@huanghaian
2020-03-21T08:50:40.000000Z
字数 9491
阅读 1776
目标检测正负样本区分策略和平衡策略总结(二)
目标检测
0 简介
本文抛弃网络具体结构,仅仅从正负样本区分和正负样本平衡策略进行分析,大体可以分为正负样本定义、正负样本采样和平衡loss设计三个方面,主要是网络预测输出和loss核心设计即仅仅涉及网络的head部分。所有涉及到的代码均以mmdetection为主。
本文属于第二篇,主要是分析anchor-free的正负样本策略,主要包括fcos、centernet、atss和spad。下一篇分析yolo-asff和ghm等等。
2 anchor-free
2.1 fcos
论文名称:FCOS: Fully Convolutional One-Stage Object Detection
FCOS堪称anchor free论文的典范,因为其结构主流,思路简单清晰,效果蛮好,故一直是后续anchor free的基准对比算法。FCOS的核心是将输入图像上的位置作为anchor point的中心点,并且对这些anchor point进行回归。
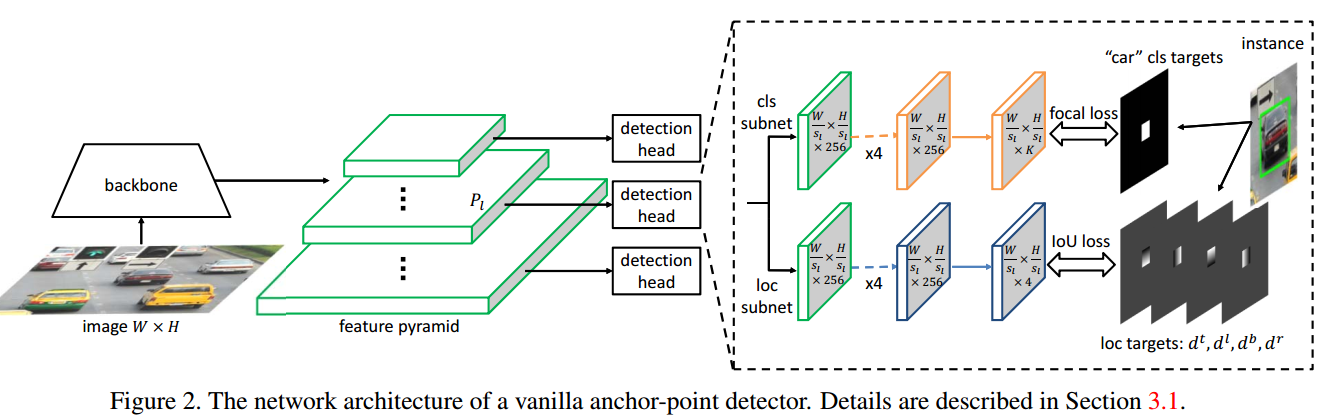
(1) head结构
fcos的骨架和neck部分是标准的resnet+fpn结构,和retinanet完全相同。如下所示:
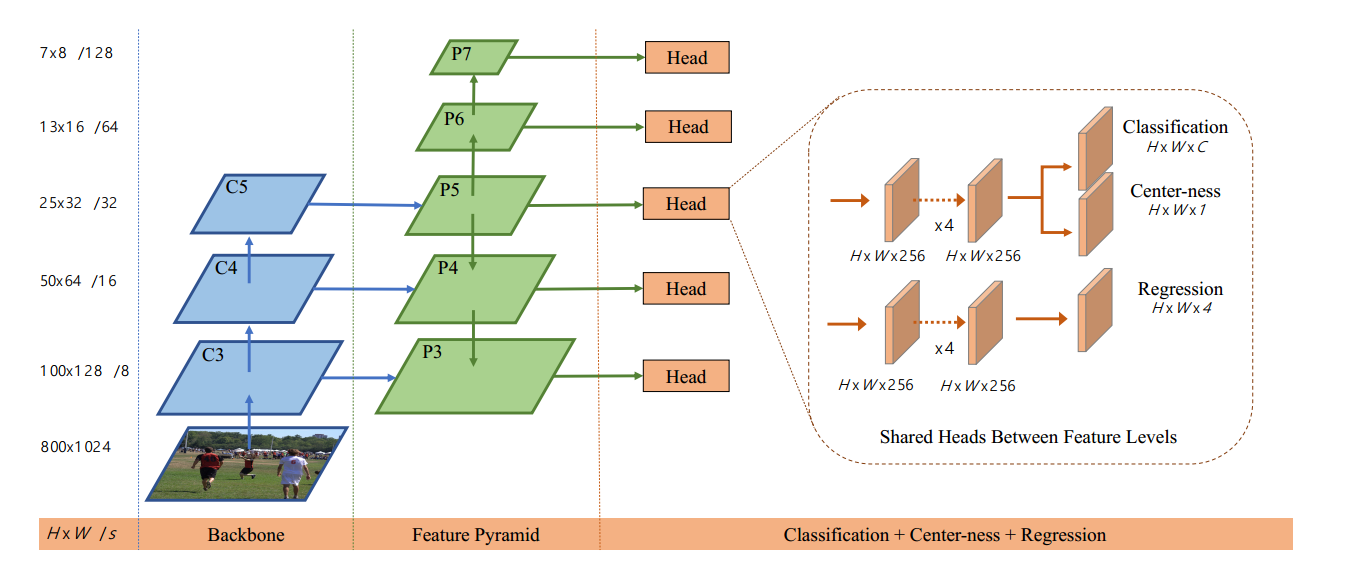
我们仅仅考虑head部分。除去center-ness分支,则可以看出和retinanet完全相同。其配置如下:
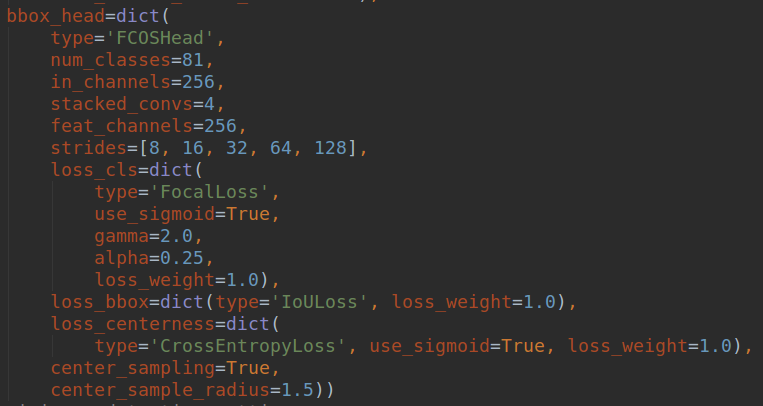
可以看出一共5个尺度进行预测,每个尺度的stride可以从strides中看出来。由于其是anchor free论文,故少了很多复杂参数。
(2) 正负样本定义
考虑到anchor free预测值和anchor base不一样,故还是需要提前说下网络预测形式。FCOS是全卷积预测模式,对于cls分支,输出是h x w x (class+1),每个空间位置值为1,表示该位置有特定类别的gt bbox,对于回归分支,输出是h x w x 4,其4个值的含义是:

每个点回归的4个数代表距离4条边的距离,非常简单易懂。
和所有目标检测算法一样,需要提前定义好正负样本,同时由于是多尺度预测输出,还需要首先考虑gt由哪一个输出层具体负责。
作者首先设计了min_size和max_size来确定某个gt到底由哪一层负责,具体设置是0, 64, 128, 256, 512和无穷大,也就是说对于第1个输出预测层而言,其stride=8,负责最小尺度的物体,对于第1层上面的任何一个空间位置点,如果有gt bbox映射到特征图上,满足0 < max(中心点到4条边的距离) < 64,那么该gt bbox就属于第1层负责,其余层也是采用类似原则。总结来说就是第1层负责预测尺度在0~64范围内的gt,第2层负责预测尺度在64~128范围内的gt,其余类推。通过该分配策略就可以将不同大小的gt分配到最合适的预测层进行学习。
