@huanghaian
2020-03-19T06:51:52.000000Z
字数 3132
阅读 1420
Light-Head R-CNN
目标检测
论文题目: Light-Head R-CNN: In Defense of Two-Stage Object Detector
论文地址:https://arxiv.org/abs/1711.07264
简介
本文是旷视提出的偏向工程技术论文。主要出发点是为啥two-stage算法慢于one-stage算法?,作者深入分析原因,并且基于R-FCN论文提出了对应的改进版本: Light-Head R-CNN,可以看出就是将faster rcnn的重量级head修改为light,在精度没有损失情况下,大幅提高two-stage算法速度。
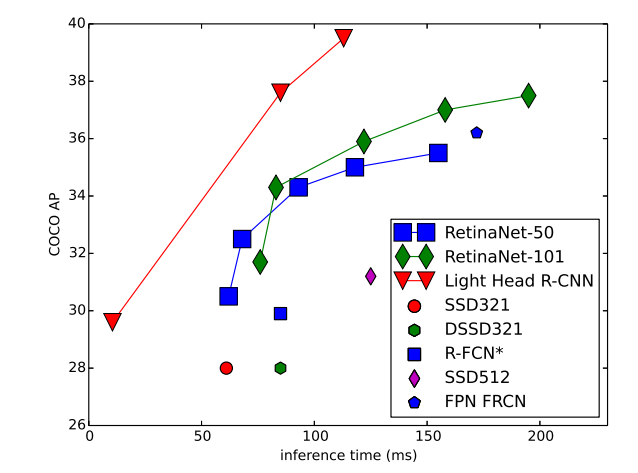
two-stage算法效率分析
其实在微软的R-FCN论文中进行了分析。一般可以把 two-stage 拆解成 body 跟 head:
- body: 生成proposal(RoI)的过程, 即: ROI warping.
- head: 基于proposal的recognition过程, 即: RCNN subnet.
作者认为目前的算法,为了追求best accurcy,一般都会把head设计的非常heavy,所以即使我们把前面的base model变小,还是无法明显提升检测速度。
为了说清楚Faster rcnn为何那么慢,需要先简要分析下faster rcnn结构。
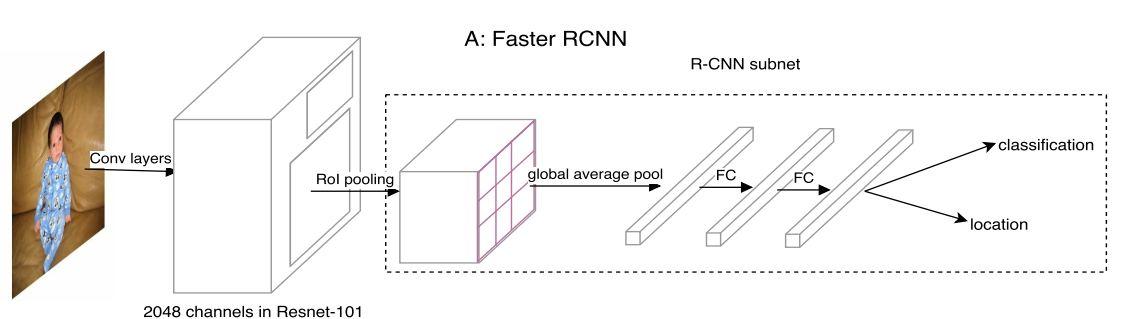
骨架和FPN就没啥说的,可以认为是body部分。在测试时候,RPN会输出一般是1000~2000个roi框,每个roi框维度是7x7x256,如果有2000个roi,那么输入到head部分的数据就是batchx2000x7x7x256,每个roi都要经过avg+fc(1024)+fc(1024),然后进行分类和回归预测。由于每个roi都需要单独输入到head部分进行推理,可以想象速度有多慢。如果减少roi数目,一定程度可以提高rcnn速度,但是精度可能下降。即rcnn部分无法共享计算,必须要每个roi单独计算一遍。现代faster rcnn模型一般不会用avg,因为实际效果可以发现会丢失空间细节,对mAP有影响,现在的代码都是直接对7x7x256的向量拉成向量,直接输入到后面2层fc中。所以计算量会更大,速度更慢。
