@huanghaian
2020-06-01T08:42:07.000000Z
字数 14399
阅读 6822
unet变种
语义分割
优秀语义分割模型代码:https://github.com/qubvel/segmentation_models.pytorch
loss代码: https://github.com/JunMa11/SegLoss
https://www.zhihu.com/question/272988870/answer/575302856
https://link.zhihu.com/?target=https%3A//github.com/ShawnBIT/UNet-family
Dilated U-net 可以试下,效果应该不差
上采样采用pixshuffle操作,可以试一下,看下是否会更好。
Boundary Loss for Remote Sensing Imagery Semantic Segmentation https://arxiv.org/pdf/1905.07852.pdf
Boundary-aware Context Neural Network for Medical Image Segmentation
看起来将effecib1作为骨架,可以取的非常不错的效果
1 unet
论文地址:U-Net: Convolutional Networks for Biomedical Image Segmentation
结构如下所示:
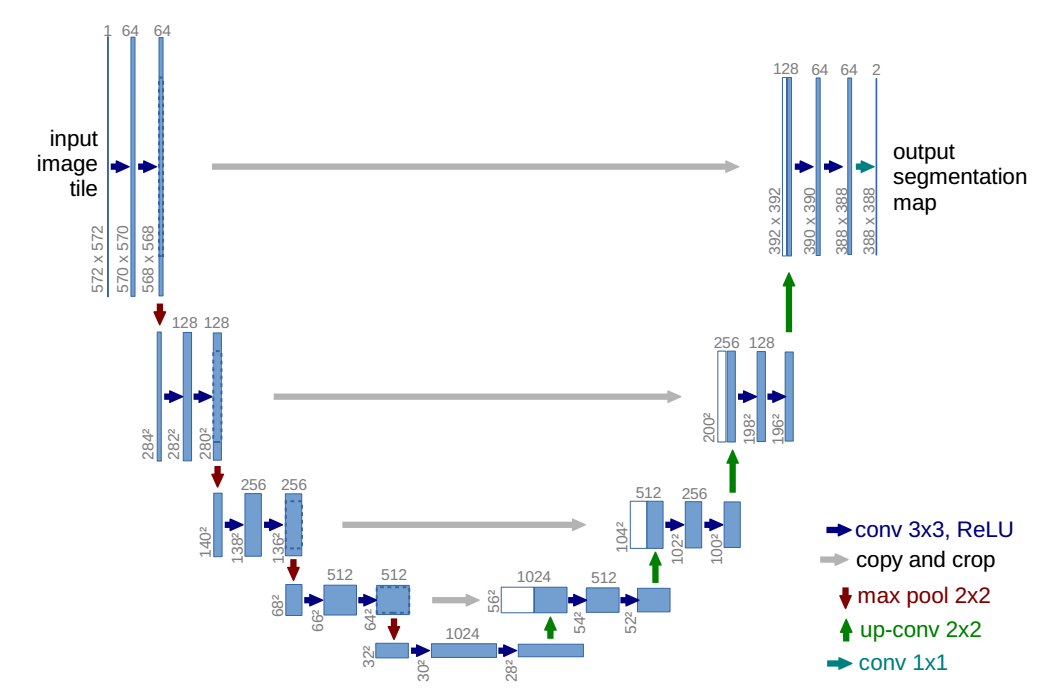
unet最成功的部分或者说性能好的核心是skip connections。如果要改进unet,一个很大的部分就应该是改进跳层连接。
论文一些重要细节:
(1) 医学图像都是大图,无法整图预测,故一般是重叠裁剪小图预测。为了预测图像边界区域的像素点,先对整图采用overlap-tile策略补全缺失的context,然后再采用重叠裁剪patch。
因为边缘位置预测的置信度很低,一般都会导致预测不出来,故采用镜像操作补充上下文,是个常用的策略。对应我们实际应用时候,测试时候是把roi扩大,或者roi外部镜像填充,然后再进行整图或者小图预测。
(2) 由于训练数据太少,采用大量弹性形变的方式增强数据。这可以让模型更好学习形变不变性,这种增强方式对于医学图像来说很重要,因为形变是医学图像主要的一个变化,对于我们的场景不一定需要。
(3) 在细胞分割任务中的另一个挑战是,如何将同类别的相互接触的目标分开。本文提出了使用一种带权重的损失(weighted loss)。在损失函数中,对于相互接触的细胞像素,其边界赋予更大的权重。
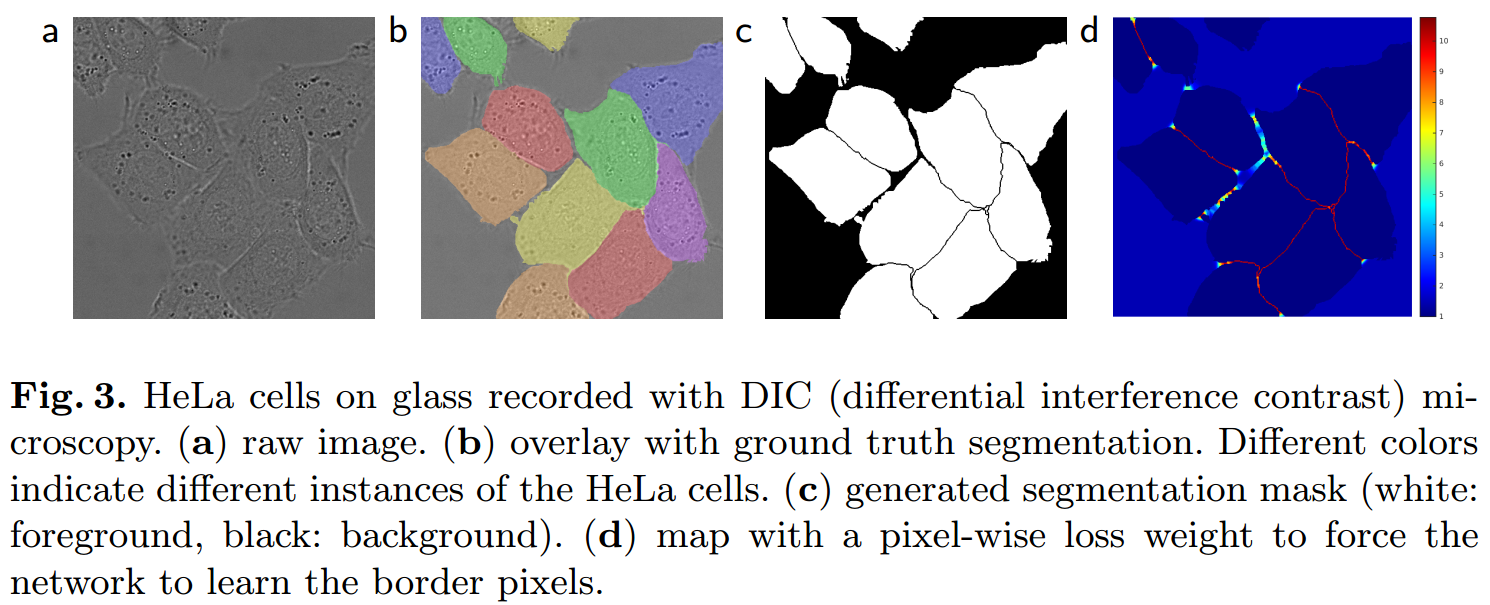
其分割场景和我们实际场景不一样,不清楚边界加权Loss对最终指标有多少影响,但是目前来看没发现有后续论文使用了这种特殊的加权方式,可能作用不大,论文也没有比较加权和不加权性能差异。
需要注意的是原始unet,输入和输出不是一样大,而是输出是输入的一半,目前常用的unet都是输入和输出一样大。
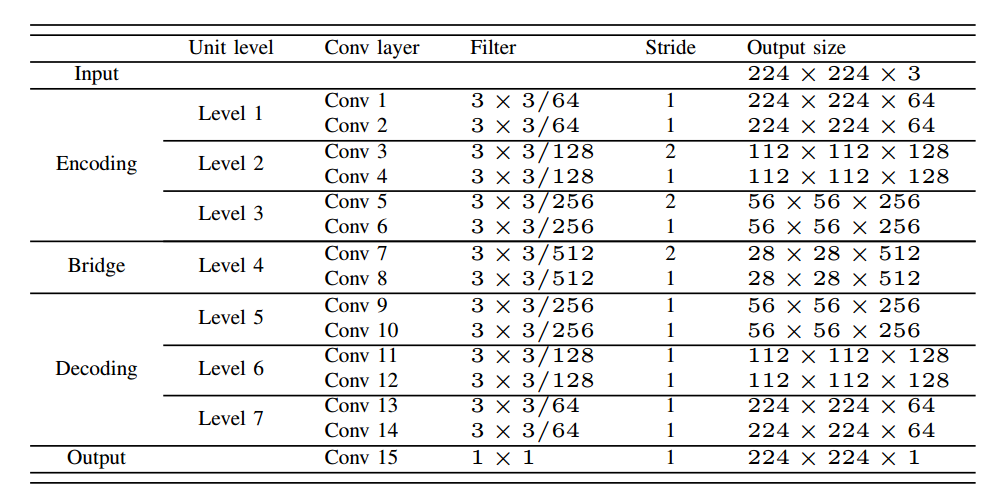
2 Residual U-Net
论文名称:Road Extraction by Deep Residual U-Net
论文地址:https://arxiv.org/abs/1711.10684
本文比较早,主要就是采用残差设计结合unet,并没有采用预训练权重,而是相当于重新设计网络而已。比赛方案,没有啥理论。
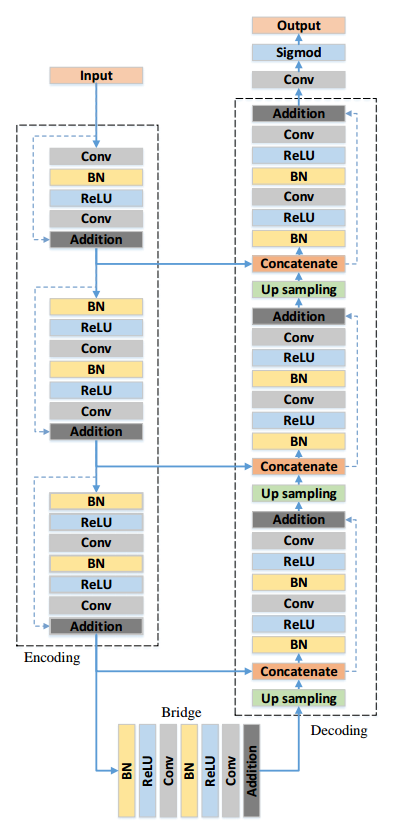
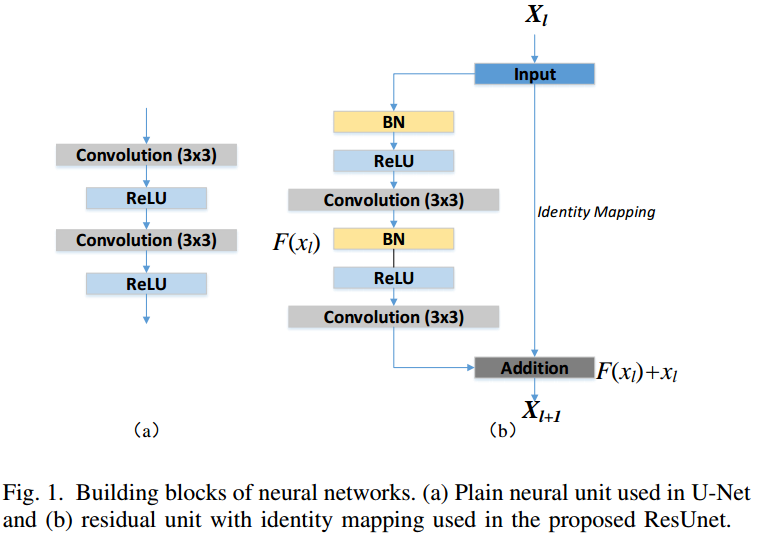
注意作者参考的其实是resnetv2的设计,BN在前。
(1) 使用residual units代替原始的卷积模块
(2) cropping操作不需要
作者特意说了下原始U-net的crop操作是不需要的,没有什么意义。而且相比于原始u-net,本文没有采用pool操作,而是通过stride=2代替(故无法用预训练权重)
(3) loss函数
可以看出,输出通道是1,作者采用的loss函数是MSE(比较神奇的操作),但是作者没有对比MSE和ce哪个效果更好。
(4) 训练细节和结果
训练图片1108张,分辨率是1500x1500,输入图片尺寸是224x224,是随机从原图中裁剪出来的,没有做任何的数据增强,没有预训练权重。
考虑到裁剪的像素边界因为conv操作有zero padding 操作,可能会导致边界像素预测精度下降,故在测试阶段,在滑窗过程中,保证了具备一定的overlap,具体实验是overlap了14pix,对所有patch预测的结果进行重排,重叠地方采用预测均值代替构成整图。
和比赛场景相关,考虑到Label也很难给出准确的标注,故实际评估是是带松弛的precision和 recall,具体就是对于某个像素预测mask,如果在其预测的3个像素范围内有对应label,那么就算预测正确。
3 TernausNet
论文名称:TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation
论文地址:https://arxiv.org/abs/1801.05746
源码地址:https://github.com/ternaus/TernausNet
背景:Kaggle: Carvana Image Masking Challenge
比赛方案,验证了预训练权重的重要性。
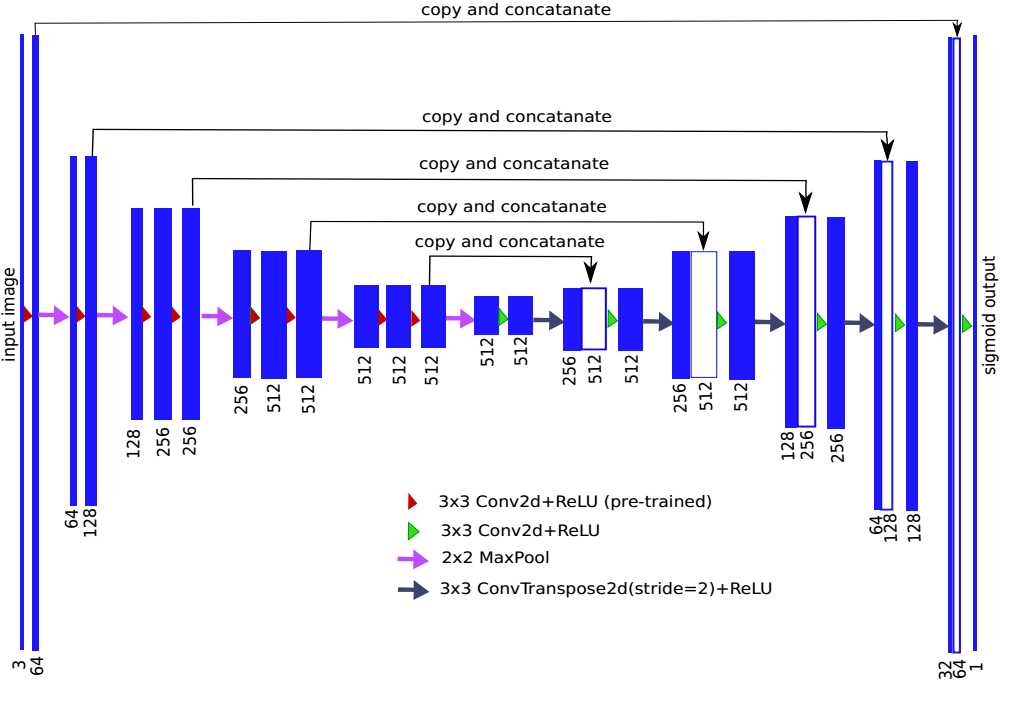
vgg11作为骨架网络。其完整结构为:
作者设计的算法在多个数据集上进行了实验,对于5000x5000大小的图片,训练阶段从原图中随机裁剪出768×768大小的图片,测试时候对原图进行中心裁剪为1440×1440
loss设计为:

可以发现其jaccard loss是带有Log的,用于加速收敛。而且可以看出,感觉加了log的dice loss和bce最匹配,因为bce也是带有log的,这样量级是否就差不多了?优化速度也是差不多?