第二步是需要确定在每个输出层上面,哪些空间位置是正样本区域,哪些是负样本区域。原版的fcos的正负样本策略非常简单粗暴:在bbox区域内的都是正样本,其余地方都是负样本,而没有忽略样本区域。可想而知这种做法不友好,因为标注本身就存在大量噪声,如果bbox全部区域都作为正样本,那么bbox边沿的位置作为正样本负责预测是难以得到好的效果的,显然是不太靠谱的(在文本检测领域,都会采用shrink的做法来得到正样本区域),所以后面又提出了center sampling的做法来确定正负样本,具体是:引入了center_sample_radius(基于当前stride参数)的参数用于确定在半径范围内的样本都属于正样本区域,其余区域作为负样本,依然没有定义忽略样本。默认配置center_sample_radius=1.5,如果第1层为例,其stride=8,那么也就是说在该输出层上,对于任何一个gt,基于gt bbox中心点为起点,在半径为1.5*8=12个像素范围内都属于正样本区域。其核心代码如下:
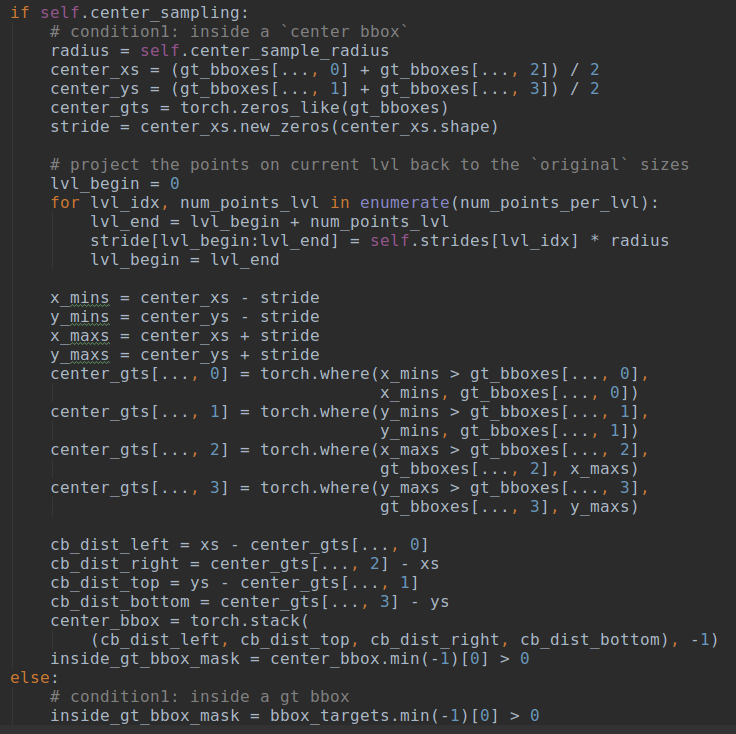
如果需要进行中心采样,那么基于采样半径比例×当前stride的范围内都属于正样本inside_gt_bbox_mask,其余样本全部属于负样本。
可能很多人都有疑问:为啥不需要设置忽略区域?个人猜测原因可能是:1. 设置忽略区域,又需要增加一个超参;2.多了一个center-ness分支,可以很大程度抑制这部分区域对梯度的影响。3.间接的增加了正样本数目。不管咋说应该是作者实验后发现没有很大必要吧。
(3) 平衡loss设计
可以发现上述肯定存在大量正负样本不平衡问题,故作者对于分类分支采用了one-stage常用的focal loss;对于bbox回归问题,由于很多论文表明直接优化bbox比单独优化4个值更靠谱,故作者采用了GIOU loss来回归4个值,对于center-ness分支,采用的是CrossEntropyLoss,当做分类问题处理。
(4) 附加内容
center-ness作用比较大,从上面的正负样本定义就可以看出来,如果没有center-ness,对于所有正样本区域,其距离bbox中心不同远近的loss权重居然是一样的,这明显是违反直觉的,理论上应该越是远离Bbox中心的空间位置,其权重应该越小,作者实验也发现如果没有center-ness分支,会产生大量假正样本,导致很多虚检。center-ness本质就是对正样本区域按照距离gt bbox中心来设置权重,这是作者的做法,还有很多类似做法,不过有些是在Loss上面做文章,例如在ce loss基础上乘上一个类似预center-ness的权重来实现同样效果(例如Soft Anchor-Point Object Detection)。center-ness效果如下:

2.2 centernet
论文名称:Objects as Points
centernet也是非常流行的anchor-free论文,其核心是:一些场景的cv任务例如2d目标检测、3d目标检测、深度估计和关键点估计等等任务都可以建模成以物体中心点学习,外加上在该中心点位置处额外学习一些各自特有属性的通用做法。对于目标检测,可以将bbox回归问题建模成学习bbox中心点+bbox宽高问题,如下所示:

(1) head结构
centernet的输出也非常简单,其相比较于FCOS等算法,使用更大分辨率的输出特征图(缩放了4倍),本质上是因为其采用关键点检测思路做法,而关键点检测精度要高,通常是需要输出高分辨率特征图,同时不需要多尺度预测。其输出预测头包含3个分支,分别是
1. 分类分支h' x w' x (c+1),如果某个特定类的gt bbox的中心点落在某个位置上,那么该通道的对应位置值设置为1,其余为0;
2. offset分支h' x w' x 2,用于学习量化偏差,图像下采样时,gt bbox的中心点会因数据是离散的而产生偏差,例如gt bbox的中心点坐标是101,而由于输入和输出相差4倍,导致gt bbox映射到特征图上坐标由25.25量化为了25,这就出现了101-25x4=1个pix的误差,如果下采样越大,那么量化误差会越大,故可以使用offset分支来学习量化误差,这样可以提高预测精度。
3. 宽高分支h' x w' x 2,表示gt bbox的宽高。
其中1.2分支和cornetnet的做法完全相同。而由于objects as points的建模方式和FCOS的建模方式不一样,故centernet的正负样本定义就会产生很大区别。主要是宽高分支的通道数是2,而不是4,也就是说其输入到宽高分支的正样本其实会非常少,必须是gt bbox的中心位置才是正样本,左右偏移位置无法作为正样本,也没有啥忽略样本的概念,这个是和FCOS的最大区别。
(2) 正负样本定义
由于centernet特殊的建模方式,故其正负样本定义特别简单,不需要考虑多尺度、不需要考虑忽略区域,也不用考虑iou,正样本定义就是某个gt bbox中心落在哪个位置上,那么那个位置就是正样本,其余位置全部是负样本。
(3) 平衡Loss设计
前面说过目标检测所有论文的样本平衡策略都主要包括正负样本定义、正负样本采样和平衡loss设计,不管啥目标检测算法都省不了,对于centernet,其正负样本定义非常简单,可以看出会造成极其严重的正负样本不平衡问题,然后也无法像two-stage算法一样设计正负样本采样策略,那么平衡问题就必须要在loss上面解决。
对于offset和宽高预测分支,其只对正样本位置进行监督,故核心设计就在平衡分类上面。