针对faster rcnn无法共享计算问题,R-FCN提出了对应的改进版本,主要是要共享roi计算,大约可以快2.5~20倍。
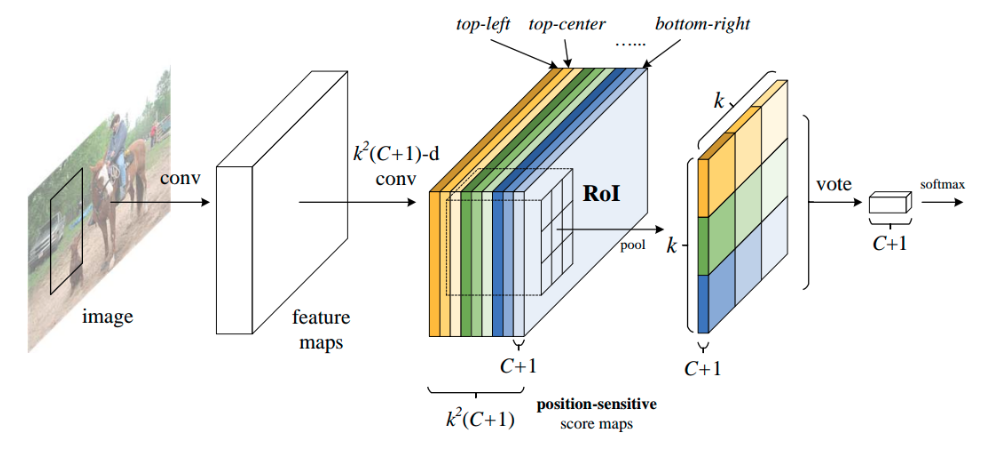
主要修改是得到ROI后,裁剪方式不是采用原始做法,而是先采用1x1的卷积核生成位置敏感分值图position-sensitive score maps,然后利用roi对分值图进行裁剪(PSRoI Pooling ),每个roi裁剪后直接得到的就是小特征图,经过简单vote就可以进行分类和回归,没有fc层。整个操作都是相当于全卷积操作,速度很快。通过引入位置敏感分值图来平衡分类需要平移不变性和检测需要平移变换性问题,并且roi后面只有简单的分类、回归层,使得整个检测网络基本上都共享计算,从而加速了检测速度。但是,为了让得到的feature map具有Position-sensitive的特点,需要满足它的channel数是。在COCO数据集上,相应的channel数是3969(7x7x81),这就必然还是会造成很大的时间和存储的开销。
综上所述,faster rcnn和R-FCN都存在速度和内存上面的不足。
light head rcnn设计
基本是在R-FCN的基础上进行修改的。不同的地方在于:
- 采用large separable convolution生成channel数更少的feature map(从3969减少到490)。
- 由于通道数减少,故不能用vote操作得到预测值,故用FC层代替了R-FCN中的vote(avg操作)。
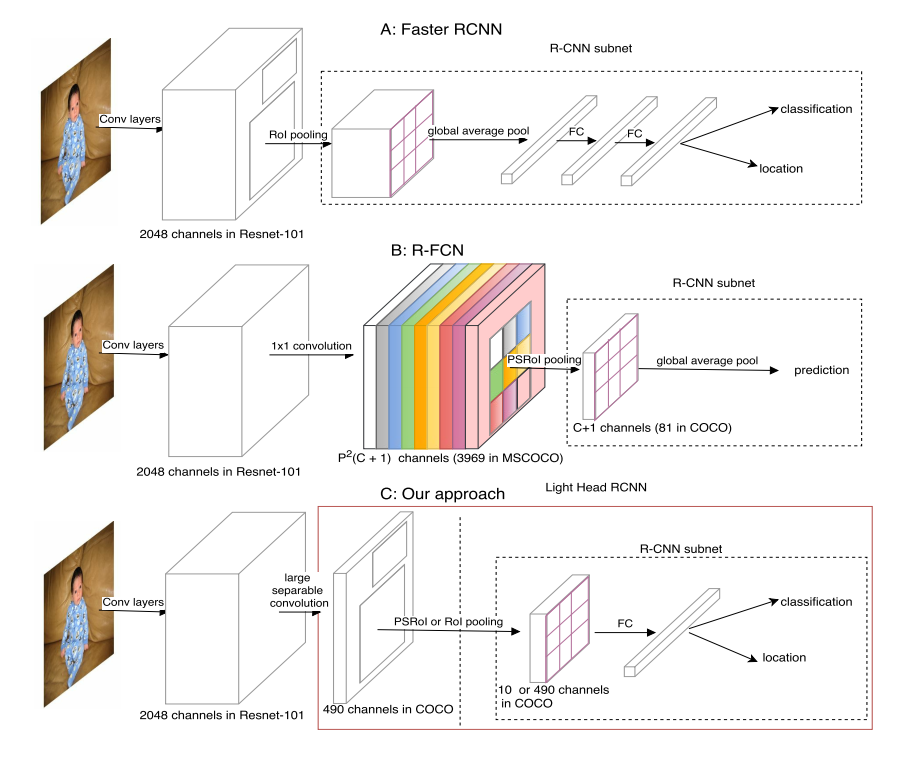
(1) Thin feature maps for RoI warping
具体做法就是在roi pool层前,先生成thin通道的特征图,减少计算量。为了保持性能,生成thin特征图时候采用了大分离卷积核操作
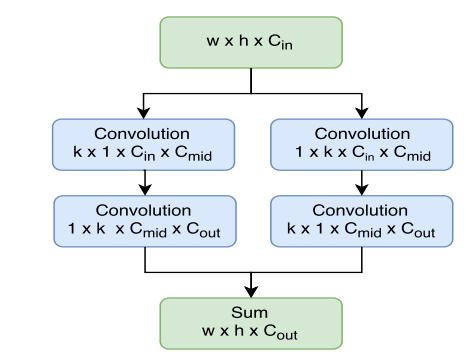
和Inception 3中的操作一致,K=15,论文中对于小骨架xception,,对于大骨架resnet101,。,故原来的位置敏感位置图的3969缩减为7x7x10=490个通道,减少内存消耗。
(2) R-CNN subnet
RCNN部分就非常简单了,就一个fc层(1024),然后接fc分类和回归。
实验
实验参数细节:

骨架网络采用了空洞卷积操作,并且采用ohem采样策略。
