下不到
6DoF Object Pose Estimation via Differentiable Proxy Voting Loss
https://arxiv.org/abs/2002.03923
属于pvnet的改进,仅仅新增了一个loss,测试流程完全不变,精度提高很多,是一个非常不错的做法。
全文出发点:基于矢量场的关键点投票已证明其在解决遮挡姿态估计问题上的有效性和优越性。但是,矢量场的直接回归忽略了像素和关键点之间的距离也极大地影响了假设的偏差。换句话说,当像素远离关键点时,方向矢量的小误差可能会产生严重偏离的假设,而本文就是要考虑该距离误差,使得远距离的方向向量估计的也比较准。
核心思想就是下图:
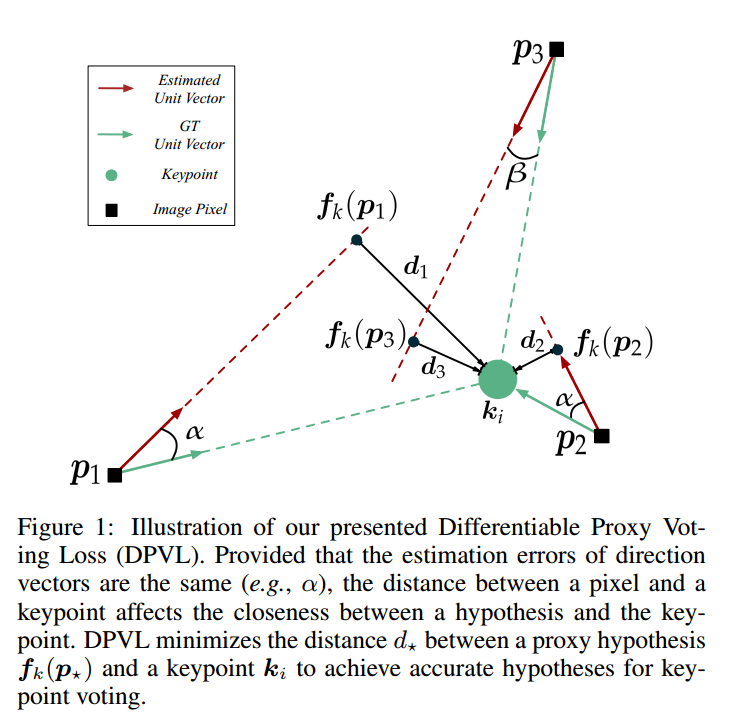
对于p1 p2 p3由于距离keypoint不一样,在单位向量误差一致情况下,其实p1带来的投票误差差距非常大。也就是说pvnet里面采用的直接l1向量场回归无法反应出这中错误,导致惩罚是一样的,这其实是不对的,p1的误差明显大于p2和p3,loss的惩罚也应该不一样。
针对上述问题,作者引入了垂直角的做法来计算d,此时就可以反应出距离误差了。论文叫做proxy代理loss,是因为投票loss采用直接loss,直接利用p这些关键点得到假设Pose,然后计算Loss,这样也可以距离,但是这样做是不可导的,所以作者采用了这种简介的loss做法实现。
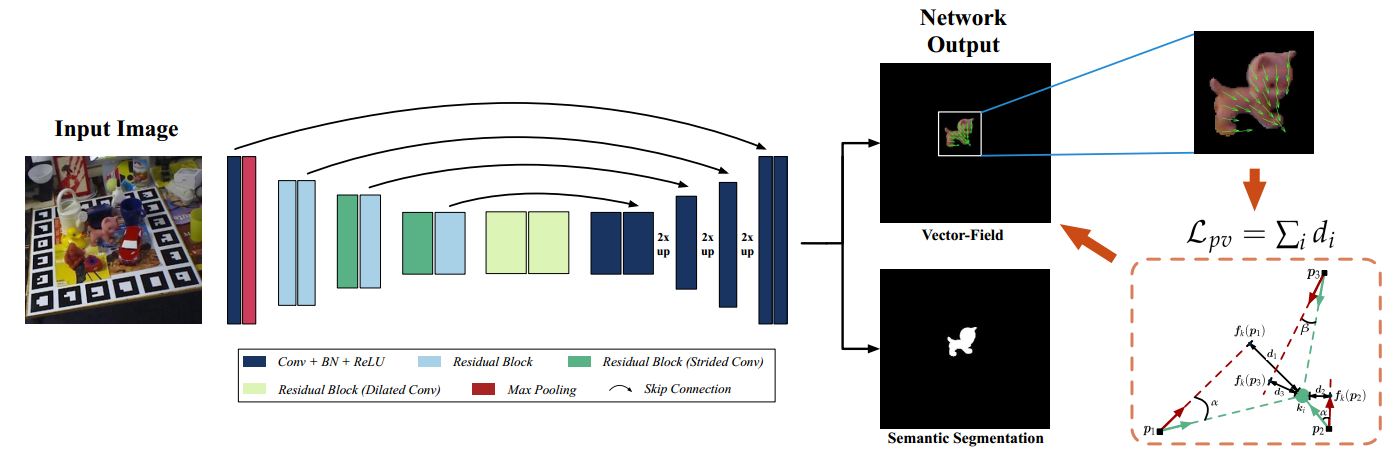
额外增加的pv loss如下定义:
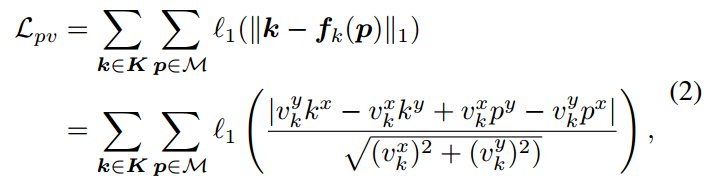
k是关键点坐标,f(p)的p像素位置的垂直脚的坐标点,然后l1即可,
上述方程其实是算d,希望d趋于0.具体是已知了p坐标和向量,此时可以得到直线方向,然后计算点k到直线的距离即为d。简单的几何数学。
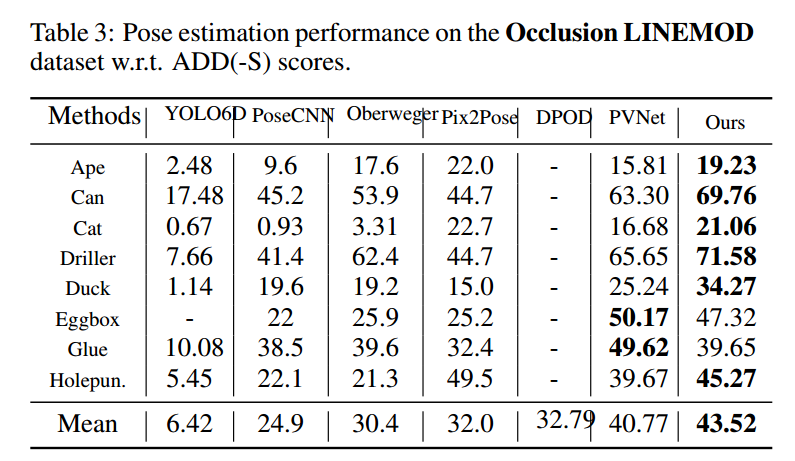
可以看出性能提高很多。其实很多人都发现了pvnet的问题,即距离远的像素投票的不准,导致误差增加。代码暂时没有开源。看起来不是那么容易训练好。
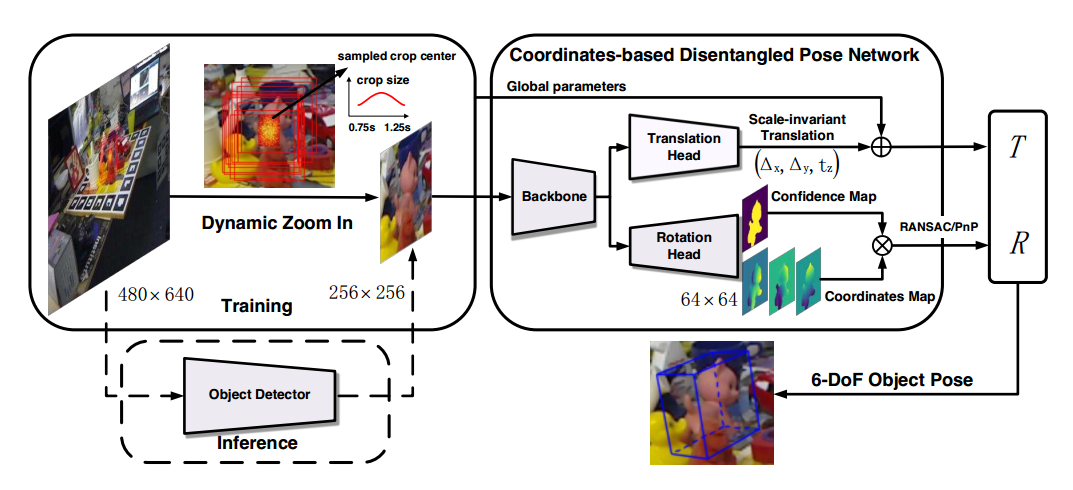
Coordinates-Based Disentangled Pose Network for Real-Time RGB-Based 6-DoF Object Pose Estimation
ICCV2019 ORAL
https://blog.csdn.net/WangKingJ/article/details/103398614
代码已开源
人体姿态估计
待阅读论文:
8. PifPaf: Composite Fields for Human Pose Estimation cvpr2019
9. PVNet: Pixel-wise Voting Network for 6DoF Pose Estimation PVNET不知道能不能改成通用做法,而不是仅仅用于6dof
待阅读代码:
1 https://github.com/tensorboy/centerpose bottom_up方法
2 https://github.com/jialee93/Improved-Body-Parts bottom_up paf格式
3 https://github.com/tensorboy/pytorch_Realtime_Multi-Person_Pose_Estimation
Learning Delicate Local Representations for Multi-Person Pose Estimation
arxiv :2003.04030 cvpr2019冠军模型
代码: https://github.com/caiyuanhao1998/RSN/ 代码写的简洁,可读性高
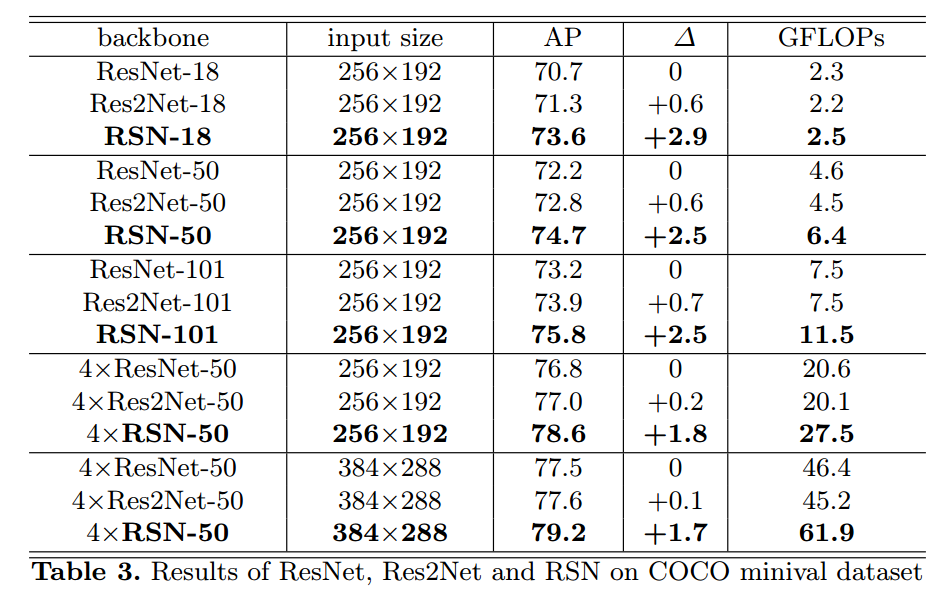
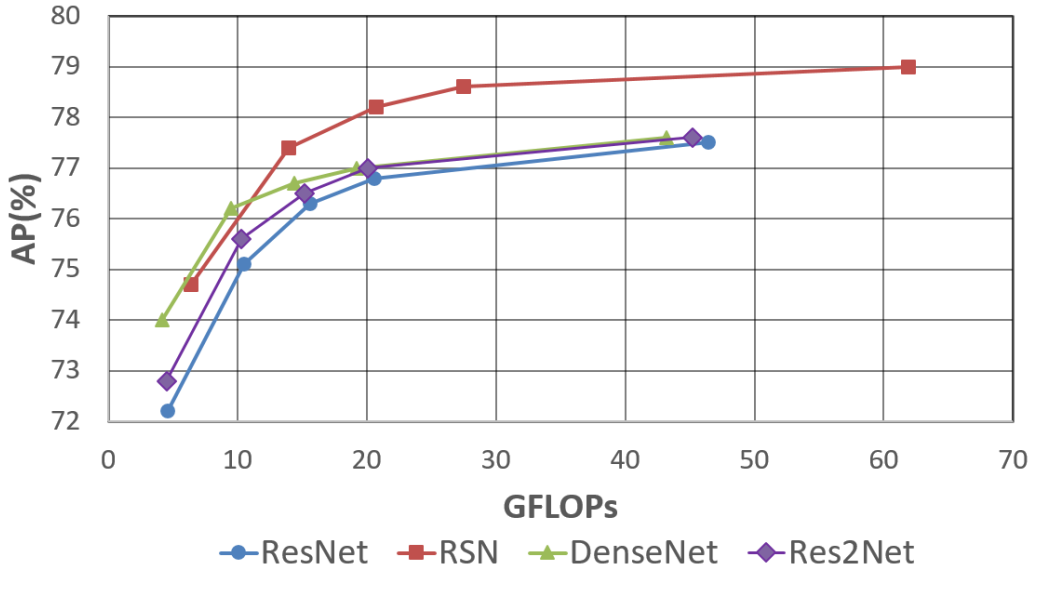
本文可以认为是MSPN的改进版本,主要是是改了骨架部分。
其出发点是目前的特征融合都是特征层之间融合,而很小考虑特征内部的融合,主要思想是参考res2net。
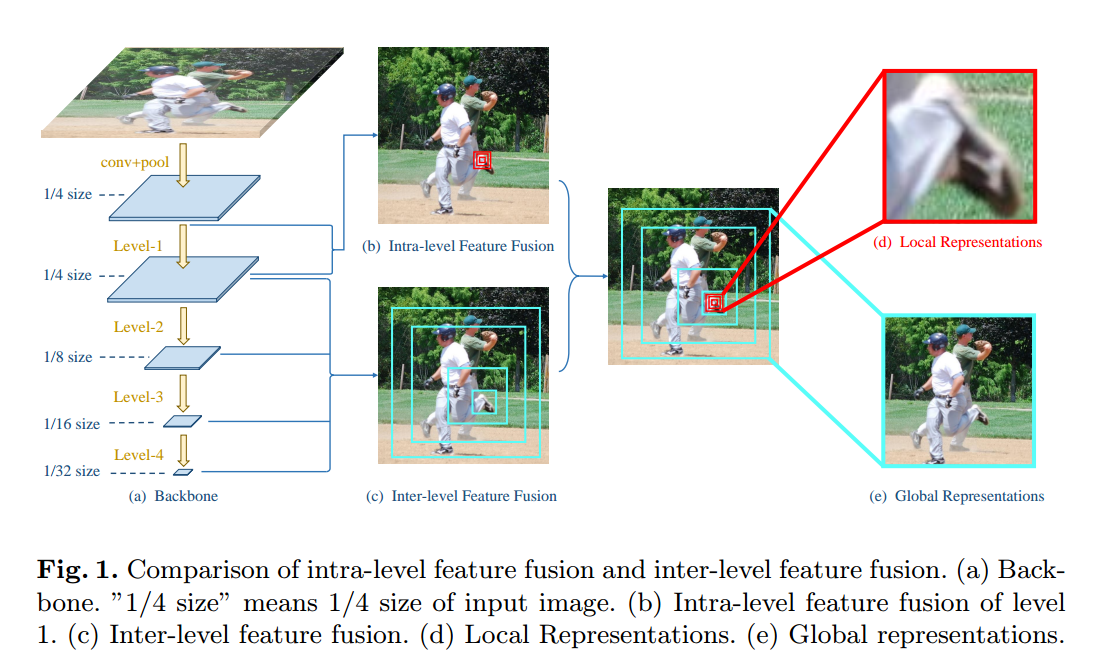
本文的出发点就是特征层级之间融合,加上特征层本身的融合。inter层级之间的融合就是讲各种尺度的特征进行融合,可以看出不同层级之间感受野外差异很大,融合过程过于粗糙。故本文希望同时引入层内部的特征融合策略,得到非常精细详尽的特征,上图红色块表示,然后两个特征图进行融合,就可得到即有多尺度多感受野的特征,也可以得到非常精细的局部特征表达。
(1) We propose a novel network - RSN, which aims to learn delicate local representations by efficient intra-level feature fusion.
(2) We propose an attention mechanism - PRM, which goes futher to refine the aggregated features in both channel and spatial wise.
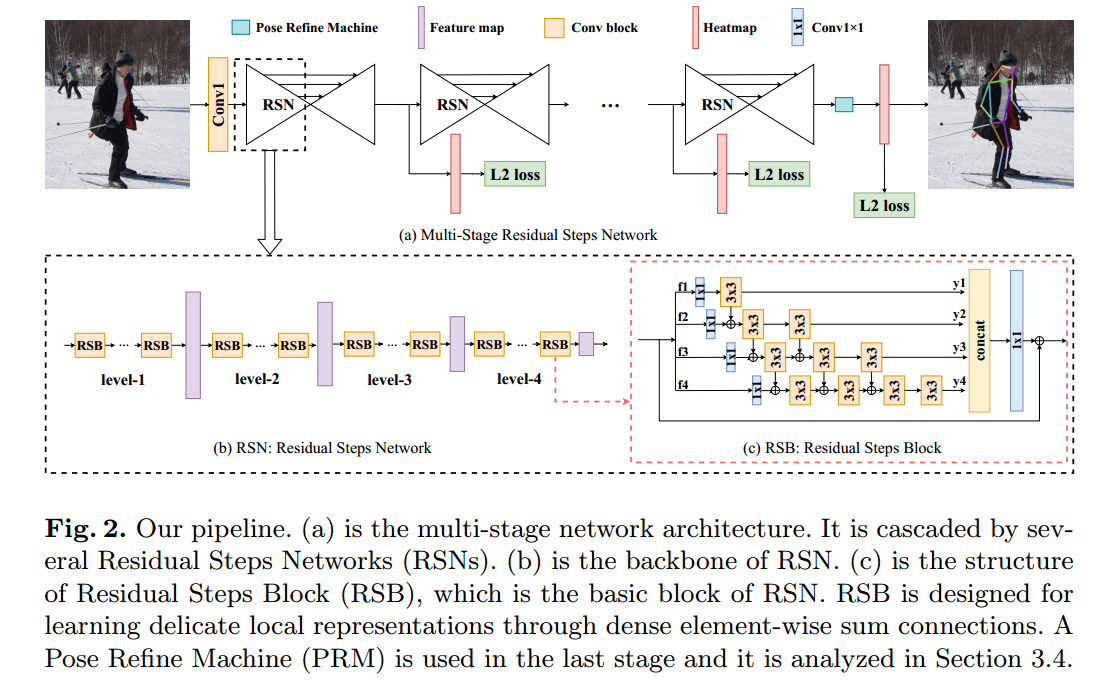
和MSPN一样,包括n个stage级联,每个stage都有l2 loss监督。每个stage包括特征提取模块RSN,和上采样融合模块,其中RSN结构完全仿照resnet,RSB相当于bottleneck模块。
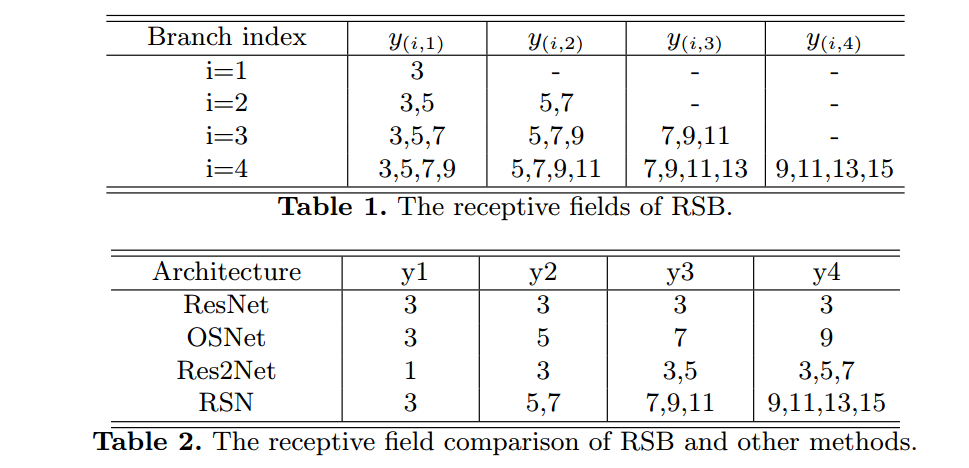
RSB模块
可以看出在每个RSB内部,感受野更加丰富。RSB特征融合也借鉴了densenet挑层思想,但是考虑到内存占用,没有采用concat模式,而是全部采用sum,减少内存消耗。
Pose Refine Machine模块
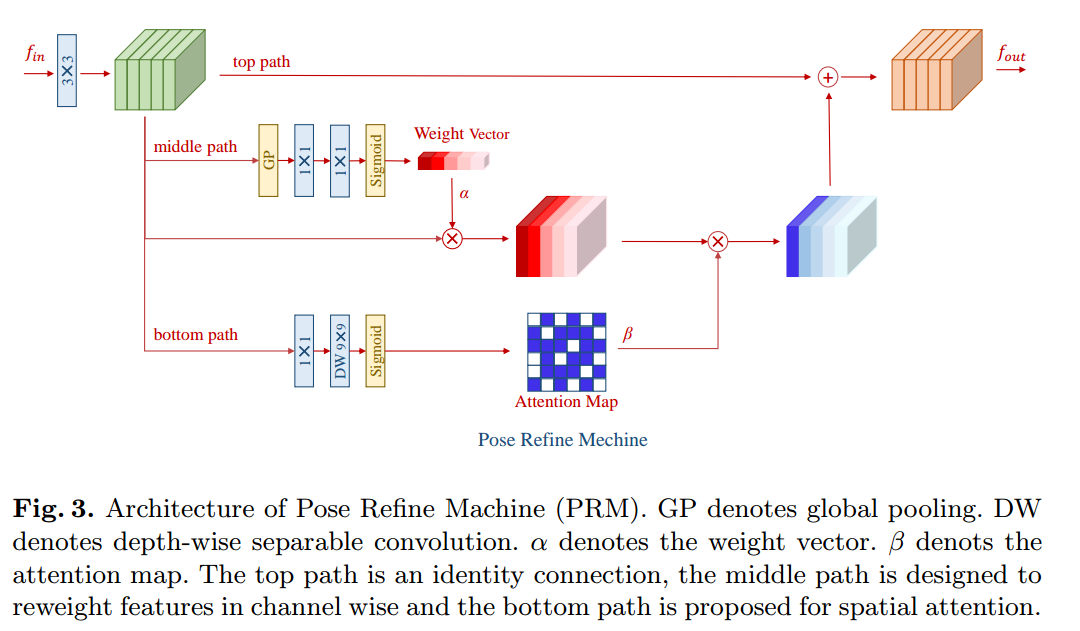
最终的热图是好像是只取了最后一个stage的输出,并且使用经验法则进行refine。
rsb模块可以无缝替换掉resnet中的b
实验
可视化:

讲每个stage的最后1x1卷积的kernel拿出来,计算绝对幅值,值越大,越显示红色,蓝色为0.可以明显看出,4个stage中,rsn学到的权重都是有很大值的,说明权重都很重要。而densenet学到的权重除了第一个stage,后面的几乎都是0,说明大部分权重都是冗余的,低效学习,相对而言res2net好于densenet。

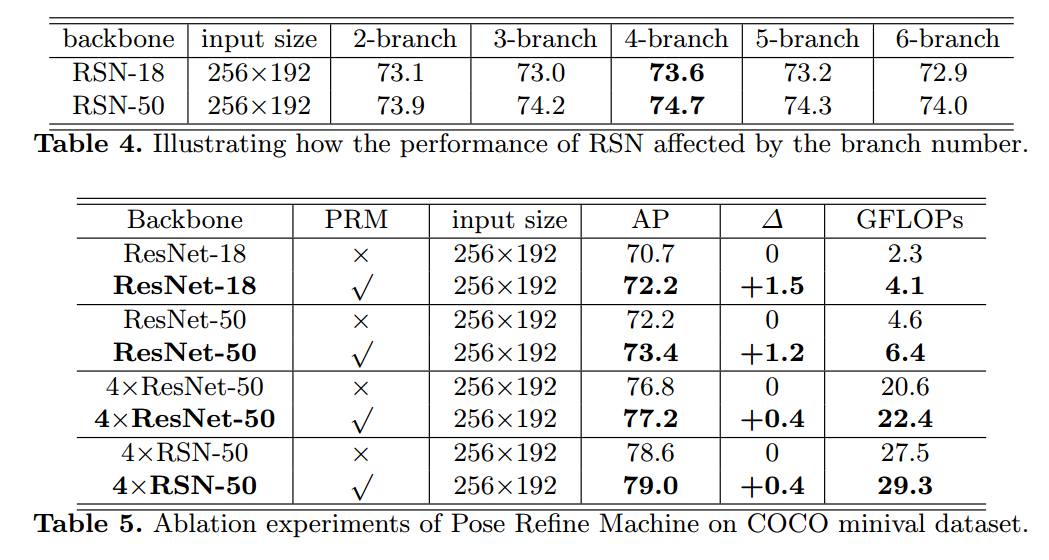
Towards Accurate Multi-person Pose Estimation in the Wild
CVPR2017 简称 G-RMI
地址:https://arxiv.org/abs/1701.01779v2
开源代码:https://github.com/hackiey/keypoints
解析:https://mp.weixin.qq.com/s/tAQj8SYOz0OcsCUm_XRQPw
虽然本文比较老,但是里面包含的思想和trick,是现在大部分改进版本的基础,比较重要的一篇文章。属于top-down做法
这篇文章应该算是除mask rcnn外第一篇做的很好的多人姿态估计论文算法。
利用fastrcnn检测图片中可能容纳人体的目标框位置和大小,并估计每个框中可能包含的人体关键点。对于每种关键点类型,使用全卷积ResNet预测一个关键点热度图和两个关键点偏移量(X轴,Y轴)。为了结合这些输出,引入了一种新颖的热图-偏移聚合方法来获得精准的关键点预测。为了避免重复关键点的预测,通过直接基于OKS指标(OKS-NMS)的新型基于关键点的非最大抑制(NMS)机制,而不是较粗糙的基于boundingbox 的IOU NMS。作者还提出了一种新颖的基于关键点的置信度估计器,与使用Faster-RCNN检测框的得分进行结合得到最终姿态置信度,该方法能够对检测的AP有极大改善。本文提出的一种image_crop策略也被后续很多文章使用。
综上所述,本文提出了四种有效提升关键点预测精度的Trick:
1.多输出姿态估计网络
2.热图-偏移解码器
3.keypoint_rescore
4.keypoint_oks_nms
5.image_crop
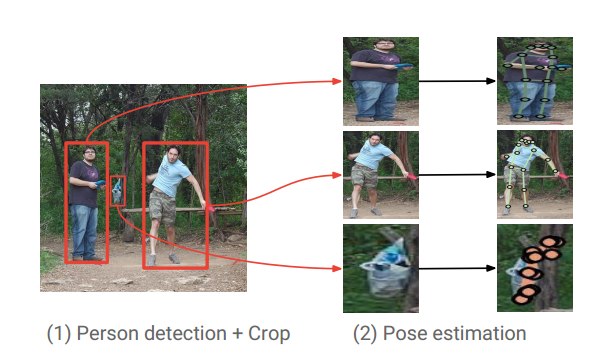
(1) Person Box Detection
采用faster rcnn网络,骨架是res101,并引入了空洞卷积进行了适当改变。注意,这里的检测结果没有进行Nms操作,而是放到了姿态估计算法部分进行。
For computational efficiency, we only forward to the second stage person box detection proposals with score higher than 0.3, resulting in only 3.5 proposals per image on average。
(2) Person Pose Estimation
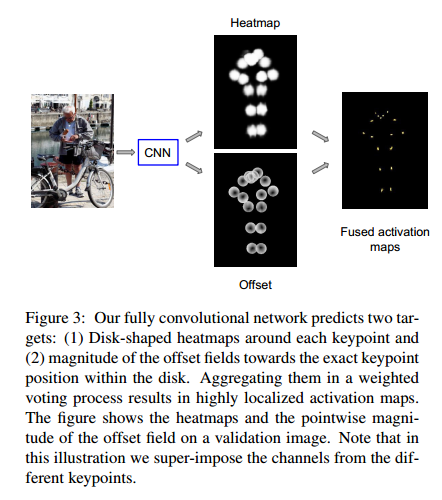
由于基于heatmap的方法,由于网络降采样的问题,最终的输出特征图和输入图之间存在分辨率的差别,在将关键点反算回去时存在固有的偏差。基于此,如下图所示,本文利用多输出姿态估计网络输出的2D偏移向量结合Heatmap得到更加精准的关键点。
(2-1) Image Cropping
作者首先通过目标框的高度和宽度,使所有的框具有相同的固定长宽比(类似pad),而不扭曲图像的长宽比。在此之后,进一步放大了方框,以包含额外的图像上下文,该扩大比例在训练时随机为1--1.5,在测试时定义为1.25。最后将得到的crop框resize成网络的输入大小。其实就是先进行padding到想要输入到网络图片的宽高比例上,然后随机保存比例的扩大bbox大小,然后再resize到统一大小输入。默认比例是353/257 = 1:37
(2-2) Heatmap and Offset Prediction with CNN