对于分类平衡loss,首选肯定是focal loss了,但是还不够,focal loss的核心是压制大量易学习样本的权重,但是由于我们没有设置忽略区域,在正样本附近的样本,实际上非常靠近正样本,如果强行设置为0背景来学习,那其实相当于难负样本,focal loss会突出学这部分区域,导致loss难以下降、不稳定,同时也是没有必要的,因为我们的label虽然是0或者1的,但是在前向后处理时候是当做高斯热图(0~1之间呈现2d高斯分布特点)来处理的,我们学到最后的输出只要满足gt bbox中心值比附近区域大就行,不一定要学习出0或者1的图。
基于上述设定,在不修改分类分支label的情况下,在使用focal loss的情况下,作者的做法是对正样本附近增加惩罚,基于2d高斯分布来降低这部分权重,相当于起到了类似于忽略区域的作用。可以简单认为是focal focal loss。
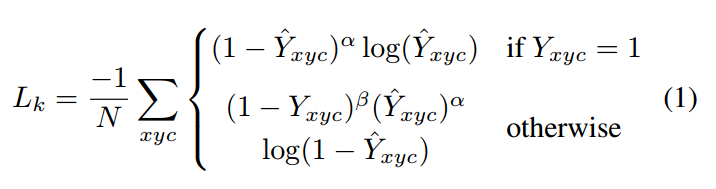
其中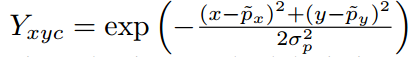
Y是label,0或者1,当Y=1时候,也就是正样本位置,就是标准的focal loss设定;其余区域,分为附近区域和外围区域,附近的定义采用了自适应宽高标准差的做法,在2d高斯分布内部的属于附近区域,外面的都称为外围背景区域,外围区域也是标准的focal loss定义。故作者设计更改的就是附近区域,也就是,可以发现如果去掉,就是标准的focal loss。附近区域中越靠近中心点的惩罚Y越大,Loss权重越小,表示该位置对于正还是负的区分越模糊。
可能很多人有疑问:明明label是0-1的,为啥学出来的会是高斯热图,而不是0-1热图?我的分析是:如果不考虑附近区域,而是仅仅采用focal loss那么确实应该学出来的最接近0-1热图,但是由于基于距离gt bbox中心远近不同,设置了不同的惩罚系数,导致网络学习时候对于这部分学习出来的值关注程度不一样,可能就会产生这种现象,举例来说:即使采用上述label,最完美的输出应该是0或1的,但是实际上很难,对于偏离gt bbox附近一点点的位置,假设其预测输出为0,那么肯定是loss最低,但是可能训练不到那么好,那么由于其权重比较小,其学习出0.9,其实loss也不会太大,但是如果距离远一点的,其也学习出0.9,由于其loss权重比较大,就会迫使网络预测要变小一点点,例如变成0.8输出。基于这种权重分布,训练出来的热图可能就会按照1-loss权重的分布呈现,出现高斯热图。
学习关键点中心,作者采用的是分类loss,不清楚如果直接采用回归loss,效果咋样,我觉得效果应该不会差。因为关键点检测一般都是采用l2回归loss直接监督在高斯热图上。并且因为宽高、offset分支其实也都是回归loss,三个分支都采用回归Loss,不好吗?