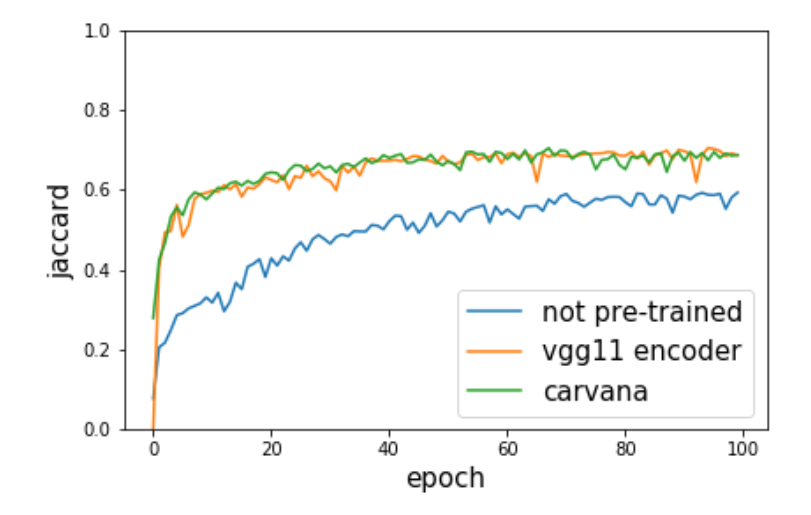
Carvana曲线表示采用Carvana数据在vgg11上面进行预训练。可以发现采用预训练权重精度和收敛速度快了很多。特别适合数据量不大的场合。
4 unet+
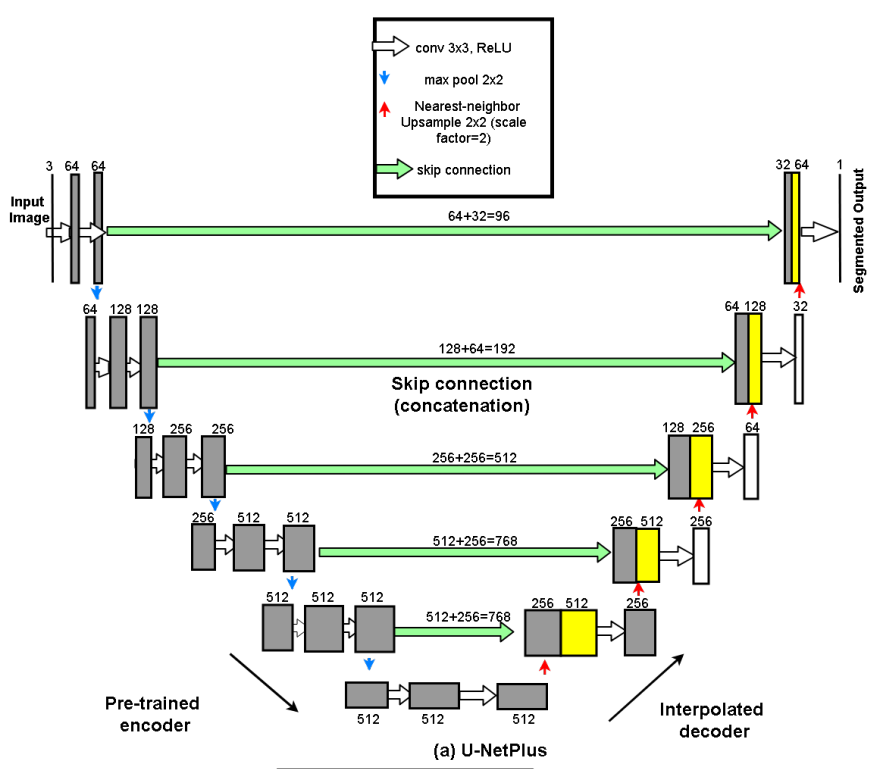
论文名称:U-NetPlus: A Modified Encoder-Decoder U-Net Architecture for Semantic and Instance Segmentation of Surgical Instrument
arxiv: https://arxiv.org/pdf/1902.08994.pdf
可以认为其实是TernausNet算法的改进。主要区别是:
(1) vgg11预训练权重采用的是带BN的
(2) 转置卷积替换为最近邻上采样NN层,在每个卷积层后都加了BN
(3) 采用albu库进行数据增强,速度很快
应用了大量增强 the affine transformation includes scaling, translation, horizontal flip, vertical flip, random brightness and noise addition etc. elastic transformation
loss和TernausNet完全相同。
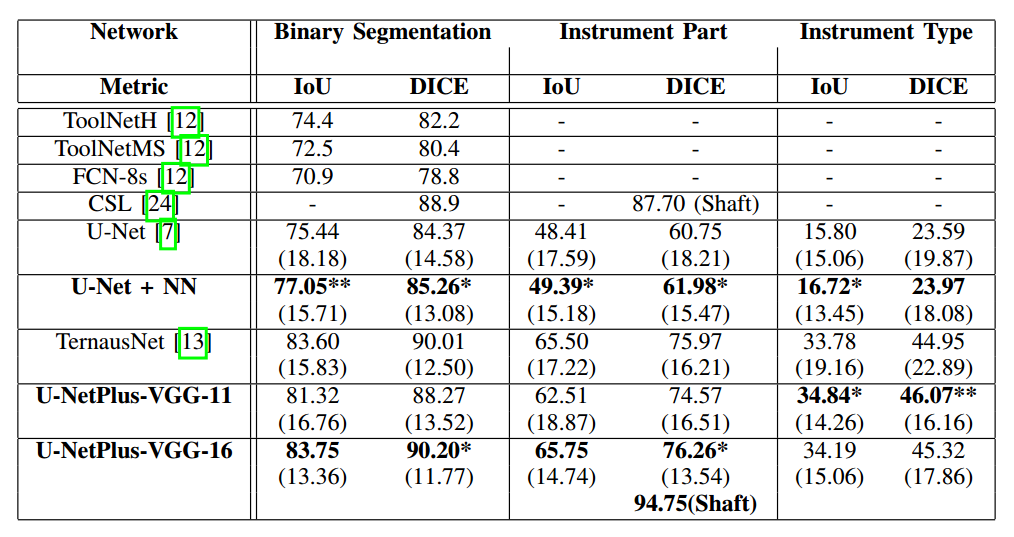
可以发现采用最近邻上采样代替反卷积,效果提升蛮多的,主要是去掉了网格效应。
加入BN后,性能可以超过TernausNet
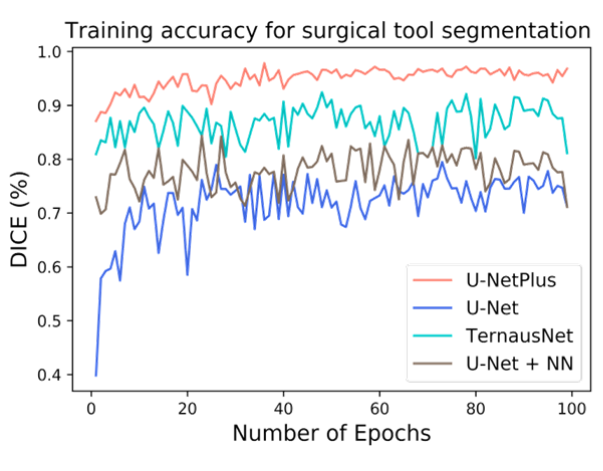
可以发现预训练权重非常有用;BN效果也明显;反卷积替换为NN是个不错的选择。
5 raunet
论文名称:RAUNet: Residual Attention U-Net for Semantic Segmentation of Cataract Surgical Instruments
本文属于小创新:
(1) 使用res unet结构,骨架是res34,但是通过我的经验,resnet抽取哪些层作为编码器输出可能效果不一样。
(2) 应用了残差注意力,不是重点
(3) 对dice loss加log操作,可以加速收敛,当开始预测和gt比较远的时候,梯度会很大。
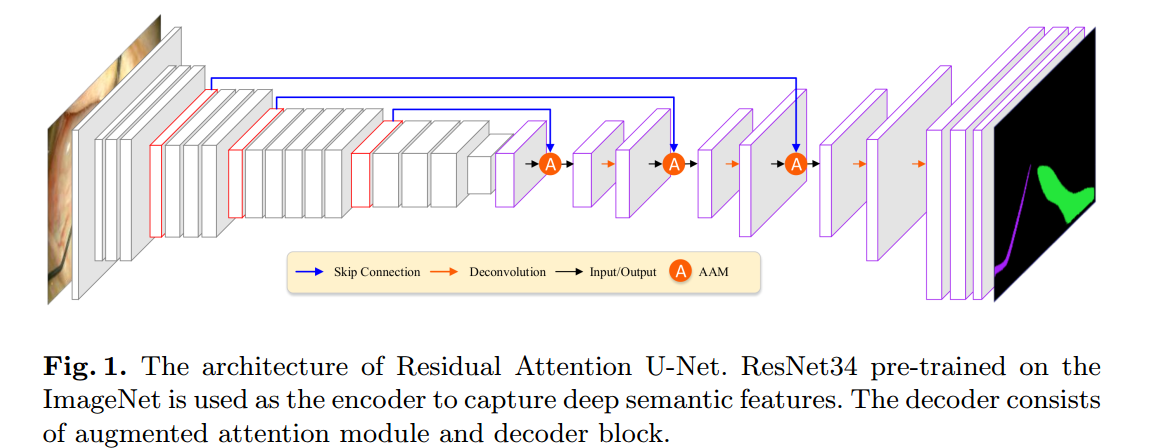
其抽取了resnet的4个输出层作为编码器输出(stride最小为8),为了恢复到原图分辨率,最后接了两个上采样层.我自己实现的res-unet抽取的不是这个,我的最小stride=4
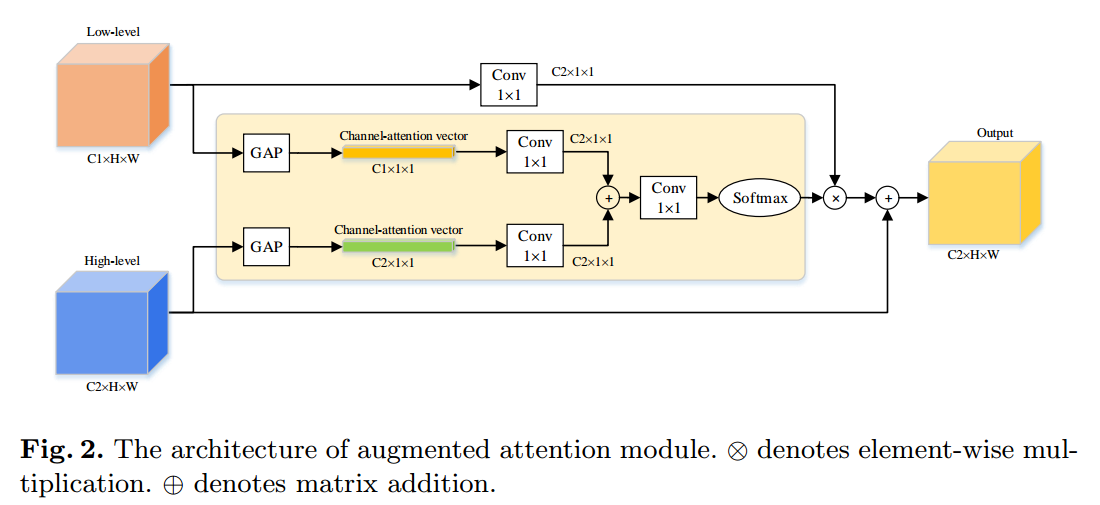
loss设计方面为:

H是二值交叉熵,D是dice系数,
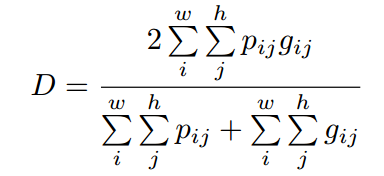
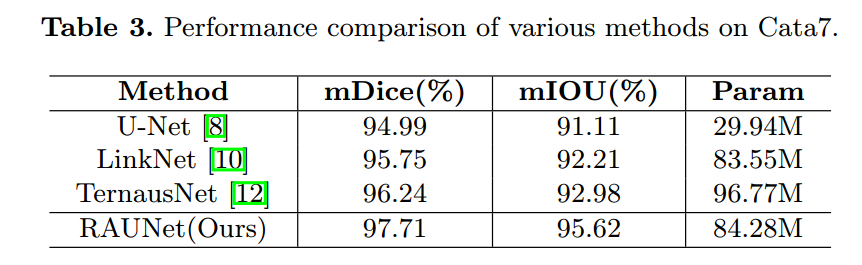
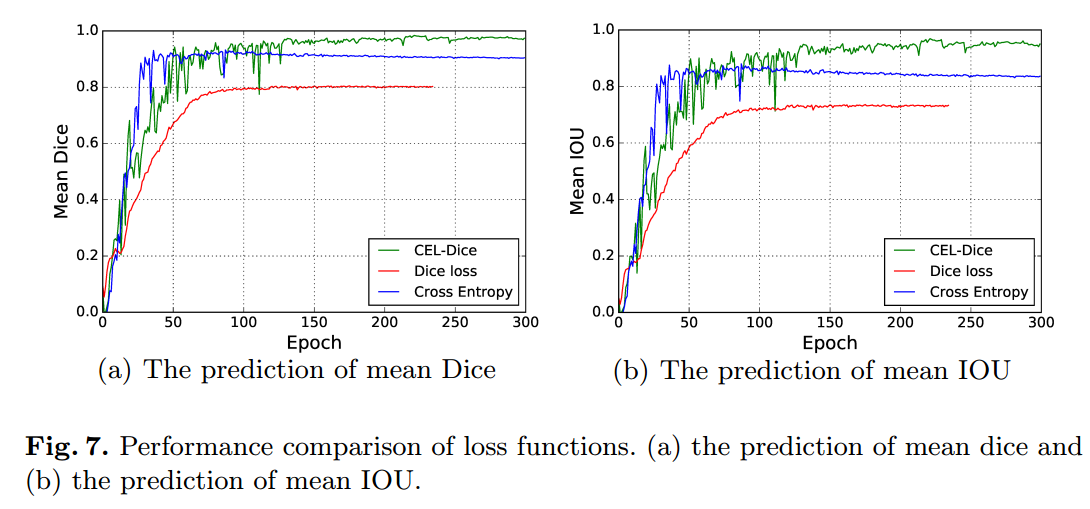
他的实验现象和我们的不太一样,可能和数据有关,明显看出,其bce权重应该加大才会有好效果,仅仅用dice loss,效果是最差的,但是我们自己实验发现仅仅用bce效果是最差的。
6 unet++
论文地址:UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation
arxiv: https://arxiv.org/pdf/1912.05074v2.pdf
github: https://github.com/MrGiovanni/UNetPlusPlus
本文认为u-net存在的缺点是最底层特征和最高层特征直接融合其实存在很大的语义gap。作者的改进吹的很大,一次训练,自动裁剪部署。
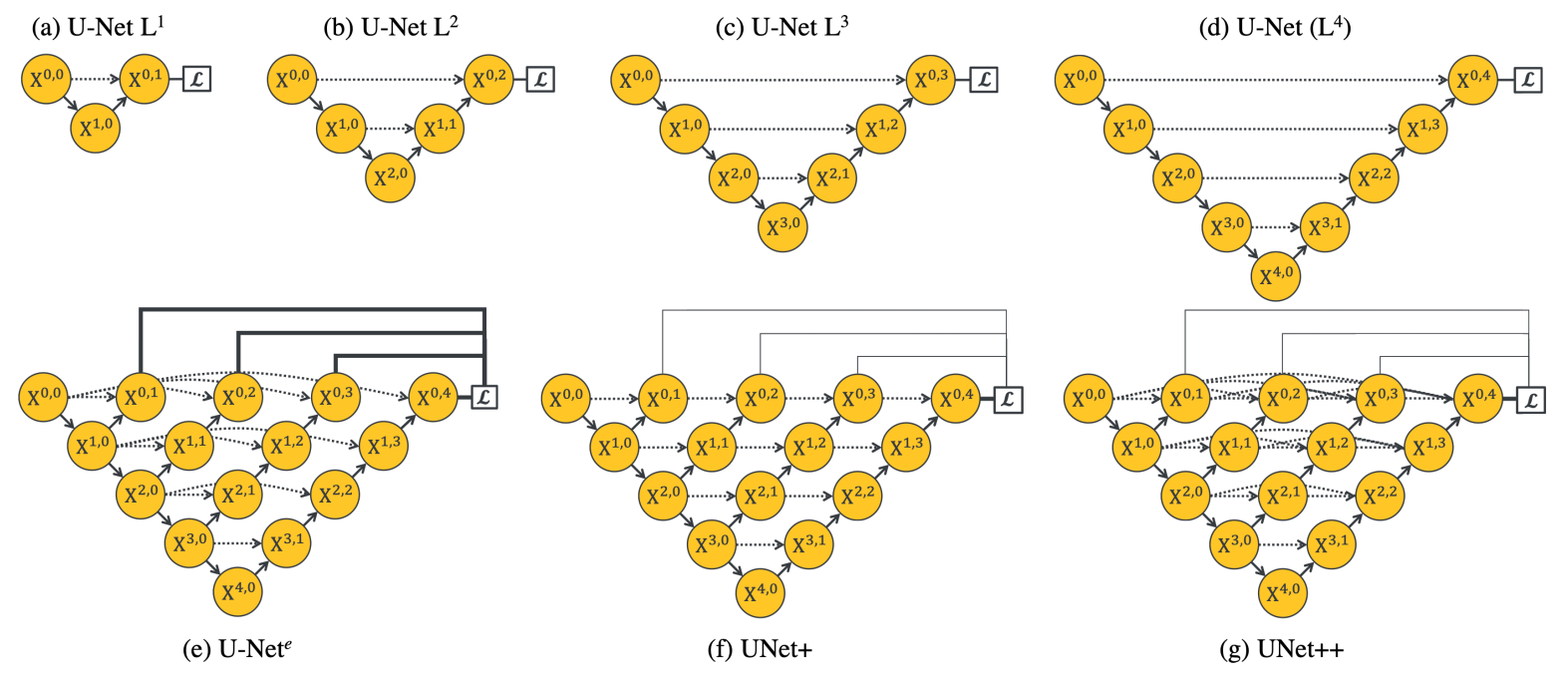