(1) Baselines
作者通过R-FCN的开源代码,在COCO mini-validation set上得到了mmAP 32.1%的baseline,记为B1. 又通过一些改进,得到一个更好的R-FCN baseline,记为B2. 主要的改进是:
- 对图像进行resize,将shorter edge设为800,同时限制max size为1200.
- 由于图像变大了,采用新的anchor: {322, 642, 1282, 2562, 5122}.
- 在R-CNN中,regression loss会比classification loss小很多,因此将regression loss*2.Each image has 2000/1000 RoIs for training/testing.
效果非常显著,这些简单的改进之后,R-FCN就提升了3%
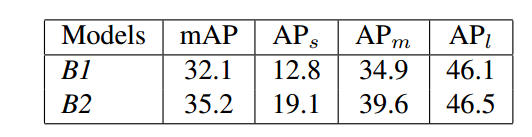
可以发现训练策略对最终结果影响很大。
(2) Thin feature maps for RoI warping
为了研究数量更少的feature map对结果的影响,作者又做了一组实验。除了以下两点,跟R-FCN基本一致:
- 减少feature map channel,从3696(81_7_7)减少到490(10_7_7).
- 由于改变了feature map channel数,导致无法直接通过global average pool进行prediction,因此加了一个FC层。
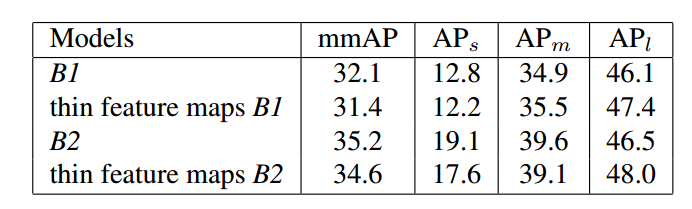
可以看出channel 数少了会导致精度的下降,这是正常现象。
(3) Large separable convolution
为了减少由于通道变小带来的性能丢失,引入大分离卷积核,结果如下:
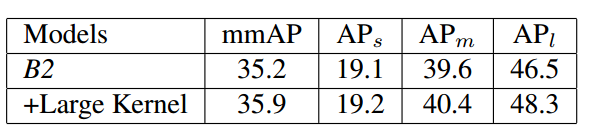
可以看出用了large separable convolution,虽然channel数减少了,效果却提升了0.7%.
(4) R-CNN subnet

(5) Light-Head R-CNN: High Accuracy
为了进一步提高性能,作者又采用了几个技巧:
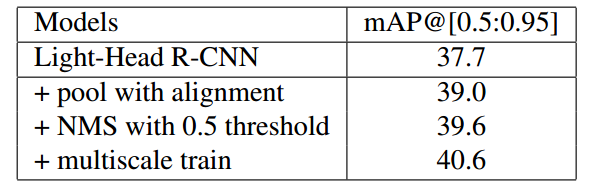
- 在PSRoI pooling中加入RoIAlign (Mask-RCNN) 中的插值技术,提升了1.7%.