还有一个问题:宽高和offset的监督仅仅在gt bbox中心位置,其余位置全部是忽略区域。这种做法其实很不鲁棒,也就是说bbox性能其实完全靠分类分支,如果分类分支学习的关键点有偏差,那么由于宽高的特殊监督特性,可能会导致由于中心点定位不准而带来宽高不准的情况(特别的如果中心点预测丢失了,那么宽高预测再准也没有用),后面有些论文有其他解决办法,
2.3 atss
论文名称:Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
本文写的非常好,作者试图分析问题:anchor-free和anchor-base算法的本质区别是啥?性能为啥不一样?最终结论是其本质区别就在于正负样本定义不同。只要我们能够统一正负样本定义方式,那么anchor-free和anchor-base就没有啥实际区别了,性能也是非常一致的。正负样本定义也是我写这篇文章的一个最大要说明的地方,因为其非常关键,要想彻底理解不同目标检测算法的区别,那么对于正负样本定义必须要非常清楚。
(1) head部分
由于这篇论文细节比较多,为了论文完整性,我这里大概说下,不重点描述。作者为了找出本质区别,采用了anchor-base经典算法retinanet以及anchor-free经典算法FCOS来说明,因为这两篇论文非常相似,最好进行对比。
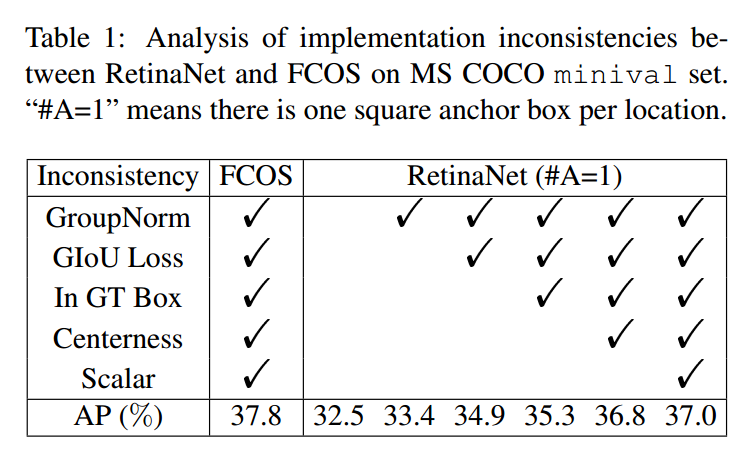
由于FCOS是基于point进行预测,故可以认为就是一个anchor,为了公平对比,将retinanet的anchor也设置为1个(#A=1),将FCOS的训练策略移动到retinanet上面,可以发现性能依然retinanet低于fcos 0.8mAP。
排除这个因素后,现在两个算法的区别是1.正负样本定义;2.回归分支中从point回归还是从anchor回归。从point回归就是指的每个点预测距离4条边的距离模式,而从anchor回归是指的retinanet那种基于anchor回归的模式。
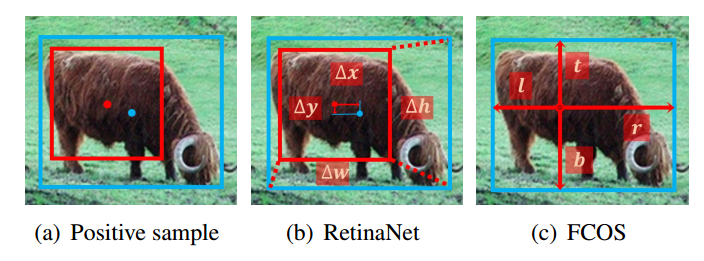
后面有实验分析可以知道回归分支中从point回归还是从anchor回归对最终影响很小。
ATSS的head部分结构如下:
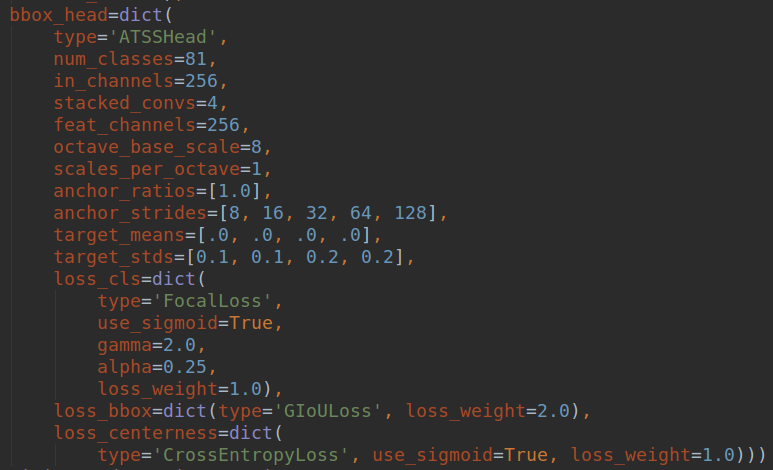
可以看出所有的参数其实就是retinanet和fcos参数的合并而已,没有新增参数。
(2) 正负样本定义
正负样本定义是本文的讨论重点。作者首先详细分析了retinanet和fcos的正负样本定义策略的不同,首先这两个算法都是多尺度预测的,故其实都包括两个步骤:gt分配给哪一层负责预测;gt分配给哪一个位置anchor负责预测。retinanet完全依靠统一的iou来决定哪一层哪一个位置anchor负责预测,而fcos显式的分为两步:先利用scale ratio来确定gt分配到哪一层,然后利用center sampling策略来确定哪些位置是正样本。具体细节请参见的retinanet和fcos的正负样本定义总结。