关键点是是K=17,那么网络输出通道数是3*K。其网络的具体做法是使用 ResNet-101, replacing its last layer with 1x1 convolution
with 3 · K outputs. we employ atrous convolution to generate the 3 · K predictions with an output stride of 8 pixels and bilinearly upsample them to the 353x257 crop size.也就是说其网络的输入和输出大小是一样的。


f_k是最后两个分支预测的结果合并得到的。

(2-3) Model Training
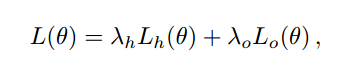
L_h是二值交叉熵loss,label是在R半径范围内的是1,其余是0,
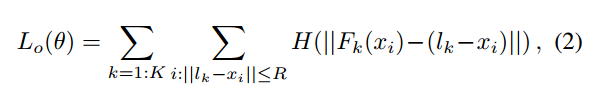
回归loss,也是仅仅计算半径范围内的值,其余位置不进行监督。
To accelerate training, we add an extra heatmap prediction layer at intermediate layer 50 of ResNet, which contributes a corresponding auxiliary loss term。在中间层还多了一个热图监督。
(2-4) 后处理
为了进行后面的oks-nms,作者提出了Pose Rescoring,就是利用某一个人的所以预测关键点处的预测值,取平均作为实例级别人的分值。
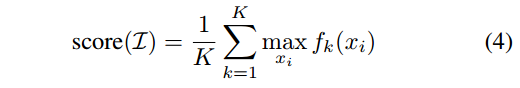
OKS-Based Non Maximum Suppression
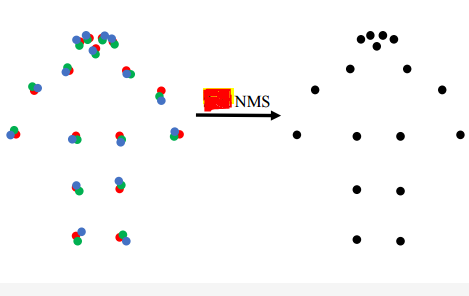
标准NMS基于目标框的交叠比(IoU)来测量重叠率。本文提出了一种考虑关键点的更精确的变体。使用关键点相似度(OKS)来测量两个候选整体检测的重叠。通常,在人体目标检测器的输出处使用一个相对较高的iou 阈值来过滤高度重叠的框。姿态估计器输出的更合适的oks阈值,更适合于确定两个候选检测姿态之间的重叠。
(3) 实验
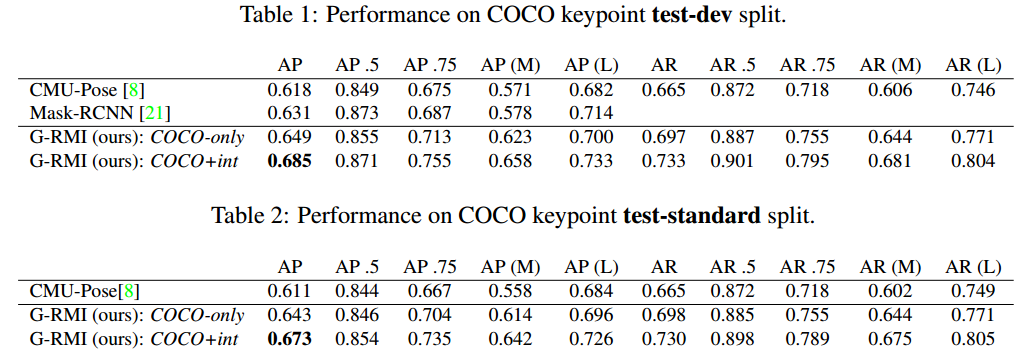
结论:通过本文可以看出,本文提出了很多优化技巧来提高多人姿态估计性能。看起来思想非常好。为啥看起来和现在的top-down算法比差很多,我觉得原因是:(1) 首先目标检测精度会严重影响后续姿态估计算法性能,而本文当时用的目标检测算法性能不能和现在的目标检测算法对比,导致精度偏低;(2) 姿态估计网络设计的非常简单就是res101,加上空洞卷积而已,设计不好,如果换成cpn,或许效果会很好。
个人觉得本文最值得学习的就是label定义,可以避免掉量化误差,后处理也比较简单,可以试着用在cpn上面,看下性能是否有提升。
PoseFix: Model-agnostic General Human Pose Refinement Network
论文:1812.03595 cvpr2019
地址:https://github.com/mks0601/PoseFix_RELEASE
本文和其他姿态refine做法不同,本文是相当于专门训练了一个姿态refine网络,和模型无关。只要输入预测pose和图片就可以refine。虽然看起来本文的做法在我们实际场景中应用范围有限,但是思想和loss、实验都是做的非常充分,值得细看。
核心思想:根据经验分析出pose estimation 模型的pose输出存在特定 的误差分布 ,根据这些误差分布,就可以和 ground truth 做合成 pose(synthetic poses), 将这个synthetic pose 作为网络的输入, 最后的输出和ground truth 做loss计算,网络收敛之后, 就有将其它pose estimation网络的pose 输出做refine的能力.
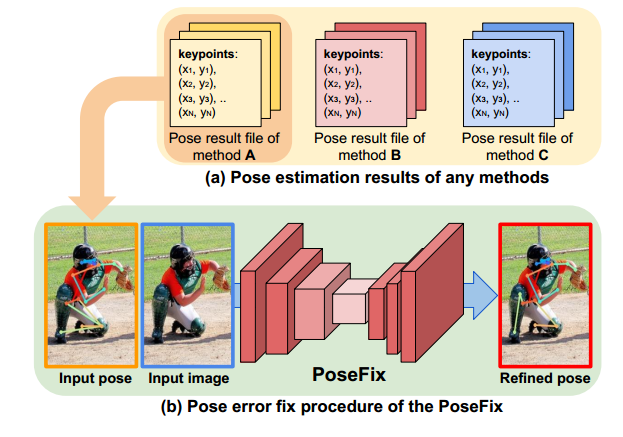
不知道这种思想可以泛化到其他任务中。
(1) 整体流程
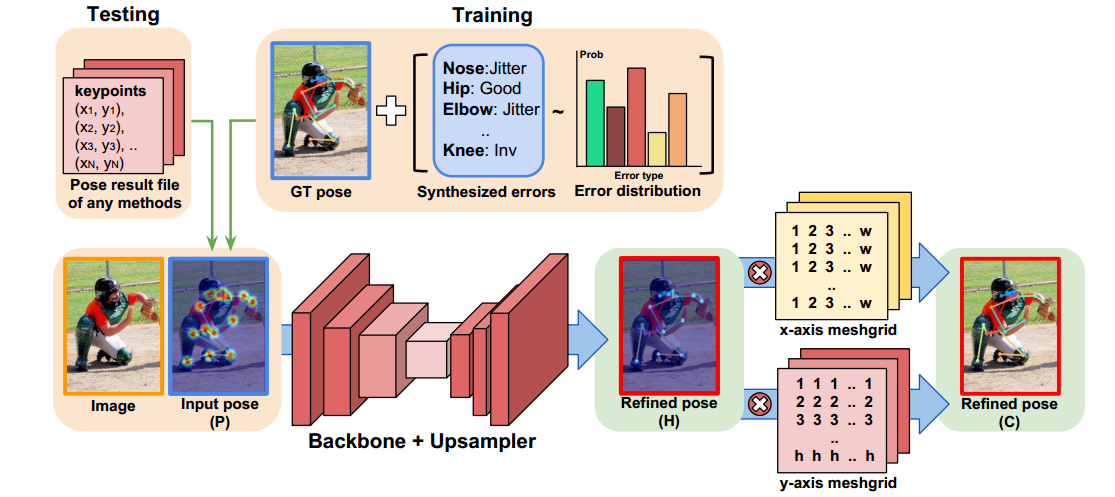
本文可以认为是top-down算法的refine模块。
(2) Synthesizing poses for training
本文全部利用论文Benchmarking and error diagnosis in multi-instance pose estimation. In ICCV, 2017中观察:通过对姿态估计算法预测的结果进行分析,可以发现大部分错误可以归纳为 jitter, inversion, swap, and miss。
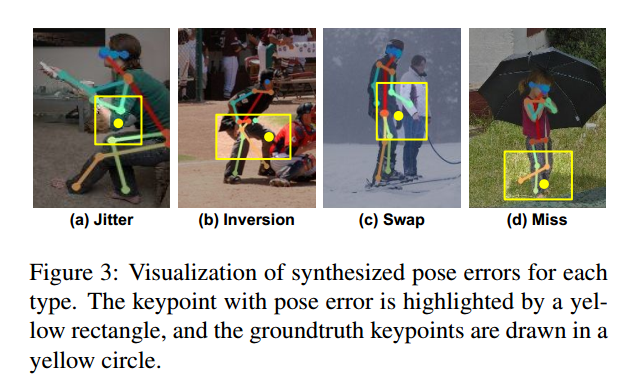
黄色为label点。我们可以利用这些误差得到先验误差统计分布,然后基于分布假设,结合gt关键点模拟这些情况,得到大量合成数据进行refine训练。具体的样本合成坚论文,这里就不重点关注了。
(3) Coarse-to-fine estimation
coarse这里其实是指高斯热图编码,fine是指One hot编码。
coarse-to-fine是指除了输入图片外,还要输入高斯热图作为coarse模式输入,但是预测输出是one hot编码的图。coarse提出定位信息,而fine可以得到更加准确的预测值,符合常理。 The generated input pose is concatenated with the input image and fed into the PoseFix。高斯热图输入不清楚是单通道输入还是多通道输入?看样子是分通道的。
(4) loss计算
由于one-hot的输出形式,故本文loss不再是回归的mse,而是交叉熵。本文还引入了Integral human pose regression. ECCV, 2018.中提到的soft-argmax算法来端到端训练直接得到关键点坐标。故现在网络输出有两个,H是one-hot热图,C是输出坐标。
C的计算来自:
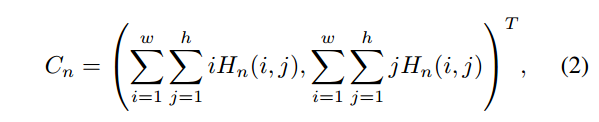
整个网络结构直接使用了Simple baselines for human pose estimation and tracking. ECCV, 2018。The final upsampling layer becomes heatmaps (H) after applying the softmax function. The soft-argmax operation extracts coordinates (C) from the heatmaps (H), and it becomes the final estimation of the PoseFix
(5) 实验
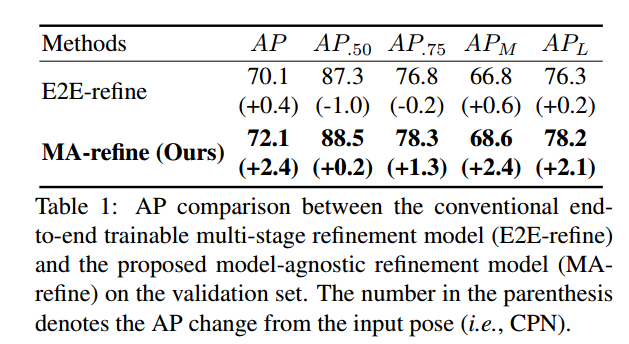
本文采用的姿态估计网络是CPN,也就是利用该网络的输出,然后输入到poseFix网络中进行refine,不是端到端训练的。为了公平对比,作者在cpn网络后面接了一个poserefine网络,端到端进行训练,得到上表。可以看出本文的优势 。用模型不可知的方法训练的MA-refine 相比传统的细化模型提高了精度。 我们认为这是因为在训练E2E-refine时,很容易发生过度适合CPN的输出姿态的情况。相比之下,posefix在训练阶段合成的各种输入姿势会产生数据扩充的效果,从而使得posefix在测试阶段对看不见的输入姿势更加鲁棒。

为了验证c2f的训练方式优点,进行了各种对比试验。可以看出,c2f效果会好一些比f2f。
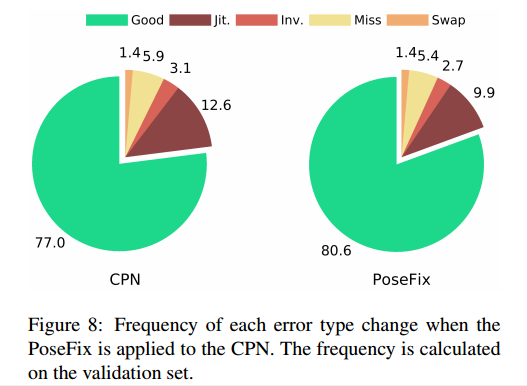
可以看出,各种先验误差都有改善。
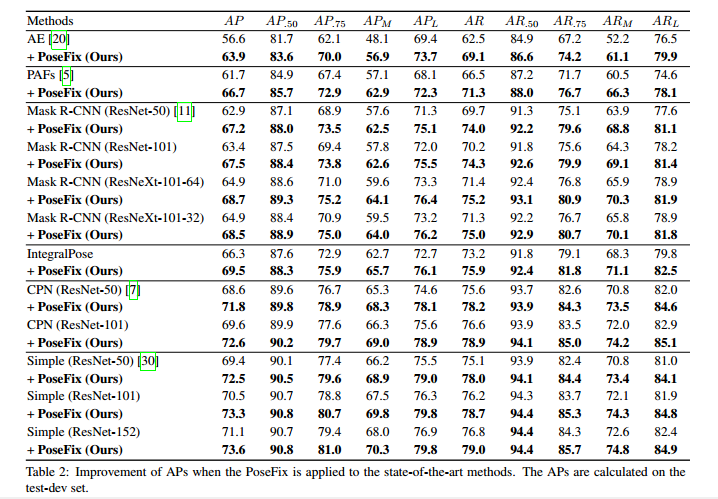
可以看出改善还是很明显的。