如果不考虑预训练权重,或许可行,但是如果采用了预训练权重encoder,解码器部分过于复杂,参数过多,可能难以发挥预训练权重的作用。而且挑层连接这么多,训练速度也是个问题。后面要实现下才知道。(作者提供的代码是采用了各种预训练权重骨架的,可以执行看看代码,就是感觉加了这么多东西,提升不是很大)
看起来改善也不是很大。
作者采用的loss是:
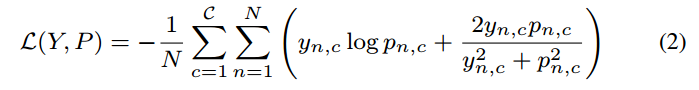
平方形式的dice+bce。N indicates the number of pixels within one batch,也就是常用的实现方式。
各个输出层级融合的语义图,感觉查不了多少。

7 UNet 3+ 重点
论文名称:UNET 3+: A FULL-SCALE CONNECTED UNET FOR MEDICAL IMAGE SEGMENTATION
论文地址:2004.08790
github地址:https://github.com/ZJUGiveLab/UNet-Version
不错的论文
我觉得unet成功的关键就是跳层连接。只要我们对其他网络采用类似的跳层操作,性能也应该不错。基于这一点,我们可以思考原始unet的不足:跳层连接设计的是否完美了?答案肯定是没有的。因为将原始unet替换为带残差的unet,性能有显著提升,说明还可以改进。本文就属于跳层改进不错的地方。
1 网络结构
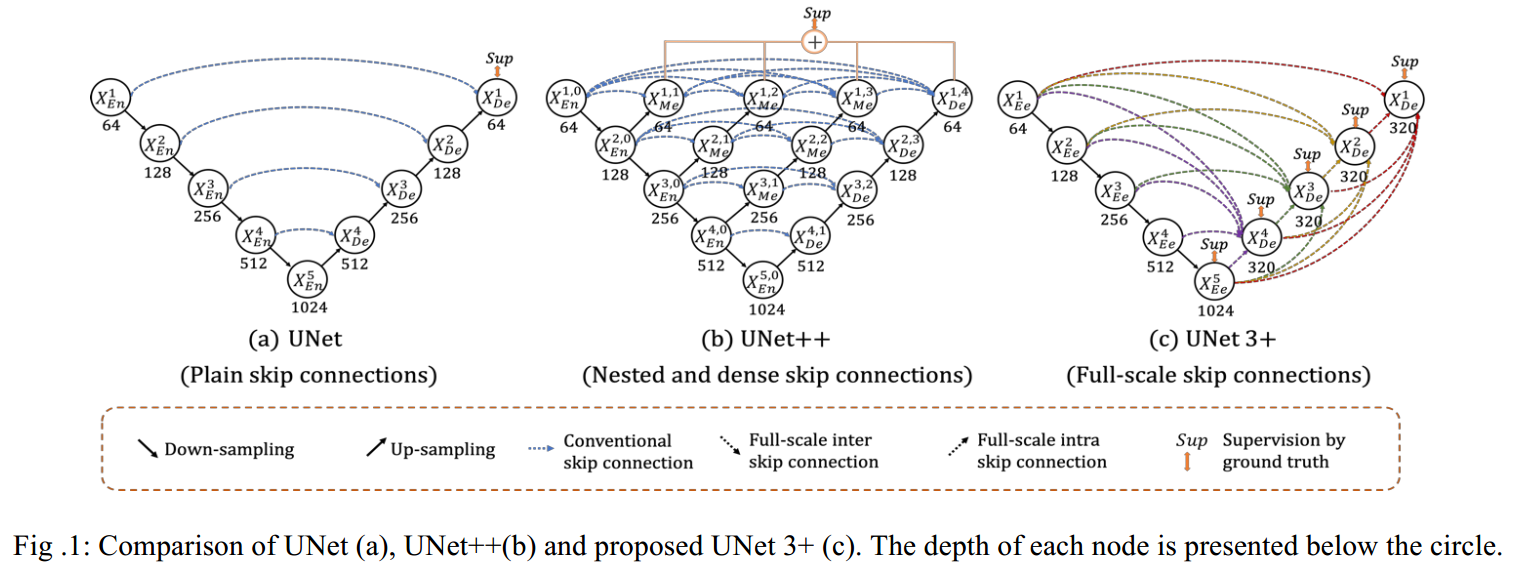
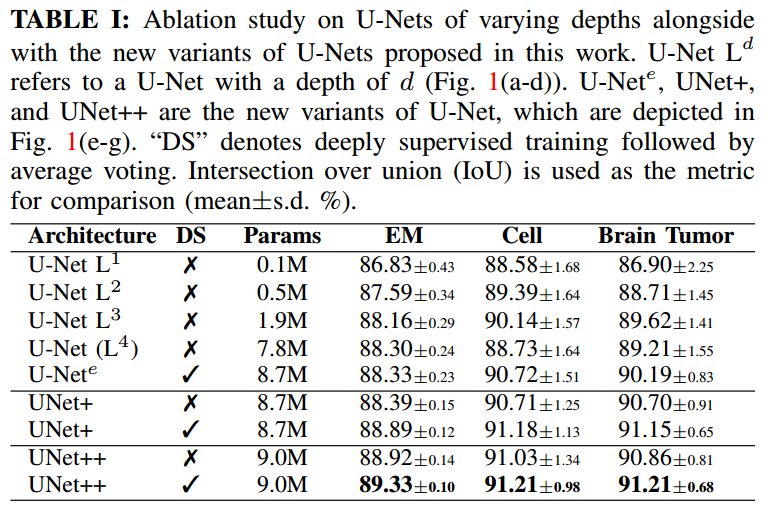
unet++的主要缺点是消耗内存实在是太多了,根本难以训练,如果自己从头训练,我觉得根本不科学,一个小数据集要花费那么多时间训练,明显违背了unet提出的宗旨。
而unet3+仅仅新增了跳层链接,没有增加参数量。我觉得是不错的思想。
以其中一个输出为例,其完整结构如下:
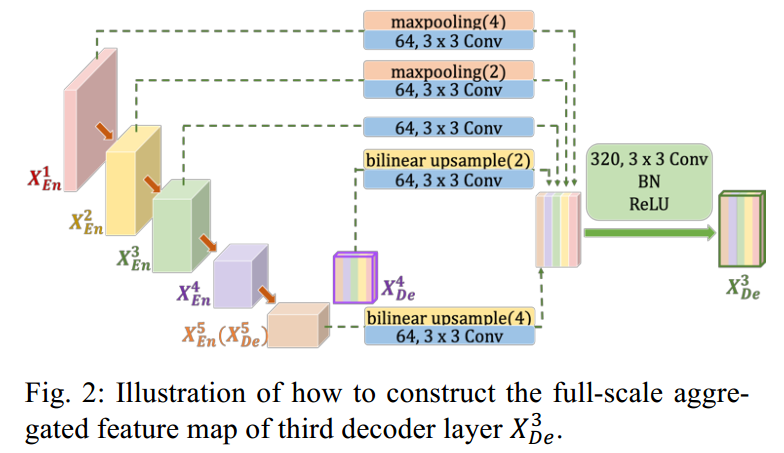
可以借鉴他的思路,但是没必要完全按照他说的做。
2 loss
为了充分利用输出层,作者在每个解码层后面都接了中继监督层。每个输出层都是直接上采样到原图大小,然后统一进行监督。
为了强调边界,突出边界权重,作者引入了多尺度结构化loss:ms-ssim loss,故总的loss包括三个:focal loss、dice Loss和ms-ssim loss,权重设置为1:1:1
看了下作者提供的代码,作者实际上采用的是bce+dice+ms ssim。
3 Classification-guided Module
在实际训练中,会出现大量纯bg图片,即使训练没有,测试也会出现,那么预测时候就不可避免的会出现误报,作者认为极有可能是由于背景中的噪点信息残留在较浅的层中,导致了过度分割现象。故作者采用了多增加一个二分类分支,用于判断是否是纯bg图片:
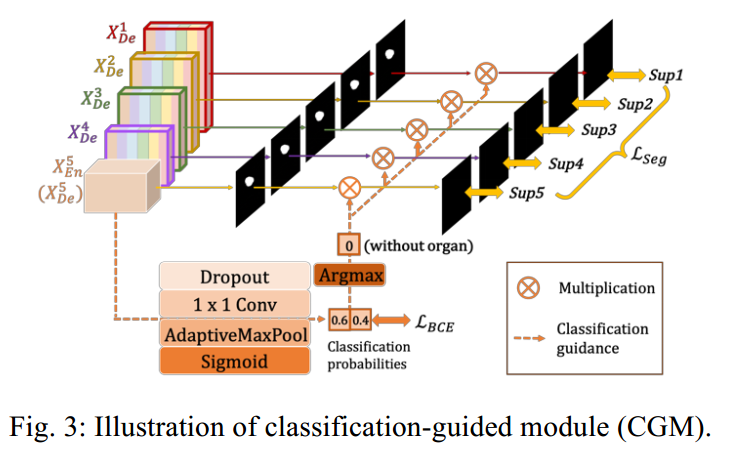
作者这块思想看起来不错,但是代码和实现感觉有问题。首先作者提供的代码不对,可能后面会改掉。bce loss这快没有大问题,一个就是二分类为啥用sigmod,明显softmax收敛更快。还是居然是argmax操作直接乘上seg分支,如果这样,那么bg图片相当于仅仅是前向而已,梯度根本不算。
看起来好像很奇怪,但是后来想想没问题,因为在训练过程中我仅仅只计算不是全黑的图片,并且我相信分类分支可以学的很好,那么在实际应用中,如果分类认为是纯bg,那么语义分割分支就全黑了,不会出现误报。
感觉这是一个去除误报的好办法。
多个输出尺度监督的权重,作者没有说,但是应该全是1,后续等代码完成了再看下。
4 结果

2 u2net
论文名称:U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection
论文地址:2005.09007
github:https://github.com/NathanUA/U-2-Net
本文感觉开销会很大,但是作者说不会,要自己实验才知道。有点点东西吧。