这两种操作的细微差别会导致如下情形:
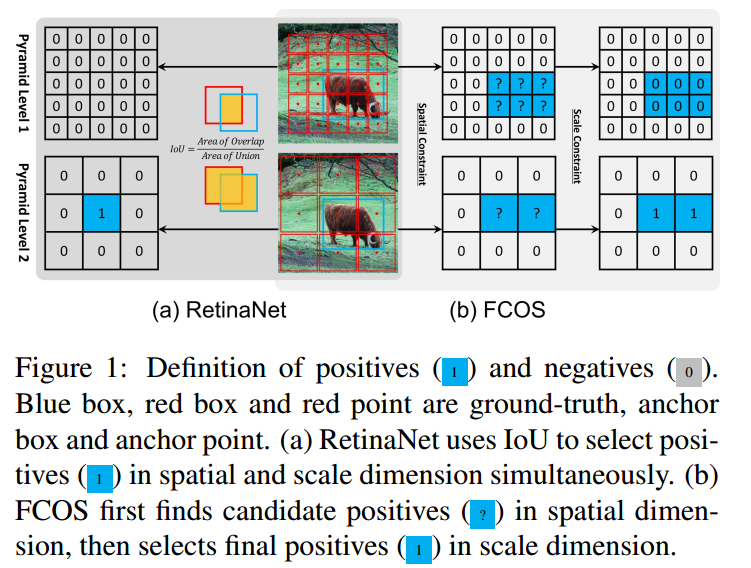
对于1和2两个输出预测层,retinanet采用统一阈值iou,可以确定上图蓝色1位置是正样本,而对于fcos来说,有2个蓝色1,表明fcos的定义方式会产生更多的正样本区域。这种细微差距就会导致retinanet的性能比fcos低一些。
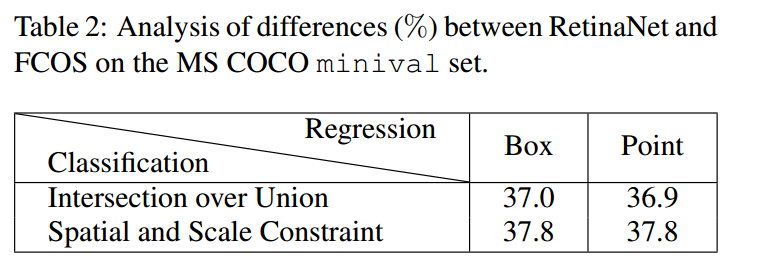
对于retinanet算法,正负样本定义采用iou阈值,回归分支采用原始的anchor变换回归模式(box),mAP=37.0,采用fcos的point模式是36.9,说明到底是point还是box不是关键因素。但是如果换成fcos的正负样本定义模式,mAP就可以上升为37.8,和fcos一致了,说明正负样本定义的不同是决定anchor-base和anchor-free的本质区别。
既然找到了本质问题,作者分析肯定是fcos的正负样本定义策略比retinanet好,但是fcos算法需要定义超参scale constraint,比较麻烦,作者希望找到一种和fcos类似功能的正负样本定义算法,主要特定是几乎没有超参,或者说对超参不敏感,可以自适应,故作者提出ATSS算法。由于作者的设计可以认为是fcos正负样本定义策略的改进版本,故mmdetection的代码中也是针对fcos来说的,具体就是除了正负样本定义策略和fcos不一样外,其余全部相同,所以我们也仅仅需要关注atss部分代码就行。

其只有一个参数topk,实验表明参数适当就行,不敏感。下面具体分析ATSS:

流程比较简单,但是需要注意,由于依然需要计算iou,故anchor的设置不能少,只不过anchor仅仅用于计算正负样本区域而已,在计算loss时候还是anchor-free的,anchor默认设置就1个。主要是理解思想:
- 对于每个gt bbox,在每一个预测层上采样tokp个基于l2距离的位置,作为候选;
- 计算gt和每个候选anchor的iou;计算所有iou的均值和方差,相加变成iou阈值(每个gt都有一个自适应的iou阈值);
- 遍历每个候选anchor,如果该anchor大于iou阈值,并且anchor中心位置在gt bbox内部,那么这个就是正样本区域,其余全部是负样本。
均值(所有层的候选样本算出一个均值)代表了anchor对gt衡量的普遍合适度,其值越高,代表候选样本质量普遍越高,iou也就越大,而方差代表哪一层适合预测该gt bbox,方差越高越能区分层和层之间的anchor质量差异。均值和方差相加就能够很好的反应出哪一层的哪些anchor适合作为正样本。一个好的anchor设计,应该是满足高均值、高方差的设定。
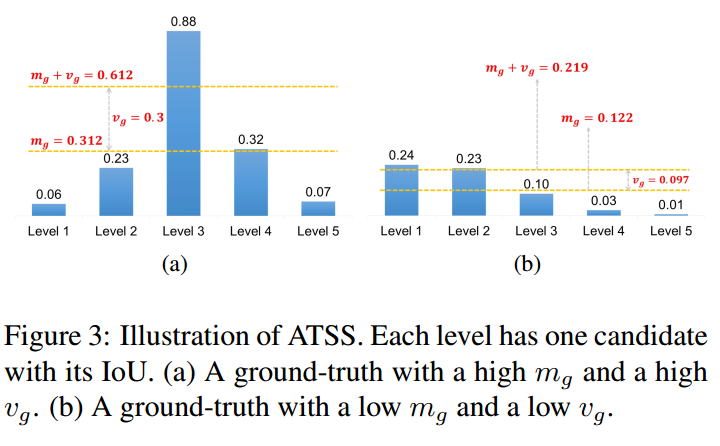