虽然看起来不错,但是为了refine,训练一个和cpn差不多的模型,真的有这个必要吗?要是有更加简单就能够达到统一思想的做法才行。
HintPose
https://arxiv.org/pdf/2003.02170.pdf iccv2019挑战赛
本文应用场景非常有限,但是思路可以看看,实际尝试价值应该没有。
本文就是解决一个问题:Most of the top-down pose estimation models assume that there exists only one person in a bounding box. However, the assumption is not always correct,例如下图:

无非准确判断到底哪个才是主体对象。此时就会检测错误。本文就是想解决这种图片的问题。
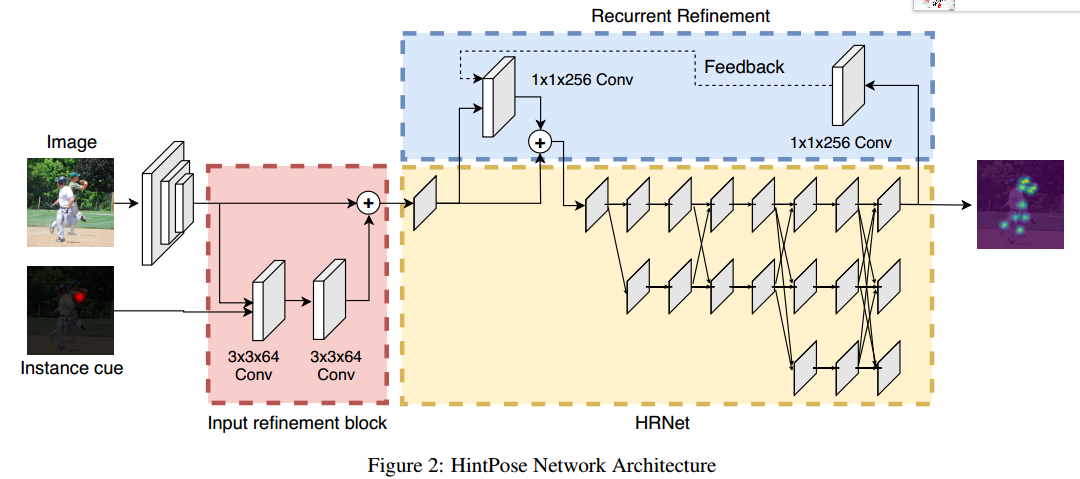
解决办法就两个:(1) 输入Instance Cue,引导网络找到主体;(2) Recurrent Refinement,本意是In addition to providing an external instance cue, it is also possible to use the outputs of the model itself as a hint for a target person。
(1) Instance Cue
额外输入一副高斯热图。在训练时候,该热图来自任意一个主体人上面的关键点,然后变成高斯热图输入即可。在测试时候,可以考虑很多来源,例如训练一个最简单的网络,只需要训练一个最明显的关键点就行;或者利用其它关键点检测网络,检测结果只挑选预测分支最大的那个关键点就可以作为实例线索输入。
(2) Recurrent Refinement
希望能够利用预测结果来refine自己的思想。引入了两个1x1卷积既可以,不增加负担。
训练时候:网络和ws-dan差不多,网络第一次运行,没有rr分支,得到预测结果,计算loss;然后再次前向2遍,得到2个loss,然后加起来进行反向传播。测试时候也是一样,推理三遍。
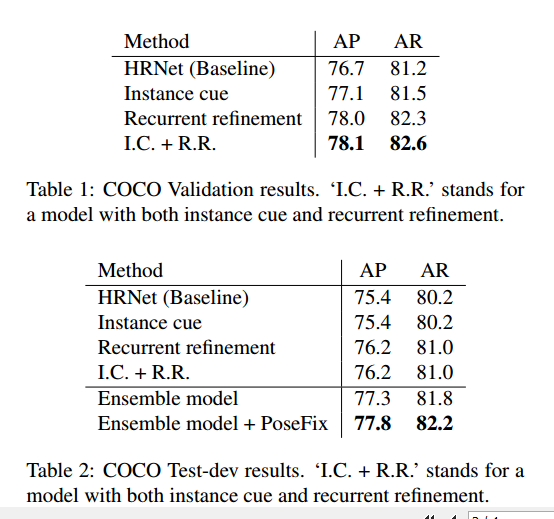
可以看出在验证集提升明显,测试集不明显。作者分析是测试集没有验证集中那么多的重叠人体样本。
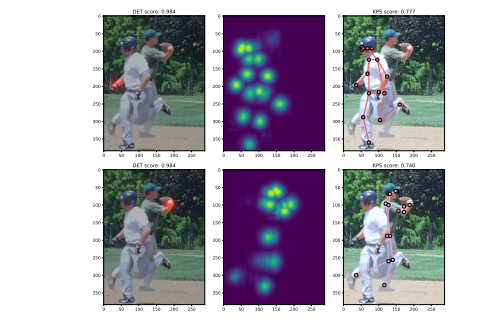
本文也指出由于是在coco上面进行测试和验证,但是coco数据其实拥挤程度不高,不能很好的发挥性能,故后续计划是在其他拥挤场景数据下测试,例如CrowdPose。
It is also possible to improve our model with a better
learning strategy as showed that curriculum learning is
vital to train its feedback network structure. Another way to
improve our model can be to use a different type of instance
cue, such as segmentation maps.
Simple Baselines for Human Pose Estimation and Tracking
代码:https://github.com/Microsoft/human-pose-estimation.pytorch
本代码可以认为是姿态估计的benchmark代码,写的很完善,可以仔细参考。
里面有flip种shift像素的操作。
https://github.com/microsoft/human-pose-estimation.pytorch/issues/69
hrnet也是微软的,所以代码也是几乎一样的。
本文是eccv2018,是最简单的姿态估计网络。
本文致力于 how good could a simple method be?Our pose estimation is based on a few deconvolutional layers added on a backbone network, ResNet in this work。得到结论: it seems that obtaining high resolution feature maps is crucial, but no matter how
这种说法启发了后面很多网络设计。
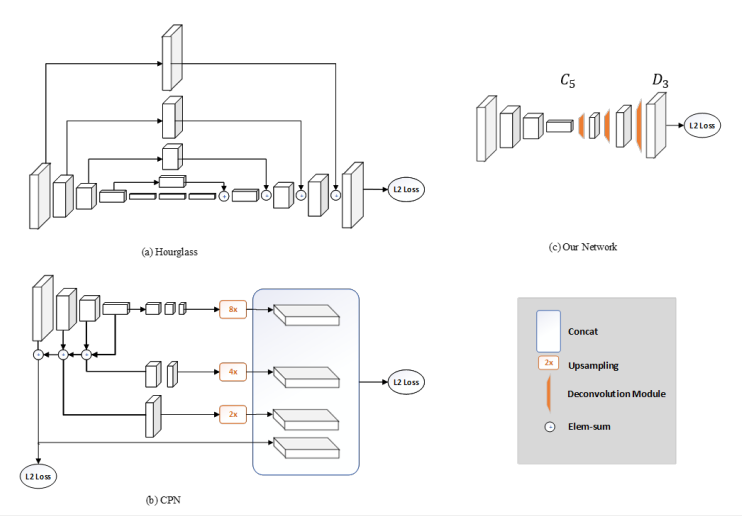
其中反卷积操作不知道采用上采样+卷积操作实现的,效果会不会一致,主要为了简单。
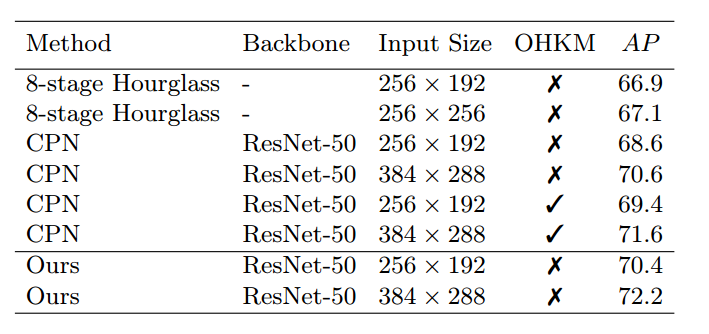
使用上述代码,别人使用resnet34代替resnet50(70.5),性能好像一模一样,但是resnet是65.7,mobilenetv2是64.8, moilenet v3 是68.5,但是速度好像也是蛮慢的。
Rethinking on Multi-Stage Networks for Human Pose Estimation
本文采用cpn中的globalnet模块作为sigle-stage模块,然后构建多阶段模型。赢得coco2018人体姿态估计关键。
地址:https://github.com/megvii-detection/MSPN 已阅读完
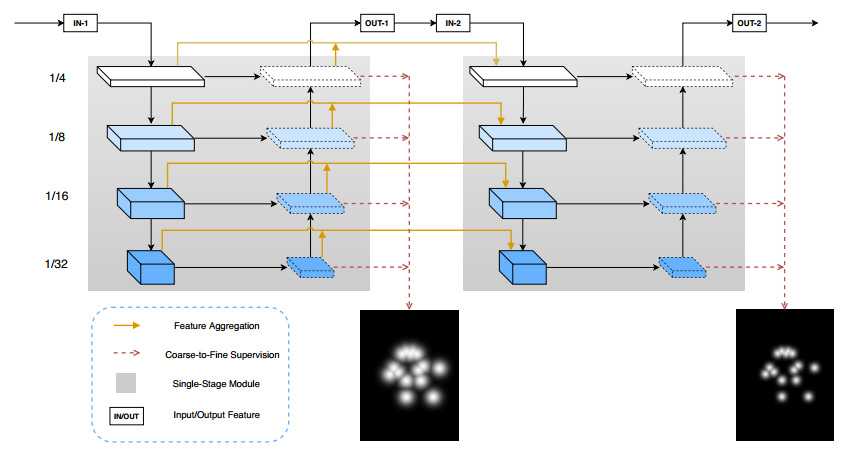
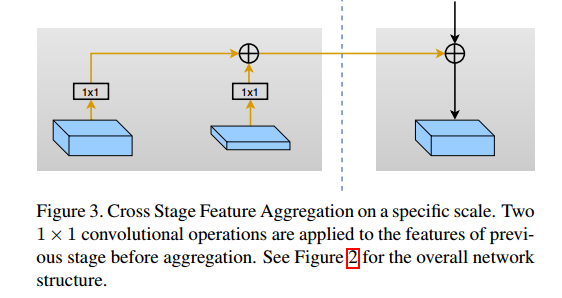
MSPN在预测前,融合的通道数全部是256,和cpn完全保持一致,目的是减少计算量。
Coarse-to-fine Supervision 属于cpn训练的特点了,在多stage中也发挥了该做法,we further propose to use different kernel sizes of the Gaussian in different stages,an
early stage uses a large kernel and a latter stage uses a small kernel。同时同一级的不同scale,也进行中级级别监督。相对于cpn网络应用ohkm于refinet阶段,本文an online hard key points mining (OHKM) is applied to the largest scale supervision in each stage即最大缩放尺度分支采用ohkm。预测高斯热图后处理采用经验准则。本文的实验结果比较有参考价值。
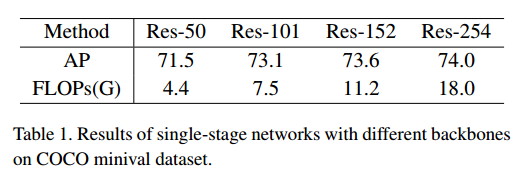
可以看出,采用res101及其以上虽然有提升,但是其实提升划不来。不应该用高于101的resnet。
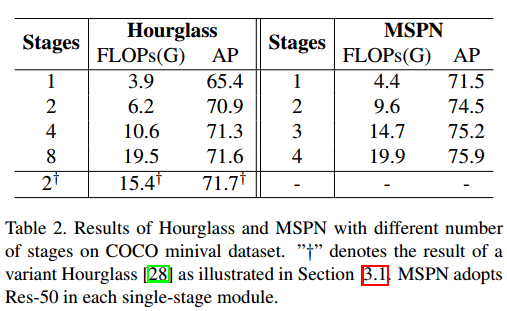
看起来,2个stage是最折中的做法,更多的stage,速度和内存是问题。
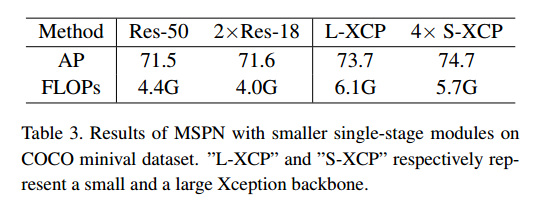
2个resnet18效果好于resnet50,并且内存更小。这里的2xresnet18是指2 stage的MSPN网络效果好于1 stage的resnet50骨架的网络。
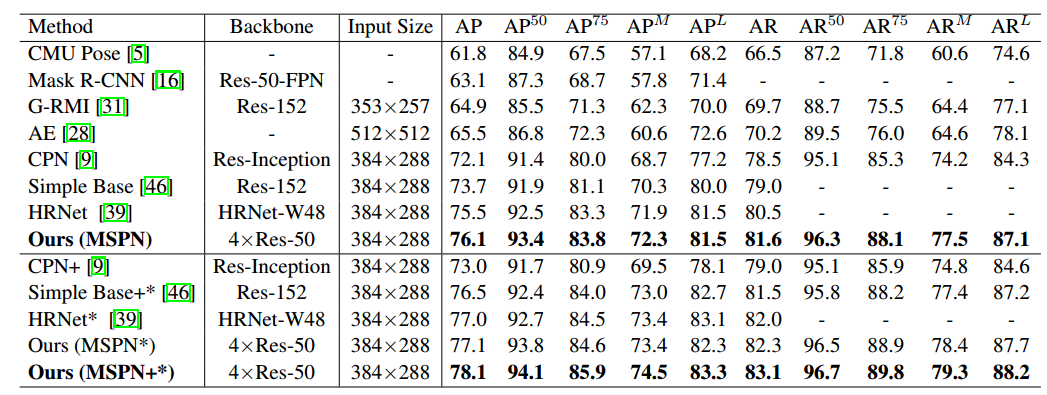
可以看出效果是很好,但是4-stage的MSPN网络应该非常大,实际用肯定不可取。
可以看出:
(1) 人体姿态估计其实主要靠骨架,骨架好,效果就不会差到哪里去
(2) 多stage方法,特别是2-stage的做法应该是非常可取的,骨架应该选择轻量级的
代码细节:
其他地方都好理解,需要注意的是Coarse-to-fine Supervision,在每个stage中,都是4个输出,不同输出采用不同的高斯核参数。但是对于多stage的,假设总共stage=2,那么生成的高斯核其实有5个尺度,第一个stage,采用前4个高斯核,第二个stage采用后4个高斯核,就能实现论文效果。如果有3个stage,则总共高斯核应该有6个尺度,按照上述做法来得到粗糙到精确的高斯热图。
Bottom-Up Higher-Resolution Networks for Multi-Person Pose Estimation
地址:https://github.com/HRNet/Higher-HRNet-Human-Pose-Estimation
hrnet应用于bottom_up方法上面进行多人姿态估计。采用gounp方法是AE。
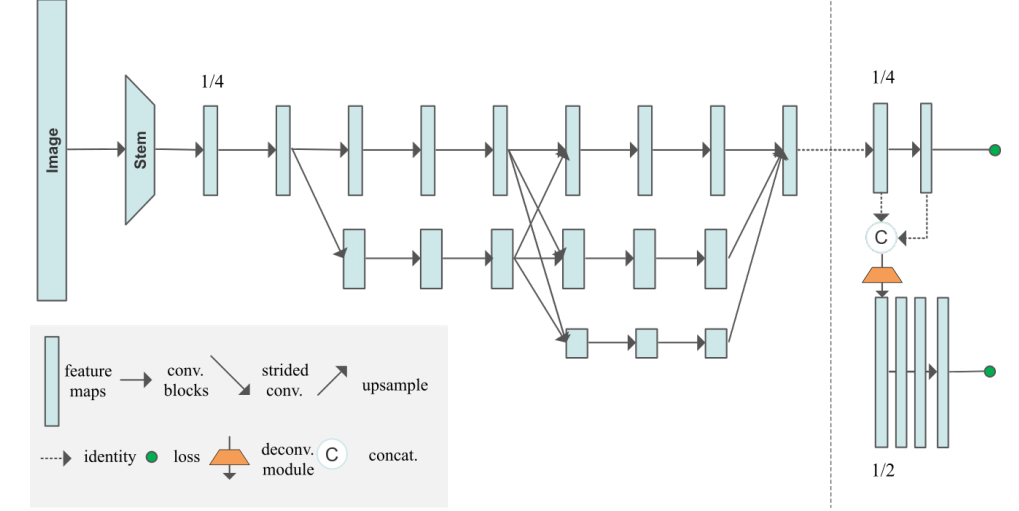
本文主要也就是讲述网络,重点是代码。
其为啥叫做higherNet,而不是hrnet,主要区别是后半部分。backbone部分是完整的hrnet,但是作者考虑到bottom up方法要想精度高,那么输出1/4图示不够,至少要1/2,故作者又进行反卷积得到1/2的,然后采用l2进行监督。更多的细节应该要看代码。
Heatmap Aggregation for Inference。 We use bilinear interpolation to upsample all the predicted heatmaps with different resolutions to the resolution of the input image and average the heatmaps from all scales for final prediction. This strategy is quite different from previous methods
Simple Pose 重点
地址:https://arxiv.org/abs/1911.10529 AAAI2020
代码:https://github.com/jialee93/Improved-Body-Parts
可以认为是open pose的改变版本。
主要改进是:
(1) 改进了openpose(CMU-Pose)的paf表达方式,使其更加自然
(2) hourglass引入了注意力机制
(3) 引入focal L2 loss
(4) robust greedy keypoint assignment algorithm for grouping
1. Definition of Heatmaps
对于关键点,和原来一样,还是采用没有归一化的高斯热图表示,值是0-1之间。对于关键点连接部件,openpose是All the pixels within the approximate limb area (may include outliers of the limb) have the same ground truth value, which brings about vagueness or even conflicts to the information representation。而本文提出的body part Pixels near to the major axes of the body parts
have higher confidence and vice versa. And we only need
the half dimensions of PAFs to encode the keypoint connection information。也就是连接部件也采用椭圆高斯热图编码形式,而不再采用paf的格式。好处是(1) 更加容易理解;(2) 可以和关键点检测任务一样,都是高斯热图回归,同一个任务更加容易优化。
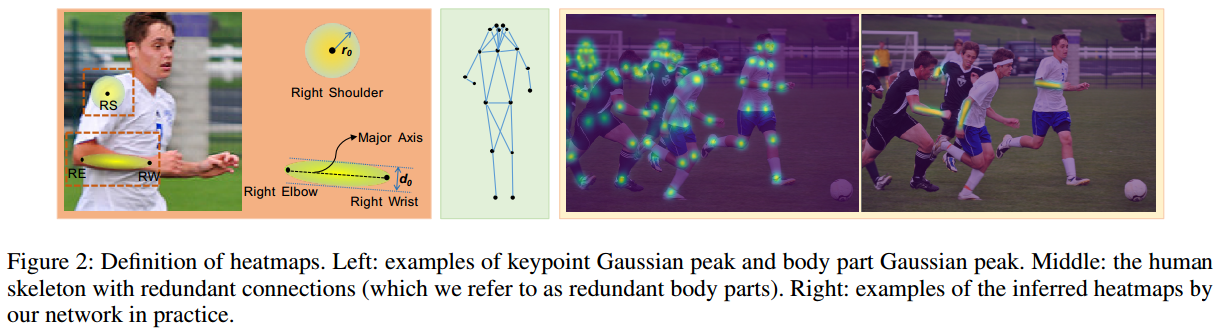
通过左图可以看出label构造方式。有两个核心参数:关键点高斯热图标准差,部件连接椭圆高斯热图标准差,非常关键,用于控制前景和背景像素比例。还有d和r参数,也是非常关键。用于截断高斯分布,通过阈值控制。
2. Network Structure
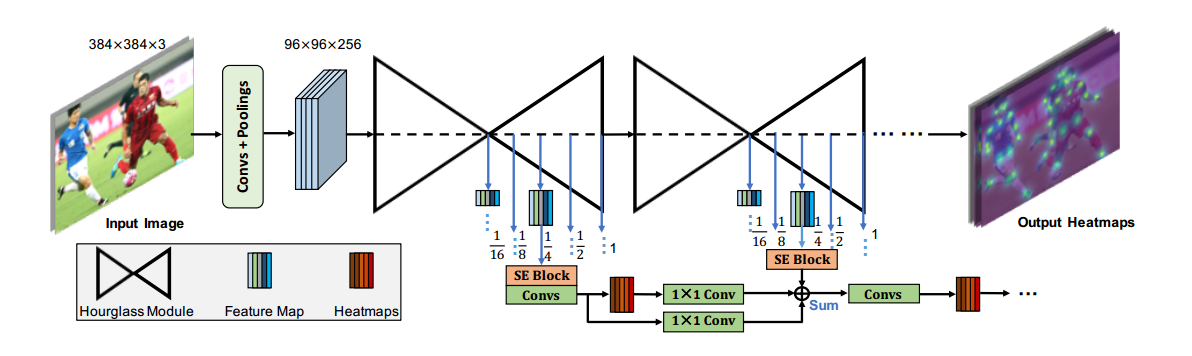
每个stage输出5个尺度特征图,每个特征图都进行监督。上图仅仅画出了一个尺度的网络结构。
3. Loss Functions 本文重点
目前常有的是L2和ohkm-L2,本文基于focal loss思想提出focal l2。
if we set them(标准差) too small, the accurate localization information is preserved but the inferred responses at these peaks tend to be low, resulting in more false negatives. On the other hand, if we set them
too big, the Gaussian peaks spread so flat that the localization information tends to become vague at inference time,
harming localization precision (using offset regression may
relieve this problem)
假设有K个关键点和P个连接部件,一共有T个stage,每个阶段的预测高斯热图定义为S_t,对应的gt值,定义为S*:

第一行是关键点热图的高斯定义,第二行是连接部件的高斯定义,其中R是stride,也就是网络输入和当前输出的缩放倍数。

定义S_d对输出高斯热图进行惩罚,thre是用来定义正负样本的。默认是0.01,当gt值的某位置值大于阈值,则任务是正样本,否则为负样本。阿发和贝达是用来减少对易样本的惩罚程度。默认,要结合后面的公式才好理解。
focal l2的定义如下:
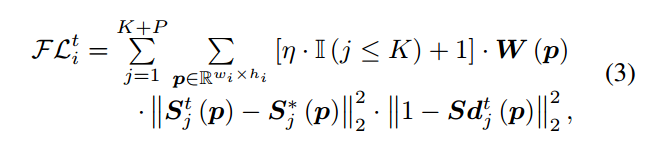
K+P是指所有关键点和连接部件的和,wxh是高斯热图size,W(P)是用于处理当没有关键点标注的场景,当该关键点没有标注时候W(P)=0,否则为1。是用来控制K个关键点和P个连接部件的权重。s_t-s*的范数是l2 loss。重点是后面的惩罚系数。由于这里是1-,举例,当在某gt位置,label是0.98,预测值是0.9888,此时预测值要减掉,变成0.8888,然后再次1-,得到0.12222,可以看出,当预测值越大,此时表示越是容易样本,此时惩罚系数越小,其权重就会越小。而且可以看出就是明显用来减少惩罚的。当过大时候,对容易学习样本惩罚就越小,其权重越大。当时候,相当于就是普通的l2 loss。故想增加对容易学习样本的惩罚程度(减少其权重),那么就要越小。由于1-sd的存在,可以在确定正负样本后,对不同位置的预测值引入不一样的惩罚,例如0.98,0.81都是正样本处的gt值,但是其惩罚是不一样的,虽然是一样的。
4. 关键点分配算法
论文写得不是也很清楚,可能要看论文才能知道。

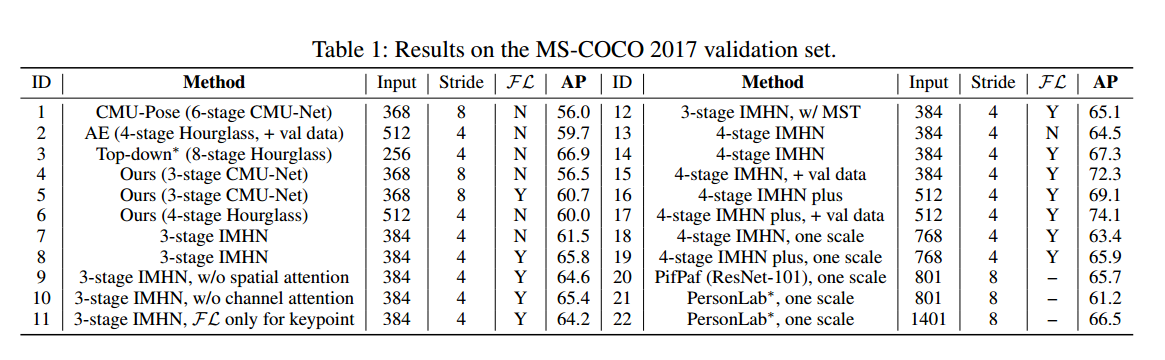
看起来提高很多。focal l2左右很大。
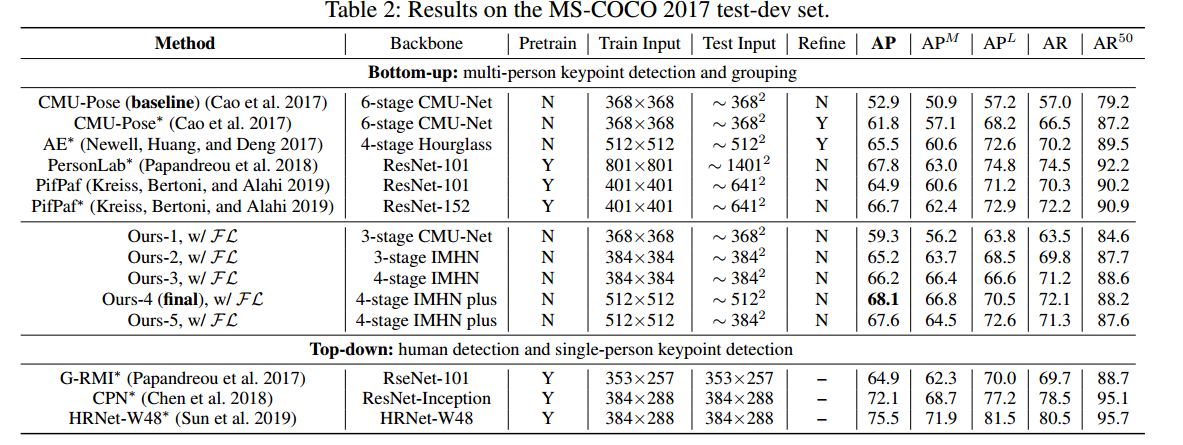

看起来分配算法比较难搞,速度非常慢。
依然可以看出,bottom-up的做法精度始终要比top dowm的方法低很多。
可以尝试将focal l2 loss应用于cpn中看下是否有精度提升。
RePose: Learning Deep Kinematic Priors for Fast Human Pose Estimation
https://arxiv.org/pdf/2002.03933.pdf
谷歌提出的轻量级人体姿态估计网络,特定是利用了人体的结构先验来提高精度。 没仔细看,这里仅仅做个记录,不知道有没有参考价值。