和 BASNet(就是我们一直再用的unet-refine)是同一个作者,代码的star非常多,应该是牛人。
本文的优点是:
(1) 可以捕获丰富的上下文信息,因为多尺度用的非常多
(2) 由于各种pool操作,导致看起来很复杂,其实计算量非常小
(3) 不需要预训练权重就可以达到非常好效果。但是我觉得这个比较扯,训练时间变长那么多,和有预训练训练时间短的比,不合理。而且既然有预训练权重,多好用啊(作者还是那一套:预训练权重是为分类设计的,并且不好改网络结构)
作者通过缩减通道数,提供了大和小两种模型。
本文主要用两个疑问进行入手:
1. can we design a new network for SOD, that allows training from scratch and achieves comparable or better performance than those based on existing pre-trained backbones?
2. can we go deeper while maintaining high resolution feature maps, at a low memory and computation cost?
作者的设计思路其实是沿用了BASNet的堆叠多个unet思想,进行改进的。
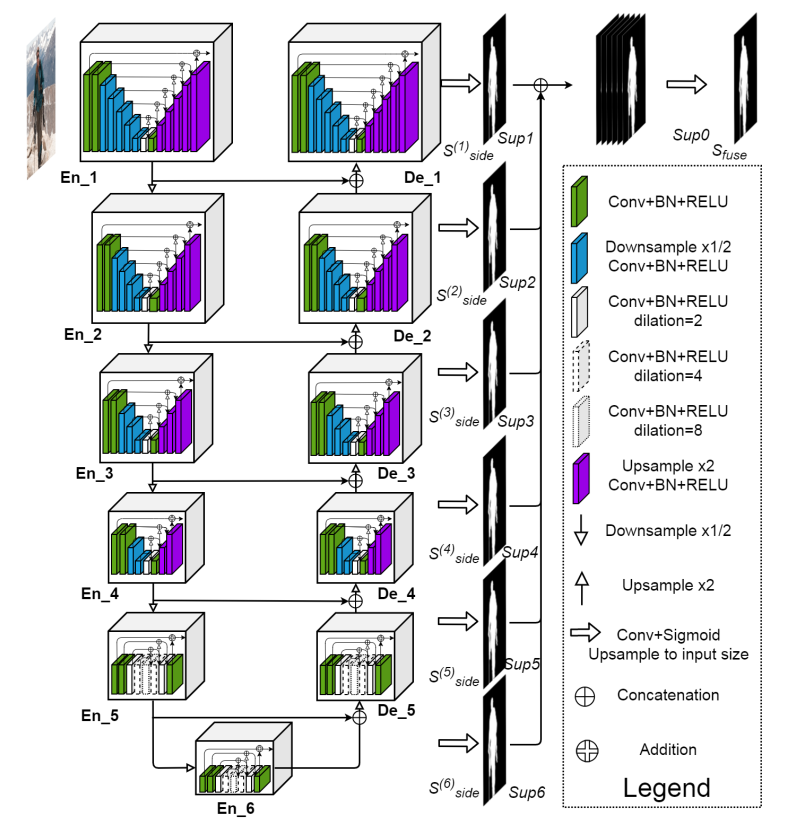
可以发现,作者将unet再嵌入了多个小的unet,所以叫做u2net。
一个亮点是:作者还多了一层fuse预测,最终的使用是fuse层输出。是一个不错的做法,应该对融合有帮助。最科学做法应该是自适应加权融合。后面可以改进。
每个尺度的输出都是上采样到一样大,然后多尺度监督的。
对于每个block,其结构为:
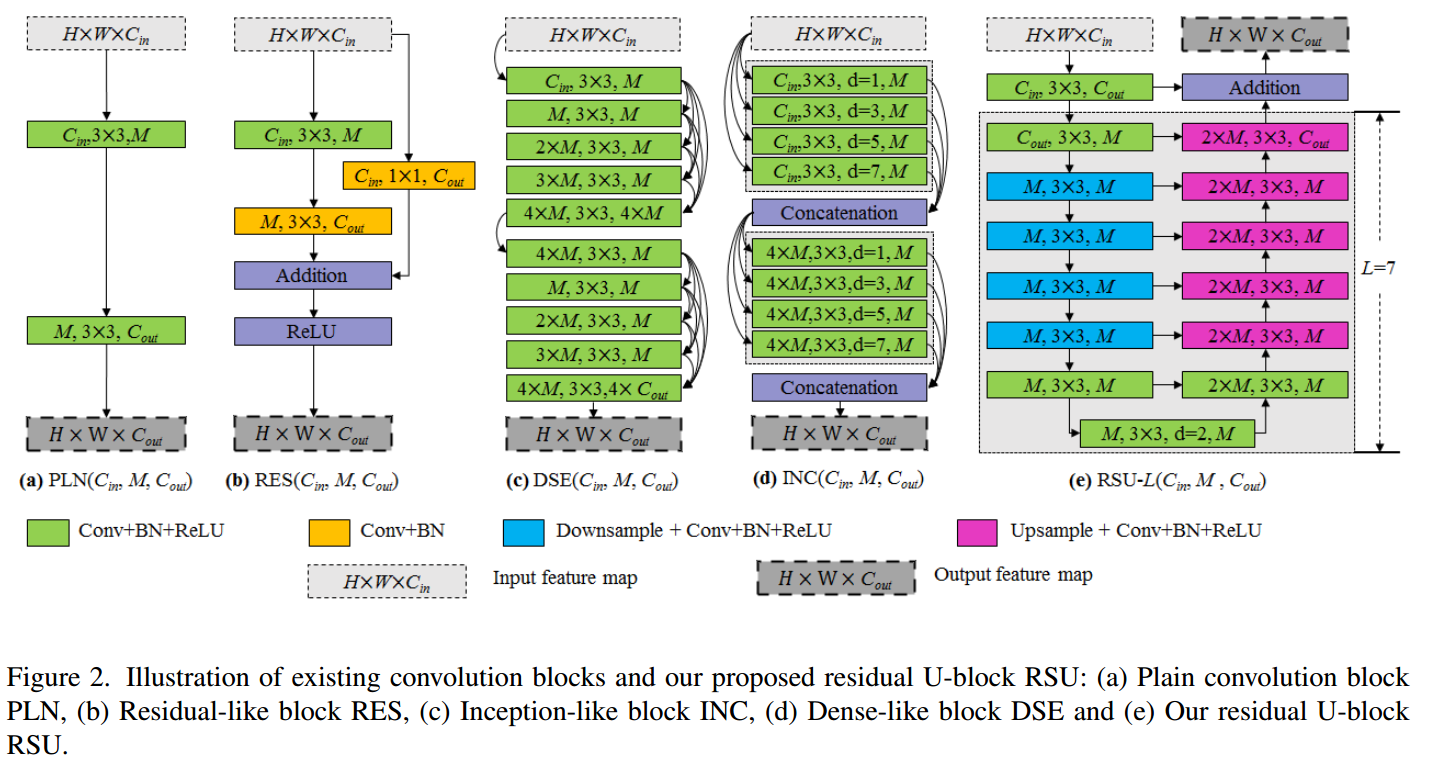
最右边是作者设计的模块。
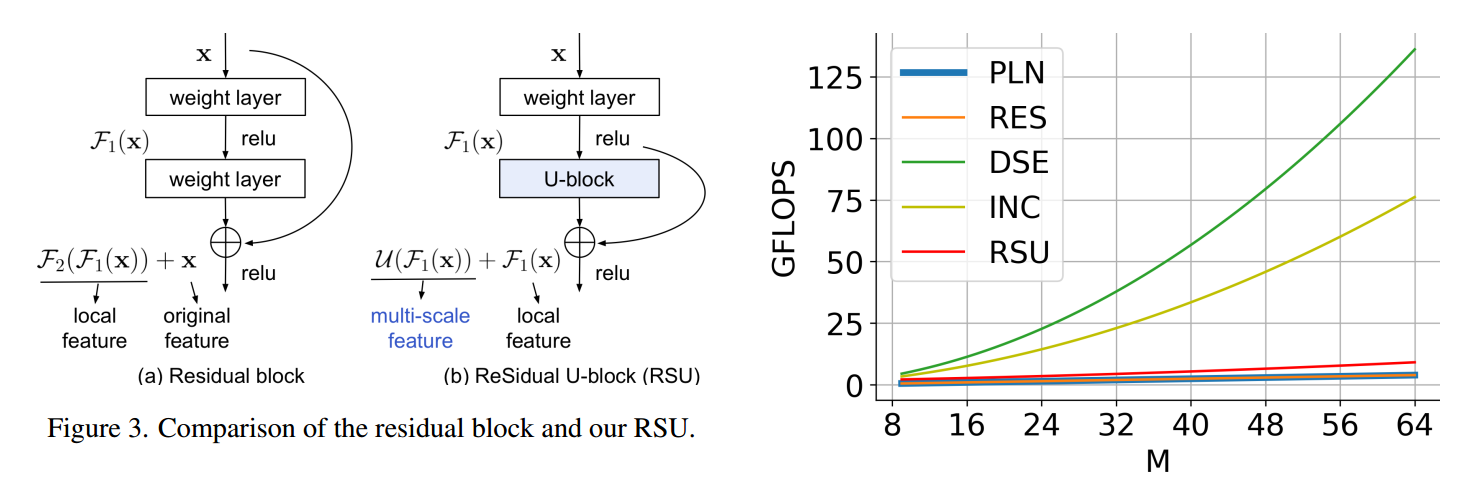
可以看出,作者的设计思路和res一样,并且计算量非常小。
作者采用的loss是bce,所有权重都是1。
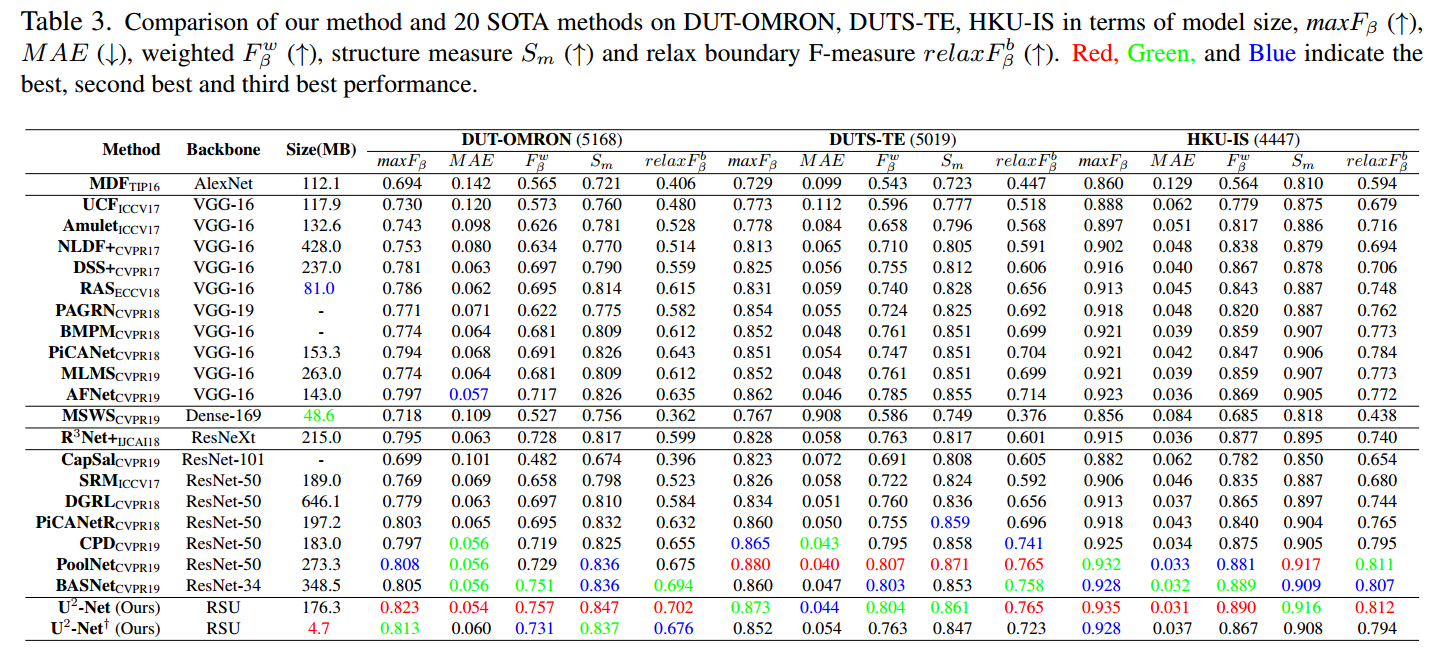
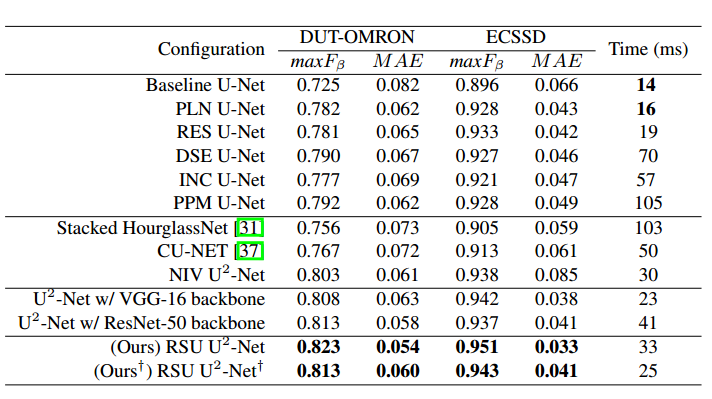
+号表示小模型。看起来效果蛮好,实际上难说。作者达到上述效果是训练了很久的,the training loss converges and the whole training process takes about 120 hours(GTX 1080ti GPU)。
3 SA-UNet
论文名称:SA-UNet: Spatial Attention U-Net for Retinal Vessel Segmentation
论文地址:2004.03696
纯粹是为了水文,空间注意力发了一篇,通道注意力(Channel Attention Residual U-Net for Retinal Vessel Segmentation)又发了一篇,人才啊。
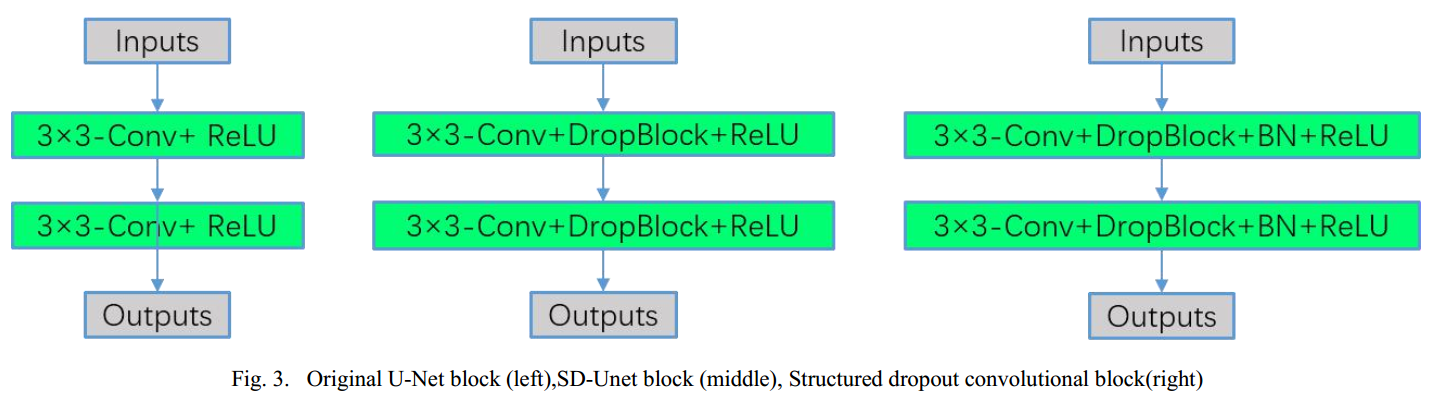
比较垃圾的论文。基于sd-net改进,主要改进就是引入了sam注意力而已,看看就行,不知道是否有效。
唯一能看的就是引入了dropblock来克服过拟合问题,加到conv后面比较科学,kernel size=7。
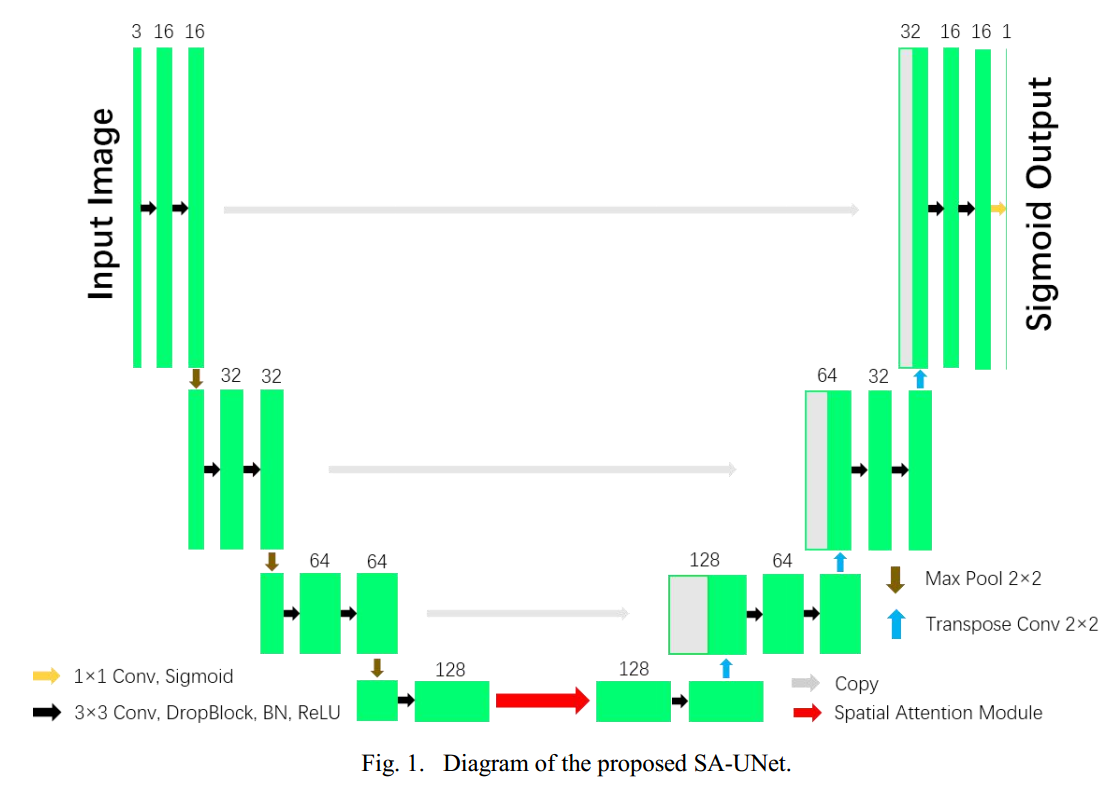
和sd-unet的区别是dropblock后面接了bn,加速收敛。
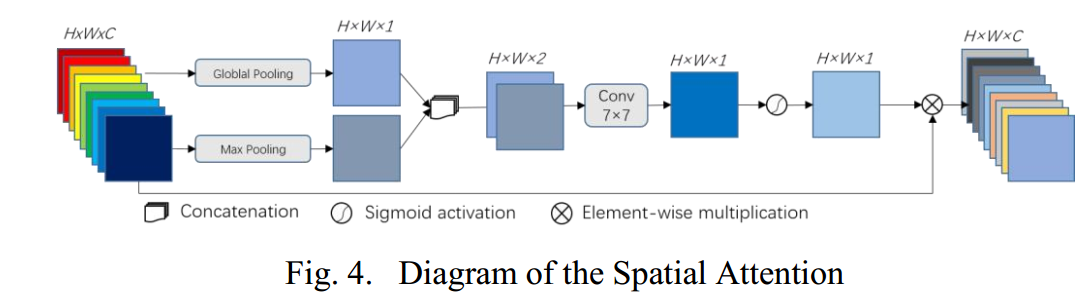
sam仅仅再加最后一个编码层的原因,作者认为该层特征图过小,可能丢失很多细节,语义有待加强
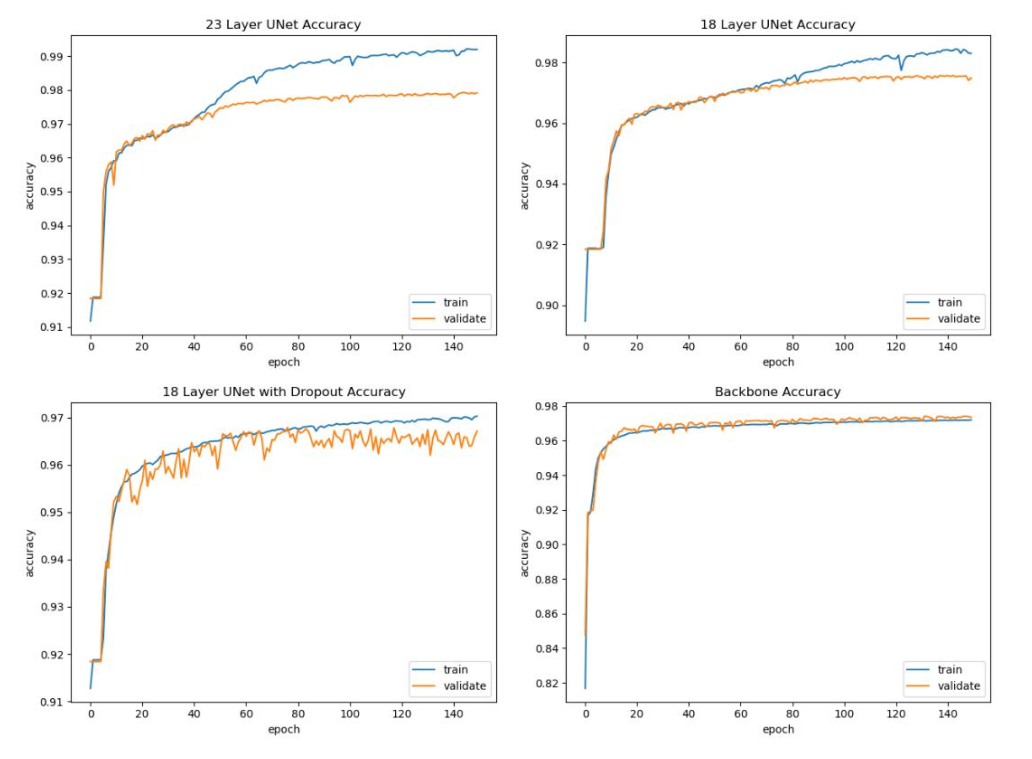
上图可以发现过拟合现象存在,使用dropblock后得到缓解,但是感觉验证集的精度下降了?