如上图所示,(a)的阈值计算出来是0.612,采用该阈值就可以得到level3上面的才是正样本,是高均值高方差的。同样的如果anchor设置和gt不太匹配,计算出来的阈值为0.219,依然可以选择出最合适的正样本区域,虽然其属于低均值、低方差的。采用自适应策略依然可以得到相对好的正负样本,实现了自适应功能,至少可以保证每个GT一定有至少一个anchor负责对应。从这个设定来看,应该会出现某个gt在多个层上面都属于正样本区域,而没有限制必须在其中某个层预测,相当于增加了些正样本。K默认是9。
(3) 平衡loss设定
其loss函数设计完全和fcos一样,不再赘述。
2.4 spad
论文名称:Soft Anchor-Point Object Detection
本文可以认为是anchor-free论文的改进。其首先指出目前anchor-free算法存在的问题:1.attention bias,2.feature selection,并提出了相应的soft策略。由于其主要是修改了正负样本定义策略,故是本文分析的重点。
(1) head
本文属于anchor point类算法,即每个点都学习距离4条边的距离,这是标准的densebox算法流程,本质上和FCOS一样:
和FCOS的区别就在于 1. 没有center-ness分支,2. 正样本区域的定义采用4条边向内shrink做法,而不是center sampling。
1.Attention bias
作者采用上面的网络进行训练,发现一个问题如下:

(b)是标准网络训练的分类confidence图,可以看出在靠近物体中心的四周会依然会产生大量confidence很高的输出,即没有清晰的边界,在训练过程中可能会抑制掉周围小的物体,导致小物体检测不出来或者检测效果很差。作者分析原因可能是在anchor-point方法在边界地方point进行回归,会存在特征不对齐问题或者说很难对齐。这个现象在FCOS没有加center-ness时候也出现了,FCOS的解决办法就是加入新的center-ness分支训练时候抑制掉,本文解决办法不一样,其通过加权方法。加权后效果如(c)。
2.Feature selection
特性选择问题其实是指的对于任何一个gt bbox,到底采用何种策略分配到不同的层级进行预测?目前目标检测的做法是基于启发式人工准则将实例分配到金字塔层次(retinanet),或将每个实例严格限制为单个层次(fcos),从而可能会导致特征能力的不充分利用。

作者通过训练发现:虽然每个GT只在特定层进行回归,但是其学出来的特征图是相似的,如上图所示,也就是说:一个以上金字塔等级的特征可以共同为特定实例的检测做出贡献,但是来自不同等级的贡献程度应该有所不同。这就是本文的出发点,不再强行判断哪一层进行回归了,而是每一层都进行回归,但是让网络自行学习到金字塔层级的权重。
说了半天,作者仔细谈到了这两个问题,但思考下可以发现说的都是同一个问题,都是正负样本定义问题。attention bias说的是对于特定输出层内的正负样本定义问题,feature selection说的则是不同输出层间的正负样本定义问题,我们以前说的正负样本定义都是hard,这里解决办法都是soft。
(2) 正负样本定义