- 将NMS threshold从0.3改成0.5之后,提升了0.6%.
- 使用multi-scale进行training,提升1%.
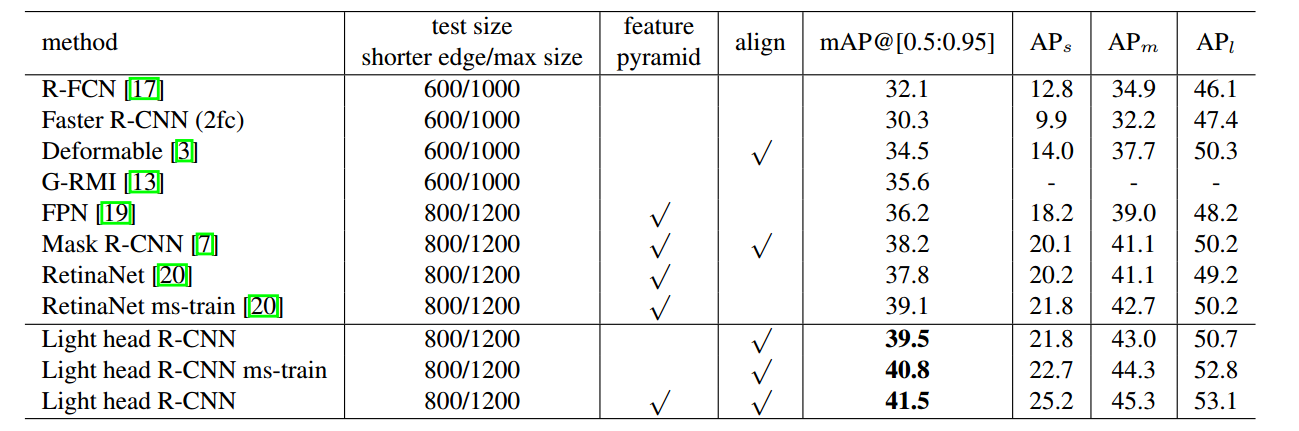
最终性能如下:
小模型高效版本:
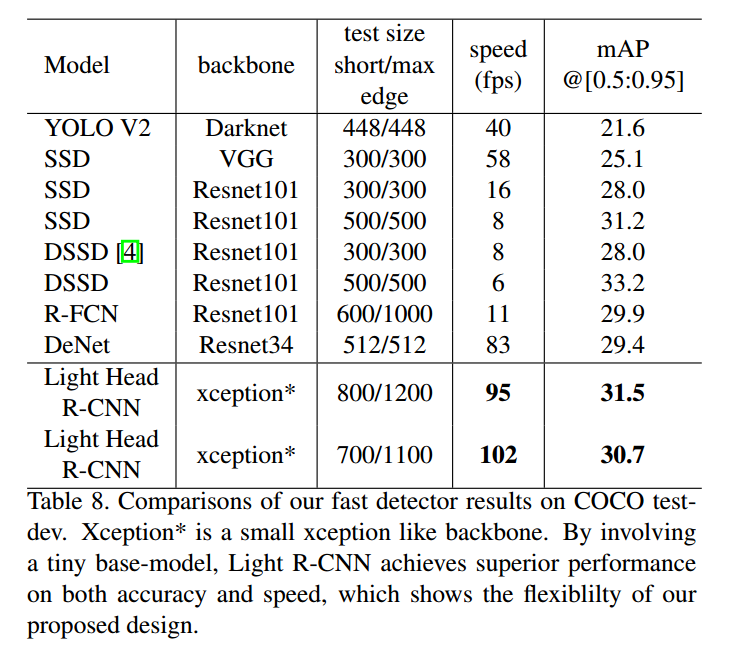
为了平衡精度与速度,作者做了如下一些改变:
- 用Xception代替Resnet-101.
- 弃用atrous algorithm.
- 将RPN channel减少一半到256.
- Large separable convolution: kernel size = 15, Cmid = 64, Cout = 490.
- 采用 PSPooling + RoI-align.
小模型结构如下:

总结
可以看出本文是经验类型论文,总体结构创新性不大,细节比较多。作者主要有以下几个改进点:
- Large separable convolution + Thin feature map 提升算法速度。
- 用FC来代替global average pooliing来减少空间信息的丢失,提高精度。
- 加入其它trick,例如: PSRoI with RoIAlign、multi-scale training、OHEM 等来进一步提升精度。
如果要自己复现,是很难复现出同样效果的。