backbone是指的sd-unet+bn的网络。而本文的sa-unet其实就是backbone+sam而已。
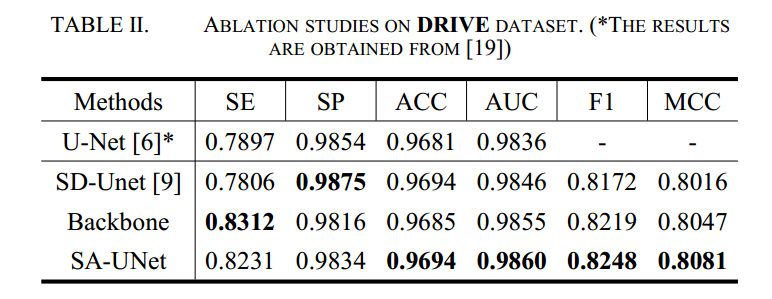
性能看起来没有啥特别大提升。不过可以看出加了BN后加速收敛了,而SAM模块的作用比较弱。
5 ResUNet-a 重点
论文名称:ResUNet-a: a deep learning framework for semantic segmentation of remotely sensed data
论文地址:1904.00592
github: https://github.com/feevos/resuneta
本文属于重点论文。其主要包括:
(1) 实验分析了各种dice loss梯度差异,比较厉害,分析了很多问题
(2) 各种res结构分析和网络分析
(3) path图如何生成,大图如何推理比较科学等问题,实验分析非常充分
1 dice loss梯度分析
无数实验已经表明dice loss可以克服正负样本不平衡问题(因为其主要梯度是仅仅计算正样本区域,背景区域梯度非常小),从而忽略正负样本比例不平衡问题,一般都可以取得比ce效果好很多的性能。
但是dice有很多中变体,到底哪一种更好?本文试图分析这个问题:
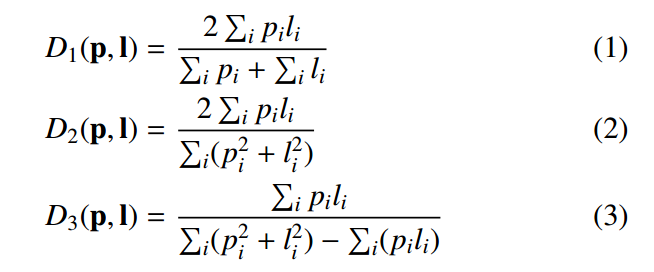
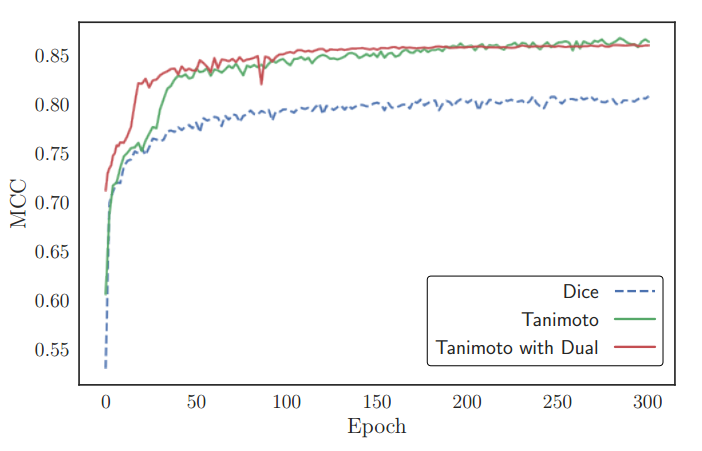
dice 系数主要有上面三种形式。作者指出上面三种在dice 系数计算数值上几乎是一致的,差距不大,但是其梯度性质差异较大,会导致最终性能不一样。
首先明确定义称Tanimoto为D3,简化采用T代表。首先作者经验指出带平方的dice形式(也就是d2,d3)会优于d1,按照我的理论和仿真分析,可以发现d1在target=1,预测为1的时候,梯度不是0,而是0.5,这是不科学的。但是如果采用d2,此时梯度就是0了,形式上更加科学(但是我跑的对比实验发现,d2效果远远差于d1,比较奇怪,难道是梯度太小了额,需要增加权重?还需要仔细分析)。
接着作者先提出了一种对偶形式的T loss,形式为:
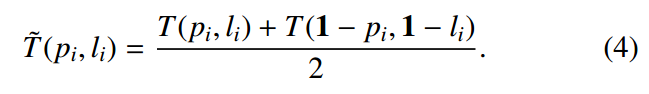
其实就是前景和背景分开算,都要算梯度,而原来的形式仅仅算正样本的(但是这样做正负样本不平衡问题到底会不会又会出现?还需要实验验证)。
为此作者做了仿真实验,设计了6个Loss,采用2d真实向量(1,0)来代表真实值,预测值p=(px,py)随机生成用于模拟网络随机初始化,导致输出任意值的场景,绘制梯度场(一阶导数)和拉普拉斯场(二阶导数)
6个loss分别是:
1 the Dice coefficient, D1
2 the Dice coefficient with its complement
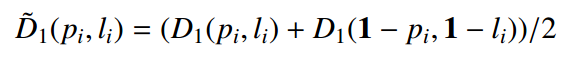

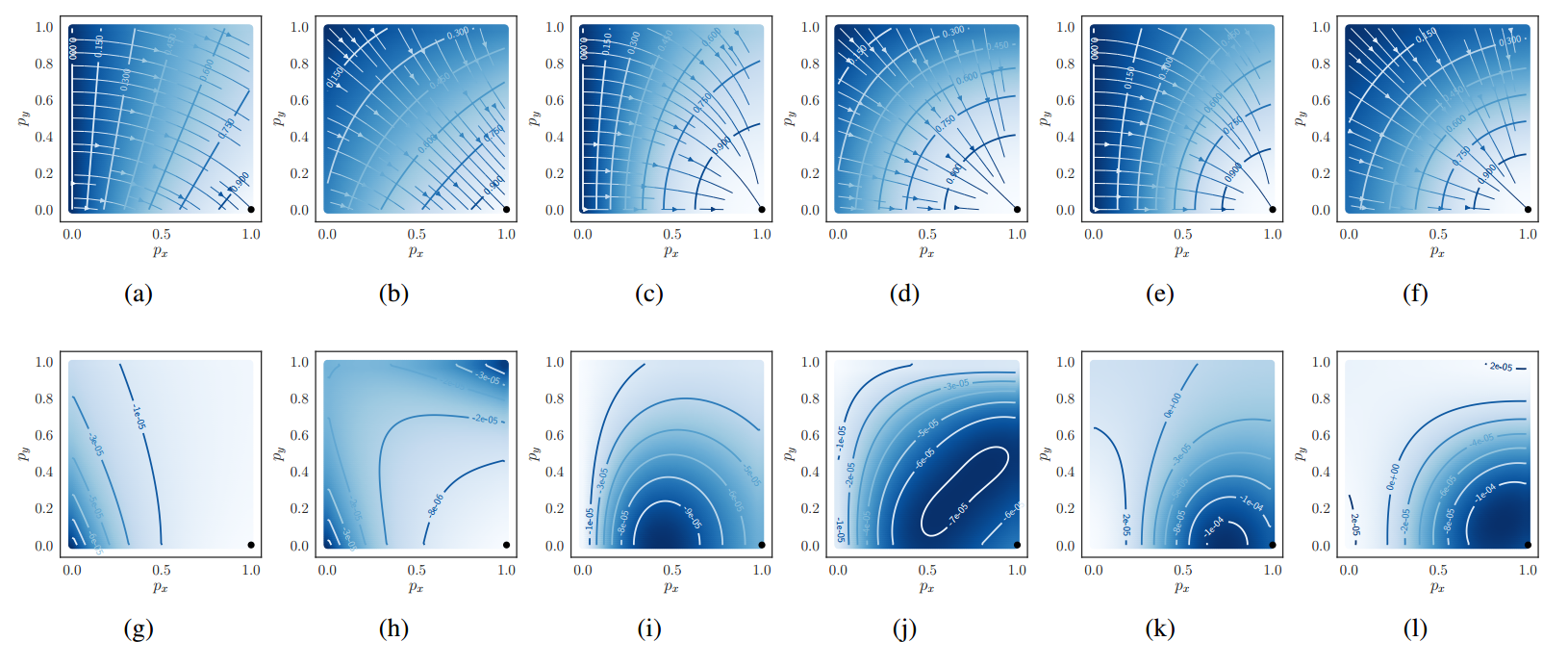
第一行6个是6个loss的梯度场,第二行是6个loss的拉普拉斯场。
放大图如下:
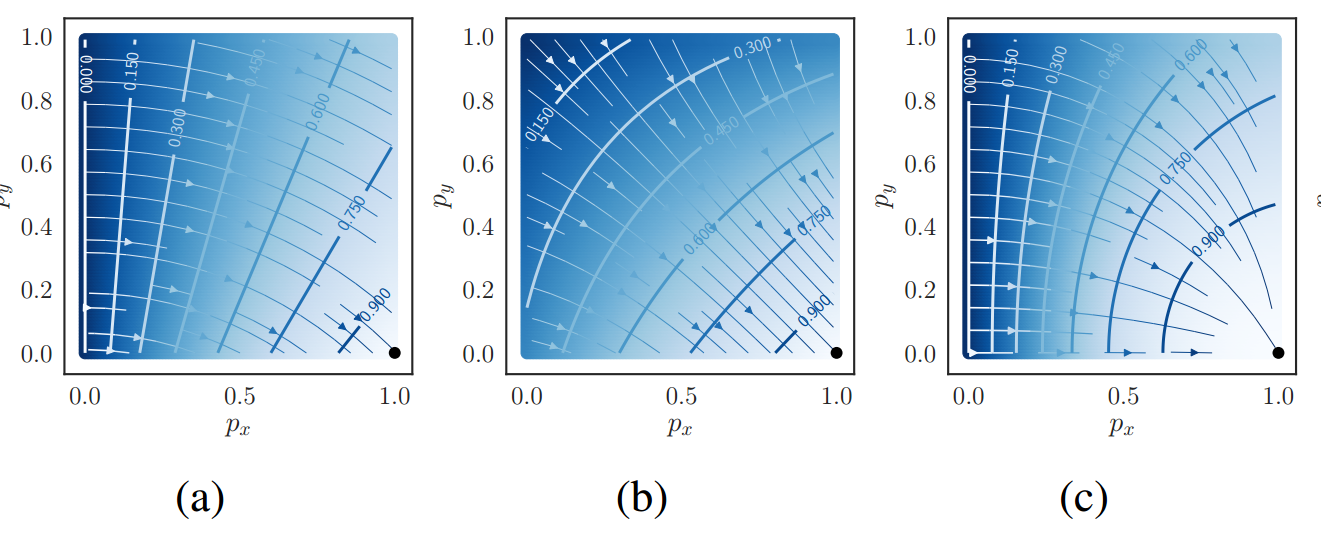
首先等高线0.0-0.9是指的dice系数值,黑色点是label位置,预测越靠近label,dice系数越大。箭头表示梯度优化方向。对于d1来说,可以明显看出,不管预测初始点在哪里,梯度方向都是正确的,但是有很多位置预测点不能正确收敛到label位置处,原因就是当target=1,预测为1的时候梯度不是0,而是0.5,导致出现很奇怪现象。并且可以看出梯度优化曲线很曲泽,走了弧线,导致收敛速度很慢。
对于复合d1,其优化曲线是直线,明显收敛速度更快。但是依然无法解决上述问题。
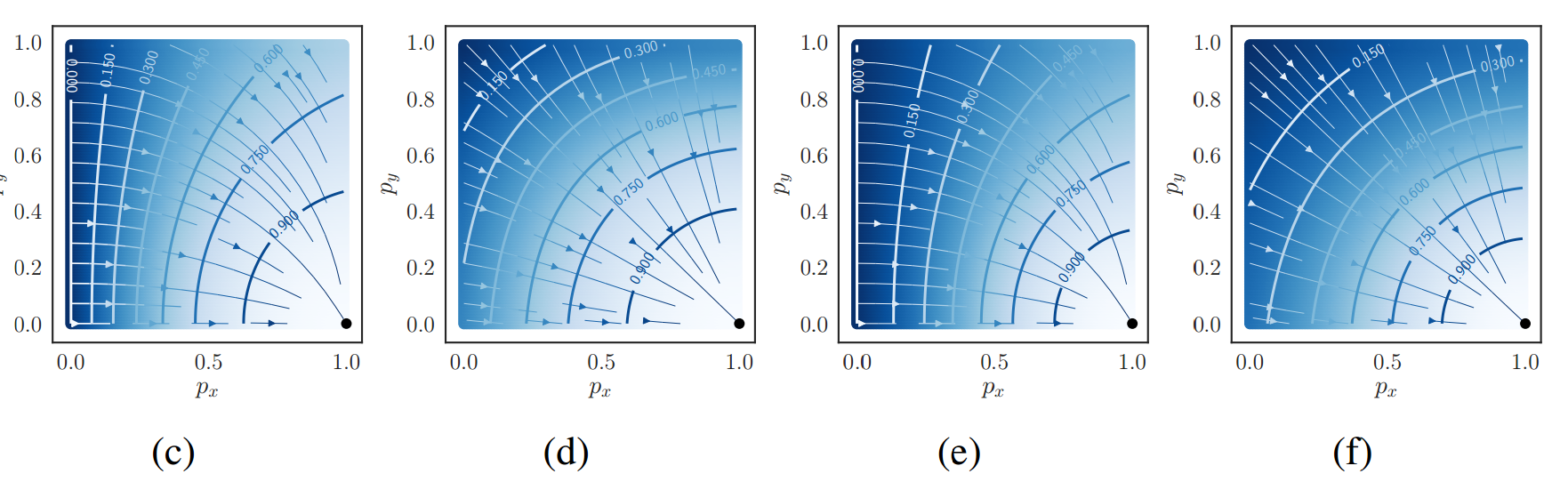
对于带平方的dice来说,就不会出现上述问题了。而且加了复合模式后,收敛曲线都是直线了。看起来d2和d3差不多,此时就需要看拉普拉斯场了:
可以发现d3的形式在靠近label处,其值最接近0(更靠近极值),说明更加靠近真实值,理论上效果更好,不是很理解。
一阶导数的极值位置,二阶导数为0。越靠近0越好。看等高线,j的0等高线都没有出现,而l的0等高线是出现了,说明其越靠近极值点,优化效果更好。
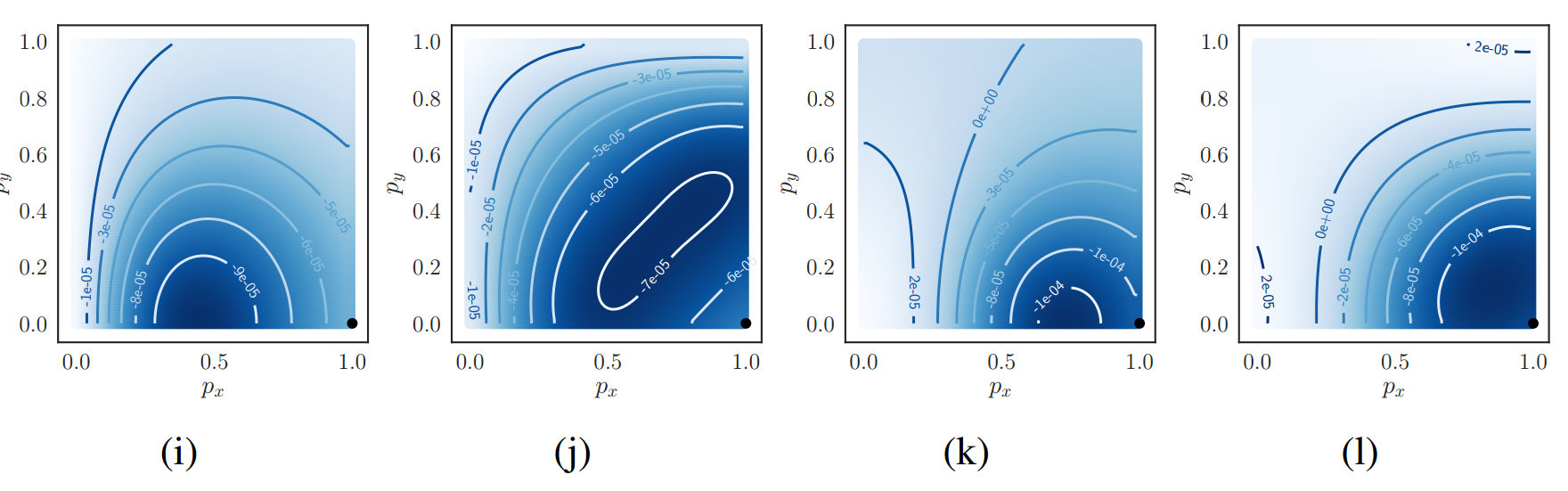
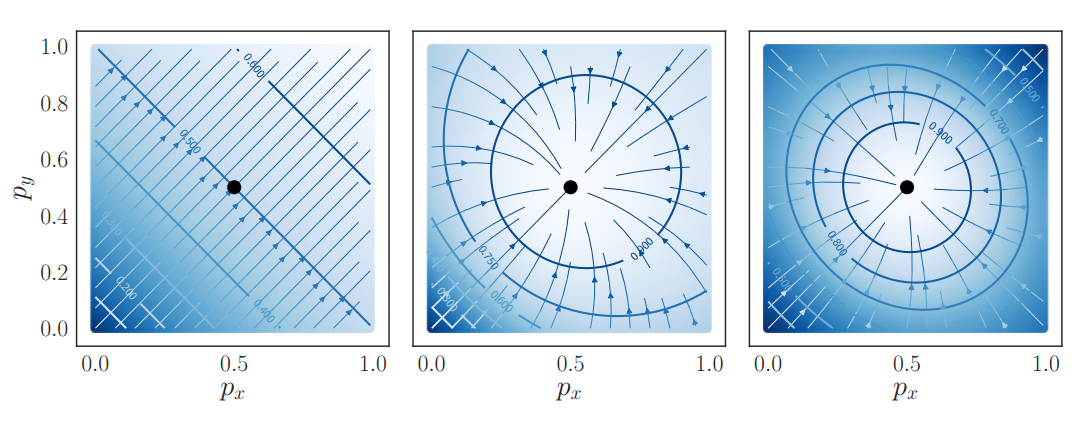
将label坐标放置在不同的位置,用于模拟回归问题,而不仅仅是分割问题,也可以得出类似的结论:
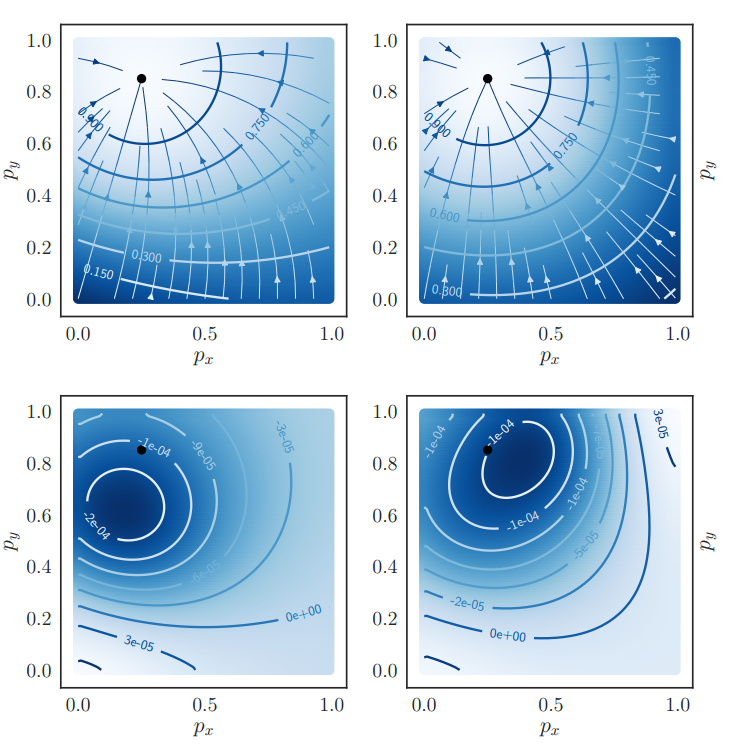
左边是T,右边是复合形式的T
分别是d1,d2,d3的梯度场。
综上所述,不管是分割还是回归问题,T的复合形式是最优的。
看起来复合形式没有并T好多少。
总之,T的复合形式最好,推荐使用。
2 网络结构设计
网络上面主要是(1) 将原始unet改成残差模式,加速收敛;(2) 引入并行空洞卷积层来捕获多尺度特征;(3) 为了扩大感受野,引入了pspool层;(4) 引入了多任务,分别是语义分割、边界图分割、距离图回归和hsv空间颜色图回归
网络全称为ResUNet-a(a应该是空洞卷积的简写),并分为ResUNet-a d6和ResUNet-a d7,d7网络更深一些。为了公平,作者设计了三种类型输出:单任务语义分割输出;多任务输出,条件多任务输出,其差别可以看网络输出结构图。
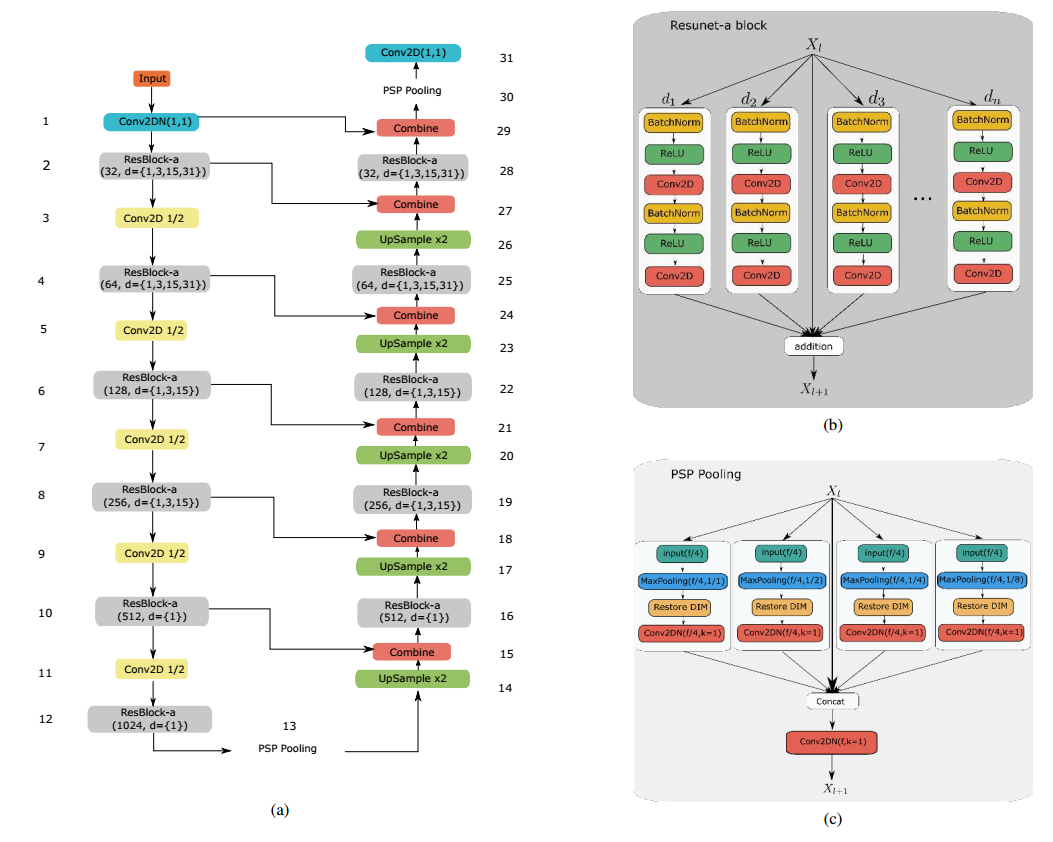
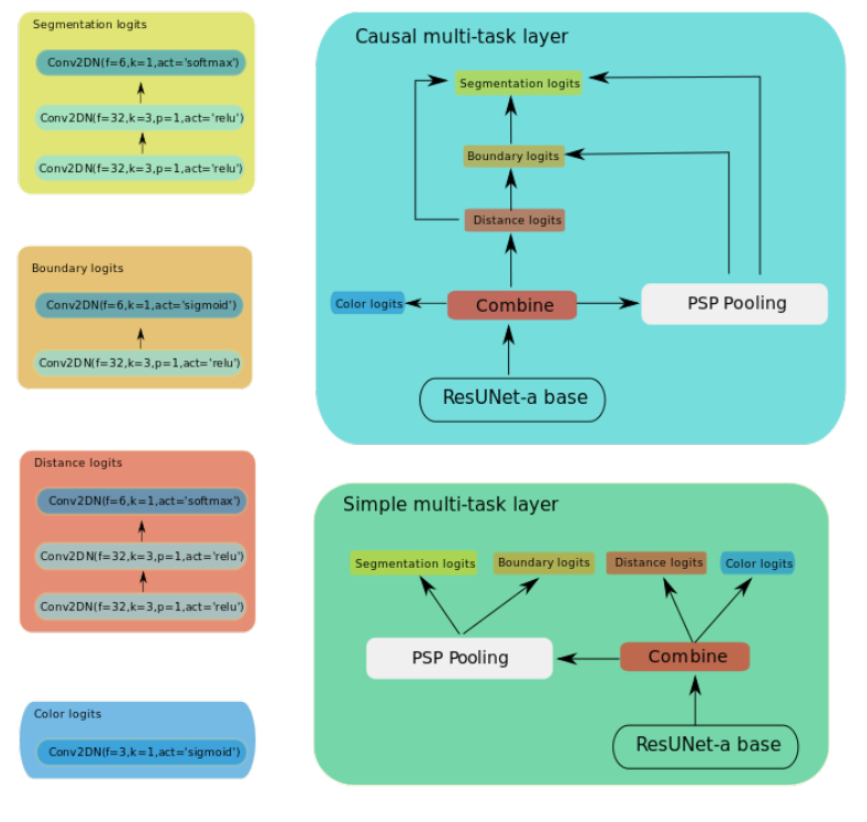
注意由于psp pool操作的特点,所以距离图回归和hsv颜色空间回归这两个任务没有经过psp pool层。