对于特定输出层内的soft正负样本定义问题,作者的解决办法是引入类似center-ness一样的权重,属于Loss层面改进,我们放在(3) 平衡loss分析;对于不同输出层间的soft正负样本定义问题,作者采用的是采用网络自动学习soft权重的做法。
注意:输出层内hard正负样本定义,作者采用的依然和FCOS相同的策略,只不过正样本区域是通过4条边shrink得到,而不是center sampling。输出层间hard正负样本定义,作者没有用FCOS的分配策略,而是提出了新的soft代替hard。
本文不再强行判断哪一输出层进行gt bbox回归了,而是每一层都进行所有gt bbox回归,但是让网络自行学习到金字塔层级的权重。
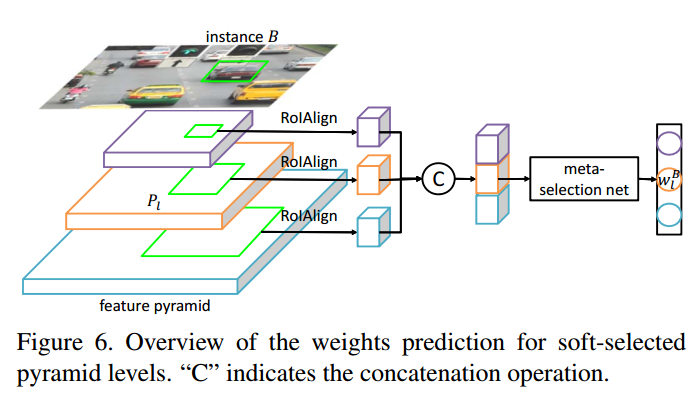
引入一个简单的网络来学习金字塔权重,具体做法是:利用gt bbox,映射到对应的特征图层,然后利用roialign层提出特征,在采用简单的分类器输出每个层级的权重。由于金字塔层数是5,故fc的输出是5。label设置上,这个思想的提出是参考FSAF(Feature Selective Anchor-Free Module for Single-Shot Object Detection)的做法,核心思想是不再人为定义具体是哪一层负责预测GT,而是根据loss最小的动态选择的那个层。本文借鉴上述思想,也是自动选择最适合的层。meta选择网络的独热码label不是人为提前计算好的,而是根据输出softmax层的值或者说loss来选择的,哪个输出节点loss最小,那么Label就设置为1,其余为0。整个meta选择网络和目标检测网络联合训练。
(3) 平衡loss设计
对于特定输出层内的soft正负样本定义问题,作者的解决办法是引入类似center-ness一样的权重,来对距离gt bbbx中心点进行惩罚。中心点权重最大,往外依次减少,其权重图如fcos里面所示:
从本质上来说和centernet的解决办法一模一样。
看过前面centernet 平衡分类loss分析的人可能有疑问:在centernet里面,其对focal loss的权重设置是在半径范围内,除中心点外,离中心点越近,权重最小,往外依次增加;但是这里的设计是正好相反的,其是离中心点越近,权重越大,往外依次减少。看起来是矛盾的?其实不是,千万不要忘记了label设计规则,centernet的分类label设置是除了中心点是1外,其余全部为0,而本文的label设置是不仅仅中心点是1,shrink附近区域的点也是1,其余全部是0,也就是说模糊区域中,centernet出发点认为是背景样本,而本文出发点认为是前景样本,所以其权重设置规则是正好相反的。
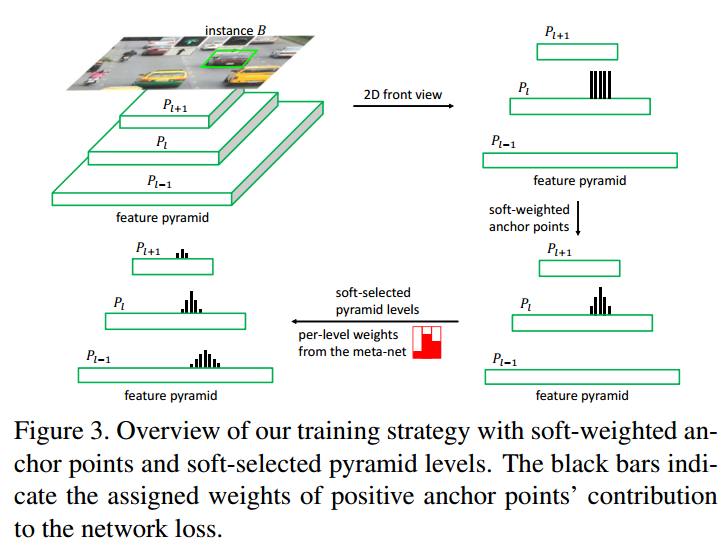
看到上图,就可以知道本文所有的操作了。对于特定层内的正负样本定义,原先是hard,现在通过引入权重变成了soft;对于层级间的正负样本定义,原先只会分配到特定层,其余层都0,现在引入了soft操作,权重是自己学到的。

通过网络学习到的层级间的权重,可以发现符合作者设定。