人体先验

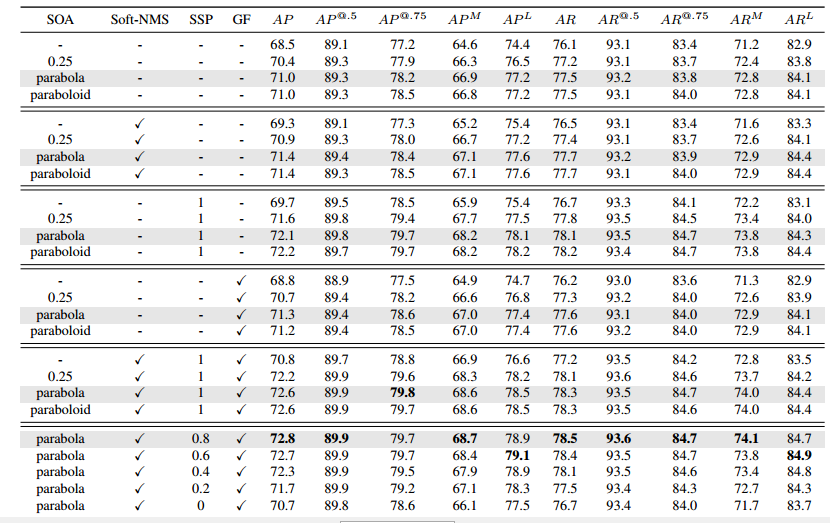
Towards High Performance Human Keypoint Detection-CCM 优秀论文
https://arxiv.org/abs/2002.00537
https://github.com/chaimi2013/CCM
本文获得2018 coco关键点检测冠军。主要提出了三个策略:(1) 提出了一个CCM模块,提供特征提取能力;(2) 提出了一个hard-negative person detection mining strategy;(3) 提出一系列可自由组合的亚像素后处理办法。本文后处理部分比较好,等代码公布,可以考虑使用。
(1) CCM
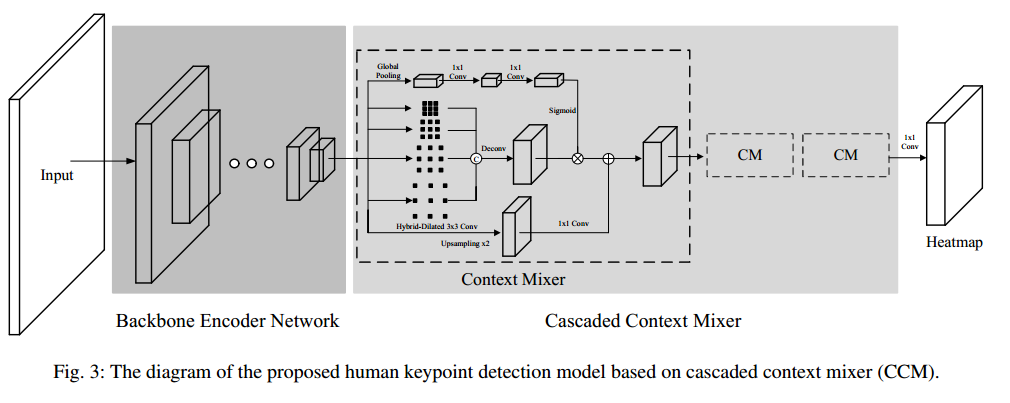
CM模块如上所述,主要包括SE、空洞卷积核aspp设计思想。将CM模块级联,每个cm模块的输出都会上采样二倍,CM相当于一个解码器模块,只不过比较重量级。计算量比较大。
在倒数第二个CM模块中,作者还使用辅助Loss。这也是常用技巧,loss是MSE
(2) Hard-Negative Person Detection Mining (HNDM)
虽然本文方法是单人关键点检测,但是输入图片依赖于上一级检测器, the keypoint detection model is usually trained with ground truth bounding box annotations enclosing exact person instances. It has never seen any false positive detections during the training phase. 训练时候不会出现难负样本,但是测试时候会出现,导致训练和测试分布不一致,当输入负样本时候,网络也会输出高响应值,这是不好的,故作者在训练中特意利用检测器的虚检结果加入到网络训练中,强制输出低响应值,抑制这部分输出。
(3)亚像素后处理
这部分内容比较重要,如果代码出来,需要仔细看。
以前常有的后处理办法有0.25-pixel shift of the maximum response pixel最大响应输出处加上次最大响应处值偏移0.25像素,
one-pixel shift of flipped heatmap 用于flip测试时候的策略,保证flip后对齐, and Gaussian filtering of predicted heatmap 高斯滤波策略。
作者基于这几个做法进行了归纳,(1) 二阶近似;(2) Soft Non-Maximum Suppression;(3)extending the one-pixel shift of flipped heatmap
to a general sub-pixel form;(4) 高斯滤波
其中(1) 和(4) 是通用做法,(2) 是应用到一个人有多个检测结果,然后输入网络得到多个预测输出时候,进行的关键点级别的nms操作;(3) 是flip增强应用时候的扩展做法。重点是(1)。需要注意的是这几个后处理办法是可以一起用的。
(1)Sub-pixel Refinement by the Second-Order Approximation
分为两种处理办法:单个维度进行抛物线近似和两个维度同时进行抛物面近似。
单个维度进行抛物线近似公式:
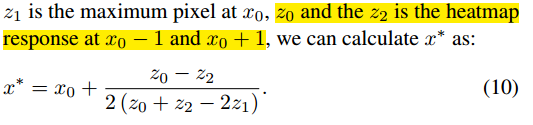
抛物面拟合:


(3)sub-pixel shift of flipped heatmaps (ssp)
暂时没有搞懂这个不对齐问题

Distribution-Aware Coordinate Representation for Human Pose Estimation 优秀论文
arxiv 1910.06278
https://ilovepose.github.io/coco/
本文比较重要,第一篇文章对高斯热图进行深入研究,提出一个后处理办法进行亚像素refine。可以和CCM论文一起看,都是后处理策略,和训练无关。
以前采用的经验法如下:
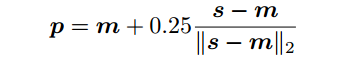
m是最大响应位置,s是第二大响应位置。
上述做法是经验做法,本文提出更加系统严格的推断。细节没看,结论是:
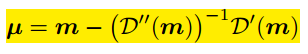
D是输出的高斯热图,m是最大响应位置。
上面得到的结论是基于输出的高斯热图是标准的热图,实际预测的不一定的,一般会包含多个峰值,故需要进行前置一步:
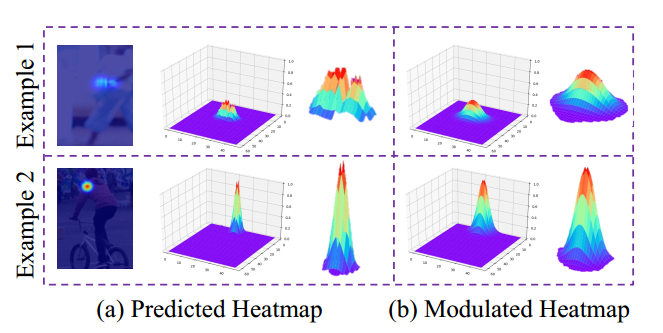
左图是预测的图,右图是进行处理后的图,实际做法就是高斯滤波,然后归一化即可。故本文提出的算法完整流程为:
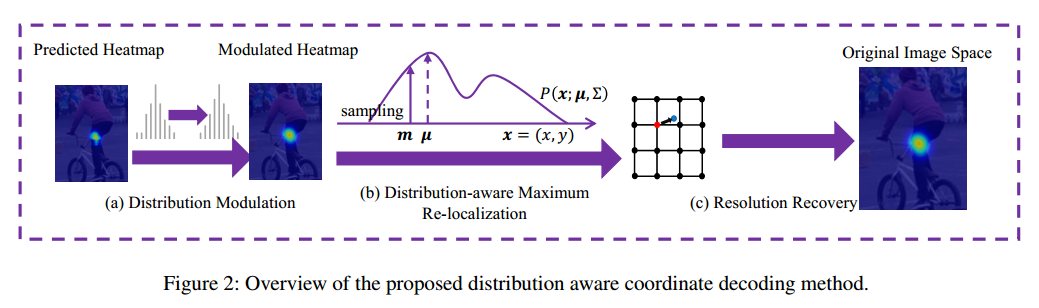
先进行高斯滤波,然后进行归一化,然后进行亚像素二阶计算,最后乘上缩放系数得到最终坐标。
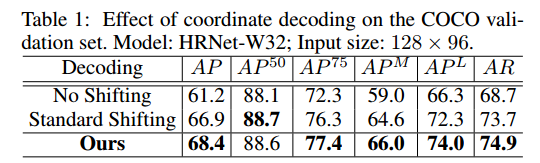
在小分辨率输出上面,可以看出,即使采用标准后处理办法也可以提高很多精度,采用本文做法精度可以提高更多。
在数据前处理中,作者也提出了无偏数据处理办法,其实就是计算高斯热图时候不要进行量化,尽量用原始真实值。
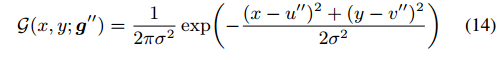
其实就是在计算高斯热图label时候,均值(关键点)不要用量化值,而是用原始值,但是这样的做法,可能会比较计算慢。
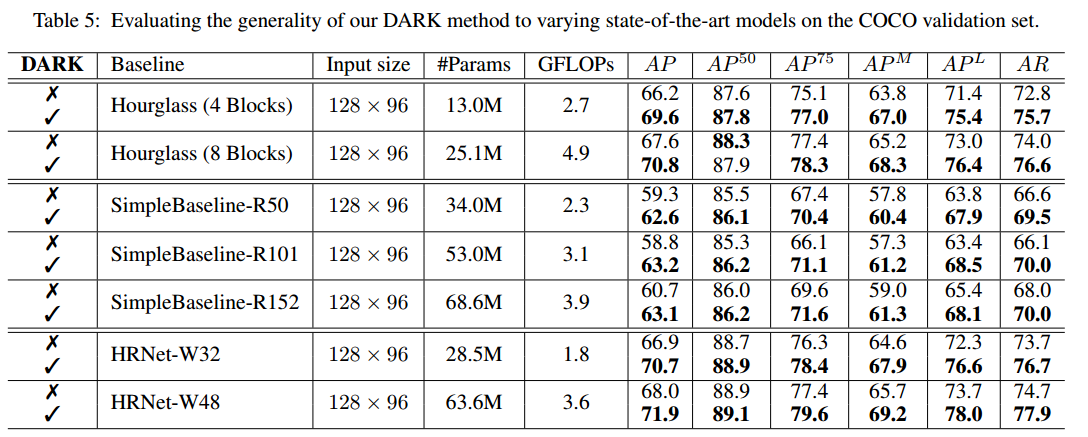
可以看出,效果显著。
代码实践
label生成要求
原来的生成高斯热图的方法是:def generate_heatmap(shape, pt, sigma):
"""
:param shape: shape of heatmap
:param pt: array, points
:param sigma: 标准差
:return: 高斯热图 (值为0~255)
"""
heatmap = np.zeros((int(shape[0]), int(shape1)))
if (pt[0] >= shape1) or (pt1 >= shape[0]) or (pt[0] < 0) or (pt1 < 0):
return heatmap
heatmap[int(pt1), int(pt[0])] = 1
heatmap = cv2.GaussianBlur(heatmap, sigma, 0)
am = np.max(heatmap)
heatmap = heatmap / am
return heatmap
注意上面生成的高斯热图的中心点已经取整了,这是不好的,因为在label层面就已经损失精度了,不能取整,参考代码如下:class GaussianMapGenerator(object):
def init(self, shape_hw):
assert isinstance(shape_hw, (list, tuple))self.h, self.w = shape_hw self.xx, self.yy = np.meshgrid(np.arange(shape_hw[0]), np.arange(shape_hw[1])) def __call__(self, center_xy, sigma_px=2): gaussian_map_hw = np.exp( -((self.xx - center_xy[0]) ** 2 + (self.yy - center_xy[1]) ** 2) / (2 * sigma_px ** 2)) return gaussian_map_hw当然这样生成的高斯图,最大值可能不是1,但是其实没啥关系。
在生成不取整的高斯热图后,在进行亚像素级别的后处理才是正确的做法,否则由于label生成的时候就已经丢失精度了,那么后面后处理也就没啥用途了。- 后处理
现在我们保证了生成的高斯热图没有损失精度。但是如何从生成的只有整数位置的图片坐标中恢复出真实的带小数点的中心点坐标? 也就是说如何从离散高斯分布采样值中估计出连续高斯分布参数得中心点? 有很多种做法,下面仔细分析。
2.1 经验估计法
在Hourglass论文里面提到的方法。非常简单。
m是最大响应位置,s是第二大响应位置。可以看出这只是个经验做法。This means that the prediction is as the maximal activation with a 0.25
pixel (i.e. sub-pixel) shifting towards the second maximal
activation in the heatmap space.
2.2 二维高斯曲面拟合后处理
参考:https://blog.csdn.net/houjixin/article/details/8490653/
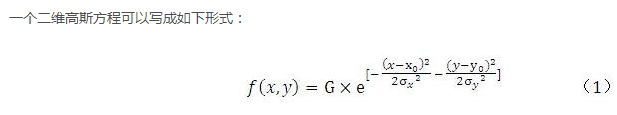
忽略幅值G,是浮点中心坐标,由于生成的高斯热图是整数坐标的,故x,y坐标都是整数值,现在我们基于整数坐标的高斯值,估计得到高斯分布参数,是很典型的参数估计问题。参数估计肯定是采用极大使然估计方法。
其实有个疑问:我们预测得到的是整数坐标下的高斯分布值,现在要估计其精确的中心点坐标,这不就是普通的最大使然估计吗?求解的均值就是所有数据坐标点的平均值:
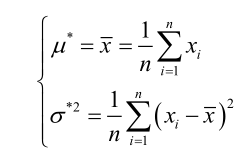
那不是直接就求出来了吗?为啥还有那么多复杂的操作?难道是因为这样估计得到的值还是不够精度?没有想明白。
下面开始分析上述博客做法。
对式(1)两边取对数,并展开平方项,整理后为,左右两边各乘f:
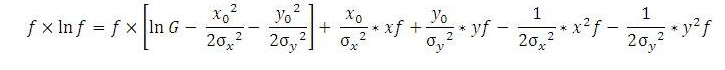
f是预测的高斯热图,例如100x100,f_i是其中第i个位置的预测值。
假如参与拟合的数据点有N个(自己挑选处理,因为图片像素太多了),则将这个N个数据点写成矩阵的形式为:A = B C,其中A为N*1的向量,其元素为:
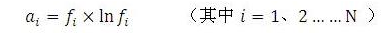
B为N*5的矩阵:

C为一个由高斯参数组成的向量:
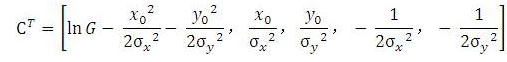
现在已知f和标准差,需要求,即需要求A=BC
N个数据点误差的列向量为:E=A-BC,用最小二乘法拟合,使其N个数据点的均方差最小,即


要想这个MSE最小,由于只有C才是未知数,S和T都是常数(N个点数据可以得到),故:

优化到这一步,其实答案就已经出来了,即我们只要基于N个点数据得到那就可以得到C了,然后自然就求出中心坐标了。
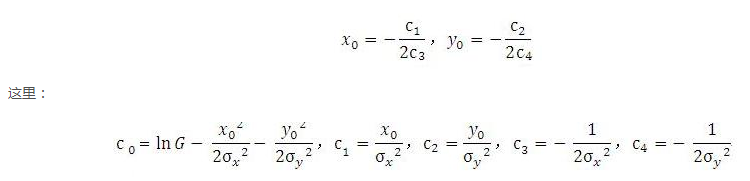
代码流程也很简单了:预测高斯热图->采样出N个点->构造A,B矩阵->对B矩阵进行QR分解->基于A,Q, R 计算得到C-> 得到中心坐标.
参考代码:
def calcSubpixelGaussianCenter(gaussianMap2d, center_xy_int, sigma_px=1):
"""
Calculate gaussian map center in subpixel accuracy.
reference blog: https://blog.csdn.net/houjixin/article/details/8490653/
Args:
gaussianMap2d: 2d gaussian map
center_xy_int: initial center in int accuracy
sigma_px: determine the valid neighbor range by 3*sigma principle
Returns:
(cx, cy): subpixel center coordinates, tuple of (cx, cy)
"""
assert isinstance(gaussianMap2d, np.ndarray)
assert gaussianMap2d.ndim == 2
# extract gaussian map by initial center and 3*sigma
h, w = gaussianMap2d.shape
_3sigma = int(sigma_px * 3 + 0.5)
xx, yy = np.meshgrid(np.arange(max(center_xy_int[0] - _3sigma, 0),
min(center_xy_int[0] + _3sigma + 1, w)),
np.arange(max(center_xy_int[1] - _3sigma, 0),
min(center_xy_int[1] + _3sigma + 1, h)))
neighbors = gaussianMap2d[yy, xx]
# construct equation
A_nx1 = (neighbors * np.log(neighbors)).reshape((-1, 1))
B_nx5 = np.dstack([neighbors,
neighbors * xx,
neighbors * yy,
neighbors * xx ** 2,
neighbors * yy ** 2]).reshape((-1, 5))
# solving equation, read reference blog for details
Q_nxn, R_nx5 = np.linalg.qr(B_nx5, mode='complete')
S_5x1 = Q_nxn.T.dot(A_nx1)[:5]
C_5x1 = np.linalg.inv(R_nx5[:5]).dot(S_5x1)
# compute subpixel cx and cy from solved C
cx = np.round(-C_5x1[1, 0] / (2 * C_5x1[3, 0]), decimals=3)
cy = np.round(-C_5x1[2, 0] / (2 * C_5x1[4, 0]), decimals=3)
return cx, cy
2.3 Distribution-Aware Coordinate Representation 解码方法
2d高斯热图表示:
https://blog.csdn.net/senius/article/details/102595771
http://www.ilovepose.cn/t/99
http://www.ilovepose.cn/

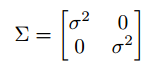
标准差是已知的,现在要求均值。下面开始进行最大使然估计:
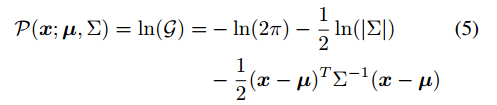
对上式子求导,并且导数为0:
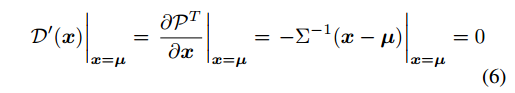
看上述例子可以知道如果我们能够取得x=,则取得了中心点,但是实际上我们知道我们不一定能够得到,为了最大程度逼近这个值,我们采用泰勒级数展开进行逼近:
直接对在处展开,得到二阶表达式:
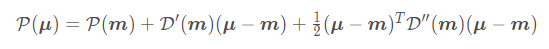
可以看出就是比原始的高斯分布公式多了一个二阶泰勒展开而已,
这里μ=[x ,y]是一个二维变量,由热力图上的值,我们能得到这个分布在m上值D(m)、偏导向量D'(m)和海森矩阵D''(m),于是分布的参数全部知道,所估计的分布函数也知道了,于是通过下面的步骤求出估计的极值点:
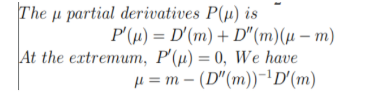
故最终的式子是:

其中:
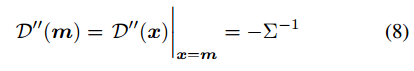
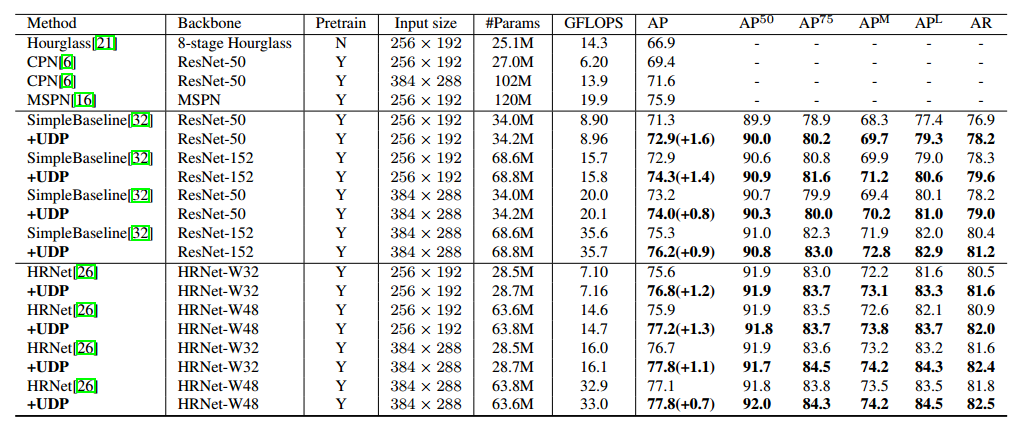
The Devil is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation 优秀论文
arxiv 1911.07524
https://github.com/HuangJunJie2017/UDP-Pose
https://zhuanlan.zhihu.com/p/107170931
本文和上面两篇要解决的问题一样,也是提出一种后处理办法,但是网络要重新训练,性能和dark差不多。
也是要解决两个问题:一个是在测试过程中,如果使用flip ensemble时,由翻转图像得到的结果和原图得到的结果并不对齐。另外一个是使用的编码解码(encoding-decoding)方法存在较大的统计误差。这两个问题耦合在一起,产生的影响包括:估计的结果不准确、复现指标困难、有较大可能使得实验的结果结论不可靠。
在对上述两个问题的量化分析基础上,我们提出用于人体姿态估计的无偏的数据处理方法(UDP)。UDP 包含两个主要的思想: 一个是在数据处理的时候,使用单位长度去度量图像的大小,而非像素的多少,以解决第一个问题。另外,引入一种在理想情况下无统计误差的编码解码方法。
第一个问题的解决数学推导非常多,没咋看懂,但是应用应该非常简单。
第二个问题分为编解码阶段:
编码过程: 如下图所示,每个关键点的坐标使用圆形区域进行标注,而不是之前的高斯滤波的方式。且配合两个偏置map图,也就是说训练label不是高斯热图,而是圆形热图。现在预测的输出不再是一个热图了,还要包括两个offsett图,类似谷歌G-RMI论文(Towards accurate multi-person pose estimation in the wild)做法。
解码过程: 在解码过程中,我们首先使用高斯核K对热图进行滤波,使其最高响应位于地面真值点附近。且高斯核如公式28所示。最终的坐标值还需要利用偏置进行反算。还原需要使用高斯核、预测的热图和预测的offset图。经过上述编解码阶段,统计误差是0。


Single-Stage Multi-Person Pose Machines ICCV2019 优秀论文
单阶段多人姿态估计
http://openaccess.thecvf.com/content_ICCV_2019/papers/Nie_Single-Stage_Multi-Person_Pose_Machines_ICCV_2019_paper.pdf
spm其实非常简单,可以认为是centernet进行姿态估计的简单改进版本。
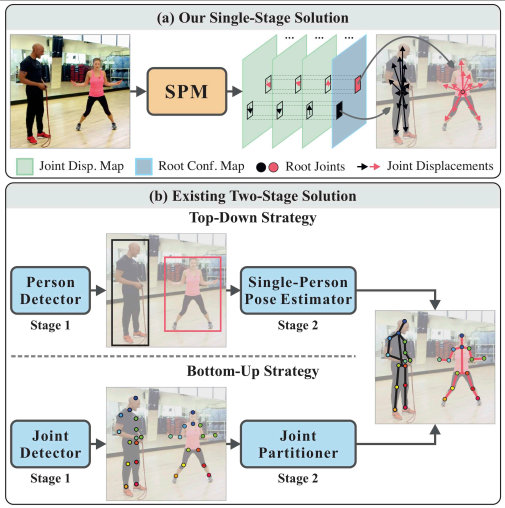
其实就是预测中心点+基于中心点的偏移,这就是centernet的做法,本文稍微进行了改进,主要原因是offset有远有近,直接计算距离loss,惩罚不一样,难以训练一个比较好的检测器。
故本文利用人体结构对offset学习进行拆解,相当于分层预测,每一层预测的offset都是短距离的,如下图:
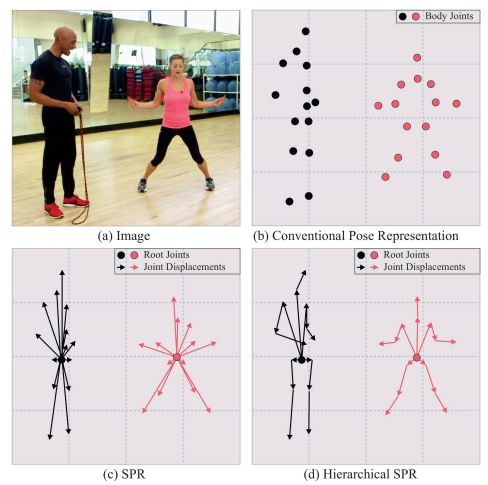
如(d)所述,层次offset预测结构。
(1)Regression target for root joint position
中心点才有高斯热图建模方式。loss是mse
(2) Regression target for body joint displacement
关键点偏移采用密集图,即在根关键点的某一半径范围内offset值都进行回归,和以前的不同是,本文的offset预测是分层的,基于人体骨架一共分层4层,每一层都是只预测短距离值而已。输出的特征图通道是跟节点第一层+5个第二层节点+5个第三层节点+4个第四层节点,每个节点学习的offset都是相对于上一层而言的。前向时候,先得到中心更节点,然后利用更节点索引,去后面5个通道上面读取到offset,然后基于当前offset特征图位置索引到下一层offset,最终值就是累加和值。
loss是l1距离如下所述:

主干网络是Hourglass。先得到所有人的根节点,然后利用offset得到最终的其余关键点坐标。
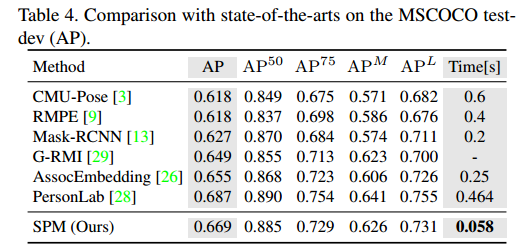
可以看出最大特点是速度快。
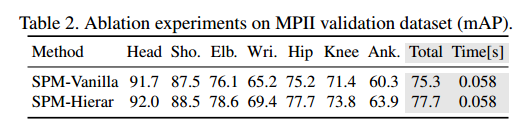
总体来说,这种做法肯定比centernet好一些,但是精度是否够是一个问题。
Nonparametric Structure Regularization Machine for 2D Hand Pose Estimation
arXiv:2001.08869
https://github.com/HowieMa/NSRMhand
本文非常像当初做积木关键点检测时候的做法,就是引入mask来提高检测精度。做法值得参考。
本文核心思想如下:
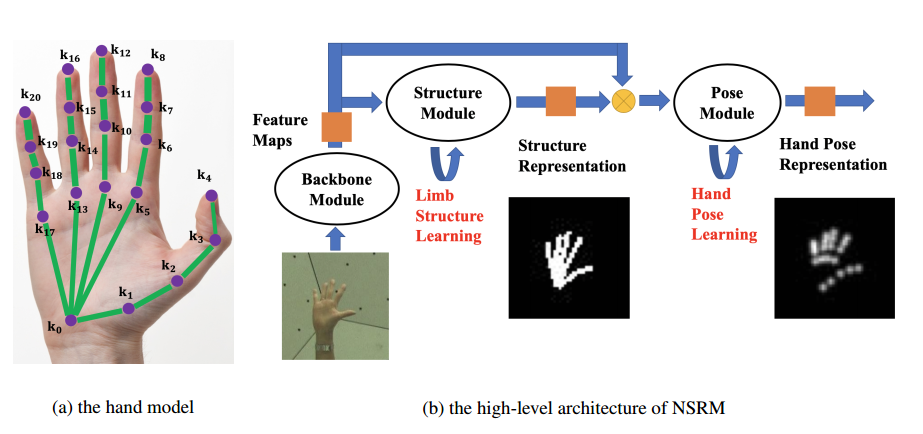
基于CPM模型,前面几个阶段学习手部结构mask,后面几个阶段学习pose。
具体如下:
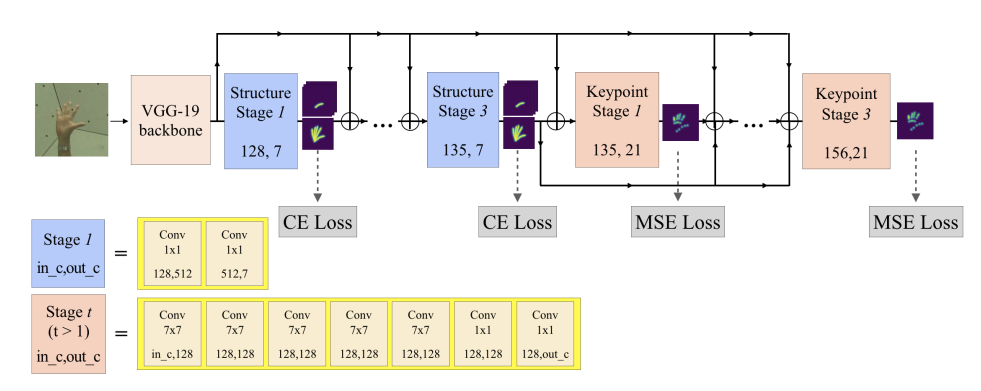
CPM一共包括6个阶段,前三个阶段学习手部结构mask,后面三个阶段学习Pose.
其中手部结构mask构造,作者提出了两个:
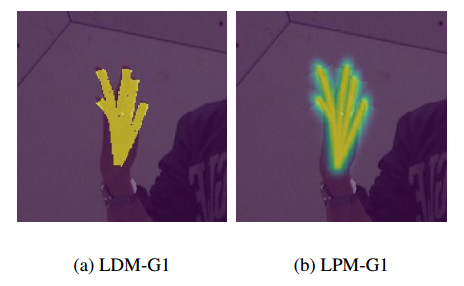
一看就知道啥意思,G1是指一张图表示所有关键点结构,作者还引入了G6分成6个通道表示,关注更多细节:

作者的实验分为CPM+LDM和CPM+LPM,其中每个又分为G1和G1&G6(通道方向拼接)
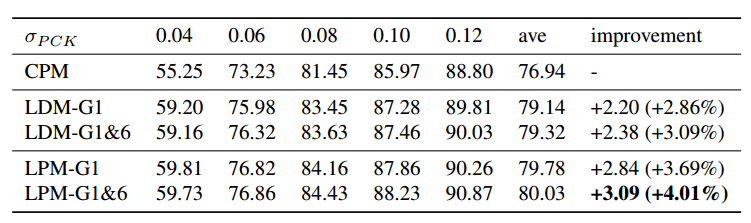
可以看出,LPM-G1&6更好。一些可视化:


DirectPose: Direct End-to-End Multi-Person Pose Estimation
arxiv 1911.07451
代码:https://github.com/aim-uofa/adet 算是一个思想吧,效果一般,速度也慢,主要是思想直接。网络和思想和PolarMask几乎一致,但是个人感觉做的没有PolarMask好。
如何进行一阶段的多人姿态估计?Single-Stage Multi-Person Pose Machines是一种做法,其实还有一种更加简单的,直接回归坐标值的做法。考虑FCOS检测bbox的做法,一条分支进行目标分类,一条分支进行bbox学习,其学习的是中心点相对于左右边的offset,也就是说回归特征图示hxwx2,如果我将其扩展为17个关键点,那么直接回归hxwx17就可以进行多人姿态估计了(实例分割转换为轮廓实例学习也是这中做法可以参考polarmask),非常naive的做法:
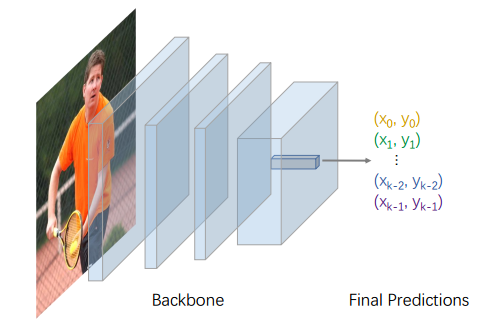
但是如此nvive的做法,性能肯定不是很好,因为特征图上面一个点要回归2x17个值,这些offset距离有进有远,直接回归效果肯定很差。故本文在这个思想基础上新加一些模块和分支,目的使得这中思路效果达到可以接受的水平。
核心就是提出一个Keypoint Alignment (KPAlign) mechanism ,位于关键点检测分支。
整体结构是基于FCOS:
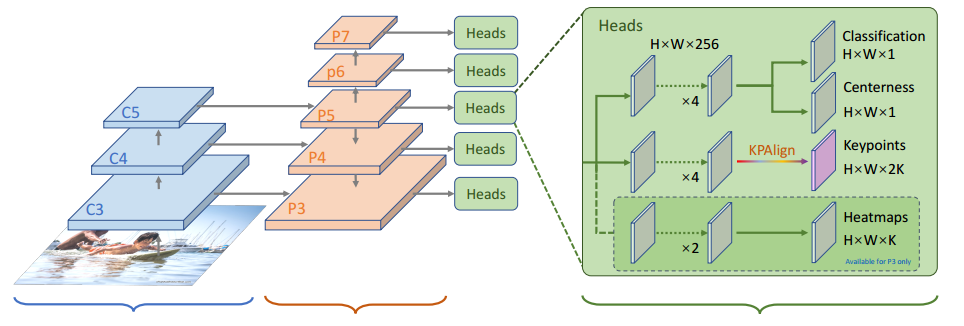
不需要bbox分支。前两个分支和目标检测一样,第三个是关键点检测分支,新增了KPAlign模块来提升性能,heatmap分支使用联合训练提高精度用的,测试时候不需要,相当于辅助loss。
(1) Keypoint Alignment (KPAlign) Module
看示意图就好理解了:
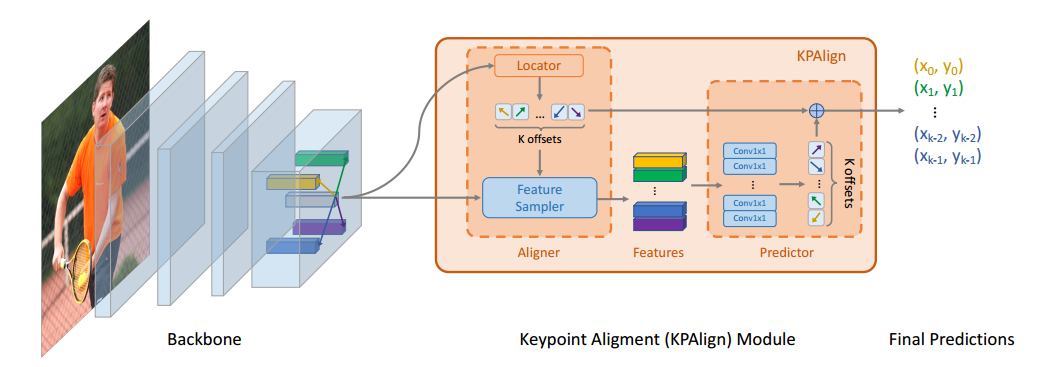
对于某一个点,由于其回归得到offset值,那么最好要提取到对应位置的特征,这就是所谓的特征对齐操作。模块包括两个部分:aligner和 predictor。
aligner输入是F特征图,输出是k个关键点的大概坐标o和相应的特征v
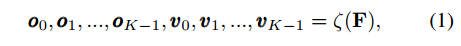
o_i的大小是hxwxkx2,2就是当前点和其余关键点的偏移,v_i大小是hxwxkxc,v_i是通过特征采样器得到的,由于输出有小数,故特征图上面采样也是双线性插值得到的。
把特征提取出来了,在进行predictor进行关键点refine,最终的输出就是两次预测结果相加,相当于refine模块学习的是残差。
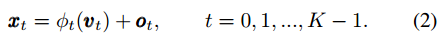
注意虽然上面看起来不一定会按照我们想象中来学习,但是整个过程是无监督的。具体还是需要看代码。
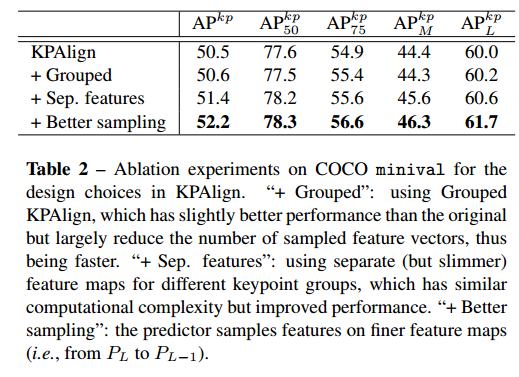
以上就是核心思想,但是作者通过实验进行了一些细节改进。
(1) Grouped KPAlign
由于某几个特征点离得非常近,例如眼睛和鼻子,为了节省资源,可以考虑分组,也就是说不一定输出的o要正好是kx2,而是可以几个合并成一组,输出Gx2,这样性能没有啥影响,节省内存。
(2) Using Separate Convolutional Features
作者做实验发现,如果将输入KPAligner的特征图F也分成G组,效果好很多,作者将256个通道分成4组,每组64个通道。KPAligner的操作也不再是对整个特征图了,而是分组,例如第一组学习出2个值,这样O的输出一共是GX2的值。节省计算量,也提高了精度
(3) Where to Sample Features?
我们前面采样的特征都是在FPN输出的各特征图上面进行,并且aligner和predictor都是在同一个特征图上面操作的,但是作者觉得这是很奇怪的,首先aligner的目的是学习出大概的offset,而preditor的输入时细节特征,其要的特征更加精细。 The locator predicts the initial but imprecise locations for all the keypoints (or keypoint groups) of an instance and thus requires high-level features with a larger receptive field. In contrast, the predictor needs to make precise predictions but only for the keypoints in a local area because the features have been aligned by the aligner.As a result, the predictor prefer high-resolution low-level features with a smaller receptive
field。所以Feature Sampler需要更加低级的特征图。具体来说就是对于第L层特征图,首先Locator定位出大概的offset后,将offset值应用于采样器上面,不再是同一个特征图层,而是更精细的的特征图L-1也就是低一层的特征图,因为其定位能力更强,虽然语义弱一点。如果已经是最低层特征图(特征图最大),则直接采样L层即可。
heatmap分支是作为辅助分支,因为直接回归难度还是有点大,故增加了heatmap,这里把K个关键点当做K个类别分类问题,在关键点附近就是类别,其余是0。Loss采用的ce loss.因为高斯热图回归的方式作者认为会比热图分类难学习,而我们这个分支只是辅助而已,对精度要求很低,故只需要改成分类就可以。

可以看出KPAligner很重要,提升非常多。
提出的三个改进策略都有很大帮助。

热图辅助分支帮助特别大。
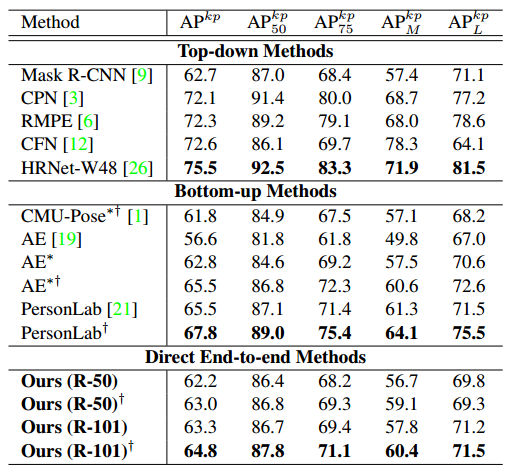
最终性能如上。看起来性能也很一般。虽然出发点是很简单的,但是实现和细节非常多,应该只是过渡算法,期待后续更加精炼网络。其实也一定程度反映出直接回归值得做法难度依然很大,不可取。
一类检测器
在某些场景下或许有用,主要是轻量级模型,速度很快,精度也很高,或许可以替换掉yolo
lffd
仓库:https://github.com/donnyyou/pytorch-lffd
lffd的设计思想:分享一个经验(论文中算出和试出来的)::如果输出层的感受野是100,那么实际上有效感受野大概就是40%~60%左右。故该原则可以用于计算anchor,也适合设计网络(不应该最后一层特征图正好和感受野一样大,应该要乘上1.4~1.6倍才是最佳)。可以基于unet感受野,反推出最合适的输入图片size。
libfacedetection
https://zhuanlan.zhihu.com/p/111325435
目前已经开源了整个训练代码和部署代码,值得学习。
KPNet
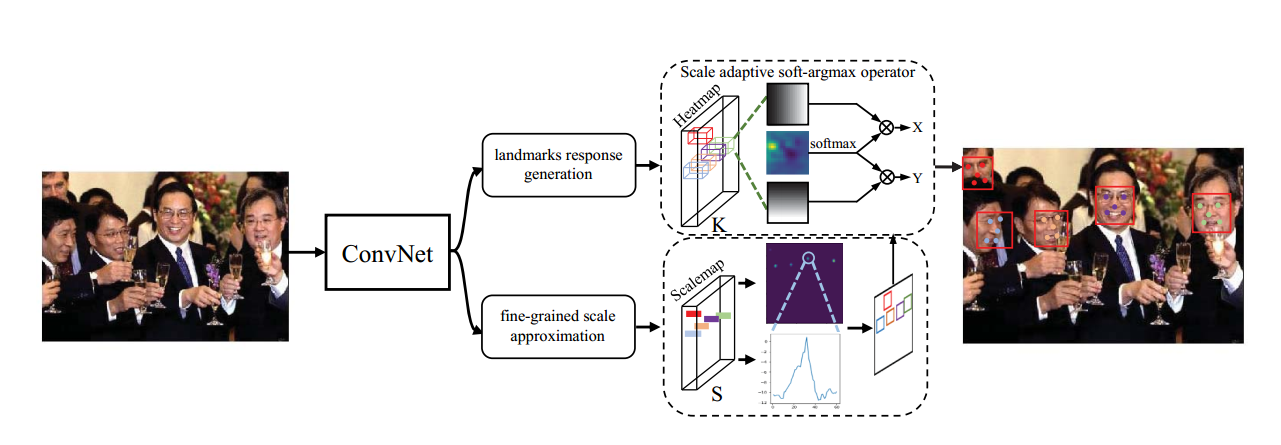
论文名称:KPNet: Towards Minimal Face Detector
地址:https://arxiv.org/abs/2003.07543v1
采用bottom-up方法学习关键点,另一个分支学习目标尺度,两者联合就可以实现目标检测和关键点检测。
上面分支是用于学习5个人脸关键点坐标,采用了soft-argmax操作,使其可以适用低分辨率图输出(其实就是AE论文做法)。下面分支是用于学习目标的大小,注意的是bbox scale的学习不是回归问题,而是分类问题,例如统计下一共有60个尺度,那么输出通道就是60,每个通道学习一个默认尺度,由于上述scale的设置,说明其实学习出来的bbox都是正方形,对于我们的场景不一定适用,思想了解下就行,论文中还有些loss设置规则,可以看看。