对于每个结构论文中都给出了详细说明。关于为啥要引入4个任务,作者在论文中也有写到。
3 Data augmentation和处理
作者采用了大量几何增强设计,模拟多尺度问题。需要注意的是对于增强出界的图片区域,作者建议采用reflect padding,并且还增加了x,y方向的随机reflect操作来作为数据增加。
训练数据的构造,也包括两个FoV×4和FoV×1,4是指对整图先进行2倍下采样,然后再进行裁剪,目的是使得每个patch包含更加多的上下文。1就是正常裁剪。
FOv4主要目的是探索上下文对训练的重要性。考虑缺陷检测项目,主要问题就是缺陷大小变化很大,在生成小图过程中,我觉得应该采用FOV4的数据和FOV1的数据混合裁剪,会得到更加鲁棒的效果,而且对于大图而言,应该增加更多的几何增强,这样裁剪得到的小图就比较丰富了。
裁剪成小图的时候,由于边沿像素的影响小于中心像素,导致预测时候边沿置信度比较低。故作者裁剪时候采用了重叠1/2像素的stride来裁剪。
4 Inference methodology
网络输入是256x256的小图,测试时候是小图滑窗裁剪测试,重叠比例是1/4,也就是64pix,重叠区域预测值取平均值。为了防止整图预测时候边沿位置影响,先对大图进行reflect padding操作,padding 256/2个像素。
如果测试是reflect pad,那么训练时候应该也是这样。训练时候如果reflect出现了mask,那么应该是把那部分mask去掉,原图也盖掉比较好?还是不管了,训练就是常规操作,测试时候把reflect部分预测忽略?
论文由于不是缺陷检测问题,所以reflect的label肯定也是reflect的,不会删除。对于缺陷检测问题,可能需要特殊处理。
5 结果分析
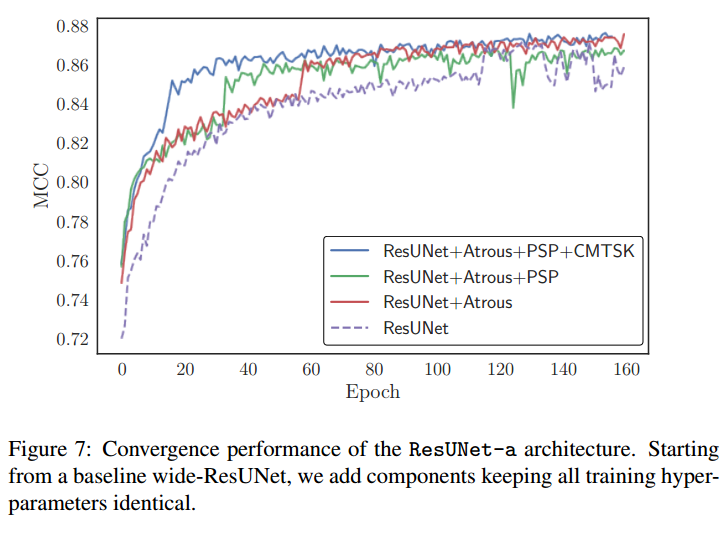
空洞卷积的作用蛮大的,加入psp后,收敛会震荡,加入多任务后就不会了。
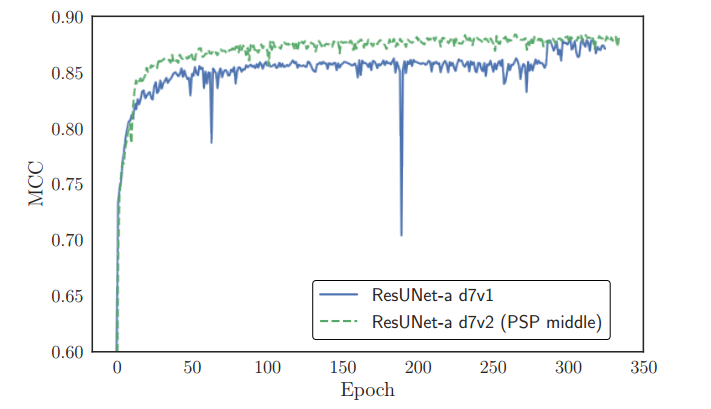
psp加在中间作用很大。
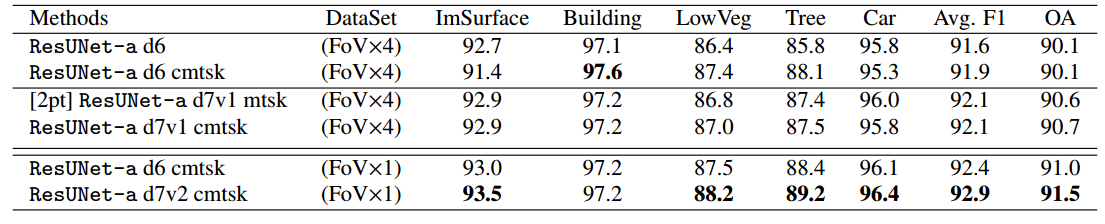
6 CE-Net
论文名称:CE-Net: Context Encoder Network for 2D Medical Image Segmentation
arxiv:1903.02740
github:https://github.com/Guzaiwang/CE-Net
设计比较简单,就是加了一点点设计,采用的也是标准的resnet34+unet+空洞卷积
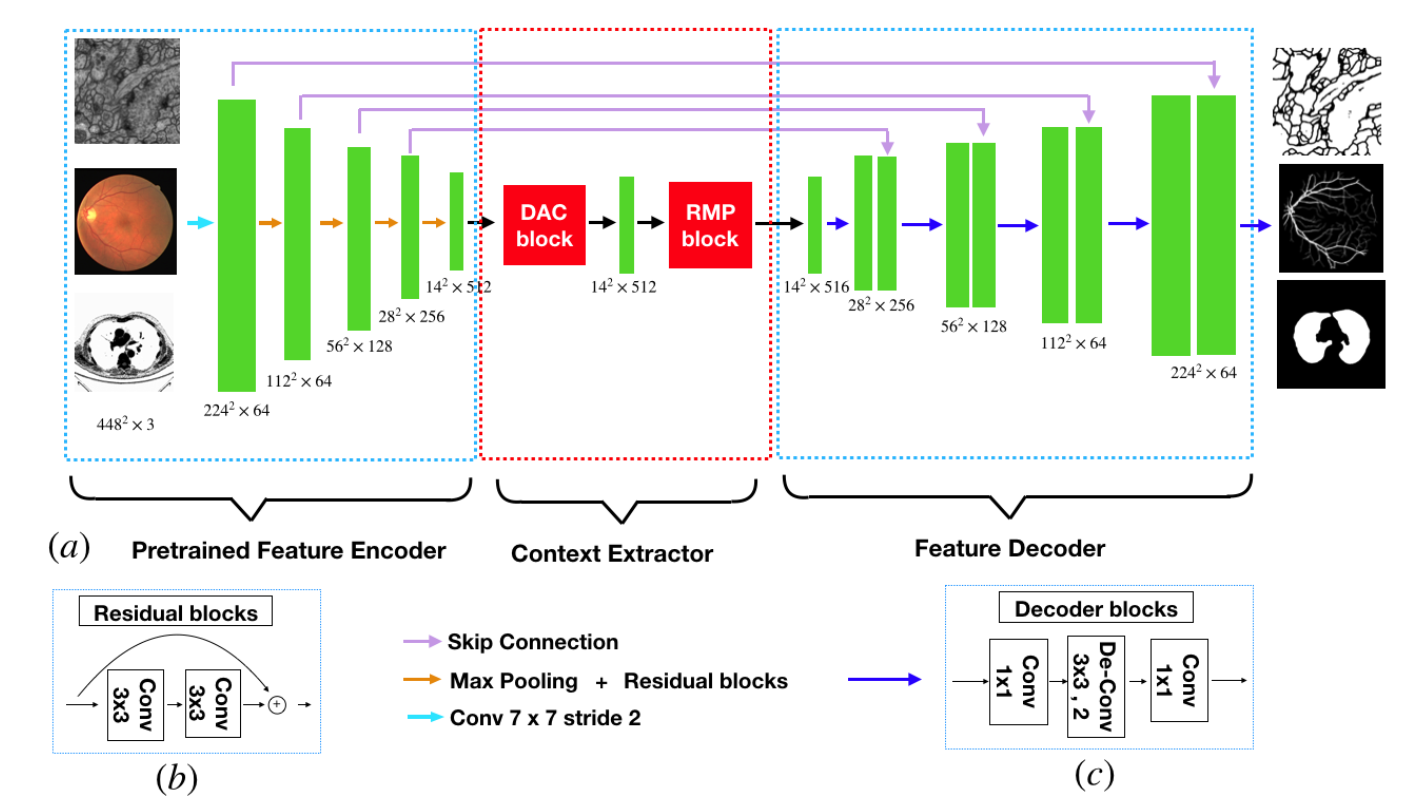
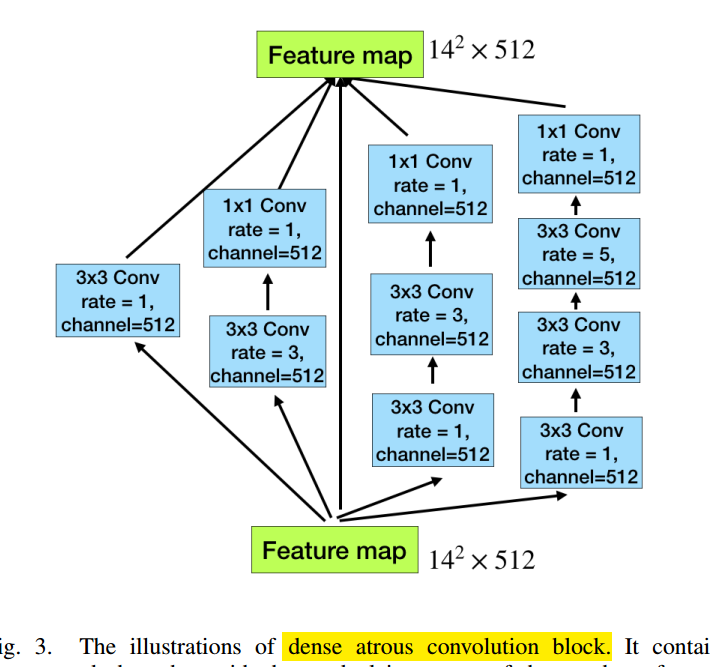
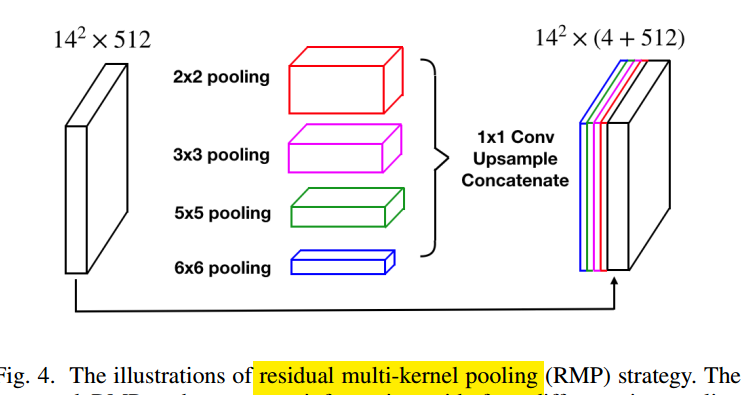
可以看出,和标准的res-unet相比,就是在最后一个编码器后加了一些新操作:
loss就是采用的dice loss。
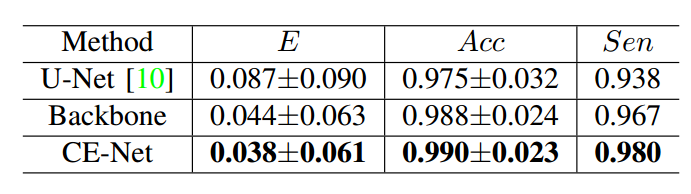
可以看出用了resnet34后,对unet提升很大,加入本文操作后也有提升,但是好像不是很大。


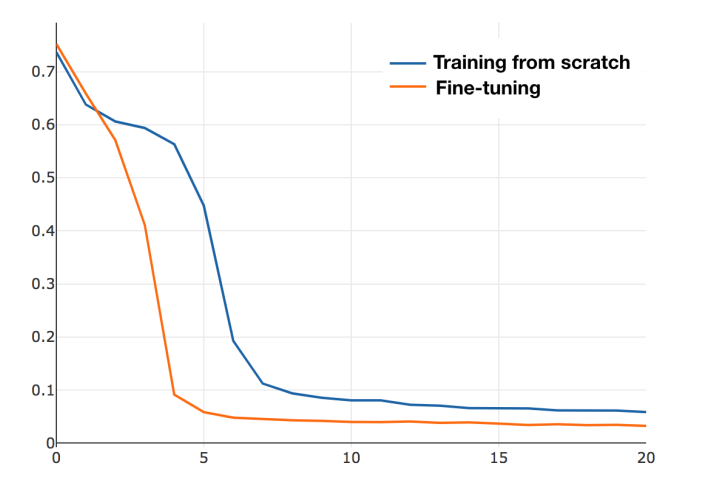
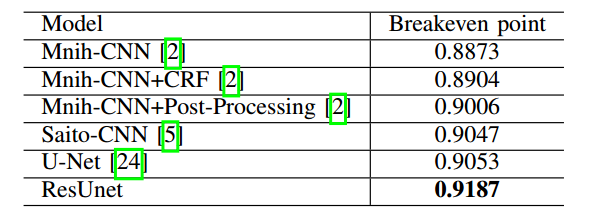
9 U-Net and Lovasz-Softmax Loss 重点
论文名称:Land Cover Classification from Satellite Imagery With U-Net and Lovasz-Softmax Loss
论文地址:http://openaccess.thecvf.com/content_cvpr_2018_workshops/papers/w4/Rakhlin_Land_Cover_Classification_CVPR_2018_paper.pdf
loss代码地址:https://github.com/bermanmaxim/LovaszSoftmax
纯比赛方案,基本上都是实践。
ls loss来自论文:The Lovasz-Softmax loss A tractable surrogate for the optimization of the ´
intersection-over-union measure in neural networks
https://arxiv.org/pdf/1705.08790v2.pdf
本文主要贡献是:
(1) 采用不同的预训练编码器作为unet的编码器
(2) 采用The Lovasz-Softmax loss进行语义分割
(3) 提出了等batch采样策略
(4) 采用swa策略提高泛化能力
任务是7类别分割问题,评估和计算dice loss时候时候背景类不算。
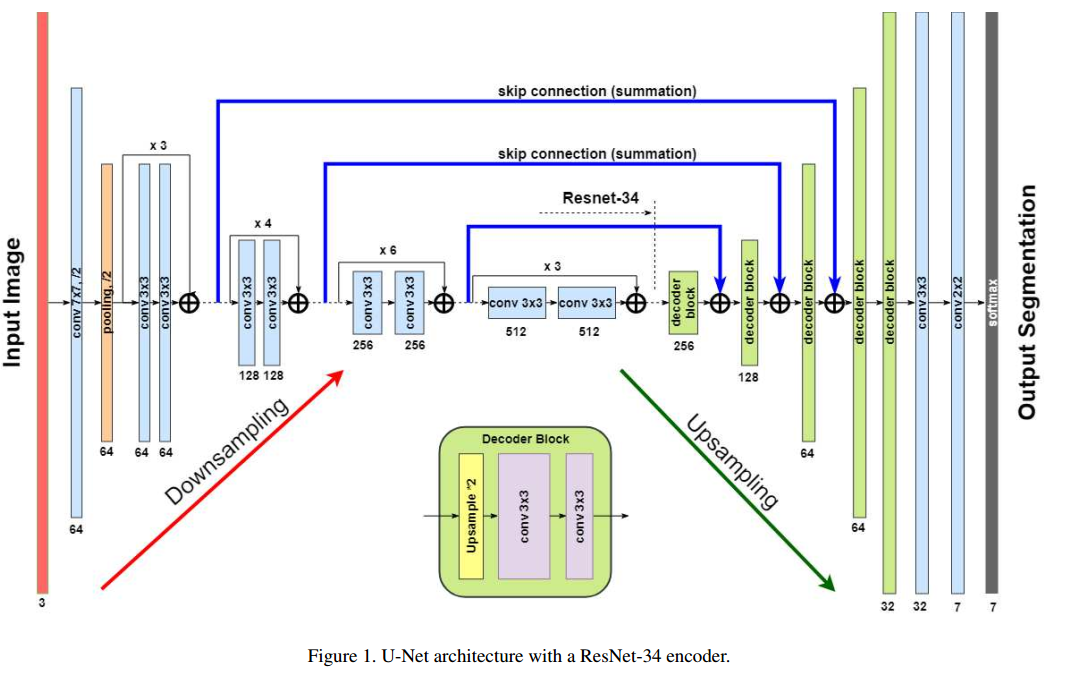
其抽取resnet34的特征层和我们实现的不太一样,其从下采样4倍数处开始抽取,而我们是下采样2倍开始抽取。
(1) 引入预训练模型
编码层部分采用3种结构:vgg,resnet34和Inception Resnet V2。具体修改为:在resnet结构中,使用 ELU激活函数代替ReLu,将BN和非线性激活函数层调换位置,作者指出这种修改很有用,但是是否所有的位置都调换就不清楚了。
(2) 解码层
解码层不再采用反卷积,而是上采样,然后后面用两个3x3卷积。
(3) skip
为了构成残差结构,skip部分也是求和,而不是原始U-net那种concat。我们实现的是concat,不知道是加法好还是concat好
(4) loss设计
也是联合loss,由于这里是多分类任务,总的loss为:

CCE是交叉熵,L`的选择有两个,分别是soft Jaccard loss J杰拉德损失和 the Lovasz-Softmax loss
一共7个类,作者设计的loss仅仅算了后面6个类,背景类loss不算。
在CVPR2018的The Lovasz-Softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks论文中指出:直接优化soft Jaccard loss即IOU是不稳定的,故提出一种新的改进算法,具体细节见论文(论文写的超级复杂,非常难懂)
作者对上述两个loss都进行了对比实验,需要说明的是: Lovasz-Softmax loss计算超级复杂,会导致网络训练速度非常慢,而且实验表明非常难训练。我也没有看到后面新论文有人用过这个loss。
(5) 数据处理策略
先对大图进行下采样2或者4倍,然后随机从图中裁剪288x288的块,然后进行各种增强操作 。而且采样策略也有两种:(1)完全随机裁剪;(2) 考虑类别不平衡的相等batch裁剪。因为mIou这种优化loss,不会考虑类别不平衡,而是把每个类同等对待,故作者设计了平衡策略:假设类别是C,那么在采样图片块时候,会循环遍历每个类,一定保证在构成的batch中,每个类至少都要出现一次。例如batch是8,我一共有3个类,那么其中8个图片块中,每个类一定要出现至少2。
(6) 训练策略
采用了Stochastic Weight Averaging (SWA) 措施,来自论文:Averaging Weights Leads to Wider Optima and Better Generalization-18.03,其是一个非常有效的代替SGD的训练策略,用一个训练模型达到集成模型效果,SWA可以得到更大范围的最小值,从而提升模型泛化能力,应用非常广泛,目前各大深度学习框架例如pytorch,mxnet等等都有实现。
(7) 预测流程
(i) downscale and normalize an image as above,
(ii) crop it into multiple tiles of 288 × 288 pixels with a stride of 288/5= 57 pixels,
(iii) predict the tiles,
(iv) assemble them into a grid and average the predictions,
(v) upsample predicted mask to original size 2448×2448,
(vi) assign the class of every pixel as arg max of the 7 class probability scores
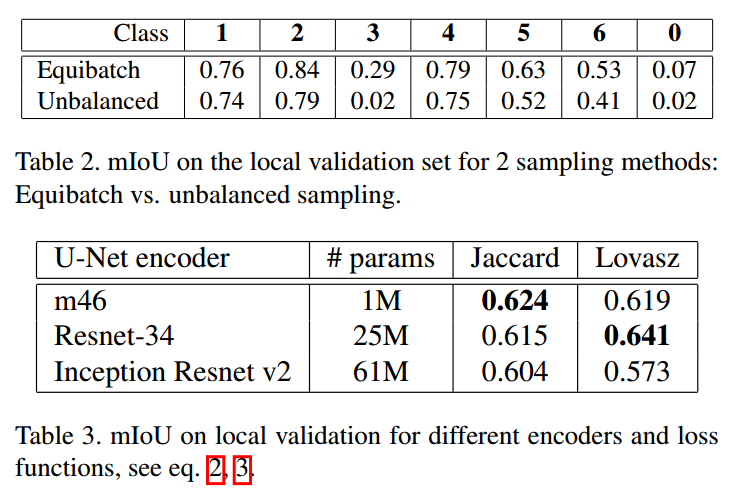
m46是指vgg模型,由于作者的是7分类实现,实验发现等batch采样效果确实比随机采样好多了。
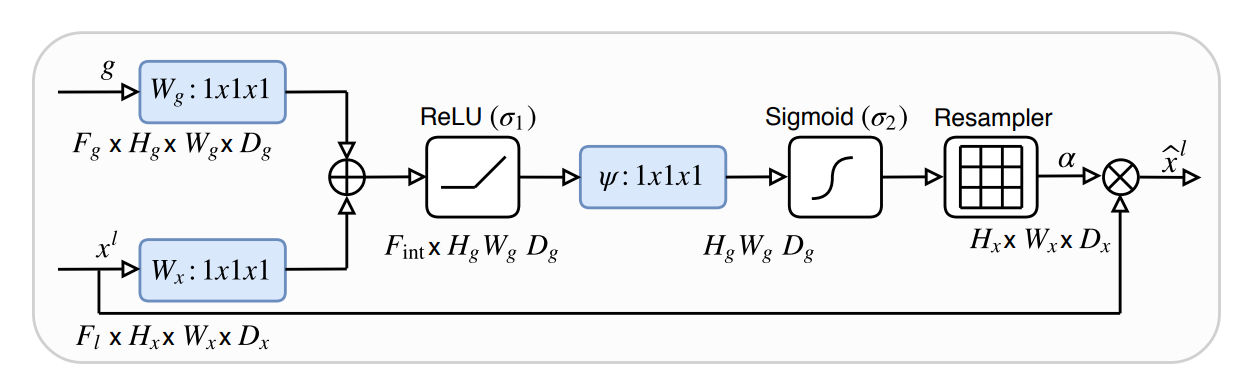
10 Attention U-Net
论文名称:Attention U-Net: Learning Where to Look for the Pancreas
arxiv: https://arxiv.org/pdf/1804.03999v3.pdf
github:https://github.com/LeeJunHyun/Image_Segmentation
官方:https://github.com/ozan-oktay/Attention-Gated-Networks
看上述github代码实现效果,感觉attention unet效果一般。
唯一创新是:本文实现的位置注意力计算计算代价很小,容易集成到标准CNN中。
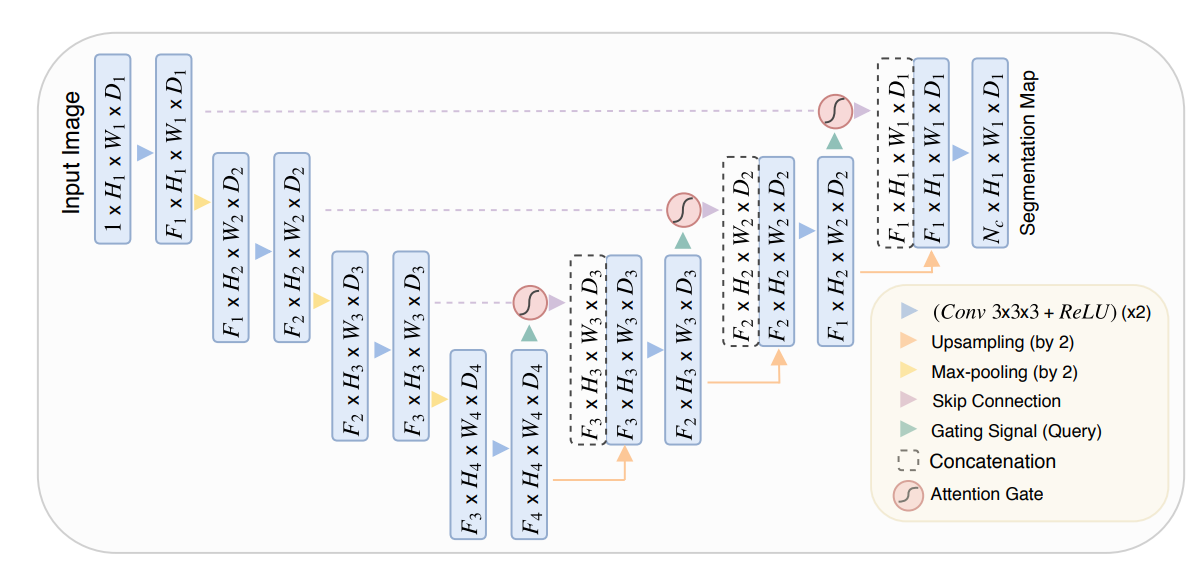
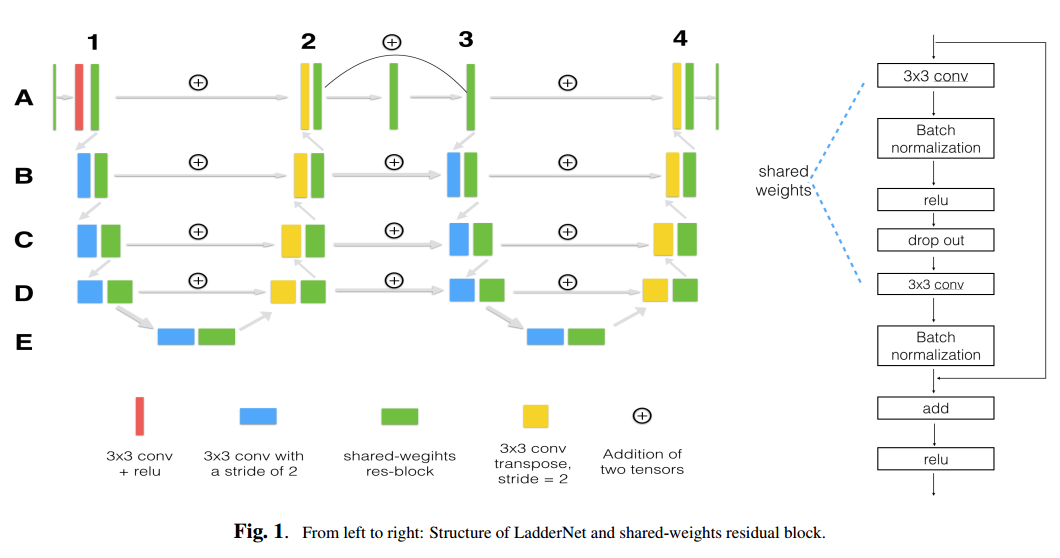
12 Laddernet
论文名称:LadderNet: Multi-path networks based on U-Net for medical image segmentation
arxiv: https://arxiv.org/abs/1810.07810v4
github: https://github.com/juntang-zhuang/LadderNet
本文指出目前所有的u-net虽然都有skip连接,但是信息流通的通道比较少,可能会限制网络性能,故提出多路径U-Net网络。作者的观点是:引入resnet中的残差结构的不同分支,实际上是集成了多个网络,而本文进一步发挥了多路径连接思想,从而得到更多的模型,自然可以提供性能和泛化能力。
但是感觉本文实现比较奇怪。暂时不管。
13 Coupled U-Nets
论文名称:CU-Net: Coupled U-Nets
arxiv: https://arxiv.org/abs/1808.06521
BMVC2018 oral 但是感觉本文太过复杂了,不可取。
本文说到一个问题:堆叠多个u-net应该会进一步提高精度,但是如果只是各种堆叠,会导致参数量巨大,不好优化。故本文基于堆叠u-net思想,但是不想增加参数,设计了Coupled密集连接操作,或许是一个可行的级联unet方案。
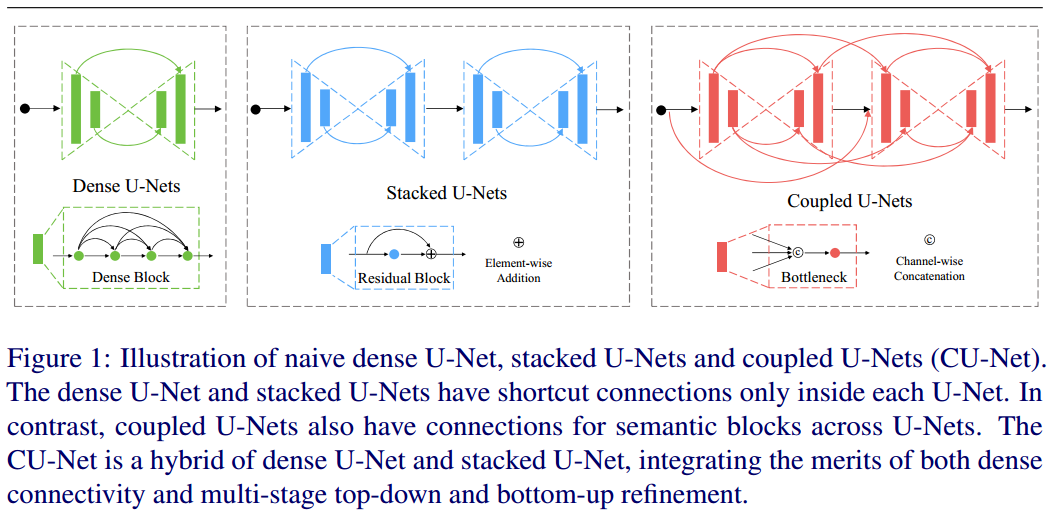
本文设计的cu unet其实就是包含了dense unet和stacked unet的设计,包含内部和外部极联设计。
三个unet级联的结构图:
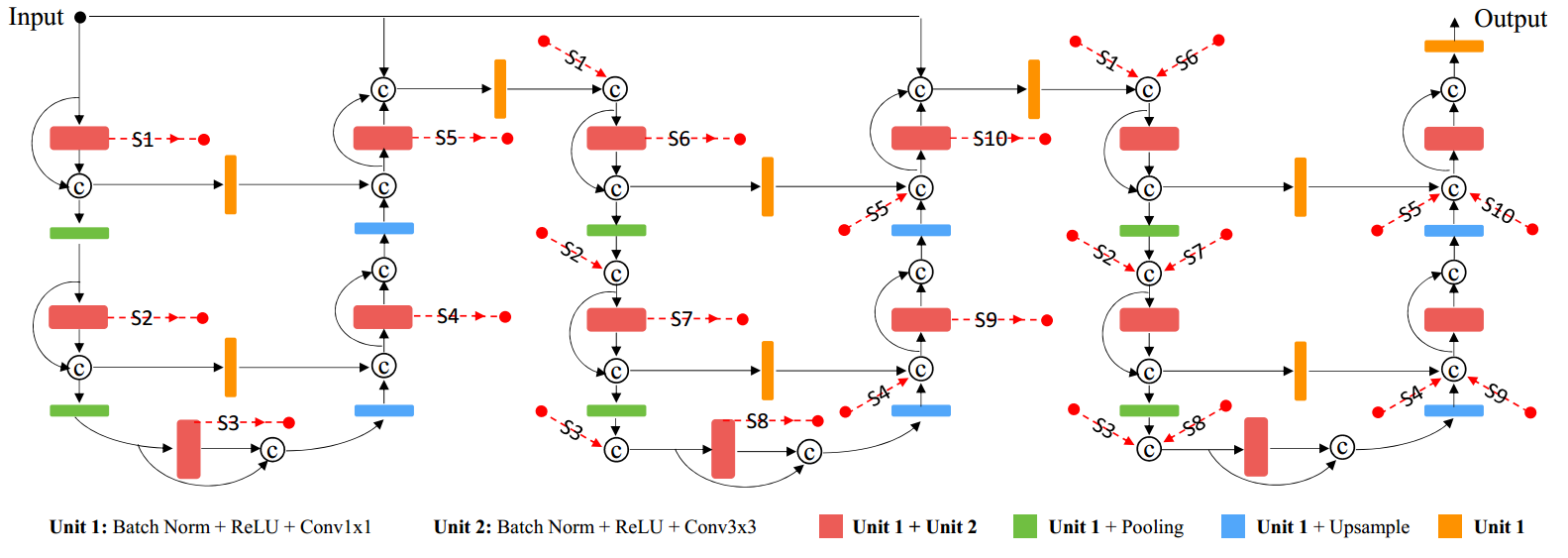
the dense connections could increase the information flow in the U-Net to some extent.
However, they are only within the local blocks.
注意本文提出的cu unet是在人体姿态估计领域进行测试,而不是语义分割。

全监督不是必须的。看实验效果,是否采用全监督也是个问题啊。
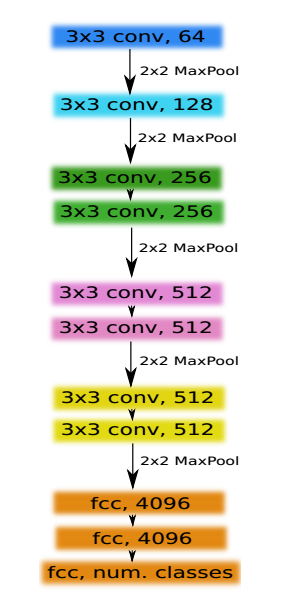
14 MultiResUNet
论文名称:MultiResUNet : Rethinking the U-Net Architecture for Multimodal Biomedical Image Segmentation
arxiv: https://arxiv.org/abs/1902.04049
github: https://github.com/nibtehaz/MultiResUNet/blob/master/MultiResUNet.py
首先给出unet结构:
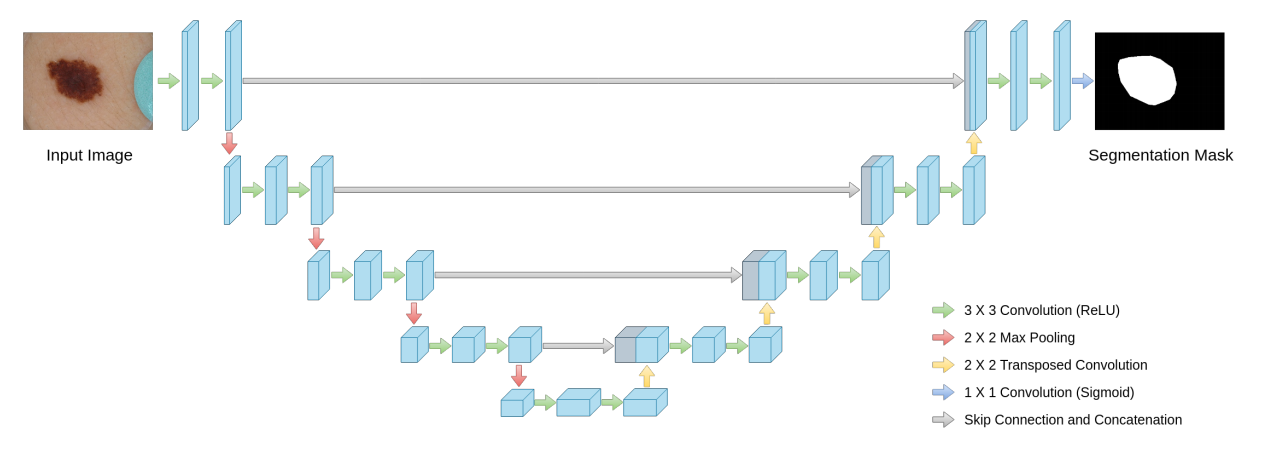
本文指出U-Net结构存在的问题:
(1) 不太好解决尺度变化问题。作者分析的原因是它的感受野固定,无法自适应,应该采用Inception这种自适应感受野的结构才比较科学。故作者设计了如下的结构:
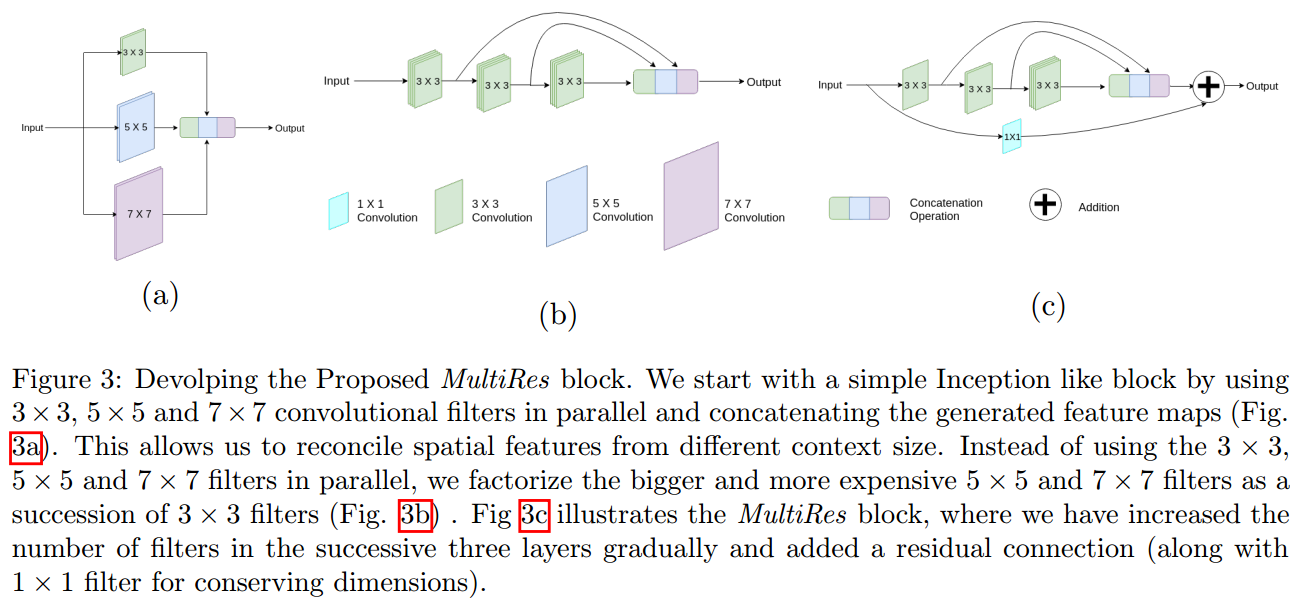
(a) 是作者设计的满足多感受野的结构,但是考虑效率不高,故提出了(b)结构,注意(b)中的每个3x3卷积块的通道数是一样,基于其他研究的结论,作者认为(c)这种结构更加轻量,更加高效。故最终的版本是(c)。
(2) 高层语义和底层特征直接融合,是不好的。这个观点在很多论文里面都有提到,作者的解决办法是:

通过控制通道数目来达到和原始U-Net一样的参数量,方便对比。
整体结构:
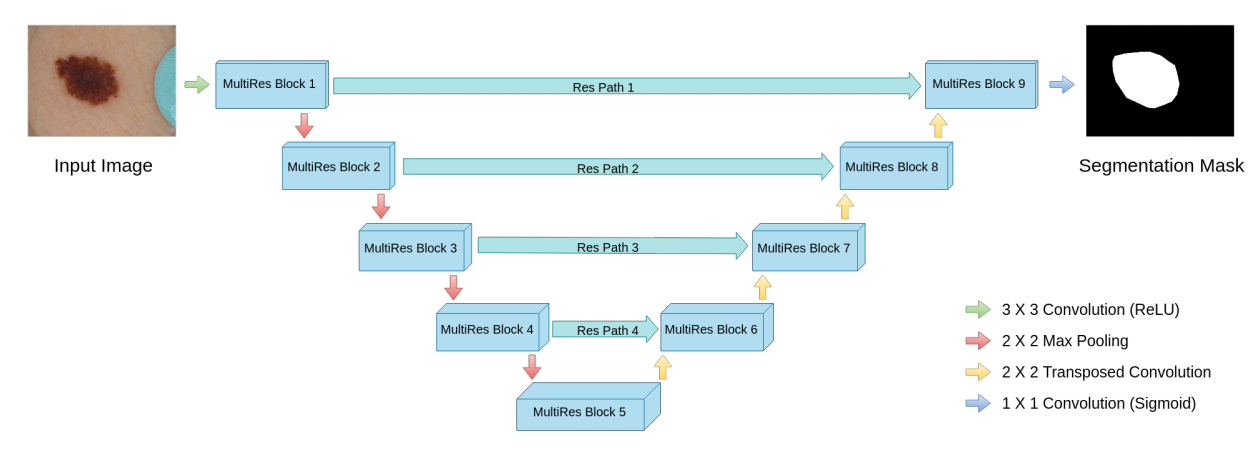
loss就是bce而已。

作者在多个数据集上面都进行了测试。
15 Focal Tversky loss
论文名称:A Novel Focal Tversky loss function with improved Attention U-Net for lesion segmentation
arxiv: 1810.07842
18 Coordination-guided
https://arxiv.org/pdf/1904.09106.pdf
辅助边界dice loss;加入坐标卷积提高精度。
LinkNet和D-LinkNet
https://arxiv.org/abs/1707.03718
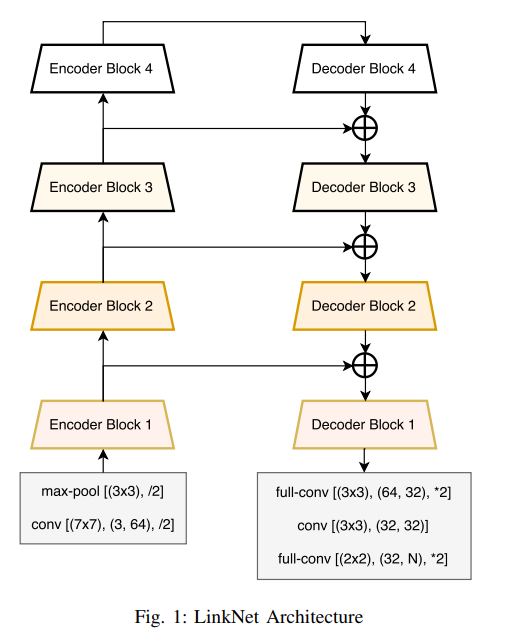
linknet是为了轻量级语义分割而设计的,是通用分割场景,其实和unet的区别就是:(1) 采用各种各样的骨架网络作为预训练权重;(2) concat操作改为add操作。
D-LinkNet:http://openaccess.thecvf.com/content_cvpr_2018_workshops/papers/w4/Zhou_D-LinkNet_LinkNet_With_CVPR_2018_paper.pdf 比赛方案
https://github.com/zlkanata/DeepGlobe-Road-Extraction-Challenge
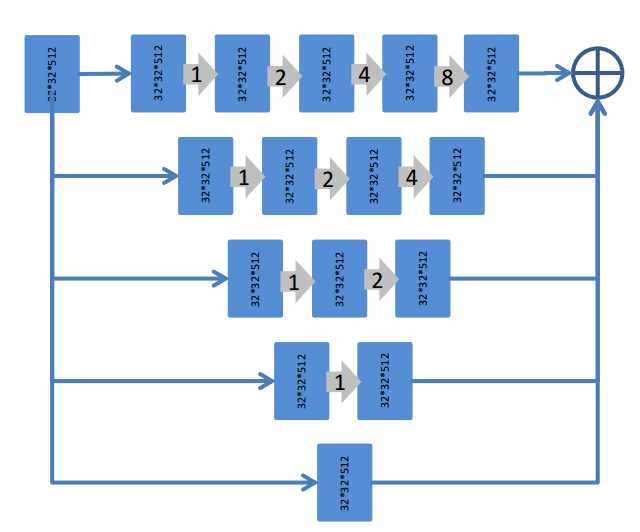
D-LinkNet是为了高分辨率分割任务设计的,原始的LinkNet虽然很节省内存,但是预训练权重一般就是resnet18或者34,对于256x256的图而言,感受野是够的,但是现在输入图片是1024x1024,此时可能就不够了,故作者在编码器的最后一层加了了并行空洞卷积来扩大感受野,提高性能。对于我们的缺陷检测任务不一定适应。
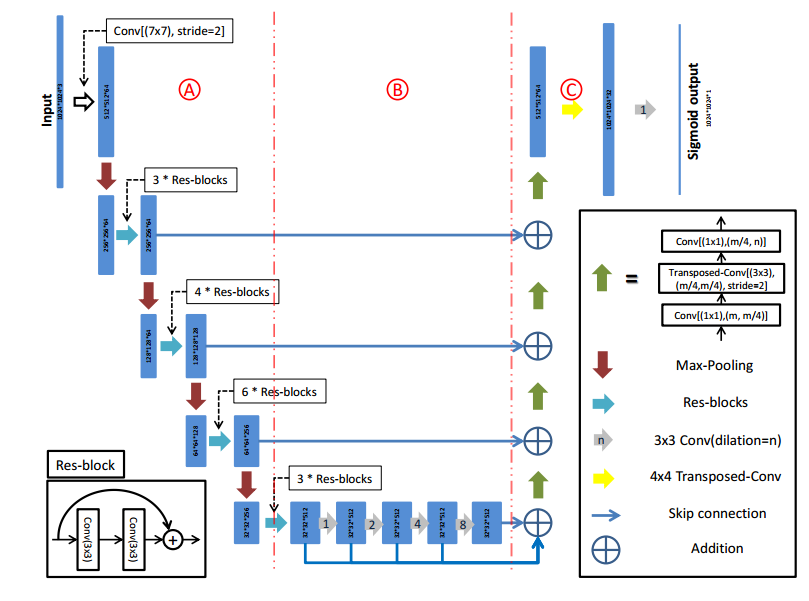
除了中心部分加入了空洞卷积外,其余部分和LinkNet相同。
详情如下:
训练采用bce+dice ,adam,测试时候采用了水平翻转、垂直翻转和对角线翻转的增强测试模式。

loss总结
https://github.com/ShawnBIT/Loss-family
https://github.com/JunMa11/SegLoss
比赛方案
https://github.com/qubvel/open-cities-challenge#pipeline-short-summary
On this step 10 Unet models are going to be trained on data. 5 Unet models for eficientnet-b1 encoder and 5 for se_resnext_32x4d encoder (all encoders are pretrained on Imagenet). We train 5 models for each encoder because of 5 folds validation scheme. Models trained with hard augmentations using albumetations library and random data sampling. Training lasts 50 epochs with continious learining rate decay from 0.0001 to 0.
27 nnU-Net
Self-adapting Framework for U-Net-Based Medical Image Segmentation
